







第五章:基于centos7的mysql数据库的开发
5.1基础知识学习
掌握mysql数据库的基本知识,数据基本语句以及命令行操作
5.2在centos7上安装mysql
需要注意的是,我的系统上如果直接使用sudo yum install mysql-server命令进行安装,系统找到的包是mariadb数据库。关于这两个数据库。下面是一些介绍:
源起关系:MariaDB最初是MySQL的一个分支,由MySQL的创始人之一Michael Widenius创建,旨在提供一个兼容MySQL的替代品。
兼容性:MariaDB被设计为与MySQL高度兼容,因此大多数MySQL的应用程序和工具可以无缝迁移到MariaDB上。大部分MySQL的语法、命令和特性在MariaDB中都可以使用。
社区发展:MariaDB拥有自己的开源社区和开发团队,不依赖于Oracle公司,这使得它能够更加灵活地推进新功能和改进。
功能扩展:MariaDB在一些方面对MySQL进行了扩展和改进,引入了一些新的功能和存储引擎。例如,MariaDB引入了一些性能优化、高可用性功能和安全增强。
默认存储引擎:MySQL的默认存储引擎是InnoDB,而MariaDB的默认存储引擎是XtraDB,它是对InnoDB存储引擎的增强版本。
尽管MariaDB和MySQL在很多方面相似,但它们仍然是两个独立的产品,存在一些细微的差异和特性。对于大多数用户来说,从MySQL迁移到MariaDB是相对容易的,因为它们之间的兼容性很高。
为了目前学习的方便,我还是选择安装mysql数据库。关于怎么安装,采取离线安装的模式。可以参考mysql官网的一篇教程。Linux Centos 7 - MySQL 5.7 Offline Installation (programmer.group)
1.下载对应版本,平台的mysql离线安装压缩包。下载完成后我采用挂载主机硬盘的方式移动至虚拟机/usr/local目录下。
2.使用这两条命令首先查找自己的系统有没有安装mariadb数据库。然后进行卸载。-e 表示卸载一个软件包。--nodeps 是一个选项,告诉 RPM 包管理器在卸载软件包时不进行依赖关系检查。通常情况下,RPM 包管理器会检查软件包之间的依赖关系,以确保正确的安装和卸载顺序。使用 --nodeps 选项可能会导致潜在的问题,因为卸载软件包可能会导致其他软件无法正常工作。
rpm -qa | grep mariadb
rpm -e --nodeps file name3.创建专门的用户和用户组来管理 MySQL。
groupadd mysql:这个命令用于创建名为 "mysql" 的用户组。用户组用于组织用户并定义其权限,这里创建的 "mysql" 用户组是专门用于 MySQL 相关操作的。
useradd -g mysql mysql -d /home/mysql:这个命令用于创建一个名为 "mysql" 的用户,并将其分配到 "mysql" 用户组中,使用 -g 选项指定了用户的主组为 "mysql"。-d 选项指定了用户的家目录为 "/home/mysql"。这个命令创建了一个专门用于 MySQL 相关操作的用户。
passwd mysql:这个命令用于修改 "mysql" 用户的登录密码。当你执行这个命令时,会提示你输入一个新密码。输入新密码后会再次要求确认密码。确认成功后,"mysql" 用户的密码将被更新。
groupadd mysql
useradd -g mysql mysql -d /home/mysql
passwd mysql4. 先创建一些文件夹。我的位置在/usr/local/mysql中。
[sxixia@localhost mysql]$ sudo mkdir ./data log tmp5.解压下载的压缩包,解压后会生成一个与压缩包同名的文件夹。将文件夹内所有文件移动到上层目录,也就是usr/local/mysql中,再删除移走后空的文件夹。最后将 mysql 文件夹下的所有文件和子文件夹的所有者和所属组都设置为 "mysql" 用户和 "mysql" 用户组。这通常在安装和配置 MySQL 时用于确保相关文件和文件夹的权限正确设置,以便 MySQL 服务能够正常运行并具有适当的访问权限。再执行最后一条命令时先要返回上级目录。
sudo tar -zxvf mysql-5.7.27-linux-glibc2.12-x86_64.tar.gz
cd mysql-5.7.27-linux-glibc2.12-x86_64
sudo mv * ..
cd ..
rm -rf mysql-5.7.27-linux-glibc2.12-x86_64
cd ..
chown -R mysql:mysql mysql/6.在/etc目录中编写mysql的配置文件。官网提供了模板。需要将模板中的路径更改为自己的。其他的不用动。
sudo vim /etc/my.cnf
[client] # Client settings, the default connection parameters for the client
port = 3306 # Default connection port
socket = /usr/local/mysql/tmp/mysql.sock # For socket sockets for local connections, the mysqld daemon generates this file
[mysqld] # Server Basic Settings
# Foundation setup
user = mysql
bind-address = 0.0.0.0 # Allow any ip host to access this database
server-id = 1 # The unique number of Mysql service Each MySQL service Id needs to be unique
port = 3306 # MySQL listening port
basedir = /usr/local/mysql # MySQL installation root directory
datadir = /usr/local/mysql/data # MySQL Data File Location
tmpdir = /usr/local/mysql/tmp # Temporary directories, such as load data infile, will be used
socket = /usr/local/mysql/tmp/mysql.sock # Specify a socket file for local communication between MySQL client program and server
pid-file = /usr/local/mysql/log/mysql.pid # The directory where the pid file is located
skip_name_resolve = 1 # Only use IP address to check the client's login, not the host name.
character-set-server = utf8mb4 # Database default character set, mainstream character set support some special emoticons (special emoticons occupy 4 bytes)
transaction_isolation = READ-COMMITTED # Transaction isolation level, which is repeatable by default. MySQL is repeatable by default.
collation-server = utf8mb4_general_ci # The character set of database corresponds to some sort rules, etc. Be careful to correspond to character-set-server.
init_connect='SET NAMES utf8mb4' # Set up the character set when client connects mysql to prevent scrambling
lower_case_table_names = 1 # Is it case sensitive to sql statements, 1 means insensitive
max_connections = 400 # maximum connection
max_connect_errors = 1000 # Maximum number of false connections
explicit_defaults_for_timestamp = true # TIMESTAMP allows NULL values if no declaration NOT NULL is displayed
max_allowed_packet = 128M # The size of the SQL packet sent, if there is a BLOB object suggested to be modified to 1G
interactive_timeout = 1800 # MySQL connection will be forcibly closed after it has been idle for more than a certain period of time (in seconds)
wait_timeout = 1800 # The default value of MySQL wait_timeout is 8 hours. The interactive_timeout parameter needs to be configured concurrently to take effect.
tmp_table_size = 16M # The maximum value of interior memory temporary table is set to 128M; for example, group by, order by with large amount of data may be used as temporary table; if this value is exceeded, it will be written to disk, and the IO pressure of the system will increase.
max_heap_table_size = 128M # Defines the size of memory tables that users can create
query_cache_size = 0 # Disable mysql's cached query result set function; later test to determine whether to turn on or not based on business conditions; in most cases, close the following two items
query_cache_type = 0
# Memory settings allocated by user processes, and each session will allocate memory size for parameter settings
read_buffer_size = 2M # MySQL read buffer size. Requests for sequential table scans allocate a read buffer for which MySQL allocates a memory buffer.
read_rnd_buffer_size = 8M # Random Read Buffer Size of MySQL
sort_buffer_size = 8M # Buffer size used for MySQL execution sort
binlog_cache_size = 1M # A transaction produces a log that is recorded in Cache when it is not committed, and persists the log to disk when it needs to be committed. Default binlog_cache_size 32K
back_log = 130 # How many requests can be stored on the stack in a short time before MySQL temporarily stops responding to new requests; the official recommendation is back_log = 50 + (max_connections/5), with a cap of 900
# log setting
log_error = /usr/local/mysql/log/error.log # Database Error Log File
slow_query_log = 1 # Slow Query sql Log Settings
long_query_time = 1 # Slow query time; Slow query over 1 second
slow_query_log_file = /usr/local/mysql/log/slow.log # Slow Query Log Files
log_queries_not_using_indexes = 1 # Check sql that is not used in the index
log_throttle_queries_not_using_indexes = 5 # Represents the number of SQL statements per minute that are allowed to be logged to a slow log and are not indexed. The default value is 0, indicating that there is no limit.
min_examined_row_limit = 100 # The number of rows retrieved must reach this value before they can be recorded as slow queries. SQL that returns fewer than the rows specified by this parameter is not recorded in the slow query log.
expire_logs_days = 5 # MySQL binlog log log file saved expiration time, automatically deleted after expiration
# Master-slave replication settings
log-bin = mysql-bin # Open mysql binlog function
binlog_format = ROW # The way a binlog records content, recording each row being manipulated
binlog_row_image = minimal # For binlog_format = ROW mode, reduce the content of the log and record only the affected columns
# Innodb settings
innodb_open_files = 500 # Restrict the data of tables Innodb can open. If there are too many tables in the library, add this. This value defaults to 300
innodb_buffer_pool_size = 64M # InnoDB uses a buffer pool to store indexes and raw data, usually 60% to 70% of physical storage; the larger the settings here, the less disk I/O you need to access the data in the table.
innodb_log_buffer_size = 2M # This parameter determines the size of memory used to write log files in M. Buffers are larger to improve performance, but unexpected failures can result in data loss. MySQL developers recommend settings between 1 and 8M
innodb_flush_method = O_DIRECT # O_DIRECT reduces the conflict between the cache of the operating system level VFS and the buffer cache of Innodb itself.
innodb_write_io_threads = 4 # CPU multi-core processing capability settings are adjusted according to read-write ratio
innodb_read_io_threads = 4
innodb_lock_wait_timeout = 120 # InnoDB transactions can wait for a locked timeout second before being rolled back. InnoDB automatically detects transaction deadlocks and rolls back transactions in its own lock table. InnoDB notices the lock settings with the LOCK TABLES statement. The default value is 50 seconds.
