






引言
它是一个功能强大的Python框架,用于以非常灵活的方式从任何网站提取数据。它使用 Xpath 来搜索和提取数据。它很轻量级,对于初学者来说很容易理解。
现在,为了了解 Scrapy 的工作原理,我们将使用这个框架来抓取 Amazon 数据。我们将抓取亚马逊的图书部分,更具体地说,我们将抓取过去 30 天内发布的书籍。
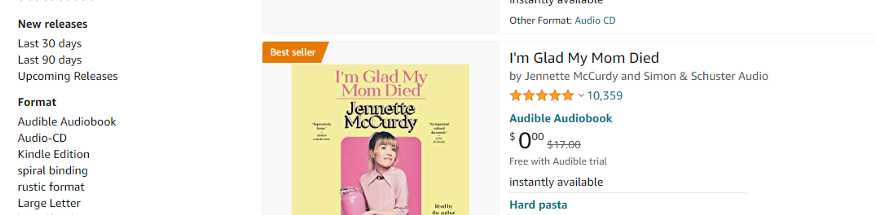
实战
我们将从创建一个文件夹并安装 Scrapy 开始。
mkdir scraper
pip install scrapy
现在,在开始编码之前,我们必须创建一个项目。只需在终端中输入以下命令即可。
scrapy startproject amazonscraper
此命令将在 scraper 文件夹内创建一个名为 amazonscraper 的项目文件夹。
上面的命令还在终端上返回一些消息,告诉您如何开始编写自己的抓取工具。我们将使用这两个命令。 让我们先进入这个 amazonscraper 文件夹。
cd amazonscraper
scrapy genspider amazon_spider amazon.com
这将为我们创建一个通用的spider,这样我们就不必通过进入spider文件夹来创建我们自己的spider,这将自动为我们创建它。然后我们为spider命名,然后输入目标网站的域名。
当您按 Enter 键时,您的文件夹中将出现一个名为 amazon_spider.py 的文件。当您打开该文件时,您会发现已自动创建了一个解析函数和一个 Amazonspider 类。
import scrapy
class AmazonSpiderSpider(scrapy.Spider):
name = ‘amazon_spider’
allowed_domains = [‘amazon.com’]
start_urls = [‘http://amazon.com/']
def parse(self, response):
pass
我们将删除 allowed_domains 变量,因为我们不需要它,同时我们将声明 start_urls 到我们的目标 URL。
//amazon_spider.py
import scrapy
class AmazonSpiderSpider(scrapy.Spider):
name = ‘amazon_spider’
allowed_domains = [‘amazon.com’]
start_urls = [‘https://www.amazon.com/s?k=books&i=stripbooks-intl-ship&__mk_es_US=%C3%85M%C3%85%C5%BD%C3%95%C3%91&crid=11NL2VKJ00J&sprefix=bo%2Cstripbooks-intl-ship%2C443&ref=nb_sb_noss_2']
def parse(self, response):
pass
在开始使用抓取工具之前,我们需要在 items.py 文件中创建一些项目,它们是临时容器。我们将从亚马逊页面上抓取标题、价格、作者和图像链接。
