






第八章:开发数据同步子系统
本章示例makefile文件:放上面文章太长了,请自行添加。
首先需要我们去自行了解一下mysql的高可用方案:
MySQL的高可用方案旨在确保数据库系统在面对硬件故障、网络问题、维护等情况下能够持续提供可靠的服务。以下是几种常见的MySQL高可用方案:
-
主从复制(Master-Slave Replication):这是MySQL中最简单的高可用方案之一。在主从复制中,有一个主数据库(Master)负责写操作,而一个或多个从数据库(Slave)负责读操作。主数据库将其写操作的日志传递给从数据库,从数据库根据这些日志来保持数据同步。主从复制提供了读扩展的能力,但在主库故障时需要手动切换。
-
主主复制(Master-Master Replication):类似于主从复制,但是两个数据库都可以执行读写操作。这种方法可以实现读写分离和负载均衡,但需要处理冲突和同步问题。
-
MySQL集群(MySQL Cluster):MySQL集群是一个面向事务的高可用和高性能解决方案,适用于需要同时满足高可用性和水平扩展需求的场景。它使用多个节点来存储和处理数据,具有自动故障检测和恢复的功能。
-
Galera Cluster:这是一个基于多主复制的集群解决方案,允许多个数据库节点相互同步,并且可以在任何节点上执行读写操作。Galera Cluster使用基于Paxos协议的技术来确保数据的一致性。
-
MySQL InnoDB Cluster:这是MySQL官方提供的高可用解决方案,基于MySQL Group Replication和MySQL Router。它提供了自动故障检测、数据同步和自动故障切换等功能。
-
分布式数据库系统:除了上述解决方案外,一些分布式数据库系统(如TiDB、Vitess等)提供了更高级别的可用性和扩展性,但它们可能需要更复杂的架构和管理。
然而对于mysql提供的高可用方案有一些缺点:
1.master和slave数据库的表结构以及数据量必须保持一致
2.非主从关系的数据库之间不能进行数据复制
3.不够灵活,效率不够高
如图:上面是核心数据库,下面是应用数据库。红色的剪头代表mysql自带的数据复制。对于应用数据来说,他不希望自己是某一个数据库的副本,它更关心的是自己服务的对象需要的是什么数据,例如实时库,存放了全部的数据种类,但是只有3天的数据,3天之前的数据不关心,它的特点是种类齐全,数据量少。总的来说,应用数据库应该是需要什么数据,就存什么数据,不必要从核心数据库中复制全部的数据过来。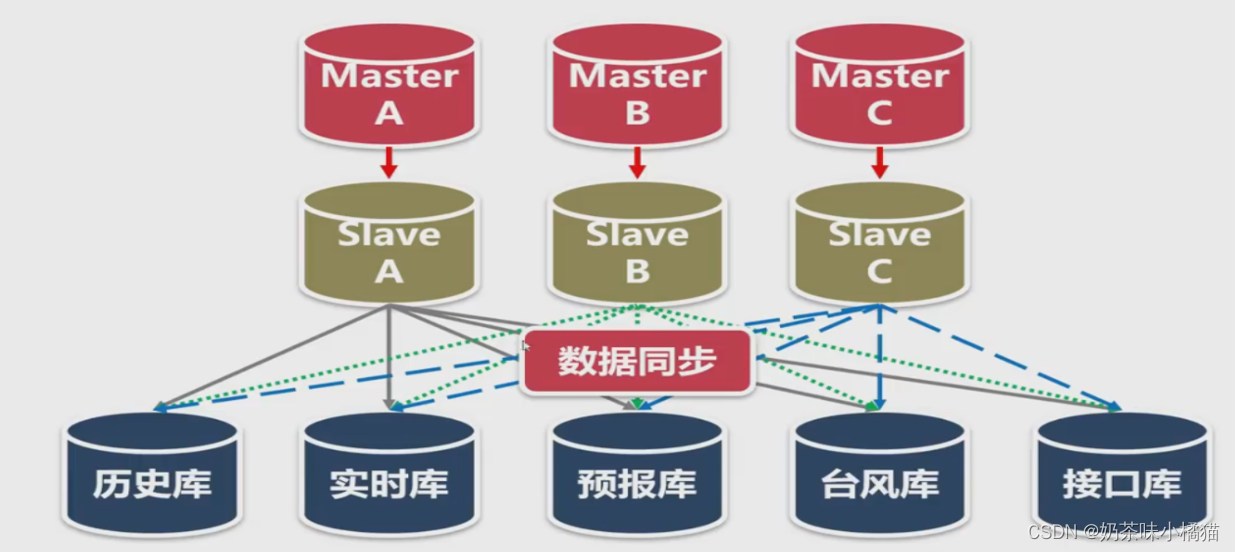
本章共有四个任务:
1.熟悉mysql数据库的federated存储引擎。
2.开发基于federated存储引擎的刷新同步模块。
3.开发基于federated存储引擎的增量同步模块。
4.开发不采用federated存储引擎的增量同步模块。
8.1Federated存储引擎
"Federated" 引擎是MySQL数据库中的一种存储引擎,它允许在不同的MySQL服务器之间建立透明的分布式查询和数据访问。通过 Federated 引擎,您可以在一个MySQL服务器上访问另一个MySQL服务器上的表格数据,就像访问本地表格一样,从而实现跨服务器的查询和数据操作。
这是一些关键特点和概念:
-
分布式查询:Federated 引擎允许您在一个MySQL服务器上执行查询,而这些查询涉及远程服务器上的表格数据。查询会在本地服务器上执行,但需要通过网络与远程服务器通信以获取数据。
-
透明性:对于查询,您不需要直接处理远程服务器的细节,Federated 引擎会自动处理远程数据的访问。这使得您可以通过一个连接进行跨服务器的查询,就像查询本地数据一样。
-
表格定义:在本地MySQL服务器上,您可以定义一个“Federated” 表格,该表格的定义指向远程服务器上的对应表格。这个定义包括远程服务器的位置、用户名、密码等信息。
-
性能注意事项:尽管 Federated 引擎提供了分布式查询的能力,但是由于涉及跨服务器的数据传输,因此在性能方面需要考虑网络延迟和数据量的影响。
8.1.1启用Federated存储引擎
如果你的mysql数据库是和我一样安装在centos7上的,可以参考我的启用方法,如果你不知道如何在centos7上安装mysql数据库,请看我写的第五章笔记,里面详细记录了在centos7上安装mysql5.7.34的方法。
[diana@localhost ~]$ sudo vim /etc/my.cnf
// 找到[mysqld] ,在这一段的末尾另起一行添加:federated
// 保存退出,重启数据库:
[diana@localhost ~]$ systemctl restart mysql
// 登入数据库,查询启动状态
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | YES | Federated MySQL storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
8.1.2创建操作远程数据库的表
打开powerdesigner软件,点开全国站点分钟观测数据表1,点击预览查看sql语句。复制下这一部分并稍作修改:修改表名为LK_ZHOBTMIND1,在末尾添加原表的地址。
create table LK_ZHOBTMIND1
(
obtid varchar(10) not null comment '站点代码',
ddatetime datetime not null comment '数据时间,精确到分钟',
t int comment '温度,单位0.1摄氏度',
p int comment '气压,单位0.1百帕',
u int comment '相对湿度,0-100之间的值',
wd int comment '风向,0-360之间的值',
wf int comment '风速,单位0.1m/s',
r int comment '降雨量,单位0.1mm',
vis int comment '能见度,单位0.1m',
upttime timestamp not null default CURRENT_TIMESTAMP comment '更新时间',
keyid bigint not null auto_increment comment '记录编号,自动增长列',
primary key (obtid, ddatetime),
key AK_ZHOBTMIND1_KEYID (keyid)
)ENGINE=FEDERATED CONNECTION='mysql://root:root@127.0.0.1:3306/ltbo/T_ZHOBTMIND1';ENGINE=FEDERATED CONNECTION='mysql://为固定写法,root:root这一部分为远程数据库的登入名和登入密码。@127.0.0.1:3306这一部分为远程主机的ip和数据库端口,这里我使用本机,填127.0.0.1。/ltbo/T_ZHOBTMIND1'最后这一部分是远程数据表所在的数据库名以及远程表名。最后在数据库中执行。