innodb_log_file_size = 32M # This parameter determines the size of the data log file. Larger settings can improve performance, but also increase the time required to recover the failed database.7.进入/usr/local/mysql/bin目录,执行初始化操作。如果有问题大概率是没有权限造成的。在初始化完成之后。会生成一个临时登入密码。这个密码会在/log/error.log文件中给出。使用grep指令进行查找。你会看到第三条那样的语句。后面的就是临时密码。
sudo ./mysqld --initialize --user=mysql
sudo cat /usr/local/mysql/log/error.log | grep temporary
[Note] A temporary password is generated for root@localhost: eIHS<*EPp3!7
8.将mysql设置为开机自动启动。
cp ./support-files/mysql.server /etc/rc.d/init.d/mysqld:将 MySQL 的启动脚本 mysql.server 复制到系统资源目录下的 /etc/rc.d/init.d/mysqld。这样做是为了将 MySQL 服务添加到系统服务中,以便可以通过系统服务管理工具进行启动、停止和重启操作。
chmod +x /etc/rc.d/init.d/mysqld:赋予 /etc/rc.d/init.d/mysqld 脚本执行权限,使其可以作为一个可执行文件。
chkconfig --add mysql:将 mysqld 服务添加到系统服务列表中,以便在系统启动时自动启动 MySQL。
chkconfig --list mysqld:检查是否成功添加了 mysqld 服务,并列出当前系统中的服务及其启动状态。
service mysqld start:启动 MySQL 服务。
service mysqld status:查看 MySQL 服务的运行状态。
ps aux|grep mysql:查看与 MySQL 相关的进程信息,使用 grep 过滤出包含 "mysql" 关键字的进程。
service mysqld restart重新启动 MySQL 服务。
cd /usr/local/mysql
cp ./support-files/mysql.server /etc/rc.d/init.d/mysqld
chmod +x /etc/rc.d/init.d/mysqld
chkconfig --add mysqld
chkconfig --list mysqld
service mysqld start
service mysqld status
ps aux|grep mysql
service mysqld restart9. 添加环境变量
vim /etc/profile
//在最后一行添加 export PATH=$PATH:/usr/local/mysql/bin
//使更改立即生效
source /etc/profile
10.登入mysql,使用第七步中找到的临时密码进行登入。重新设置密码为root。再允许用户 'root' 从任意主机连接到 MySQL 服务器。mysql的安装配置就大致完成了。
mysql -uroot -p
set password for root@localhost=password("root");
mysql> use mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> update user set host='%' where user='root';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0在安装好mysql之后,写一个简单的登入测试程序。使用开发框架中提供的数据库操作类。运行后如果没有任何反应说明程序运行成功。需要注意的是,在运行程序之前需要指定库文件的搜索路径。
[sxixia@localhost c_project]$ sudo vim ~/.bashrc
// 添加下面两行,路径改成自己的路径
LD_LIBRARY_PATH=/usr/local/mysql/lib:/usr/lib:/project/public:.
OLDPWD=/home/sxixia
5.3数据库操作函数
程序的位置:/project/public/db/mysql1
示例makefile文件:
#开发框架头文件路径
PUBINCL = -I/project/public
#mysql头文件存放的目录
MYSQLINCL = -I/usr/local/mysql/include -I/project/public/db/mysql
#mysql库文件存放目录
MYSQLLIB = -L/usr/local/mysql/lib
#开发框架cpp文件,直接包含进来,没有采用链接库,是为了方便调试
PUBCPP = /project/public/_public.cpp
#开发框架mysql的cpp文件,直接包含进来,没有采用链接库,是为了方便调试
MYSQLCPP = /project/public/db/mysql/_mysql.cpp
#需要链接的mysql库
MYSQLLIBS = -lmysqlclient
CFLAGS=-g -Wno-write-strings
all:obtcodetodb obtmindtodb
obtcodetodb:obtcodetodb.cpp
g++ $(CFLAGS) -o obtcodetodb obtcodetodb.cpp $(PUBINCL) $(PUBCPP) $(MYSQLINCL) $(MYSQLLIB) $(MYSQLLIBS) $(MYSQLCPP) -lm -lc
cp obtcodetodb ../bin/.
obtmindtodb:obtmindtodb.cpp idcapp.h idcapp.cpp
g++ $(CFLAGS) -o obtmindtodb obtmindtodb.cpp $(PUBINCL) $(PUBCPP) $(MYSQLINCL) $(MYSQLLIB) $(MYSQLLIBS) $(MYSQLCPP) idcapp.cpp -lm -lc
cp obtmindtodb ../bin/.
clean:
rm obtcodetodb obtmindtodb5.3.1登入数据库
#include "_mysql.h"
int main(int argc,char *argv[])
{
connection conn;
if(conn.connecttodb("192.168.211.128,root,root,mysql,3306","utf8")!=0)
{
printf("failed.\n%s\n",conn.m_cda.message);
return -1;
}
return 0;
}
//makefile文件部分内容
#mysql头文件存放的目录
MYSQLINCL = -I/usr/local/mysql/include
#mysql库文件存放目录
MYSQLLIB = -L/usr/local/mysql/lib
#需要链接的mysql库
MYSQLLIBS = -lmysqlclient
PUBINCL = -I/project/public/db/mysql
PUBCPP = /project/public/db/mysql/_mysql.cpp
CFLAGS=-g -Wno-write-strings
mysql:mysql.cpp
g++ $(CFLAGS) -o mysql mysql.cpp $(MYSQLINCL) $(MYSQLLIB) $(MYSQLLIBS) $(PUBCPP) $(PUBINCL) -lm -lc
在这个程序中,connection类是用来连接登入数据库的。connecttodb()函数第一个参数为一个字符串,使用" , "进行分割,分别是ip,用户名,密码,使用的数据库,端口。第二个参数是字符集,第三个参数为是否采用自动提交,缺省为不采用。
5.3.2创建表程序
#include "_mysql.h" // 开发框架操作MySQL的头文件。
int main(int argc,char *argv[])
{
connection conn; // 数据库连接类。
// 登录数据库,返回值:0-成功;其它是失败,存放了MySQL的错误代码。
// 失败代码在conn.m_cda.rc中,失败描述在conn.m_cda.message中。
if (conn.connecttodb("127.0.0.1,root,root,ltbo,3306","utf8")!=0)
{
printf("connect database failed.\n%s\n",conn.m_cda.message); return -1;
}
sqlstatement stmt(&conn); // 操作SQL语句的对象。
// 准备创建表的SQL语句。
// 卡比表girls,卡比编号id,卡比姓名name,体重weight,报名时间btime,卡比说明memo,卡比图片pic。
stmt.prepare("create table girls(id bigint(10) AUTO_INCREMENT,\
name varchar(30),\
weight decimal(8,2),\
btime datetime,\
memo longtext,\
pic longblob,\
primary key (id))");
/*
1、int prepare(const char *fmt,...),SQL语句可以多行书写。
2、SQL语句最后的分号可有可无,建议不要写(兼容性考虑)。
3、SQL语句中不能有说明文字。
4、可以不用判断stmt.prepare()的返回值,stmt.execute()时再判断。
*/
// 执行SQL语句,一定要判断返回值,0-成功,其它-失败。
// 失败代码在stmt.m_cda.rc中,失败描述在stmt.m_cda.message中。
if(stmt.execute()!=0)
{
printf("stmt.execute()
failed.\n%s\n%d\n%s\n",stmt.m_sql,stmt.m_cda.rc,stmt.m_cda.message);
return -1;
}
printf("create table girls ok.\n");
return 0;
}
stmt.m_sql存放了SQL语句的文本,最长不能超过10240字节。
stmt.m_cda.rc存放了MySQL的错误代码.