由于我们需要来自亚马逊的四件商品,因此我们将添加四个变量来存储值。
//items.py
import scrapy
class AmazonscraperItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
product_name = scrapy.Field()
product_author = scrapy.Field()
product_price = scrapy.Field()
product_imagelink = scrapy.Field()
pass
现在,我们将该文件导入到 amazon_spider.py 文件中。
//amazon_spider.py
from ..items import AmazonscraperItem
只需在文件顶部键入它即可。现在,在我们的 parse 方法中,我们将声明一个变量,它将成为 AmazonscraperItem 类的实例。
def parse(self, response):
items = AmazonscraperItem()
pass
我们现在准备从亚马逊上抓取我们的目标元素。我们将从抓取产品名称开始。我们将声明一个变量product_name,它将等于产品名称元素的CSS 选择器。
def parse(self, response):
items = AmazonscraperItem()
product_name= response.css()
pass
在这里,我将使用 SelectorGadget 扩展来获取目标页面上的元素位置。
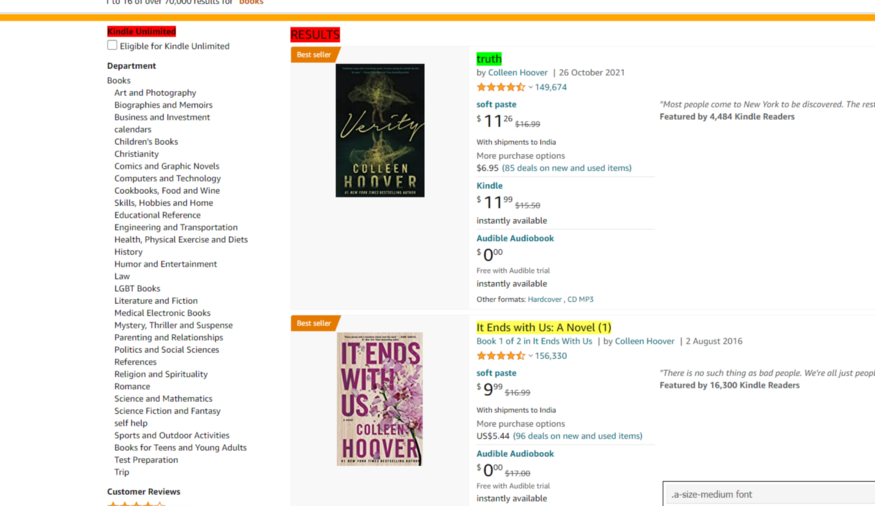
在右下角你可以看到我们的 CSS 选择器。我将从这里复制它,然后将其粘贴到我们的代码中。
def parse(self, response):
items = AmazonscraperItem()
product_name= response.css(‘.a-size-medium’).extract()
pass
我使用 .extract() 函数来获取所有这些产品元素的 HTML 部分。同样,我们将使用相同的技术来提取产品价格、作者和图像链接。在为作者查找 CSS 选择器时,SelectorGadget 会选择其中的一些,而会让许多作者未被选中。因此,您还必须选择这些作者。
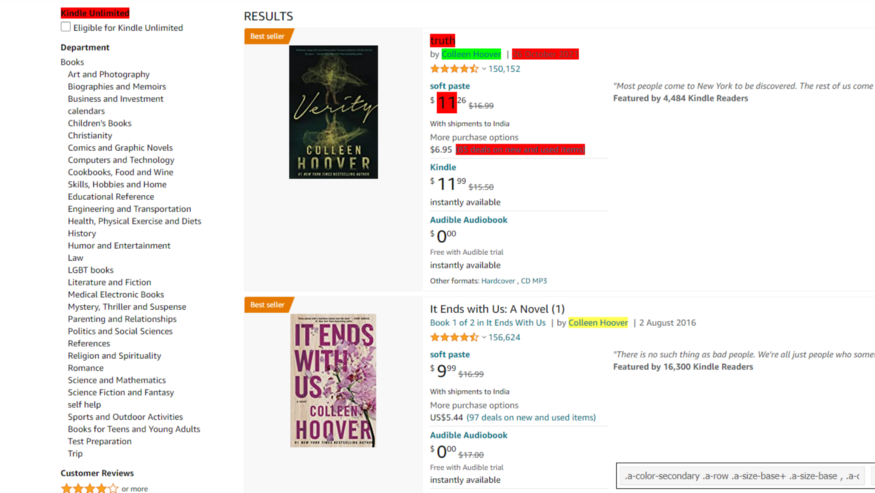
def parse(self, response):
items = AmazonscraperItem()
product_name= response.css(‘.a-size-medium’).extract()
product_author = response.css(‘.a-color-secondary .a-row .a-size-base+ .a-size-base , .a-color-secondary .a-size-base.s-link-style , .a-color-secondary .a-size-base.s-link-style font’).extract()
pass
现在,我们也找到价格的 CSS 选择器。