我这里将这个表创建在一个新的数据库ltbo1里,创建好以后会看见一个和原数据表一样的链接表,也可以说是映射表等等。可以测试一下对一张表的操作会同步提现在另一张表上,因为这本来就是一张表,类似于快捷方式。
8.1.3一些注意事项
1)创建连接表需要确保能够连上远程服务器,一是网络能够到达,二是远程数据库需要开通连接权限。
2)除了主键和唯一键以外,Federated引擎不支持普通索引。什么意思呢?
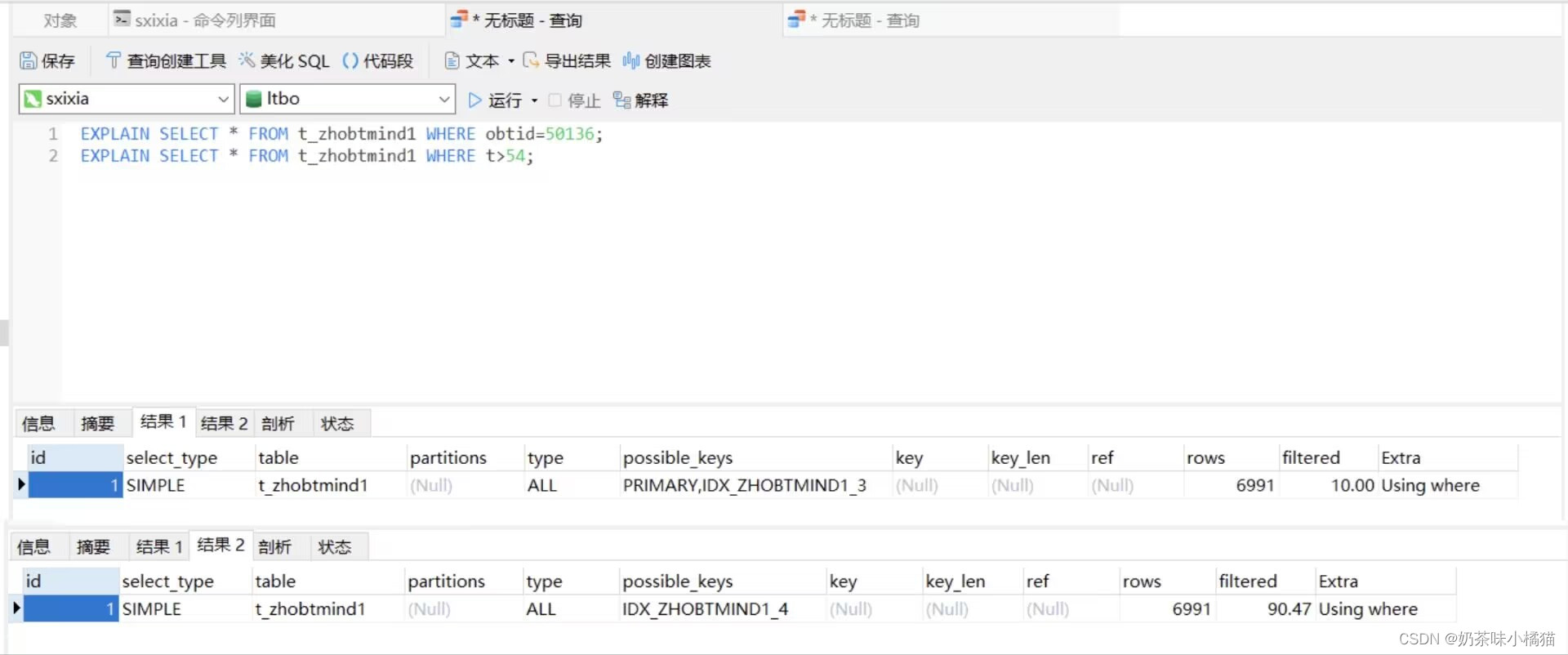
先在远程数据库的T_ZHOBTMIND1表上创建一个普通索引。索引字段是t。
create index IDX_ZHOBTMIND1_4 on T_ZHOBTMIND1 (t);打开远程数据库,新建查询。写两条查询语句,运行,解释,结果如下:可以看到第一次查询使用了表的主键,第二次使用了刚刚创建的索引。
再使用连接表查询:第一次查询使用了主键,第二次没有使用普通索引,使用的是全表扫描。
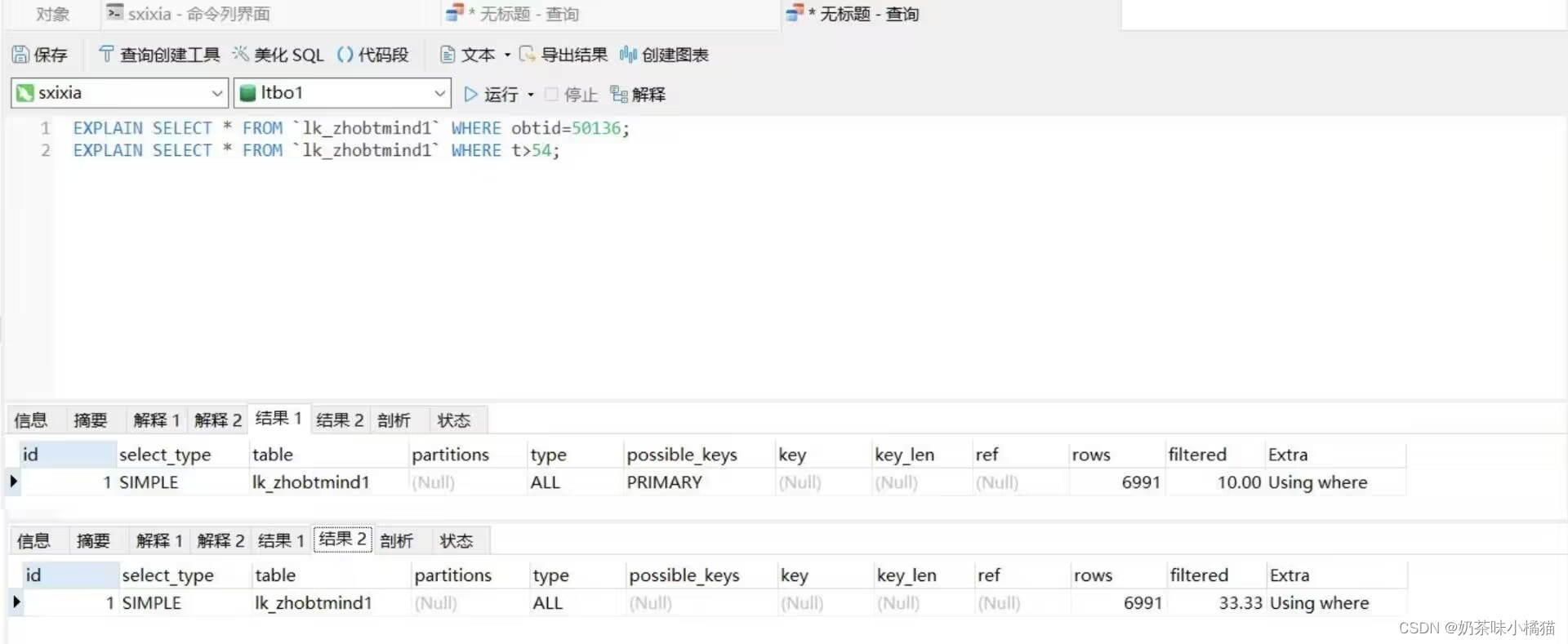
唯一键的测试也可以这样来测试,这里不再进行演示。这意味着如果使用的不好,会使得数据库表性能大幅度下降。
3)连接表在创建时必须指定主键和唯一键。
4)连接表补支持ALTER TABLE等任何DDL语句。
5)连接表不支持事务。
6)连接表无法知道远程表中表结构的改变,每当远程表发生结构变化时,都需要手动更新本地 Federated 表的定义以匹配远程表的新结构。
7)任何drop语句都只是对本地库表的操作,不影响远程表。
8.2刷新同步--全表刷新
先做一些准备工作,创建两个新的表,名字为全国站点参数表2和表3,从全国站点参数表1--T_ZHOBTCODE1表中进行拷贝,将站点代码的字段名修改为stid,将海拔高度字段名修改为altitude,字段类型修改为numeric(8,2),单位从0.1米修改为米。修改一下说明文字。
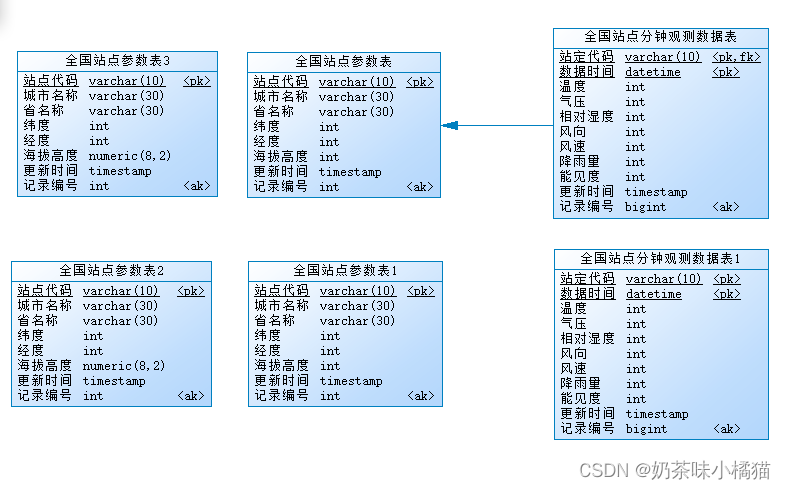
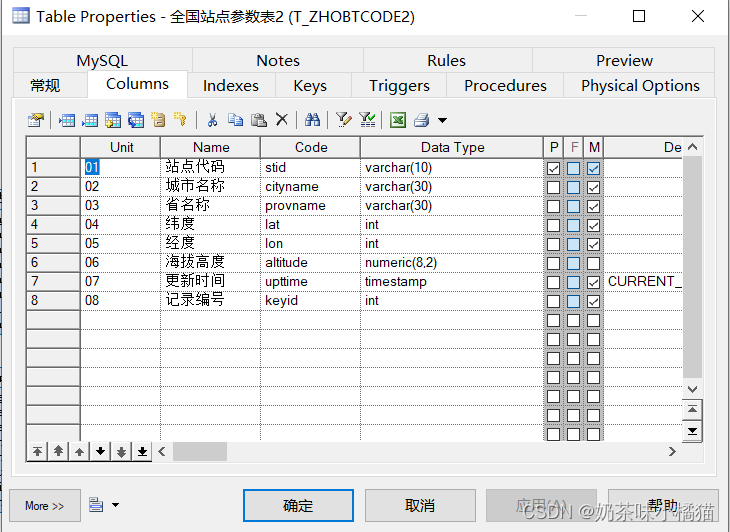
在本地数据库中创建这两个表,这里我将本机的ltbo数据库当做远程数据库,在本机的ltbo1数据库当做本地数据库,所以我在数据库ltbo1中创建这两个表。接着继续在本地数据库里创建连接表。
drop table if exists T_ZHOBTCODE2;
/*==============================================================*/
/* Table: T_ZHOBTCODE2 */
/*==============================================================*/
create table T_ZHOBTCODE2
(
stid varchar(10) not null comment '站点代码',
cityname varchar(30) not null comment '城市名称',
provname varchar(30) not null comment '省名称',
lat int not null comment '纬度,单位0.01度',
lon int not null comment '经度,单位0.01度',
altitude numeric(8,2) comment '海拔高度,单位m',
upttime timestamp not null default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP comment '更新时间,数据被插入或被更新的时间',
keyid int not null auto_increment comment '记录编号,自动增长',
primary key (stid),
key AK_ZHOBTCODE1_KEYID (keyid)
);
alter table T_ZHOBTCODE2 comment 'syncupdate程序测试表,表结构与主表略微不同';
drop table if exists T_ZHOBTCODE3;
/*==============================================================*/
/* Table: T_ZHOBTCODE3 */
/*==============================================================*/
create table T_ZHOBTCODE3
(
stid varchar(10) not null comment '站点代码',
cityname varchar(30) not null comment '城市名称',
provname varchar(30) not null comment '省名称',
lat int not null comment '纬度,单位0.01度',
lon int not null comment '经度,单位0.01度',
altitude numeric(8,2) comment '海拔高度,单位0.1m',
upttime timestamp not null default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP comment '更新时间,数据被插入或被更新的时间',
keyid int not null auto_increment comment '记录编号,自动增长',
primary key (stid),
key AK_ZHOBTCODE1_KEYID (keyid)
);
alter table T_ZHOBTCODE3 comment 'syncupdate程序测试表,表结构与主表略微不同';
create table LK_ZHOBTCODE1
(
obtid varchar(10) not null comment '站点代码',
cityname varchar(30) not null comment '城市名称',
provname varchar(30) not null comment '省名称',
lat int not null comment '纬度,单位0.01度',
lon int not null comment '经度,单位0.01度',
height int comment '海拔高度,单位0.1m',