stmt.m_cda.message存放了错误描述信息。
5.3.3插入数据程序
#include "_mysql.h"
int main(int argc,char *argv[])
{
connection conn;
if(conn.connecttodb("127.0.0.1,root,root,ltbo,3306","utf8")!=0)
{
printf("failed.\n%s\n",conn.m_cda.message);
return -1;
}
//定义一个结构体存放数据
struct st_girls
{
long id;
char name[31];
double weight;
char btime[20];
}stgirls;
//sqlstatement stmt(&conn);
//绑定数据库连接的无参构造,上一句为调用有参构造。一个效果
sqlstatement stmt;
stmt.connect(&conn);
//预处理sql语句,values里面的内容为参数绑定的形式
stmt.prepare("\
insert into girls(id,name,weight,btime) values(:1,:2,:3,str_to_date(:4,'%%Y-%%m-%%d %%H:%%i:%%s'))");
//insert into girls(id,name,weight,btime) values(?+1,?,?+45.35,to_date(?,'yyyy-mm-dd hh24:mi:ss'))");
/*
注意事项:
1、参数的序号从1开始,连续、递增,参数也可以用问号表示,但是,问号的兼容性不好,不建议;
2、SQL语句中的右值才能作为参数,表名、字段名、关键字、函数名等都不能作为参数;
3、参数可以参与运算或用于函数的参数;
4、如果SQL语句的主体没有改变,只需要prepare()一次就可以了;
5、SQL语句中的每个参数,必须调用bindin()绑定变量的地址;
6、如果SQL语句的主体已改变,prepare()后,需重新用bindin()绑定变量;
7、prepare()方法有返回值,一般不检查,如果SQL语句有问题,调用execute()方法时能发现;
8、bindin()方法的返回值固定为0,不用判断返回值;
9、prepare()和bindin()之后,每调用一次execute(),就执行一次SQL语句,SQL语句的数据来自被绑定变量的值。
*/
//绑定变量地址
stmt.bindin(1,&stgirls.id);
stmt.bindin(2, stgirls.name,30);
stmt.bindin(3,&stgirls.weight);
stmt.bindin(4, stgirls.btime,19);
// 绑定输入变量的地址。
// position:字段的顺序,从1开始,必须与prepare方法中的SQL的序号一一对应。
// value:输入变量的地址,如果是字符串,内存大小应该是表对应的字段长度加1。
// len:如果输入变量的数据类型是字符串,用len指定它的最大长度,建议采用表对应的字段长度。
// 返回值:0-成功,其它失败,程序中一般不必关心返回值。
// 注意:1)如果SQL语句没有改变,只需要bindin一次就可以了,2)绑定输入变量的总数不能超过MAXPARAMS个。
for(int ii=0;ii<5;ii++)
{
memset(&stgirls,0,sizeof(struct st_girls));
stgirls.id = ii+1;
sprintf(stgirls.name,"卡比%05dabcde",ii+1);
stgirls.weight = 99.45+ii;
sprintf(stgirls.btime,"2023-05-20 21:37:%02d",ii);
if(stmt.execute()!=0)
{
printf("stmt.execute() failed.\n%s\n%d\n%s\n",stmt.m_sql,stmt.m_cda.rc,stmt.m_cda.message);
return -1;
}
printf("成功插入了%ld条记录。\n",stmt.m_cda.rpc);
}
printf("insert table grils ok.\n");
conn.commit();//提交
return 0;
}
mysql> select * from girls;
+----+------------------+--------+---------------------+------+------+
| id | name | weight | btime | memo | pic |
+----+------------------+--------+---------------------+------+------+
| 1 | 卡比00001abcde | 99.45 | 2023-05-20 21:37:00 | NULL | NULL |
| 2 | 卡比00002abcde | 100.45 | 2023-05-20 21:37:01 | NULL | NULL |
| 3 | 卡比00003abcde | 101.45 | 2023-05-20 21:37:02 | NULL | NULL |
| 4 | 卡比00004abcde | 102.45 | 2023-05-20 21:37:03 | NULL | NULL |
| 5 | 卡比00005abcde | 103.45 | 2023-05-20 21:37:04 | NULL | NULL |
+----+------------------+--------+---------------------+------+------+
5 rows in set (0.00 sec)
需要对下面这句话进行一些说明:stmt.prepare("\
insert into girls(id,name,weight,btime) values(:1,:2,:3,str_to_date(:4,'%%Y-%%m-%%d %%H:%%i:%%s'))");
这句代码是一个插入语句的示例,用于将数据插入到名为 "girls" 的表中。
插入的字段包括 "id"、"name"、"weight" 和 "btime",它们对应的值是 ":1"、":2"、":3" 和 "str_to_date(:4,'%Y-%m-%d %H:%i:%s')"。其中,":1"、":2" 和 ":3" 是绑定变量的占位符,而 "str_to_date(:4,'%Y-%m-%d %H:%i:%s')" 是一个函数调用,用于将字符串转换为日期时间类型。
具体插入的数据要根据实际情况进行绑定和赋值,例如使用预处理语句和参数绑定的方式。这样可以避免 SQL 注入攻击,并提高代码的可读性和维护性。需要根据实际数据库和编程语言的情况,使用相应的库函数或语法来执行这条插入语句,并将正确的值绑定到占位符中。
在数据库开发中,使用预处理语句和参数绑定是一种良好的实践,被广泛应用于许多数据库操作框架和编程语言中。这种方式的优点包括:
1.防止 SQL 注入攻击:通过使用参数绑定,可以确保用户输入的数据不会直接插入到 SQL 语句中,从而防止恶意用户利用输入来执行恶意的 SQL 代码。
2.提高性能:预处理语句可以在数据库服务器中进行编译和缓存,避免每次执行都进行解析和优化,从而提高执行效率。
3.提高代码可读性和维护性:使用占位符和参数绑定可以使 SQL 语句更清晰,易于理解和维护,同时减少字符串拼接和转义的复杂性。
4.数据类型安全:通过参数绑定,可以确保传递给数据库的数据与表中定义的数据类型相匹配,避免数据类型转换错误和潜在的数据损坏。
因此,预处理语句和参数绑定是数据库开发中推荐的做法,尤其是在处理动态生成的 SQL 语句、用户输入以及需要执行多次的查询和更新操作时,更加重要和有益。
%Y-%m-%d %H:%i:%s是日期时间的格式字符串,它指定了字符串的日期时间格式。%Y表示四位数的年份,%m表示两位数的月份,%d表示两位数的日期,%H表示两位数的小时,%i表示两位数的分钟,%s表示两位数的秒数。str_to_date函数将字符串转换为与指定格式匹配的日期时间类型的值。
5.3.4修改表程序
修改表内容的程序与插入没有什么太大区别,主要稍微修改一下sql语句代码就可以了。
stmt.prepare("\
update girls set name=:1,weight=:2,btime=str_to_date(:3,'%%Y-%%m-%%d %%H:%%i:%%s') where id=:4");
stmt.bindin(1, stgirls.name,30);
stmt.bindin(2,&stgirls.weight);
stmt.bindin(3, stgirls.btime,19);
stmt.bindin(4,&stgirls.id);
mysql> select * from girls;
+----+--------------------+--------+---------------------+------+------+
| id | name | weight | btime | memo | pic |
+----+--------------------+--------+---------------------+------+------+
| 1 | 皮卡丘00001gril | 30.25 | 2023-05-22 09:10:00 | NULL | NULL |
| 2 | 皮卡丘00002gril | 31.25 | 2023-05-22 09:10:01 | NULL | NULL |
| 3 | 皮卡丘00003gril | 32.25 | 2023-05-22 09:10:02 | NULL | NULL |
| 4 | 皮卡丘00004gril | 33.25 | 2023-05-22 09:10:03 | NULL | NULL |
| 5 | 皮卡丘00005gril | 34.25 | 2023-05-22 09:10:04 | NULL | NULL |
+----+--------------------+--------+---------------------+------+------+
5 rows in set (0.00 sec)
5.3.5查询数据程序
需要注意的是,在执行SQL查询语句后,会返回数据集合,即结果集,结果集是由满足查询条件的行和对应的列组成的。bindout()函数用于将结果集和变量的地址进行绑定。next()函数用于从结果集中获取一条记录。返回值:0-成功,1403-结果集已无记录。在换行书写sql语句时,不能使用TAB键,只能用空格键,否则将导致sql语句识别不出来。
#include "_mysql.h"
int main(int argc,char *argv[])
{
connection conn;
if(conn.connecttodb("127.0.0.1,root,root,ltbo,3306","utf8")!=0)
{
printf("failed.\n%s\n",conn.m_cda.message);
return -1;
}
struct st_girls
{
long id;
char name[31];
double weight;
char btime[20];
}stgirls;
sqlstatement stmt(&conn);
int iminid,imaxid; // 查询条件最小和最大的id。
stmt.prepare("\
select id,name,weight,date_format(btime,'%%Y-%%m-%%d %%H:%%i:%%s') from girls where id>=:1 and id<=:2");
stmt.bindin(1,&iminid);
stmt.bindin(2,&imaxid);
stmt.bindout(1,&stgirls.id);
stmt.bindout(2, stgirls.name,30);
stmt.bindout(3,&stgirls.weight);
stmt.bindout(4, stgirls.btime,19);
iminid=1; // 指定待查询记录的最小id的值。
imaxid=3; // 指定待查询记录的最大id的值。
/*
注意事项:
1、如果SQL语句的主体没有改变,只需要prepare()一次就可以了;
2、结果集中的字段,调用bindout()绑定变量的地址;
3、bindout()方法的返回值固定为0,不用判断返回值;
4、如果SQL语句的主体已改变,prepare()后,需重新用bindout()绑定变量;
5、调用execute()方法执行SQL语句,然后再循环调用next()方法获取结果集中的记录;
6、每调用一次next()方法,从结果集中获取一条记录,字段内容保存在已绑定的变量中。
*/
if(stmt.execute()!=0)
{
printf("stmt.execute() failed.\n%s\n%d\n%s\n",stmt.m_sql,stmt.m_cda.rc,stmt.m_cda.message);
return -1;
}
while(true)
{
memset(&stgirls,0,sizeof(struct st_girls));
//从结果集中获取一条记录,需要判断返回值,0-成功,1403-无记录,其他-失败
if(stmt.next()!=0) break;
printf("id=%ld,name=%s,weight=%.02f,btime=%s\n",stgirls.id,stgirls.name,stgirls.weight,stgirls.btime);
}
// rpc保存了SQL语句执行后影响的记录数。
printf("本次查询了girls表%ld条记录。\n",stmt.m_cda.rpc);
return 0;
}5.3.6删除数据程序
删除表记录的程序也很简单,更改一下sql语句。由于没有结果集,在查询程序的基础上删除一些结果集相关代码,加上提交事务的代码就行。
stmt.prepare("delete from girls where id>=:1 and id<=:2");
...
