






引言
当您从 Awk 系列一开始回顾我们迄今为止介绍的所有 Awk 示例时,您会注意到各个示例中的所有命令都是按顺序执行的,即一个接一个。但在某些情况下,我们可能希望根据某些条件运行一些文本过滤操作,这就是流程控制语句的方法。

Awk 编程中有各种流程控制语句,包括:
-
if-else 语句 -
声明 -
while 语句 -
do while 语句 -
中断语句 -
继续声明 -
下一个声明 -
下一个文件语句 -
退出声明
然而,对于本系列的范围,我们将阐述:if-else、for、while 和 do while 语句。
1. if-else 语句
if 语句的预期语法与 shell if 语句的语法类似:
if (condition1) {
actions1
}
else {
actions2
}
在上述语法中,condition1和condition2是Awk表达式,actions1和actions2是满足各自条件时执行的Awk命令。
当条件1满足时,即为真,则执行actions1并退出if语句,否则执行actions2。
if 语句也可以扩展为 if-else_if-else 语句,如下所示:
if (condition1){
actions1
}
else if (conditions2){
actions2
}
else{
actions3
}
对于上面的形式,如果条件 1 为 true,则执行 actions1 并退出 if 语句,否则评估条件 2,如果为 true,则执行 actions2 并退出 if 语句。然而,当条件2为假时,则执行动作3并且退出if语句。
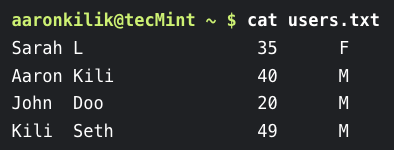
这是使用 if 语句的一个例子,我们有一个用户列表及其年龄存储在文件 users.txt 中。
我们想要打印一条声明,指明用户的姓名以及用户的年龄是小于还是大于 25 岁。
我们可以编写一个简短的shell脚本来执行上面的工作,以下是脚本的内容:
#!/bin/bash
awk ' {
if ( $3 <= 25 ){
print "User",$1,$2,"is less than 25 years old." ;
}
else {
print "User",$1,$2,"is more than 25 years old" ;
}
}' ~/users.txt
然后保存文件并退出,使脚本可执行并运行,如下所示:
$ chmod +x test.sh
$ ./test.sh
-
输出结果

2. for 语句
如果您想在循环中执行某些 Awk 命令,则 for 语句为您提供了一种合适的方法,其语法如下:
这里,该方法简单地定义为使用计数器来控制循环执行,首先需要初始化计数器,然后根据测试条件运行它,如果为真,则执行操作,最后递增计数器。当计数器不满足条件时循环终止。
for ( counter-initialization; test-condition; counter-increment ){
actions
}
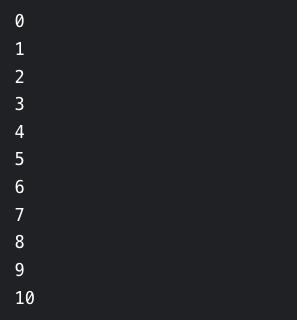
以下 Awk 命令显示了 for 语句的工作原理,我们要在其中打印数字 0-10:
$ awk 'BEGIN{ for(counter=0;counter<=10;counter++){ print counter} }'
-
输出结果
3. while 语句
while 语句的常规语法如下:
while ( condition ) {
actions
}
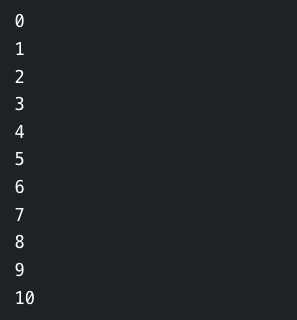
条件是一个 Awk 表达式,操作是条件为真时执行的 Awk 命令行。下面是一个脚本来说明如何使用 while 语句来打印数字 0-10:
#!/bin/bash
awk ' BEGIN{ counter=0 ;
while(counter<=10){
print counter;
counter+=1 ;
}
}
保存文件并使脚本可执行,然后运行它:
$ chmod +x test.sh
$ ./test.sh
4. do while 语句
它是上面 while 语句的修改,具有以下底层语法:
do {
actions
}
while (condition)
细微的差别在于,在 do while 下,Awk 命令在评估条件之前执行。使用上面 while 语句下的示例,我们可以通过更改 test.sh 脚本中的 Awk 命令来说明 do while 的用法,如下所示:
#!/bin/bash
awk ' BEGIN{ counter=0 ;
do{
print counter;
counter+=1 ;
}
while (counter<=10)
}
修改脚本后,保存文件并退出。然后使脚本可执行并按如下方式执行:
$ chmod +x test.sh
$ ./test.sh
结果如上图一致。
总结
Awk 系列的这一部分应该让您清楚地了解如何根据特定条件控制 Awk 命令的执行。
本文由 mdnice 多平台发布















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