upttime timestamp not null default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP comment '更新时间,数据被插入或被更新的时间',
keyid int not null auto_increment comment '记录编号,自动增长',
primary key (obtid),
key AK_ZHOBTCODE1_KEYID (keyid)
)ENGINE=FEDERATED CONNECTION='mysql://root:root@127.0.0.1:3306/ltbo/T_ZHOBTCODE1';刷新同步有两种方案,一种是全表刷新,一种是分批刷新。
全表刷新是先清空表中全部数据,再将数据插入,这种方法能保证数据的完整性,但是只适用于表数据很少的情况,不然会产生大事务。操作如下:注意,插入语句这么写的原因是因为两个表结构不完全相同。
DELETE FROM t_zhobtcode2;
INSERT INTO t_zhobtcode2(stid,cityname,provname,lat,lon,altitude,upttime,keyid)
SELECT obtid,cityname,provname,lat,lon,height/10,upttime,keyid FROM lk_zhobtcode1;分批刷新的步骤是:从远程表中查询需要同步的数据,把结果分为若干批,每批的记录在50-256之间。
删除本地表中指定批的记录。
把FEDERATED表中指定批的记录插入本地表中。
#假设查询到8条记录
select obtid from T_ZHOBTCODE1 where provname='广东' and obtid like '592%';
59271
59278
59280
59287
59289
59293
59294
59298
#分批插入,每次插入3条记录
DELETE FROM t_zhobtcode3 where stid in ('59271','59278','59280');
INSERT INTO t_zhobtcode3(stid,cityname,provname,lat,lon,altitude,upttime,keyid)
SELECT obtid,cityname,provname,lat,lon,height/10,upttime,keyid FROM lk_zhobtcode1
where obtid in ('59271','59278','59280');
DELETE FROM t_zhobtcode3 where stid in ('59287','59289','59293');
INSERT INTO t_zhobtcode3(stid,cityname,provname,lat,lon,altitude,upttime,keyid)
SELECT obtid,cityname,provname,lat,lon,height/10,upttime,keyid FROM lk_zhobtcode1
where obtid in ('59287','59289','59293');
DELETE FROM t_zhobtcode3 where stid in ('59294','59298');
INSERT INTO t_zhobtcode3(stid,cityname,provname,lat,lon,altitude,upttime,keyid)
SELECT obtid,cityname,provname,lat,lon,height/10,upttime,keyid FROM lk_zhobtcode1
where obtid in ('59294','59298');
先看全表刷新同步:我们首先在本地数据库ltbo1中创建两个表,T_ZHOBTCODE2和T_ZHOBTCODE3,接着分别创建远程数据库ltbo中两个表的链接表。LK_ZHOBTCODE1和LK_ZHOBTMIND1。那么本地数据库ltbo1就会有4个表。我们需要先删除本地数据库表T_ZHOBTCODE2中的全部数据,再使用链接表LK_ZHOBTCODE1查询全部的数据插入其中。
程序的框架如下:理解各个参数的意思时最好结合我上面写的全表刷新的sql语句一起理解。看看各个参数是sql语句中的哪一部分。
需要注意,当synctype==2,也就是说采用分批刷新的时候,我们需要链接远程表,从远程表中查询数据再插入,因为使用federated表来查询也是先从远程表中进行查询的,相当于了多了一个步骤,所以就需要链接远程数据库表的参数。
#include "_tools.h"
struct st_arg
{
char localconnstr[101]; // 本地数据库的连接参数。
char charset[51]; // 数据库的字符集。
char fedtname[31]; // Federated表名。
char localtname[31]; // 本地表名。
char remotecols[1001]; // 远程表的字段列表。
char localcols[1001]; // 本地表的字段列表。
char where[1001]; // 同步数据的条件。
int synctype; // 同步方式:1-不分批同步;2-分批同步。
char remoteconnstr[101]; // 远程数据库的连接参数。
char remotetname[31]; // 远程表名。
char remotekeycol[31]; // 远程表的键值字段名。
char localkeycol[31]; // 本地表的键值字段名。
int maxcount; // 每批执行一次同步操作的记录数。
int timeout; // 本程序运行时的超时时间。
char pname[51]; // 本程序运行时的程序名。
} starg;
// 显示程序的帮助
void _help(char *argv[]);
// 把xml解析到参数starg结构中
bool _xmltoarg(char *strxmlbuffer);
CLogFile logfile;
connection connloc; // 本地数据库连接。
connection connrem; // 远程数据库连接。
// 业务处理主函数。
bool _syncupdate();
void EXIT(int sig);
CPActive PActive;
int main(int argc,char *argv[])
{
if (argc!=3) { _help(argv); return -1; }
// 关闭全部的信号和输入输出,处理程序退出的信号。
//CloseIOAndSignal();
signal(SIGINT,EXIT); signal(SIGTERM,EXIT);
if (logfile.Open(argv[1],"a+")==false)
{