conn.commit();
[sxixia@localhost mysql1]$ ./deletetable
本次删除了girls表3条记录。
mysql> select * from girls;
+----+--------------------+--------+---------------------+------+------+
| id | name | weight | btime | memo | pic |
+----+--------------------+--------+---------------------+------+------+
| 4 | 皮卡丘00004gril | 33.25 | 2023-05-22 09:10:03 | NULL | NULL |
| 5 | 皮卡丘00005gril | 34.25 | 2023-05-22 09:10:04 | NULL | NULL |
+----+--------------------+--------+---------------------+------+------+
2 rows in set (0.00 sec)
5.3.7向数据库中存入二进制文件
数据库的二进制对象(Binary Object)是指在数据库中存储二进制数据的一种类型。二进制对象可以包含任意类型的二进制数据,例如图像、音频、视频、文档等。
二进制对象通常以二进制形式存储在数据库表的列中。这些列的数据类型通常称为BLOB(Binary Large Object)或者BINARY,具体名称和定义可能因数据库管理系统而异。
我要向数据库中存入两张图片进行测试。随意准备两张图片命名为"1.jpg"和"2.jpg"放在和程序的同一个目录下。图片不要太大就好。不然数组会设置得很大。
//更改结构体
struct st_girls
{
long id; //编号
char pic[2000000]; //图片内容
unsigned long picsize; //图片内容占用字节数
}stgirls;
//修改sql语句
stmt.prepare("\
update girls set pic=:1 where id=:2");
//由于pic字段的类型是longblob类型,bindinlob()函数用于绑定该类型的变量。
//参数为字段顺序,字段内容,字段大小
stmt.bindinlob(1, stgirls.pic,&stgirls.picsize);
stmt.bindin(2,&stgirls.id);
//filetobuf()函数把文件filename加载到buffer中,必须确保buffer足够大。
//参数1为filename,使用全路径,这里放在了同一个目录下。参数2为buffer。
//函数返回值为文件的大小
for(int ii=1;ii<3;ii++)
{
memset(&stgirls,0,sizeof(struct st_girls));
stgirls.id = ii;
//把图片内容加载到pic中
if (ii==1) stgirls.picsize = filetobuf("1.jpg",stgirls.pic);
if (ii==2) stgirls.picsize = filetobuf("2.jpg",stgirls.pic);
if(stmt.execute()!=0)
{
printf("stmt.execute() failed.\n%s\n%d\n%s\n",stmt.m_sql,stmt.m_cda.rc,stmt.m_cda.message);
return -1;
}运行以后如果直接在mysql上使用查询语句会显示出乱码。我们使用navicat软件来连接数据库进行查看。我的navicat安装在本机上,如果要连接虚拟机的数据库。需要在防火墙上开通3306端口。 在安装mysql数据库时已经设置过允许远程连接,所以这里我只需要开通一下端口即可。关于navicat软件如何使用不作解释。查询到的结果如下:
开通端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent
重新加载防火墙配置
firewall-cmd --reload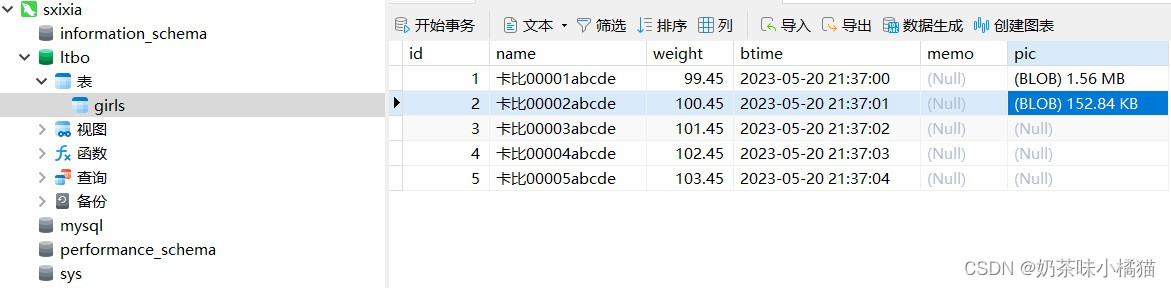
选中图片字段右击选择保存数据为,就可以将数据库中的图片取出来。我们再写一个程序将存入的二进制文件取出来。
stmt.prepare("select id,pic from girls where id in(1,2)");
//把结果集的字段与变量的地址绑定。
stmt.bindout(1,&stgirls.id);
stmt.bindoutlob(2,stgirls.pic,2000000,&stgirls.picsize);
if(stmt.execute()!=0)
{
printf("stmt.execute() failed.\n%s\n%d\n%s\n",stmt.m_sql,stmt.m_cda.rc,stmt.m_cda.message);
return -1;
}
while(true)
{
memset(&stgirls,0,sizeof(struct st_girls));
//从结果集中获取记录
if(stmt.next()!=0) break;
//生成文件名
char filename[101]; memset(filename,0,sizeof(filename));
sprintf(filename,"%d_out.jpg",stgirls.id);
//把内容写入文件
buftofile(filename,stgirls.pic,stgirls.picsize);
} 
实际上 二进制大对象占用的磁盘空间很大,对数据库会造成很大压力。所以不要把大量的二进制大对象存入数据库。通常情况下采用将文件放入磁盘中,把文件路径,文件名等信息存放在数据库内的方法。
5.4将站点参数入库
程序名为/project/idc1/c/obtcodetodb.cpp
在我们学习了数据库的基本使用以后,我们将第二章的站点参数文件,以及利用随机数生成的测试数据文件写入数据库。首先我们使用工具创建站点参数表,表名为t_zhobtcode,表的结构如下,字符集选用utf8。对比第二章的程序,增添了最后两项。

还有一个需要注意的地方是关于字段lat和lon,在程序中使用的类型是浮点数类型,而在数据库中却使用的是整数类型。这是因为整数类型更好操控,存储空间更小,运算效率更高。例如银行数据库中余额如果是1.25元,那么存储的数据是125分。
那么整个程序的流程是这样子的。也可以不需要将全国站点参数文件加载到容器中,直接打开文件一行一行进行处理。这只是程序的一种实现方法。连接数据库应该放在加载参数文件之后,如果参数文件没能加载成功,那么就不需要进行数据库的连接了。判断记录已存在的方法是判断插入sql语句的返回结果,如果记录已存在,返回1062。
#include "_public.h"
#include "_mysql.h"
int main(int argc,char *argv[])
{
// 帮助文档
// 处理程序退出的信号
// 打开日志文件
// 把全国站点参数文件加载到vstcode容器中
// 连接数据库
// 准备插入表的sql语句
// 准备更新表的sql语句
// 遍历vstcode容器
for (int ii=0;ii<vstcode.size();ii++)
{
// 从容器中取出一条记录到结构体stcode中
// 执行插入的sql语句
// 如果记录已经存在,就执行更新的sql语句
}
// 提交事务
return 0;
}
把 站点文件加载到结构体的函数,注意,纬度,经度,海拔高度已经被修改为字符数组类型。在程序中使用char类型来操作会更加方便,因为数据文件都是含有其他符号的,我们需要对文件进行一行一行的拆分。拆分掉一些符号,标志符等。
vector<struct st_stcode> vstcode; // 存放全国气象站点参数的容器。
struct st_stcode // 全国气象站点参数结构体。
{
char provname[31]; // 省
char obtid[11]; // 站号
char cityname[31]; // 站名
char lat[11]; // 纬度
char lon[11]; // 经度
char height[11]; // 海拔高度
};
// 把站点参数文件中加载到vstcode容器中。
bool LoadSTCode(const char *inifile)
{
CFile File;
// 打开站点参数文件。
if (File.Open(inifile,"r")==false)
{
logfile.Write("File.Open(%s) failed.\n",inifile); return false;
}
char strBuffer[301];
CCmdStr CmdStr;
struct st_stcode stcode;
while (true)
{
// 从站点参数文件中读取一行,如果已读取完,跳出循环。
if (File.Fgets(strBuffer,300,true)==false) break;
// 把读取到的一行拆分。
CmdStr.SplitToCmd(strBuffer,",",true);
if (CmdStr.CmdCount()!=6) continue; // 扔掉无效的行。
// 把站点参数的每个数据项保存到站点参数结构体中。
memset(&stcode,0,sizeof(struct st_stcode));
CmdStr.GetValue(0, stcode.provname,30); // 省
CmdStr.GetValue(1, stcode.obtid,10); // 站号
CmdStr.GetValue(2, stcode.cityname,30); // 站名
CmdStr.GetValue(3, stcode.lat,10); // 纬度
CmdStr.GetValue(4, stcode.lon,10); // 经度
CmdStr.GetValue(5, stcode.height,10); // 海拔高度
// 把站点参数结构体放入站点参数容器。
vstcode.push_back(stcode);
}
/*
for (int ii=0;ii<vstcode.size();ii++)
logfile.Write("provname=%s,obtid=%s,cityname=%s,lat=%.2f,lon=%.2f,height=%.2f\n",\
vstcode[ii].provname,vstcode[ii].obtid,vstcode[ii].cityname,vstcode[ii].lat,\
vstcode[ii].lon,vstcode[ii].height);
*/
return true;
}
全部代码
#include "_public.h"
#include "_mysql.h"
CLogFile logfile; //日志类
connection conn; //数据库连接类
CPActive PActive; //心跳类
vector<struct st_stcode> vstcode; // 存放全国气象站点参数的容器。
struct st_stcode // 全国气象站点参数结构体。
{
char provname[31]; // 省
char obtid[11]; // 站号
char cityname[31]; // 站名
char lat[11]; // 纬度
char lon[11]; // 经度
char height[11]; // 海拔高度
};
void _help();
bool LoadSTCode(const char *inifile); // 把站点参数文件中加载到vstcode容器中。
void EXIT(int sig);
int main(int argc,char *argv[])
{
// 帮助文档
if (argc!=5) { _help(); return -1; }
// 处理程序退出的信号
CloseIOAndSignal(); signal(SIGINT,EXIT); signal(SIGTERM,EXIT);
// 打开日志文件
if(logfile.Open(argv[4],"a+")==false)
{
