







字符编码格式:
只有127字符的ASCII码,一个字符就是一个字节
GB2312将中文编码
Unicode所有的语言统一编码,通常是2个字节
UTF-8可变长编码,一个字符编成1-6个字节,一个英文字符一个字节,汉子三个字节,生僻字符4-6个字节
计算机内存中的编码格式都是Unicode,所以我们看到的浏览器前端都是服务器转换Unicode字符为UTF-8格式传递过来的,网页源码包括<meta charset="UTF-8"/>
Python3中的字符串也是Unicode编码;
1.ord()函数获取字符的整数表示:
>>>ord('A')
65
2.chr()函数则把编码转换为字符表示:
>>>chr(65)
'A'
字符串转换为bytes—encode()
1.Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x=b'ABC'
2.以Unicode表示的str通过encode()方法可以编码为指定的bytes:
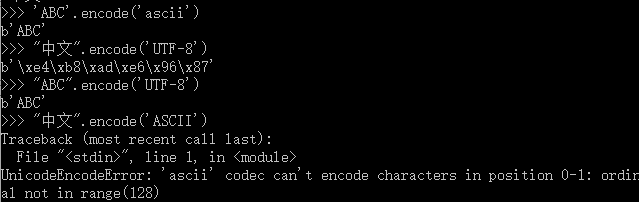
可以明显看到,中文使用encode()方法根据ASCII码转换为bytes时是失败的!
bytes转换为字符串—decode()
>>> b'ABC'.decode('ascii')
'ABC'
>>>b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
字符串计算多少个字符使用函数len();如果参数是bytes,那么计算的是bytes的字节数
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
格式化
Python中的字符串格式化方式是使用%符号
>>> 'Hello, %s' % 'world'
'Hello, world'
>>>'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
| 常见占位符 | 意义 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
格式化整数和浮点数还可以指定是否补0和整数与小数的位数
>>>'%2d-%02d' % (3, 1)
' 3-01'
>>>'%.2f' % 3.1415926
'3.14'
3前面是存在一个空格的占位符的;
而%s可以将任何数据类型转换为字符串 ;
如果%本身是个需要显示的符号,那么使用两个%%~















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









