






 本文介绍了缓存穿透的概念,以及如何通过缓存空对象和布隆过滤器来解决这一问题。特别强调了布隆过滤器作为推荐方案,尽管存在误识别率但能有效防止数据库崩溃。
本文介绍了缓存穿透的概念,以及如何通过缓存空对象和布隆过滤器来解决这一问题。特别强调了布隆过滤器作为推荐方案,尽管存在误识别率但能有效防止数据库崩溃。
一、缓存穿透的定义
缓存穿透: 指客户端请求的数据在Redis缓存和数据库中都不存在,这样Redis缓存将永远不会生效,也就是说请求都会打到数据库中。
如果有心人利用这一特性对服务器同时进行大量请求,就有可能造成数据库的奔溃,因此,我们需要对缓存穿透进行处理。
二、常见解决方案
1.缓存空对象
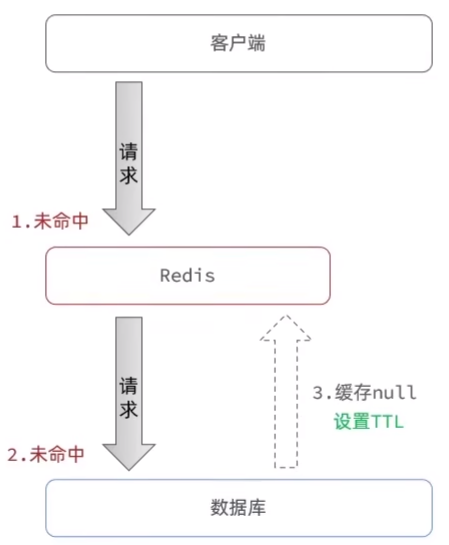
即客户端请求的数据如果在缓存和数据库中都不存在,我们也在Redis中进行缓存,设置value为null。
优点: 实现简单,维护方便。
缺点:
①大量的空值会造成额外的内存消耗
由于我们将不存在的数据都存入Redis缓存中并置为null,如此大量的空值会占据较多的内存空间,造成内存的浪费。
解决方法: 对每一个空数据都设置较短过的期时间(TTL),可以是一两分钟或者适当的时间。这样可以保证每一个空数据只存在一定的时间就会被删除,减少内存空间的占用。
②造成短期的数据不一致
假设用户请求了一个不存在的id数据,根据缓存空对象的处理办法,我们向Redis中插入了null值并设置了TTL过期时间。如果这时我们向数据库插入了一条id的数据,而该id恰好与刚刚用户请求的id一致,那么,在TTL到期之前,所有用户请求这一id得到的值都是null,而不是我们向数据库中插入的数据。
解决方法: 设置较短的TTL可以在一定程度上缓解。或者采用主动更新的方式更新(删除)缓存。亦或者用第二种解决方案布隆过滤。
③无法抵御随机攻击
缓存空对象会将用户请求的不存在的数据存入Redis中并置为空值,当用户第二次及之后请求这一数据时会返回Redis中的缓存(即null),但如果用户每次请求的值都不存在于数据库和缓存中,则每次请求还是会直接打到数据库中,大量的这类请求同样会造成数据库的崩溃。
解决方法: 用第二种解决方案布隆过滤。
2.布隆过滤(推荐)
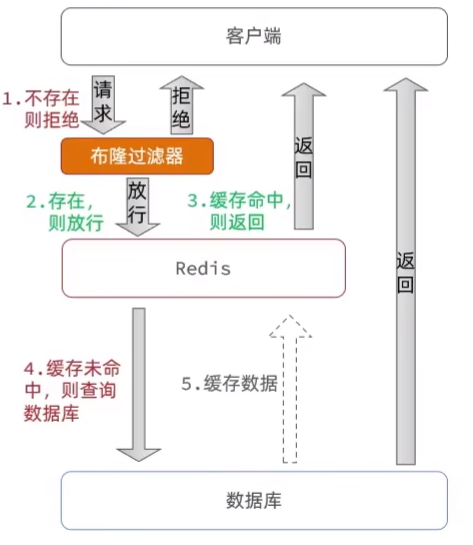
即采用布隆过滤器(Bloom Filter)对请求的数据进行过滤,如果布隆过滤器认为元素可能存在,则会放行,如果认为元素不存在,则直接拒绝请求。
布隆过滤器是1970年由Bloom提出的,它是由一组哈希(Hash)函数和一个位阵列组成。布隆过滤器可以用于查询一个元素是否存在于一个集合当中。
其查询结果只有两个:
- 这个元素可能存在于这个集合当中。
- 这个元素一定不存在于这个集合当中。
简单而言,布隆过滤器认为存在的数据不一定存在,但认为不存在的数据一定不存在。
优点: 其空间效率和查询时间都比一般的算法要好的多。
缺点: 有一定的误识别率、删除困难。
布隆过滤器在实际中主要用来解决网页URL去重复,垃圾邮件检测,大集合中重复元素的判断和缓存击穿等问题。
布隆过滤器的具体使用这里不做讨论,有时间会回来补充,可以自行检索其他文献。















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