printf("打开日志文件失败(%s)。\n",argv[4]);
return -1;
}
PActive.AddPInfo(10,"obtcodetodb"); // 进程的心跳,10秒足够。
// 把全国站点参数文件加载到vstcode容器中
if (LoadSTCode(argv[1])==false) return -1;
logfile.Write("加载参数文件(%s)成功,站点数(%d)。\n",argv[1],vstcode.size());
// 连接数据库
if(conn.connecttodb(argv[2],argv[3])!=0)
{
logfile.Write("connect database(%s) failed.\n%s\n",argv[2],conn.m_cda.message);
return -1;
}
logfile.Write("connect database(%s) ok.\n",argv[2]);
struct st_stcode stcode;
// 准备插入表的sql语句
sqlstatement stmtins(&conn);
stmtins.prepare("insert into T_ZHOBTCODE(obtid,cityname,provname,lat,lon,height,upttime) values(:1,:2,:3,:4*100,:5*100,:6*10,now())");
stmtins.bindin(1,stcode.obtid,10);
stmtins.bindin(2,stcode.cityname,30);
stmtins.bindin(3,stcode.provname,30);
stmtins.bindin(4,stcode.lat,10);
stmtins.bindin(5,stcode.lon,10);
stmtins.bindin(6,stcode.height,10);
// 准备更新表的sql语句
sqlstatement stmtupt(&conn);
stmtupt.prepare("update T_ZHOBTCODE set cityname=:1,provname=:2,lat=:3*100,lon=:4*100,height=:5*10,upttime=now() where obtid=:6");
stmtupt.bindin(1,stcode.cityname,30);
stmtupt.bindin(2,stcode.provname,30);
stmtupt.bindin(3,stcode.lat,10);
stmtupt.bindin(4,stcode.lon,10);
stmtupt.bindin(5,stcode.height,10);
stmtupt.bindin(6,stcode.obtid,10);
int inscount=0,uptcount=0;
CTimer Timer; //定时器类,精确到微秒。构造方法会调用Start方法开始计时,调用Timer.Elapsed()方法后会结束计时并重新开始计时、
// 遍历vstcode容器
for (int ii=0;ii<vstcode.size();ii++)
{
// 从容器中取出一条记录到结构体stcode中
memcpy(&stcode,&vstcode[ii],sizeof(struct st_stcode));
// 执行插入的sql语句
if(stmtins.execute()!=0)
{
//如果记录已经存在,就执行更新的sql语句
if(stmtins.m_cda.rc==1062)
{
if(stmtupt.execute()!=0)
//如果执行更新失败
{
logfile.Write("stmtupt.execute() faild.\n%s\n%s\n",stmtupt.m_sql,stmtupt.m_cda.message);
return -1;
}
else
{
uptcount++;
}
}
else
{
//如果执行插入语句失败
logfile.Write("stmtins.execute() failed.\n%s\n%s\n",stmtins.m_sql,stmtins.m_cda.message);
return -1;
}
}
else
inscount++;
}
// 把总记录数、插入记录数、更新记录数、消耗时长记录日志。
logfile.Write("总记录数=%d,插入=%d,更新=%d,耗时=%.2f秒。\n",vstcode.size(),inscount,uptcount,Timer.Elapsed());
// 提交事务
conn.commit();
return 0;
}
void _help()
{
printf("\n");
printf("Using:./obtcodetodb inifile connstr charset logfile\n");
printf("Example:/project/tools1/bin/procctl 120 /project/idc1/bin/obtcodetodb /project/idc/ini/stcode.ini \"127.0.0.1,root,root,ltbo,3306\" utf8 /log/idc/obtcodetodb.log\n\n");
printf("本程序用于把全国站点参数数据保存到数据库表中,如果站点不存在则插入,站点已存在则更新。\n");
printf("inifile 站点参数文件名(全路径)。\n");
printf("connstr 数据库连接参数:ip,username,password,dbname,port\n");
printf("charset 数据库的字符集。\n");
printf("logfile 本程序运行的日志文件名。\n");
printf("程序每120秒运行一次,由procctl调度。\n\n\n");
}
// 把站点参数文件中加载到vstcode容器中。
bool LoadSTCode(const char *inifile)
{
CFile File;
// 打开站点参数文件。
if (File.Open(inifile,"r")==false)
{
logfile.Write("File.Open(%s) failed.\n",inifile); return false;
}
char strBuffer[301];
CCmdStr CmdStr;
struct st_stcode stcode;
while (true)
{
// 从站点参数文件中读取一行,如果已读取完,跳出循环。
if (File.Fgets(strBuffer,300,true)==false) break;
// 把读取到的一行拆分。
CmdStr.SplitToCmd(strBuffer,",",true);
if (CmdStr.CmdCount()!=6) continue; // 扔掉无效的行。
// 把站点参数的每个数据项保存到站点参数结构体中。
memset(&stcode,0,sizeof(struct st_stcode));
CmdStr.GetValue(0, stcode.provname,30); // 省
CmdStr.GetValue(1, stcode.obtid,10); // 站号
CmdStr.GetValue(2, stcode.cityname,30); // 站名
CmdStr.GetValue(3, stcode.lat,10); // 纬度
CmdStr.GetValue(4, stcode.lon,10); // 经度
CmdStr.GetValue(5, stcode.height,10); // 海拔高度
// 把站点参数结构体放入站点参数容器。
vstcode.push_back(stcode);
}
/*
for (int ii=0;ii<vstcode.size();ii++)
logfile.Write("provname=%s,obtid=%s,cityname=%s,lat=%.2f,lon=%.2f,height=%.2f\n",\
vstcode[ii].provname,vstcode[ii].obtid,vstcode[ii].cityname,vstcode[ii].lat,\
vstcode[ii].lon,vstcode[ii].height);
*/
return true;
}
void EXIT(int sig)
{
logfile.Write("程序退出,sig=%d\n\n",sig);
conn.disconnect();
exit(0);
}5.5将测试数据入库
本程序名为/project/idc1/c/obtmindtodb.cpp。分阶段完成。
在完成了将站点参数的数据入库以后,下一个程序要完成将站点没分钟生成的测试数据入库。使用Power Designer来设计表。软件如何使用请自行学习。
常规设置,对于观测数据为什么没有更新和删除操作。这很好理解。该表的数据来源于传感器的采集。(目前来源于随机生成)采集到的数据无论是否有异常都只需要保存下来以便分析。对于异常数据的操作在别的部分去完成。
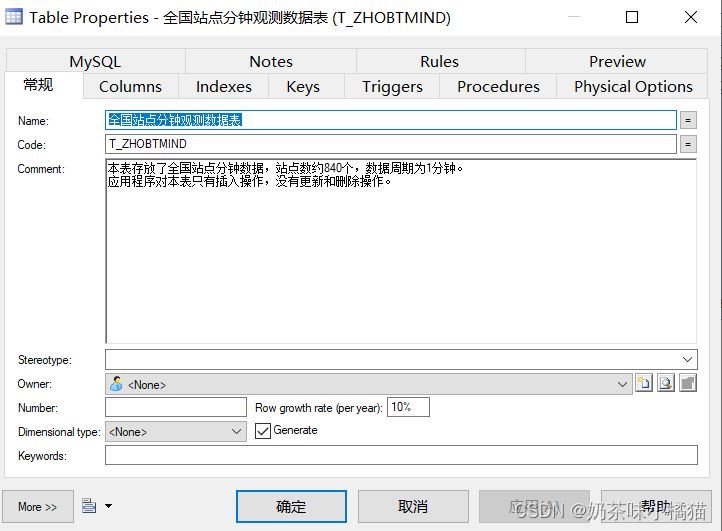
字段,还是使用int类型来存放浮点数数据。原因在上一节作过说明。
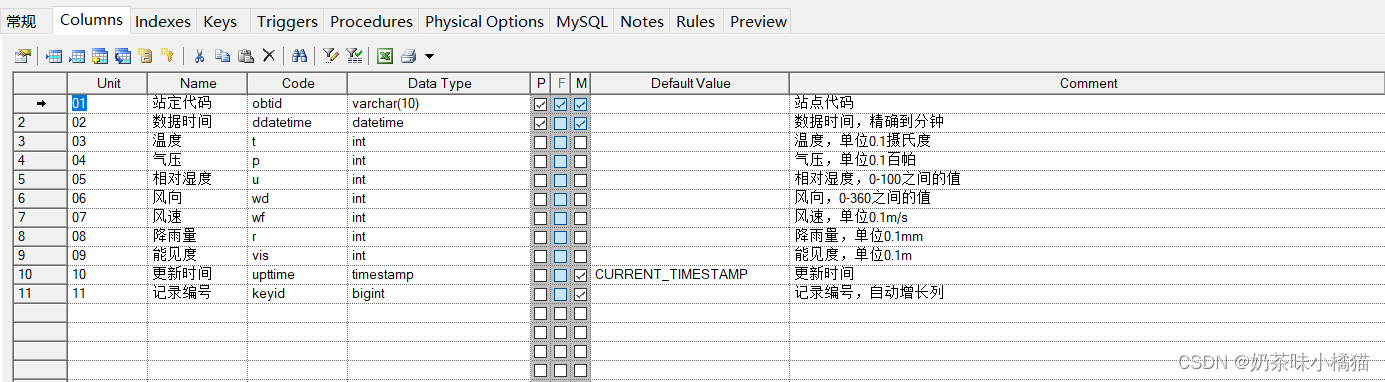 索引,索引一的顺序不能弄反。当查询语句为select * from student where obtid=:1 and ddatetime=:2时,利用的是主键进行查询。当查询语句为select * from student where ddatetime=:1 and obtid=:2时,利用的是索引来进行查询。
索引,索引一的顺序不能弄反。当查询语句为select * from student where obtid=:1 and ddatetime=:2时,利用的是主键进行查询。当查询语句为select * from student where ddatetime=:1 and obtid=:2时,利用的是索引来进行查询。
 键,需要键自增列设置为键,不一定是主键或者外键等,但是一定要是键。
键,需要键自增列设置为键,不一定是主键或者外键等,但是一定要是键。

两张表总体结构。
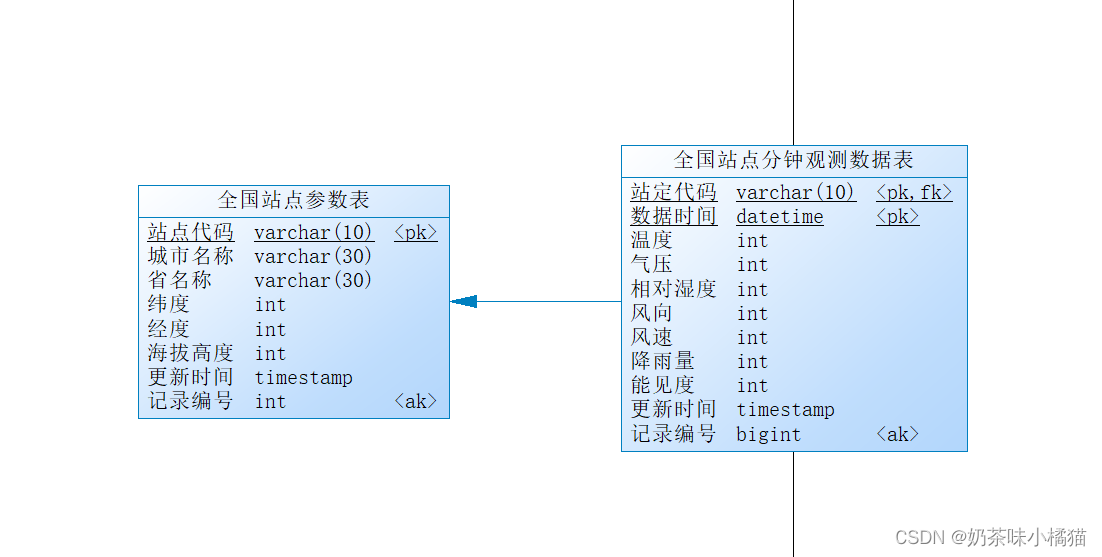
点击数据库-生成数据库可以得到sql代码。整个模型的sql语句如下:
drop index IDX_ZHOBTMIND_3 on T_ZHOBTMIND;
drop index IDX_ZHOBTMIND_2 on T_ZHOBTMIND;
drop index IDX_ZHOBTMIND_1 on T_ZHOBTMIND;
drop table if exists T_ZHOBTMIND;
/*==============================================================*/
/* Table: T_ZHOBTMIND */
/*==============================================================*/
create table T_ZHOBTMIND
(
obtid varchar(10) not null comment '站点代码',
ddatetime datetime not null comment '数据时间,精确到分钟',
t int comment '温度,单位0.1摄氏度',
p int comment '气压,单位0.1百帕',
u int comment '相对湿度,0-100之间的值',
wd int comment '风向,0-360之间的值',
wf int comment '风速,单位0.1m/s',
r int comment '降雨量,单位0.1mm',
vis int comment '能见度,单位0.1m',
upttime timestamp not null default CURRENT_TIMESTAMP comment '更新时间',
keyid bigint not null auto_increment comment '记录编号,自动增长列',
primary key (obtid, ddatetime),
key AK_ZHOBTMIND_KEYID (keyid)
