







1、树与树的表示
什么是树?
客观世界中许多事物存在层次关系
- 人类社会家谱
- 社会组织结构
- 图书信息管理
分层次组织在管理上具有更高的效率!
数据管理的基本操作之一:查找(根据某个给定关键字K,从集合R 中找出关键字与K 相同的记录)。一个自然的问题就是,如何实现有效率的查找?
- 静态查找:集合中记录是固定的,没有插入和删除操作,只有查找
- 动态查找:集合中记录是动态变化的,除查找,还可能发生插入和删除
静态查找——方法一:顺序查找(时间复杂度O(n))
|
1
2
3
4
5
6
7
8
9
|
int
SequentialSearch(StaticTable * Tbl, ElementType K)
{
// 在表Tbl[1]~Tbl[n] 中查找关键字为K的数据元素
int
i;
Tabl->Element[0] = K;
// 建立哨兵
for
(i = Tbl->Length; Tbl->Element[i] != K; i--)
;
return
i;
// 查找成功返回所在单元下标;不成功返回0
}
|
静态查找——方法二:二分查找(时间复杂度O(logn))
二分查找的启示?
二分查找判定树:
- 判定树上每个结点需要的查找次数刚好为该结点所在的层数
- 查找成功时查找次数不会超过判定树的深度
- n 个结点的判定树的深度为⌊log2n⌋+1
树的定义
树(Tree):n(n ≥ 0)个结点构成的有限集合。
当n = 0 时,称为空树。
对于任一颗非空树(n > 0),它具备以下性质:
- 树中有一个称为"根(Root)"的特殊结点,用r 表示;
- 其余结点(与r 相关联的)可分为m(m > 0)个互不相交的有限集T1,T2,...,Tm,其中每个集合本身又是一颗树,称为原来树的"子树(SubTree)"。
树与非树?
- 子树是不相交的
- 除了根结点外,每个结点有且仅有一个父节点
- 一颗N个结点的树有N-1条边(我认为可以用构造性的存在性证明或是数学归纳法来证明这一点)
树的一些基本术语:
- 结点的度(Degree):结点的子树个数
- 树的度:树的所有结点中最大的度数
- 叶结点(Leaf):度为0的结点
- 父结点(Parent):有子树的结点是其子树的根结点的父结点
- 子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点
- 兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点
- 路径和路径长度:从结点n1到nk的路径为一个结点序列n1,n2,...,nk,ni是ni+1的父结点,路径所包含的边的个数为路径的长度
- 祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点
- 子孙结点(Descendant):某一结点的子树中的所有结点都是这个结点子孙
- 结点的层次(Level):规定根结点在1层,其它任一结点的层数时其父节点的层数加1
- 树的深度(Depth):树中所有结点中的最大层次是这棵树的深度
树的表示
为可节省空间,最常用的表示树的方法是儿子-兄弟表示法。
2、二叉树及存储结构
二叉树的定义
二叉树T:一个有穷的结点集合
这个集合可以为空
若不为空,则它是由根结点和称为其左子树TL和右子树TR的两个不相交的二叉树组成
- 二叉树具有五种基本形态(空、单根、根+TL、根+TR、根+TL+TR)
- 二叉树的子树有左右顺序之分
特殊二叉树
斜二叉树(Skewed Binary Tree)、完美二叉树(Perfect Binary Tree)/满二叉树(Full Binary Tree)、完全二叉树(Complete Binary Tree)
这里重点介绍下CBT:有n 个结点的二叉树,对树中结点按从上至下、从左至右顺序进行编号,编号为i (1 ≤ i ≤ n)结点与满二叉树中编号为i 结点在二叉树中位置相同
二叉树几个重要性质
- 一个二叉树第i 层的最大结点数为:2i-1,i ≥ 1
- 深度为k 的二叉树有最大结点总数为:2k-1,k ≥ 1
- 对任何非空二叉树T,若n0 表示叶结点的个数,n2 是度为2 的非叶结点个数,那么两者满足关系n0 = n2 + 1(证明见这里)
二叉树的抽象数据类型
重要操作:
- BinTree CreateBinTree():创建一个二叉树
- Boolean IsEmpty(BinTree BT):判别BT 是否为空
- void Traversal(BinTree BT):遍历,按某顺序访问每个结点
常用的遍历方法有:
- void PreOrderTraversal(BinTree BT):先序——根、左子树、右子树
- void InOrderTraversal(BinTree BT):中序——左子树、根、右子树
- void PostOrderTraversal(BinTree BT):后序——左子树、右子树、根