printf("打开日志文件失败(%s)。\n",argv[1]); return -1;
}
// 把xml解析到参数starg结构中
if (_xmltoarg(argv[2])==false) return -1;
// PActive.AddPInfo(starg.timeout,starg.pname);
// 注意,在调试程序的时候,可以启用类似以下的代码,防止超时。
// PActive.AddPInfo(starg.timeout*100,starg.pname);
// 连接本地数据库
if (connloc.connecttodb(starg.localconnstr,starg.charset) != 0)
{
logfile.Write("connect database(%s) failed.\n%s\n",starg.localconnstr,connloc.m_cda.message); EXIT(-1);
}
// logfile.Write("connect database(%s) ok.\n",starg.localconnstr);
//如果starg.remotecols或者starg.localcols为空,就用starg.localtname表的全部列来填充
//为空就代表着本地表和远程表中的表结构一致(列名称,列顺序,列类型等,我们这里是做了修改的,适用大多数情况。)
if((strlen(starg.remotecols)==0) || (strlen(starg.localcols)==0))
{
CTABCOLS TABCOLS; //获取数据库表主键或者全部列信息的类
//获取starg.localtname表的全部列
if(TABCOLS.allcols(&connloc,starg.localtname)==false)
{
logfile.Write("表%s不存在。\n",starg.localtname);
EXIT(-1);
}
if(strlen(starg.remotecols)==0) strcpy(starg.remotecols,TABCOLS.m_allcols);
if(strlen(starg.localcols)==0) strcpy(starg.localcols,TABCOLS.m_allcols);
}
// 业务处理主函数。
_syncupdate();
}
// 显示程序的帮助
void _help(char *argv[])
{
printf("Using:/project/tools1/bin/syncupdate logfilename xmlbuffer\n\n");
printf("Sample:/project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTCODE2.log \"<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTCODE1</fedtname><localtname>T_ZHOBTCODE2</localtname><remotecols>obtid,cityname,provname,lat,lon,height/10,upttime,keyid</remotecols><localcols>stid,cityname,provname,lat,lon,altitude,upttime,keyid</localcols><synctype>1</synctype><timeout>50</timeout><pname>syncupdate_ZHOBTCODE2</pname>\"\n\n");
// 因为测试的需要,xmltodb程序每次会删除LK_ZHOBTCODE1中的数据,全部的记录重新入库,keyid会变。
// 所以以下脚本不能用keyid,要用obtid,用keyid会出问题,可以试试。
printf(" /project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTCODE3.log \"<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTCODE1</fedtname><localtname>T_ZHOBTCODE3</localtname><remotecols>obtid,cityname,provname,lat,lon,height/10,upttime,keyid</remotecols><localcols>stid,cityname,provname,lat,lon,altitude,upttime,keyid</localcols><where>where obtid like '54%%%%'</where><synctype>2</synctype><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><remotetname>T_ZHOBTCODE1</remotetname><remotekeycol>obtid</remotekeycol><localkeycol>stid</localkeycol><maxcount>10</maxcount><timeout>50</timeout><pname>syncupdate_ZHOBTCODE3</pname>\"\n\n");
printf(" /project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTMIND2.log \"<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND2</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><where>where ddatetime>timestampadd(minute,-120,now())</where><synctype>2</synctype><synctype>2</synctype><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><remotetname>T_ZHOBTMIND1</remotetname><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timeout>50</timeout><pname>syncupdate_ZHOBTMIND2</pname>\"\n\n");
printf("本程序是数据中心的公共功能模块,采用刷新的方法同步MySQL数据库之间的表。\n");
printf("logfilename 本程序运行的日志文件。\n");