);
alter table T_ZHOBTMIND comment '本表存放了全国站点分钟数据,站点数约840个,数据周期为1分钟。
应用程序对本表只有插入操作,没有更新和删除';
/*==============================================================*/
/* Index: IDX_ZHOBTMIND_1 */
/*==============================================================*/
create unique index IDX_ZHOBTMIND_1 on T_ZHOBTMIND
(
ddatetime,
obtid
);
/*==============================================================*/
/* Index: IDX_ZHOBTMIND_2 */
/*==============================================================*/
create index IDX_ZHOBTMIND_2 on T_ZHOBTMIND
(
ddatetime
);
/*==============================================================*/
/* Index: IDX_ZHOBTMIND_3 */
/*==============================================================*/
create index IDX_ZHOBTMIND_3 on T_ZHOBTMIND
(
obtid
);
alter table T_ZHOBTMIND add constraint FK_FK_ZHOBTCODE_ZHOBTMIND foreign key (obtid)
references T_ZHOBTCODE (obtid) on delete restrict on update restrict;
回到程序,先看帮助文档以及处理业务的函数主流程。
void _help()
{
printf("\n");
printf("Using:./obtcodetodb inifile connstr charset logfile\n");
printf("Example:/project/tools1/bin/procctl 120 /project/idc1/bin/obtcodetodb /project/idc/ini/stcode.ini \"127.0.0.1,root,root,ltbo,3306\" utf8 /log/idc/obtcodetodb.log\n\n");
printf("本程序用于把全国站点分钟观测数据保存到数据库的T_ZHOBTMIND表中,数据只插入,不更新。\n");
printf("pathname 全国站点分钟观测数据文件存放的目录。\n");
printf("connstr 数据库连接参数:ip,username,password,dbname,port\n");
printf("charset 数据库的字符集。\n");
printf("logfile 本程序运行的日志文件名。\n");
printf("程序每10秒运行一次,由procctl调度。\n\n\n");
}
bool _obtmindtodb(char *pathname,char *connstr,char *charset)
{
//打开目录
//打开文件
while(true)
{
//处理文件中的每一行
}
//删除文件,提交事务
return true;
}函数全部代码,该程序名为obtmindtodb1.cpp,完成获取目录下文件的属性功能。接下来再继续完善功能。先做一个备份。
bool _obtmindtodb(char *pathname,char *connstr,char *charset)
{
CDir Dir;
//打开目录
if(Dir.OpenDir(pathname,"*.xml")==false)
{
logfile.Write("Dir.OpenDir(%s) failed.\n",pathname);
return false;
}
//打开文件
while(true)
{
//读取目录,得到一个数据文件名
if(Dir.ReadDir()==false) break;
logfile.Write("filename=%s\n",Dir.m_FullFileName);
//处理文件中的每一行
/*
while(true)
{
}
*/
}
//删除文件,提交事务
return true;
}完成主要功能函数,注释在代码里,本部分命名为obtmindtodb2.cpp
struct st_zhobtmind
{
char obtid[11]; //站点代码
char ddatetime[21]; //数据时间,精确到分钟
char t[11]; //温度,单位0.1摄氏度
char p[11]; //气压,单位0.1百帕
char u[11]; //相对湿度,0-100
char wd[11]; //风向,0-360
char wf[11]; //风速,单位0.1m/s
char r[11]; //降雨量,单位0.1mm
char vis[11]; //能见度,0.1m
}stzhobtmind;
// 业务处理主函数。
bool _obtmindtodb(char *pathname,char *connstr,char *charset)
{
//将数据库的连接操作移动至业务里
//本程序运行很快,只有当存在文件需要处理时才会去连接数据库。
sqlstatement stmt;
//目录操作类
CDir Dir;
// 打开目录。
if (Dir.OpenDir(pathname,"*.xml")==false)
{
logfile.Write("Dir.OpenDir(%s) failed.\n",pathname); return false;
}
//文件操作类
CFile File;
int totalcount=0; // 文件的总记录数。
int insertcount=0; // 成功插入记录数。
CTimer Timer; // 计时器,记录每个数据文件的处理耗时。
while (true)
{
// 读取目录,得到一个数据文件名。
if (Dir.ReadDir()==false) break;
// 连接数据库。对象conn的成员变量m_state记录了数据库的连接状态,0--未连接,1--已连接
// 只有检测到未连接数据库时才进行连接
if (conn.m_state==0)
{
if (conn.connecttodb(connstr,charset)!=0)
{
logfile.Write("connect database(%s) failed.\n%s\n",connstr,conn.m_cda.message); return -1;
}
logfile.Write("connect database(%s) ok.\n",connstr);
}
// 对象stmt的成员变量m_state记录了绑定状态,0--未绑定,1--已绑定
if (stmt.m_state==0)
{
stmt.connect(&conn);
stmt.prepare("insert into T_ZHOBTMIND(obtid,ddatetime,t,p,u,wd,wf,r,vis) values(:1,str_to_date(:2,'%%Y%%m%%d%%H%%i%%s'),:3,:4,:5,:6,:7,:8,:9)");
stmt.bindin(1,stzhobtmind.obtid,10);
stmt.bindin(2,stzhobtmind.ddatetime,14);
stmt.bindin(3,stzhobtmind.t,10);
stmt.bindin(4,stzhobtmind.p,10);
stmt.bindin(5,stzhobtmind.u,10);
stmt.bindin(6,stzhobtmind.wd,10);
stmt.bindin(7,stzhobtmind.wf,10);
stmt.bindin(8,stzhobtmind.r,10);
stmt.bindin(9,stzhobtmind.vis,10);
}
//logfile.Write("filename=%s\n",Dir.m_FullFileName);
totalcount=insertcount=0;
// 打开文件。
if (File.Open(Dir.m_FullFileName,"r")==false)
{
logfile.Write("File.Open(%s) failed.\n",Dir.m_FullFileName); return false;
}
char strBuffer[1001]; // 存放从文件中读取的一行。
while (true)
{
// FFGETS函数将以<endl/>为结尾的内容作为一次读取的内容块,存入strBuffer中。该函数中进行了数组的初始化操作。
if (File.FFGETS(strBuffer,1000,"<endl/>")==false) break;
//logfile.Write("strBuffer=%s",strBuffer);
// 处理文件中的每一行。
totalcount++;
memset(&stzhobtmind,0,sizeof(struct st_zhobtmind));
// 解析xml文件将结果存入结构体中
GetXMLBuffer(strBuffer,"obtid",stzhobtmind.obtid,10);
GetXMLBuffer(strBuffer,"ddatetime",stzhobtmind.ddatetime,14);
char tmp[11];
// 对于原本是浮点数,但是用程序中采用字符数组操作的变量需要进行处理
GetXMLBuffer(strBuffer,"t",tmp,10); if (strlen(tmp)>0) snprintf(stzhobtmind.t,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"p",tmp,10); if (strlen(tmp)>0) snprintf(stzhobtmind.p,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"u",stzhobtmind.u,10);
GetXMLBuffer(strBuffer,"wd",stzhobtmind.wd,10);
GetXMLBuffer(strBuffer,"wf",tmp,10); if (strlen(tmp)>0) snprintf(stzhobtmind.wf,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"r",tmp,10); if (strlen(tmp)>0) snprintf(stzhobtmind.r,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"vis",tmp,10); if (strlen(tmp)>0) snprintf(stzhobtmind.vis,10,"%d",(int)(atof(tmp)*10));
//logfile.Write("obtid=%s,ddatetime=%s,t=%s,p=%s,u=%s,wd=%s,wf=%s,r=%s,vis=%s\n\n",stzhobtmind.obtid,stzhobtmind.ddatetime,stzhobtmind.t,stzhobtmind.p,stzhobtmind.u,stzhobtmind.wd,stzhobtmind.wf,stzhobtmind.r,stzhobtmind.vis);
// 把结构体中的数据插入表中。
if (stmt.execute()!=0)
{
// 1、失败的情况有哪些?是否全部的失败都要写日志?
// 答:失败的原因主要有二:一是记录重复,二是数据内容非法。
// 2、如果失败了怎么办?程序是否需要继续?是否rollback?是否返回false?