- void LevelOrderTraversal(BinTree BT):层次遍历——从上到下、从左到右
二叉树的存储结构
顺序存储结构
依完全二叉树的形式存储:按从上到下、从左到右顺序存储。
n 个结点的完全二叉树的节点父子关系:
- 非根节点(序号i > 1)的父结点序号是⌊i/2⌋
- 结点(序号为i)的左孩子结点的序号是2i(若2i ≤ n,否则没有左孩子)
- 结点(序号为i)的右孩子结点的序号是2i+1(若 2i+1 ≤ n,否则没有右孩子)
应当注意的一点是:一般二叉树也可以采用这种结构,但会造成空间浪费
链表存储
|
1
2
3
4
5
6
7
|
typedef
struct
TreeNode *BinTree;
typedef
BinTree Position;
struct
TreeNode{
ElementType Data;
BinTree Left;
BinTree Right;
}
|
3、二叉树的遍历
二叉树的递归遍历
先序遍历:访问根结点;先序遍历其左子树;先序遍历其右子树
|
1
2
3
4
5
6
7
8
9
|
void
PreOrderTraversal(BinTree BT)
{
if
(BT)
{
printf
(
"%d"
, BT->data);
PreOrderTraversal(BT->Left);
PreOrderTraversal(BT->Right);
}
}
|
中序遍历:中序遍历其左子树;访问根结点;中序遍历其右子树
|
1
2
3
4
5
6
7
8
9
|
void
InOrderTraversal(BinTree BT)
{
if
(BT)
{
InOrderTraversal(BT->Left);
printf
(
"%d"
, BT->Data);
InOrderTraversal(BT->Right);
}
}
|
后序遍历:后续遍历其左子树;后续遍历其右子树;访问根结点
|
1
2
3
4
5
6
7
8
9
|
void
PostOrderTraversal(BinTree BT)
{
if
(BT)
{
PostOrderTraversal(BT->Left);
PostOrderTraversal(BT->Right);
printf
(
"%d"
, BT->Data);
}
}
|
附注:先序、中序和后序遍历过程:遍历过程经过结点的路线一样,只是访问各结点的时机不同。下图在从入口到出口的曲线上用ⓧ、★和△三种符号分别标记出了先序、中序和后序访问各结点的时刻
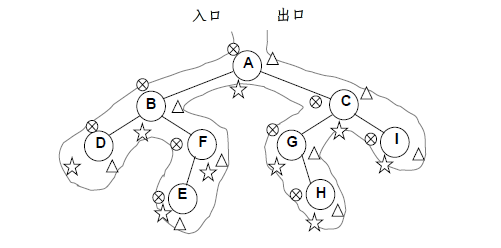
先序:当曲线第一次经过一个结点时,就列出这个结点;中序:当曲线第一次经过一个树叶时,就列出这个树叶,当曲线第二次经过一个内点时就列出这个内点;后序:当曲线最后一次经过一个结点而返回这个结点的父亲时,就列出这个结点。
二叉树的非递归遍历
非递归遍历算法实现的基本思路:使用堆栈。我们以中序遍历的非递归算法为例:
- 遇到一个结点,就把它压栈,并去遍历它的左子树
- 当左子树遍历结束后,从栈顶弹出这个结点并访问它
- 然后按其右指针再去中序遍历该结点的右子树
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void
InOrderTraversal(BinTree BT)
{
BinTree T = BT;
Stack S = CreateStack(MaxSize);
// 创建并初始化堆栈
while
(T || !IsEmpty(S))
{
while
(T)
// 一直向左并将沿途结点压入堆栈
{
Push(S, T);
T = T->Left;
}
if
(!IsEmpty(S))
// 不是必须的,因为while入口处已经判断过了
{
T = Pop(S);
// 结点弹出堆栈
printf
(
"%5d"
, T->Data);
// (访问)打印结点
T = T->Right;
// 转向右子树
}
}
}
|
注意到先序的非递归算法只要在中序非递归算法的基础上做一下调整就好了:printf语句放到Push操作之前。而后续遍历就比较繁琐了,因为当指针T指向一个结点时,不能马上对它进行访问,而要先遍历它的左子树,因而要将此结点的地址进栈保存。当其左子树遍历完毕之后,再次搜索到该结点时(退栈),还不能对它访问,还需要遍历它的右子树,所以,再一次将此结点的地址进栈保存。为了区别同一结点的两次进栈,需要引入一个标志变量,比如flag为0表示该结点暂不访问,为1表示该结点可以访问。
层序遍历
层序遍历基本过程:先根结点入队,然后:
- 从队列中取出一个元素
- 访问该元素所指结点
- 若该结点所指结点的左、右孩子结点非空,则将其左、右孩子的指针顺序入队
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
void
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