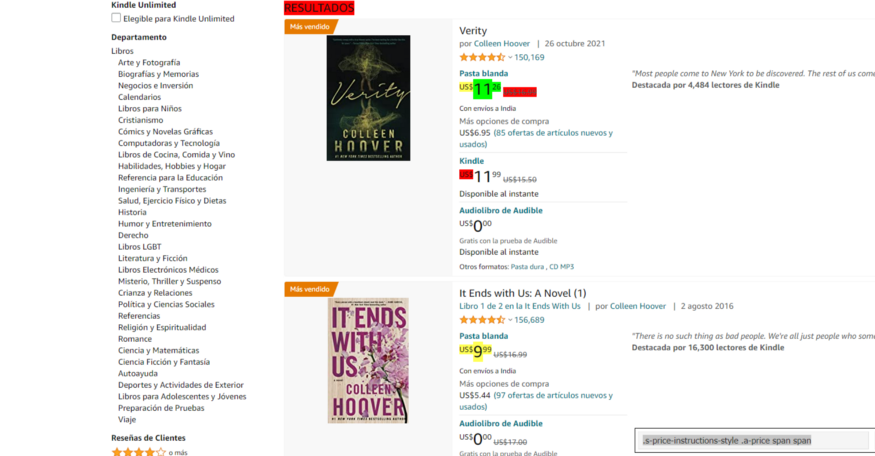
def parse(self, response):
items = AmazonscraperItem()
product_name= response.css(‘.a-size-medium’).extract()
product_author = response.css(‘.a-color-secondary .a-row .a-size-base+ .a-size-base , .a-color-secondary .a-size-base.s-link-style , .a-color-secondary .a-size-base.s-link-style font’).extract()
product_price = response.css(‘.s-price-instructions-style .a-price-fraction , .s-price-instructions-style .a-price-whole’).extract()
pass
最后,现在我们将找到图像的 CSS 选择器。
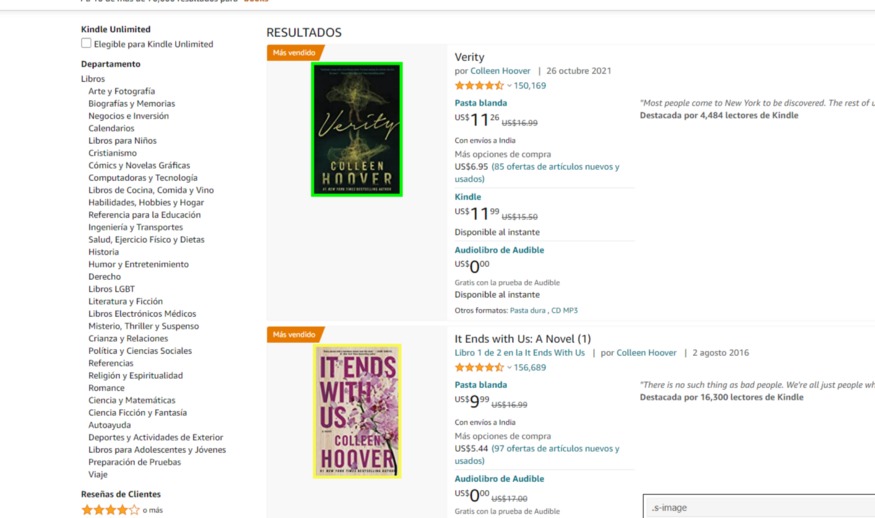
.s-image 是我们图像的 CSS 选择器。
def parse(self, response):
items = AmazonscraperItem()
product_name= response.css(‘.a-size-medium’).extract()
product_author = response.css(‘.a-color-secondary .a-row .a-size-base+ .a-size-base , .a-color-secondary .a-size-base.s-link-style , .a-color-secondary .a-size-base.s-link-style font’).extract()
product_price = response.css(‘.s-price-instructions-style .a-price-fraction , .s-price-instructions-style .a-price-whole’).extract()
product_imagelink = response.css(‘.s-image’).extract()
现在,正如我之前所说,这只会为我们提供 HTML 代码,我们需要从中提取名称。因此,为此,我们将使用 Scrapy 的文本功能。这将确保不会提取整个标签,并且仅提取该标签中的文本。
product_name= response.css(‘.a-size-medium::text’).extract()
但是因为我们为 CSS 选择器使用了多个类,所以我们无法在末尾添加此文本。我们必须对product_price 和product_author 使用.css() 函数。