// 答:如果失败的原因是数据内容非法,记录日志后继续;如果是记录重复,不必记录日志,且继续。
if (stmt.m_cda.rc!=1062)
{
//logfile.Write("Buffer=%s\n",strBuffer);
logfile.Write("stmt.execute() failed.\n%s\n%s\n",stmt.m_sql,stmt.m_cda.message);
}
}
else
insertcount++;
}
// 删除文件、提交事务。
// File.CloseAndRemove();
conn.commit();
logfile.Write("已处理文件%s (totalcount=%d,insertcount=%d),耗时%.2f秒。\n",Dir.m_FullFileName,totalcount,insertcount,Timer.Elapsed());
}
return true;
}
程序优化,obtmindtodb3.cpp主要优化了一些日志的记录,删除了一些不必要的日志写入。使日志更加方便阅读。没有单独备份。接着我们考虑一个问题。数据入库的程序十分常见,也非常多。如何使这个程序变得更加简捷,更加具有通用性呢?我们首先考虑将程序封装成类。
class CZHOBTMIND
{
public:
connection *m_conn; //数据库连接
CLogFile *m_logfile; //日志
sqlstatement m_stmt; //插入表操作的sql
char m_buffer[1024]; //从文件中读取一行
struct st_zhobtmind m_zhobtmind; //全国站点分钟观测数据结构
CZHOBTMIND();
CZHOBTMIND(connection *conn,CLogFile *logfile);
~CZHOBTMIND();
void BindConnLog(connection *conn,CLogFile *logfile); //把connection和CLogFile传进去
bool SplitBuffer(char *strBuffer); //把文件读到的一行拆进结构体
bool InsertTable(); //把结构体中的数据插入数据库
};
默认构造函数将指针初始化为空,有参构造函数将指针初始化为传入的参数。析构函数什么都不用做。成员函数BindConnLog()完成的功能和有参构造一样。
CZHOBTMIND::CZHOBTMIND()
{
m_conn=NULL; m_logfile=NULL;
}
CZHOBTMIND::CZHOBTMIND(connection *conn,CLogFile *logfile)
{
m_conn=conn;
m_logfile=logfile;
}
CZHOBTMIND::~CZHOBTMIND()
{
}
void CZHOBTMIND::BindConnLog(connection *conn,CLogFile *logfile)
{
m_conn=conn;
m_logfile=logfile;
}再把业务功能的代码拷贝到成员函数中,修改主函数中调用的部分,类的封装就算完成了。本部分命名为obtmindtodb4.cpp
bool CZHOBTMIND::SplitBuffer(char *strBuffer)
{
memset(&m_zhobtmind,0,sizeof(struct st_zhobtmind));
GetXMLBuffer(strBuffer,"obtid",m_zhobtmind.obtid,10);
GetXMLBuffer(strBuffer,"ddatetime",m_zhobtmind.ddatetime,14);
char tmp[11];
GetXMLBuffer(strBuffer,"t",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.t,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"p",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.p,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"u",m_zhobtmind.u,10);
GetXMLBuffer(strBuffer,"wd",m_zhobtmind.wd,10);
GetXMLBuffer(strBuffer,"wf",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.wf,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"r",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.r,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"vis",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.vis,10,"%d",(int)(atof(tmp)*10));
STRCPY(m_buffer,sizeof(m_buffer),strBuffer);
return true;
}
bool CZHOBTMIND::InsertTable()
{
if (m_stmt.m_state==0)
{
m_stmt.connect(m_conn);
m_stmt.prepare("insert into T_ZHOBTMIND(obtid,ddatetime,t,p,u,wd,wf,r,vis) values(:1,str_to_date(:2,'%%Y%%m%%d%%H%%i%%s'),:3,:4,:5,:6,:7,:8,:9)");
m_stmt.bindin(1,m_zhobtmind.obtid,10);
m_stmt.bindin(2,m_zhobtmind.ddatetime,14);
m_stmt.bindin(3,m_zhobtmind.t,10);
m_stmt.bindin(4,m_zhobtmind.p,10);
m_stmt.bindin(5,m_zhobtmind.u,10);
m_stmt.bindin(6,m_zhobtmind.wd,10);
m_stmt.bindin(7,m_zhobtmind.wf,10);
m_stmt.bindin(8,m_zhobtmind.r,10);
m_stmt.bindin(9,m_zhobtmind.vis,10);
}但是如果一个表中有很多的字段怎么办呢?假设一个表有50个字段,我们的绑定函数和解析函数就要写50行。并且此程序还不支持csv格式,如果要支持,该怎么修改呢?我们的办法是创建一个新的头文件和源文件。将这些繁琐的代码分离出去,在主程序中只要使用类进行调用就行了。头文件和源文件命名为/project/idc1/c/idccpp.h /project/idc1/c/idccpp.cpp。
把类和结构体的声明放在头文件。
/project/idc1/c/idccpp.h
#ifndef IDCAPP_H
#define IDCAPP_H
#include "_public.h"
#include "_mysql.h"
struct st_zhobtmind
{
char obtid[11]; // 站点代码。
char ddatetime[21]; // 数据时间,精确到分钟。
char t[11]; // 温度,单位:0.1摄氏度。
char p[11]; // 气压,单位:0.1百帕。
char u[11]; // 相对湿度,0-100之间的值。
char wd[11]; // 风向,0-360之间的值。
char wf[11]; // 风速:单位0.1m/s。
char r[11]; // 降雨量:0.1mm。
char vis[11]; // 能见度:0.1米。
};
// 全国站点分钟观测数据操作类。
class CZHOBTMIND
{
public:
connection *m_conn; // 数据库连接。
CLogFile *m_logfile; // 日志。
sqlstatement m_stmt; // 插入表操作的sql。
char m_buffer[1024]; // 从文件中读到的一行。
struct st_zhobtmind m_zhobtmind; // 全国站点分钟观测数据结构。
CZHOBTMIND();
CZHOBTMIND(connection *conn,CLogFile *logfile);
~CZHOBTMIND();
void BindConnLog(connection *conn,CLogFile *logfile); // 把connection和CLogFile的传进去。
bool SplitBuffer(char *strBuffer,bool bisxml); // 把从文件读到的一行数据拆分到m_zhobtmind结构体中。
bool InsertTable(); // 把m_zhobtmind结构体中的数据插入到T_ZHOBTMIND表中。
};
把成员函数的实现放在cpp文件。增加了对文件类型的判断,主函数中判断文件的类型来调用不同的处理代码。
/project/idc1/c/idccpp.cpp
#include "idcapp.h"
CZHOBTMIND::CZHOBTMIND()
{
m_conn=0; m_logfile=0;
}
CZHOBTMIND::CZHOBTMIND(connection *conn,CLogFile *logfile)
{
m_conn=conn;
m_logfile=logfile;
}
CZHOBTMIND::~CZHOBTMIND()
{
}
void CZHOBTMIND::BindConnLog(connection *conn,CLogFile *logfile)
{
m_conn=conn;
m_logfile=logfile;
}
// 把从文件读到的一行数据拆分到m_zhobtmind结构体中。增加了对文件类型的判断
bool CZHOBTMIND::SplitBuffer(char *strBuffer,bool bisxml)
{
memset(&m_zhobtmind,0,sizeof(struct st_zhobtmind));
if (bisxml==true)
{
GetXMLBuffer(strBuffer,"obtid",m_zhobtmind.obtid,10);
GetXMLBuffer(strBuffer,"ddatetime",m_zhobtmind.ddatetime,14);
char tmp[11];
GetXMLBuffer(strBuffer,"t",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.t,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"p",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.p,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"u",m_zhobtmind.u,10);
GetXMLBuffer(strBuffer,"wd",m_zhobtmind.wd,10);
GetXMLBuffer(strBuffer,"wf",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.wf,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"r",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.r,10,"%d",(int)(atof(tmp)*10));
GetXMLBuffer(strBuffer,"vis",tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.vis,10,"%d",(int)(atof(tmp)*10));
}
else
{
CCmdStr CmdStr;
CmdStr.SplitToCmd(strBuffer,",");
CmdStr.GetValue(0,m_zhobtmind.obtid,10);
CmdStr.GetValue(1,m_zhobtmind.ddatetime,14);
char tmp[11];
CmdStr.GetValue(2,tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.t,10,"%d",(int)(atof(tmp)*10));
CmdStr.GetValue(3,tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.p,10,"%d",(int)(atof(tmp)*10));
CmdStr.GetValue(4,m_zhobtmind.u,10);
CmdStr.GetValue(5,m_zhobtmind.wd,10);
CmdStr.GetValue(6,tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.wf,10,"%d",(int)(atof(tmp)*10));
CmdStr.GetValue(7,tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.r,10,"%d",(int)(atof(tmp)*10));
CmdStr.GetValue(8,tmp,10); if (strlen(tmp)>0) snprintf(m_zhobtmind.vis,10,"%d",(int)(atof(tmp)*10));
}
STRCPY(m_buffer,sizeof(m_buffer),strBuffer);
return true;
}
// 把m_zhobtmind结构体中的数据插入到T_ZHOBTMIND表中。
bool CZHOBTMIND::InsertTable()
{
if (m_stmt.m_state==0)
{
m_stmt.connect(m_conn);
m_stmt.prepare("insert into T_ZHOBTMIND(obtid,ddatetime,t,p,u,wd,wf,r,vis) values(:1,str_to_date(:2,'%%Y%%m%%d%%H%%i%%s'),:3,:4,:5,:6,:7,:8,:9)");
m_stmt.bindin(1,m_zhobtmind.obtid,10);
m_stmt.bindin(2,m_zhobtmind.ddatetime,14);
m_stmt.bindin(3,m_zhobtmind.t,10);
m_stmt.bindin(4,m_zhobtmind.p,10);
m_stmt.bindin(5,m_zhobtmind.u,10);
m_stmt.bindin(6,m_zhobtmind.wd,10);
m_stmt.bindin(7,m_zhobtmind.wf,10);
m_stmt.bindin(8,m_zhobtmind.r,10);
m_stmt.bindin(9,m_zhobtmind.vis,10);
}
// 把结构体中的数据插入表中。
if (m_stmt.execute()!=0)
{
// 1、失败的情况有哪些?是否全部的失败都要写日志?
// 答:失败的原因主要有二:一是记录重复,二是数据内容非法。
// 2、如果失败了怎么办?程序是否需要继续?是否rollback?是否返回false?