printf("xmlbuffer 本程序运行的参数,用xml表示,具体如下:\n\n");
printf("localconnstr 本地数据库的连接参数,格式:ip,username,password,dbname,port。\n");
printf("charset 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。\n");
printf("fedtname Federated表名。\n");
printf("localtname 本地表名。\n");
printf("remotecols 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,也可以是函数的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
printf("localcols 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,就用localtname表的字段列表填充。\n");
printf("where 同步数据的条件,即select语句的where部分,本参数可以为空,表示同步全部的记录。\n");
printf("synctype 同步方式:1-不分批同步;2-分批同步。\n");
printf("remoteconnstr 远程数据库的连接参数,格式与localconnstr相同,当synctype==2时有效。\n");
printf("remotetname 远程表名,当synctype==2时有效。\n");
printf("remotekeycol 远程表的键值字段名,必须是唯一的,当synctype==2时有效。\n");
printf("localkeycol 本地表的键值字段名,必须是唯一的,当synctype==2时有效。\n");
printf("maxcount 每批执行一次同步操作的记录数,不能超过MAXPARAMS宏(在_mysql.h中定义),当synctype==2时有效。\n");
printf("timeout 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。\n");
printf("pname 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。\n\n");
printf("注意:1)remotekeycol和localkeycol字段的选取很重要,如果用了MySQL的自增字段,那么在远程表中数据生成后自增字段的值不可改变,否则同步会失败;2)当远程表中存在delete操作时,无法分批同步,因为远程表的记录被delete后就找不到了,无法从本地表中执行delete操作。\n\n\n");
}
// 把xml解析到参数starg结构中
bool _xmltoarg(char *strxmlbuffer)
{
memset(&starg,0,sizeof(struct st_arg));
// 本地数据库的连接参数,格式:ip,username,password,dbname,port。
GetXMLBuffer(strxmlbuffer,"localconnstr",starg.localconnstr,100);
if (strlen(starg.localconnstr)==0) { logfile.Write("localconnstr is null.\n"); return false; }
// 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。
GetXMLBuffer(strxmlbuffer,"charset",starg.charset,50);
if (strlen(starg.charset)==0) { logfile.Write("charset is null.\n"); return false; }
// Federated表名。
GetXMLBuffer(strxmlbuffer,"fedtname",starg.fedtname,30);
if (strlen(starg.fedtname)==0) { logfile.Write("fedtname is null.\n"); return false; }
// 本地表名。
GetXMLBuffer(strxmlbuffer,"localtname",starg.localtname,30);
if (strlen(starg.localtname)==0) { logfile.Write("localtname is null.\n"); return false; }
// 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,也可以是函数
// 的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
GetXMLBuffer(strxmlbuffer,"remotecols",starg.remotecols,1000);
// 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,就用localtname表的字段列表填充。
GetXMLBuffer(strxmlbuffer,"localcols",starg.localcols,1000);
// 同步数据的条件,即select语句的where部分。
GetXMLBuffer(strxmlbuffer,"where",starg.where,1000);
// 同步方式:1-不分批同步;2-分批同步。
GetXMLBuffer(strxmlbuffer,"synctype",&starg.synctype);
if ( (starg.synctype!=1) && (starg.synctype!=2) ) { logfile.Write("synctype is not in (1,2).\n"); return false; }
if (starg.synctype==2)
{
// 远程数据库的连接参数,格式与localconnstr相同,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"remoteconnstr",starg.remoteconnstr,100);
if (strlen(starg.remoteconnstr)==0) { logfile.Write("remoteconnstr is null.\n"); return false; }
// 远程表名,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"remotetname",starg.remotetname,30);