product_author = response.css(‘.a-color-secondary .a-row .a-size-base+ .a-size-base , .a-color-secondary .a-size-base.s-link-style , .a-color-secondary .a-size-base.s-link-style font’).css(‘::text’).extract()
product_price = response.css(‘.s-price-instructions-style .a-price-fraction , .s-price-instructions-style .a-price-whole’).css(‘::text’).extract()
现在,product_imagelink 只是选择图像,因此我们不会在其上使用 .css() 函数。我们的图像存储在 src 标签内,我们需要它的值。
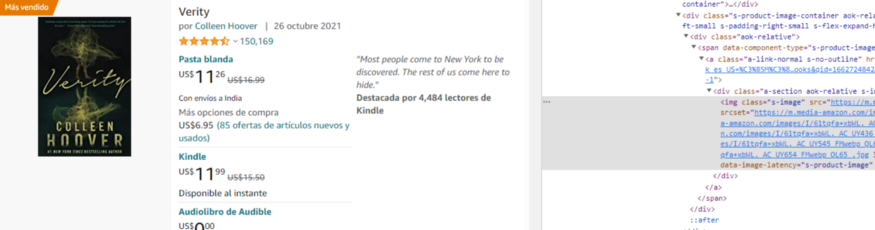
我们将使用Scrapy的attr功能。
product_imagelink = response.css(‘.s-image::attr(src)’).extract()
我们已经成功提取了所有值。现在,我们将它们存储在各自的临时物品容器中,这就是我们的做法。
items[‘product_name’] = product_name
这个product_name实际上是我们在items.py文件中声明的变量。我们将对所有其他目标元素执行此操作。
items[‘product_name’] = product_name
items[‘product_author’] = product_author
items[‘product_price’] = product_price
items[‘product_imagelink’] = product_imagelink
现在,我们只需要生成这些项目,这将完成我们的代码。我们的代码一开始可能不会,但让我们看看我们得到了什么。
yield items
现在,要运行我们的代码,请在终端上运行以下命令。
scrapy crawl amazon_spider
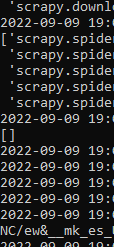
正如你所看到的,我们得到了一个空数组。这是由于亚马逊的反机器人机制所致。为了克服这个问题,我们将在 settings.py 文件中设置一个用户代理。
USER_AGENT = ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0’
现在,让我们再试一次。
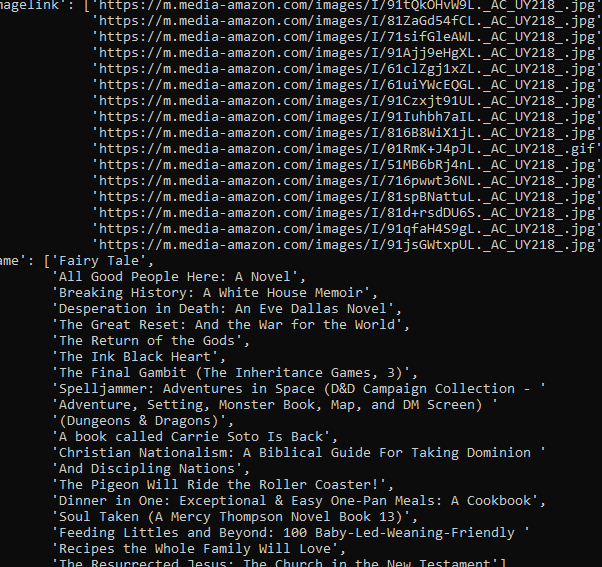
我们得到了结果。但和往常一样,这不会持续多久,因为亚马逊的反机器人技术将会启动,你的抓取工具将会停止。
Scrapy的功能还不止于此!
-
您可以通过更改 CONCURRENT_REQUESTS 的值在 settings.py 文件中设置并行请求数。这将帮助您检查 API 可以处理多少负载。 -
它比 Python 提供的大多数 HTTP 库都要快。
本文由 mdnice 多平台发布















 57万+
57万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