// 答:如果失败的原因是数据内容非法,记录日志后继续;如果是记录重复,不必记录日志,且继续。
if (m_stmt.m_cda.rc!=1062)
{
m_logfile->Write("Buffer=%s\n",m_buffer);
m_logfile->Write("m_stmt.execute() failed.\n%s\n%s\n",m_stmt.m_sql,m_stmt.m_cda.message);
}
return false;
}
return true;
}
最终版本主程序
#include "idcapp.h"
CLogFile logfile;
connection conn;
CPActive PActive;
// 把站点参数文件中加载到vstcode容器中。
void EXIT(int sig);
void _help();
//业务处理主函数
bool _obtmindtodb(char *pathname,char *connstr,char *charset);
int main(int argc,char *argv[])
{
// 帮助文档
if (argc!=5) { _help(); return -1; }
// 处理程序退出的信号
CloseIOAndSignal(); signal(SIGINT,EXIT); signal(SIGTERM,EXIT);
// 打开日志文件
if(logfile.Open(argv[4],"a+")==false)
{
printf("打开日志文件失败(%s)。\n",argv[4]);
return -1;
}
PActive.AddPInfo(5000,"obtmindtodb"); // 进程的心跳,10秒足够。
_obtmindtodb(argv[1],argv[2],argv[3]);
return 0;
}
void _help()
{
printf("\n");
printf("Using:./obtmindtodb pathname connstr charset logfile\n");
printf("Example:/project/tools1/bin/procctl 10 /project/idc1/bin/obtmindtodb /idcdata/surfdata \"127.0.0.1,root,root,ltbo,3306\" utf8 /log/idc/obtmindtodb.log\n\n");
printf("本程序用于把全国站点分钟观测数据保存到数据库的T_ZHOBTMIND表中,数据只插入,不更新。\n");
printf("pathname 全国站点分钟观测数据文件存放的目录。\n");
printf("connstr 数据库连接参数:ip,username,password,dbname,port\n");
printf("charset 数据库的字符集。\n");
printf("logfile 本程序运行的日志文件名。\n");
printf("程序每10秒运行一次,由procctl调度。\n\n\n");
}
void EXIT(int sig)
{
logfile.Write("程序退出,sig=%d\n\n",sig);
conn.disconnect();
exit(0);
}
// 业务处理主函数。
bool _obtmindtodb(char *pathname,char *connstr,char *charset)
{
//如果需要增加对json和csv格式的数据文件的支持怎么办
//如果表的字段有很多,例如50个,怎么使代码简介
CDir Dir;
// 打开目录。增加csv格式
if (Dir.OpenDir(pathname,"*.xml,*.csv")==false)
{
logfile.Write("Dir.OpenDir(%s) failed.\n",pathname); return false;
}
CFile File;
CZHOBTMIND ZHOBTMIND(&conn,&logfile);
int totalcount=0; // 文件的总记录数。
int insertcount=0; // 成功插入记录数。
CTimer Timer; // 计时器,记录每个数据文件的处理耗时。
bool bisxml=false; // 处理的文件格式,true--xml,false--csv。
while (true)
{
// 读取目录,得到一个数据文件名。
if (Dir.ReadDir()==false) break;
// 判断文件类型
if (MatchStr(Dir.m_FullFileName,"*.xml")==true) bisxml=true;
else bisxml=false;
// 连接数据库。
if (conn.m_state==0)
{
if (conn.connecttodb(connstr,charset)!=0)
{
logfile.Write("connect database(%s) failed.\n%s\n",connstr,conn.m_cda.message);
return -1;
}
logfile.Write("connect database(%s) ok.\n",connstr);
}
totalcount=insertcount=0;
// 打开文件。
if (File.Open(Dir.m_FullFileName,"r")==false)
{
logfile.Write("File.Open(%s) failed.\n",Dir.m_FullFileName); return false;
}
char strBuffer[1001]; // 存放从文件中读取的一行。
while (true)
{
if (bisxml==true) //如果文件类似是xml
{
if (File.FFGETS(strBuffer,1000,"<endl/>")==false) break;
}
else //如果文件类型是csv
{
if (File.Fgets(strBuffer,1000,true)==false) break;
if (strstr(strBuffer,"站点")!=0) continue; //根据csv文件的格式,需要丢掉第一行
}
// 处理文件中的每一行。
totalcount++;
ZHOBTMIND.SplitBuffer(strBuffer,bisxml);
if(ZHOBTMIND.InsertTable()==true) insertcount++;
}
File.CloseAndRemove();
conn.commit();
logfile.Write("已处理文件%s (totalcount=%d,insertcount=%d),耗时%.2f秒。\n",Dir.m_FullFileName,totalcount,insertcount,Timer.Elapsed());
}
return true;
}
这样一来站点分钟观测数据的入库程序也算完成了。这一章很长,如果有什么地方写的不够清楚请提出来。最后我们开发小脚本自动化运行。
5.6数据入库自动化处理程序
我们需要写一个程序,不断清空数据库中表的记录,不然数据源源不断地入库,表会变得非常大。sql文件非常简单:第二行是用于测试的错误sql语句。正式运行后可以删除。
/project/idc1/sql/cleardata.sql
delete from T_ZHOBTMIND where ddatetime<timestampadd(minute,-30,now());
delete from T_ZHOBTMIN where ddatetime<timestampadd(minute,-30,now());然后我们写一个程序来执行这个sql文件。
#include "_public.h"
#include "_mysql.h"
CLogFile logfile;
connection conn;
CPActive PActive;
void _help();
void EXIT(int sig);
int main(int argc,char *argv[])
{
// 帮助文档
if (argc!=5) { _help(); return -1; }
// 处理程序退出的信号
CloseIOAndSignal(); signal(SIGINT,EXIT); signal(SIGTERM,EXIT);
// 打开日志文件
if(logfile.Open(argv[4],"a+")==false)
{
printf("打开日志文件失败(%s)。\n",argv[4]);
return -1;
}
PActive.AddPInfo(500,"obtcodetodb"); // 进程的心跳,10秒足够。
// 连接数据库,不启用事务
if(conn.connecttodb(argv[2],argv[3],1)!=0)
{
logfile.Write("connect database(%s) failed.\n%s\n",argv[2],conn.m_cda.message);
return -1;
}
logfile.Write("connect database(%s) ok.\n",argv[2]);
CFile File;
if (File.Open(argv[1],"r")==false)
{
logfile.Write("File.Open(%s) failed.\n",argv[1]);
EXIT(-1);
}
char strsql[1001];
while (true)
{
memset(strsql,0,sizeof(strsql));
// 从SQL文件中读取以分号结束的一行。
if (File.FFGETS(strsql,1000,";")==false) break;
// 如果第一个字符是#,注释,不执行。
if (strsql[0]=='#') continue;
// 删除掉SQL语句最后的分号。
char *pp=strstr(strsql,";");
if (pp==0) continue;
pp[0]=0;
logfile.Write("%s\n",strsql);
int iret=conn.execute(strsql); // 执行SQL语句。
// 把SQL语句执行结果写日志。
if (iret==0) logfile.Write("exec ok(rpc=%d).\n",conn.m_cda.rpc);
else logfile.Write("exec failed(%s).\n",conn.m_cda.message);
PActive.UptATime(); // 进程的心跳。
}
//不写时间
logfile.WriteEx("\n");
return 0;
}
void _help()
{
printf("\n");
printf("Using:./execsql sqlfile connstr charset logfile\n");
printf("Example:/project/tools1/bin/procctl 120 /project/tools1/bin/execsql /project/idc1/sql/cleardata.sql \"127.0.0.1,root,root,ltbo,3306\" utf8 /log/idc/execsql.log\n\n");
printf("这是一个工具程序,用于执行一个sql脚本文件。\n");
printf("sqlfile sql脚本文件名,每条sql语句可以多行书写,分号表示一条sql语句的结束,不支持注释。\n");
printf("connstr 数据库连接参数:ip,username,password,dbname,port\n");
printf("charset 数据库的字符集。\n");
printf("logfile 本程序运行的日志文件名。\n\n");
}
void EXIT(int sig)
{
logfile.Write("程序退出,sig=%d\n\n",sig);
conn.disconnect();
exit(0);
}修改启动脚本,在脚本末尾加上这三行。
# 把全国站点参数数据保存到数据库表中,如果站点不存在则插入,站点已存在则更新。
/project/tools1/bin/procctl 120 /project/idc1/bin/obtcodetodb /project/idc/ini/stcode.ini "127.0.0.1,root,root,ltbo,3306" utf8 /log/idc/obtcodetodb.log
# 把全国站点分钟观测数据保存到数据库的T_ZHOBTMIND表中,数据只插入,不更新。
/project/tools1/bin/procctl 10 /project/idc1/bin/obtmindtodb /idcdata/surfdata "127.0.0.1,root,root,ltbo,3306" utf8 /log/idc/obtmindtodb.log
# 清理T_ZHOBTMIND?表中120分之前的数据,防止磁盘空间被撑满。
/project/tools1/bin/procctl 120 /project/tools1/bin/execsql /project/idc1/sql/cleardata.sql "127.0.0.1,root,root,ltbo,3306" utf8 /log/idc/execsql.log修改停止脚本
####################################################################
# 停止数据中心后台服务程序的脚本。
####################################################################
killall -9 procctl
killall gzipfiles crtsurfdata deletefiles ftpgetfiles ftpputfiles tcpputfiles tcpgetfiles fileserver
killall obtcodetodb obtmindtodb execsql
sleep 3
killall -9 gzipfiles crtsurfdata deletefiles ftpgetfiles ftpputfiles tcpputfiles tcpgetfiles fileserver
killall -9 obtcodetodb obtmindtodb execsql5.7注意事项
(1)一个connection对象同一时间只能连一个数据库(断开可以重连)。
(2)同一程序中,创建多个connection对象可以同时连接多个数据库。
(3)每个connection对象的事务是独立的,这意味着同一个程序创建了多个connection对象,连接了多个数据库。他们的业务互相独立。
(4)connection对象也有execute方法,如果执行的sql语句不需要绑定输入变量和输出变量。就可以直接使用这个对象执行。
(5)多个进程不能共享同一个已连接成功的connection对象,如果一个进程要提交事务,一个进程要回滚事务,必然产生冲突。使用信号量加锁又过于麻烦,没有必要。所以需要先fork创建子进程,再让子进程连接数据库。
(6)多个sqlstatement对象可以绑定同一个connection对象,也就是说在一个数据库连接中,可以执行多个sql语句。
(7)如果执行的sql语句不需要绑定输入变量和输出变量,可以不需要先prepare直接execute。
(8)如果执行了select语句,在结果集没有获取完之前,同一个connection中的sqlstatement对象都不能执行任何的sql语句。
(9)c语言中不能表示空的整数和浮点数,实际项目中可以使用字符串来存放整数和浮点数,也可以表示空值。当一条记录为空时,我们不可能去修改程序中的sql语句,所以使用字符串来进行操作,封装的execute函数中对字符串为空的情况做了处理。















 2901
2901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