if (strlen(starg.remotetname)==0) { logfile.Write("remotetname is null.\n"); return false; }
// 远程表的键值字段名,必须是唯一的,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"remotekeycol",starg.remotekeycol,30);
if (strlen(starg.remotekeycol)==0) { logfile.Write("remotekeycol is null.\n"); return false; }
// 本地表的键值字段名,必须是唯一的,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"localkeycol",starg.localkeycol,30);
if (strlen(starg.localkeycol)==0) { logfile.Write("localkeycol is null.\n"); return false; }
// 每批执行一次同步操作的记录数,不能超过MAXPARAMS宏(在_mysql.h中定义),当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"maxcount",&starg.maxcount);
if (starg.maxcount==0) { logfile.Write("maxcount is null.\n"); return false; }
if (starg.maxcount>MAXPARAMS) starg.maxcount=MAXPARAMS;
}
// 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。
GetXMLBuffer(strxmlbuffer,"timeout",&starg.timeout);
if (starg.timeout==0) { logfile.Write("timeout is null.\n"); return false; }
// 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。
GetXMLBuffer(strxmlbuffer,"pname",starg.pname,50);
if (strlen(starg.pname)==0) { logfile.Write("pname is null.\n"); return false; }
return true;
}
void EXIT(int sig)
{
logfile.Write("程序退出,sig=%d\n\n",sig);
connloc.disconnect();
connrem.disconnect();
exit(0);
}再来看业务处理的主函数:
bool _syncupdate()
{
CTimer Timer; //计时类
sqlstatement stmtdel(&connloc); //删除本地表中记录的sql语句
sqlstatement stmtins(&connloc); //向本地表中插入数据的sql语句
//如果是不分批同步,表示需要同步的数据量比较少,执行一次sql语句就可以完成
if(starg.synctype==1)
{
logfile.Write("sync %s to %s ...",starg.fedtname,starg.localtname);
//先删除starg.localtname本地表中满足where条件的记录。
stmtdel.prepare("delete from %s %s",starg.localtname,starg.where);
if(stmtins.execute()!=0)
{
logfile.Write("stmtdel.execute() failed.\n%s\n%s\n",stmtdel.m_sql,stmtdel.m_cda.message);
return false;
}
//再把starg.fedtname表中满足where条件的记录插入到starg.localtname表中
stmtins.prepare("insert into %s(%s) select %s from %s %s",starg.localtname,starg.localcols,starg.remotecols,starg.fedtname,starg.where);
if(stmtins.execute()!=0)
{
logfile.Write("stmtins.execute() failed.\n%s\n%s\n",stmtins.m_sql,stmtins.m_cda.message);
connloc.rollback(); //插入失败,回滚事务
return false;
}
//记录下操作的行数,以及消耗时间
logfile.Write(" %d row in %.2fsec.\n",stmtins.m_cda.rpc,Timer.Elapsed());
connloc.commit(); //提交事务
return true;
}
return true;
}本部分备份为/project/tools1/c/syncupdate2.cpp
先手工清空本地数据库表T_ZHOBTCODE2中的全部数据,使用第一个参数运行,查看日志,接着修改一下运行参数,添加一个where条件:再清空表,运行查看日志:
//在最后添加了<where>字段的运行参数
./syncupdate /log/idc/syncupdate_ZHOBTCODE2.log "<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTCODE1</fedtname><localtname>T_ZHOBTCODE2</localtname><remotecols>obtid,cityname,provname,lat,lon,height/10,upttime,keyid</remotecols><localcols>stid,cityname,provname,lat,lon,altitude,upttime,keyid</localcols><synctype>1</synctype><timeout>50</timeout><pname>syncupdate_ZHOBTCODE2</pname><where>where provname='广东'</where>"
2023-09-08 19:47:06 sync LK_ZHOBTCODE1 to T_ZHOBTCODE2 ...2023-09-08 19:47:06 839 row in 0.02sec.
2023-09-08 19:55:16 sync LK_ZHOBTCODE1 to T_ZHOBTCODE2 ...2023-09-08 19:55:16 37 row in 0.01sec.8.3刷新同步--分批刷新
在上一节中,已经完成了全表刷新的流程,本节完成分批刷新。接着在业务处理主函数的后面添加代码。
根据第一句查询语句:obtid是starg.remotekeycol,T_ZHOBTCODE1是starg.remotetname,
where条件使用参数来灵活调整。
//实际语句
select obtid from T_ZHOBTCODE1 where provname='广东' and obtid like '592%';
//代码语句
select starg.remotekeycol from starg.remotetname where provname='广东' and obtid like '592%';数组remkeyvalue[51]用于存放查询的结果,使用bindout函数来实现。
// 把connrem的连数据库的代码放在这里,如果synctype==1,根本就不用以下代码了。
if (connrem.connecttodb(starg.remoteconnstr,starg.charset) != 0)
{
logfile.Write("connect database(%s) failed.\n%s\n",starg.remoteconnstr,connrem.m_cda.message); return false;
}
// logfile.Write("connect database(%s) ok.\n",starg.remoteconnstr);
// 从远程表查找的需要同步记录的key字段的值。
char remkeyvalue[51]; // 从远程表查到的需要同步记录的key字段的值。
sqlstatement stmtsel(&connrem);
stmtsel.prepare("select %s from %s %s",starg.remotekeycol,starg.remotetname,starg.where);
stmtsel.bindout(1,remkeyvalue,50);接着我们看分批刷新的删除sql语句:
//实际语句
DELETE FROM t_zhobtcode3 where stid in ('59271','59278','59280');
//代码中语句
DELETE FROM starg.localtname where starg.localkeycol in (:1,:2,:3...:starg.maxcount);
首先处理(:1,:2,:3...:starg.maxcount)这一部分:一次性最多删除starg.maxcount条,注意数组下标从0开始,绑定从1开始。%lu是无符号长整数。完成这一步就可以准备删除的sql语句了。
// 拼接绑定同步SQL语句参数的字符串(:1,:2,:3,...,:starg.maxcount)。
char bindstr[2001]; // 绑定同步SQL语句参数的字符串。
char strtemp[11];
memset(bindstr,0,sizeof(bindstr));
for (int ii=0;ii<starg.maxcount;ii++)
{
memset(strtemp,0,sizeof(strtemp));
sprintf(strtemp,":%lu,",ii+1);
strcat(bindstr,strtemp);
}
bindstr[strlen(bindstr)-1]=0; // 最后一个逗号是多余的。使用二维数组,每一行代表一个key字段:
char keyvalues[starg.maxcount][50]; //存放key字段的值
//准备删除本地表数据的sql语句,一次删除starg.maxcount条记录。
//delete from T_ZHOBTCODE3 where stid in (:1,:2,:3...,:starg.maxcount);
stmtdel.prepare("delete from %s where %s in (%s)",starg.localtname,starg.localkeycol,bindstr);
for(int ii=0;ii<starg.maxcount;ii++)
{
stmtdel.bindin(ii+1,keyvalues[ii],50);
}
准备插入的sql语句:
// 准备插入本地表数据的SQL语句,一次插入starg.maxcount条记录。
// insert into T_ZHOBTCODE3(stid ,cityname,provname,lat,lon,altitude,upttime,keyid)
// select obtid,cityname,provname,lat,lon,height/10,upttime,keyid from LK_ZHOBTCODE1
// where obtid in (:1,:2,:3);
stmtins.prepare("insert into %s(%s) select %s from %s where %s in (%s)",starg.localtname,starg.localcols,starg.remotecols,starg.fedtname,starg.remotekeycol,bindstr);
for (int ii=0;ii<starg.maxcount;ii++)
{
stmtins.bindin(ii+1,keyvalues[ii],50);
}
准备好三个sql语句后,就可以首先执行查询的sql语句,然后从结果集中取出记录,放入数组keyvalues中,这样一来,(:1,:2,:3...:starg.maxcount)这一部分的字段值内容就有了。接着就可以执行删除的sql和插入的sql语句了。如果记录条数不够maxcount条,需要再执行一次删除和插入。
业务处理主函数的剩余代码如下:
int ccount=0; // 记录从结果集中已获取记录的计数器。
memset(keyvalues,0,sizeof(keyvalues));
//执行查询sql语句
if (stmtsel.execute()!=0)
{
logfile.Write("stmtsel.execute() failed.\n%s\n%s\n",stmtsel.m_sql,stmtsel.m_cda.message); return false;
}
while (true)
{
// 获取需要同步数据的结果集。
if (stmtsel.next()!=0) break;
// 将结果集中的字段值放入数组
strcpy(keyvalues[ccount],remkeyvalue);
ccount++;
// 每starg.maxcount条记录执行一次同步。
if (ccount==starg.maxcount)
{
// 从本地表中删除记录。
if (stmtdel.execute()!=0)
{
// 执行从本地表中删除记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtdel.execute() failed.\n%s\n%s\n",stmtdel.m_sql,stmtdel.m_cda.message); return false;
}
// 向本地表中插入记录。
if (stmtins.execute()!=0)
{
// 执行向本地表中插入记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtins.execute() failed.\n%s\n%s\n",stmtins.m_sql,stmtins.m_cda.message); return false;
}
logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n",starg.fedtname,starg.localtname,ccount,Timer.Elapsed());
connloc.commit();
ccount=0; // 完成一次插入后计数器清0,重新开始放入
memset(keyvalues,0,sizeof(keyvalues));
PActive.UptATime(); //更新心跳时间
}
}
// 如果ccount>0,表示还有没同步的记录,再执行一次同步。
if (ccount>0)
{
// 从本地表中删除记录。
if (stmtdel.execute()!=0)
{
logfile.Write("stmtdel.execute() failed.\n%s\n%s\n",stmtdel.m_sql,stmtdel.m_cda.message); return false;
}
// 向本地表中插入记录。
if (stmtins.execute()!=0)
{
logfile.Write("stmtins.execute() failed.\n%s\n%s\n",stmtins.m_sql,stmtins.m_cda.message); return false;
}
logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n",starg.fedtname,starg.localtname,ccount,Timer.Elapsed());
connloc.commit();
}
编译,使用第二段参数运行,这是使用分批刷新同步的方式来操作表3:T_ZHOBTCODE3。接着打开powerdesigner软件,复制两次全国站点分钟观测表1,即T_ZHOBTMIND1,修改字段名称:
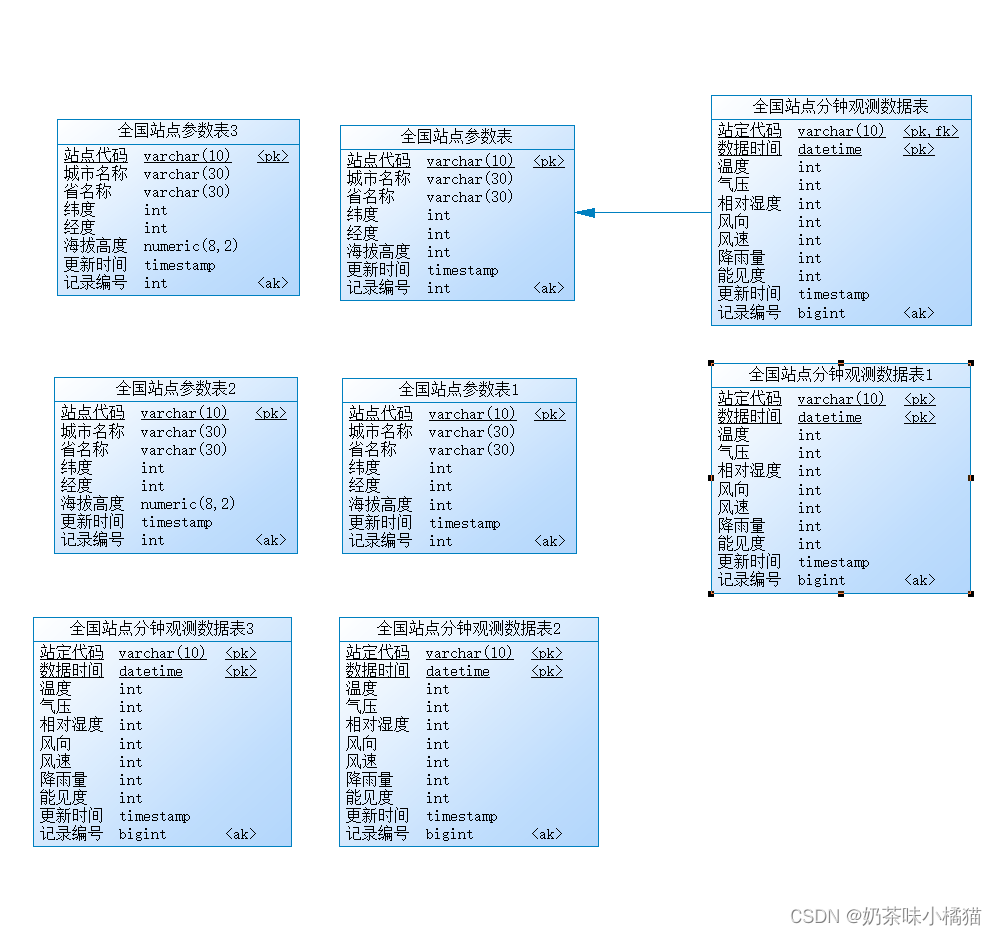
修改说明文字:
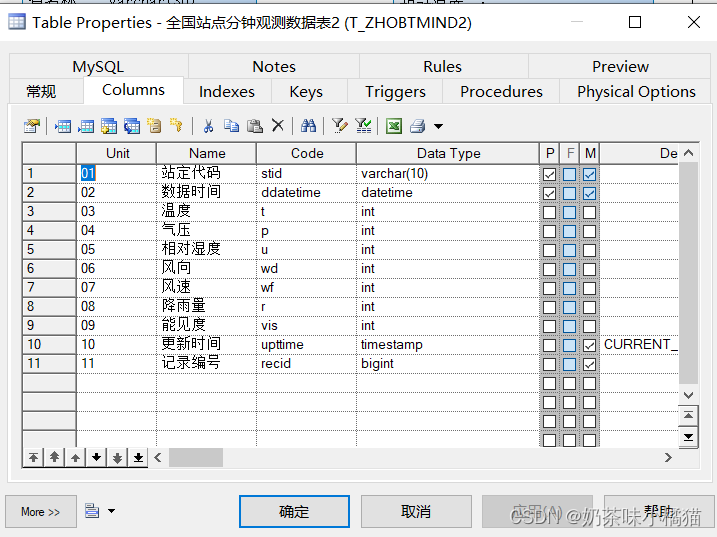
修改字段名:将站点代码由obtid改为stid,将记录编号由keyid改为recid,其他不变。
使用第三段参数运行程序,刷新同步站点分钟观测数据,部分日志:
//分批刷新同步站点参数表
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.01sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(10 rows) in 0.00sec.
2023-09-09 20:06:35 sync LK_ZHOBTCODE1 to T_ZHOBTCODE3(6 rows) in 0.00sec.
//分批刷新同步站点分钟观测数据表
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.04sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.04sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.04sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.04sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.05sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.05sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.05sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.05sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(256 rows) in 0.05sec.
2023-09-09 21:01:02 sync LK_ZHOBTMIND1 to T_ZHOBTMIND2(127 rows) in 0.03sec.
该程序基本功能已经完善,本部分命名为/project/tools1/scyncupdate.cpp
8.4刷新同步--增量同步
开发增量同步的功能有两个要求,一是远程表的数据只有插入,没有修改和删除操作,二是远程表要有自增字段。在原程序的基础上进行修改:cp syncupdate.cpp syncincrement.cpp
修改了一些说明文字,删除了同步类型synctype参数,这是因为增量同步肯定是刷新同步,所以关于全表刷新的代码也可以全部删除,只留下分批刷新的代码。
where参数也需要修改:增量同步的思想是先从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。再从远程表查找自增字段的值大于maxkeyvalue的记录。前面部分是固定的,后面可以添加and关键字加上一些格外的条件。
添加一个新参数timetvl。全表刷新和分批刷新的程序不是常驻内存的,是由调度程序每隔一段时间来进行启动的。而增量刷新同步是常驻内存的。这是因为刷新同步的时间间隔一般不会太短,根据业务需求,可能几小时,一天才刷新一次。没有必要每隔十几秒就刷新一次。而增量同步就不一样,业务的需求是越快越好,并且增量同步是根据自增字段来同步的,有数据就同步,没有数据就不进行同步,对数据库造成的压力比较小。所以每隔若干秒进行一次增量同步,时间间隔的大小取决于业务需求。
printf("where 同步数据的条件,填充在select remotekeycol from remotetname where remotekeycol>:1之后,\n"\
" 注意,不要加where关键字,但是,需要加and关键字。\n");
printf("timetvl 执行同步的时间间隔,单位:秒,取值1-30。\n");结构体以及参数解析函数也需要做相应调整:这里需要注意,程序的超时时间肯定要比执行同步的时间间隔要长。同时替换程序中update为increment。
// 执行同步的时间间隔,单位:秒,取值1-30。
GetXMLBuffer(strxmlbuffer,"timetvl",&starg.timetvl);
if (starg.timetvl<=0) { logfile.Write("timetvl is null.\n"); return false; }
if (starg.timetvl>30) starg.timetvl=30;
// 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。
GetXMLBuffer(strxmlbuffer,"timeout",&starg.timeout);
if (starg.timeout==0) { logfile.Write("timeout is null.\n"); return false; }
// 以下处理timetvl和timeout的方法虽然有点随意,但也问题不大,不让程序超时就可以了。
if (starg.timeout<starg.timetvl+10) starg.timeout=starg.timetvl+10;
在程序的开头声明存放自增字段最大值的全局变量以及查找函数:
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
long maxkeyvalue=0;
bool findmaxkey();程序的流程不难,注意是从本地表中查询最大值,所以绑定的是本地数据库连接。在最后记得获取结果集。
bool findmaxkey()
{
maxkeyvalue=0;
sqlstatement stmt(&connloc);
stmt.prepare("select max(%s) from %s",starg.localkeycol,starg.localtname);
stmt.bindout(1,&maxkeyvalue);
if (stmt.execute()!=0)
{
logfile.Write("stmt.execute() failed.\n%s\n%s\n",stmt.m_sql,stmt.m_cda.message); return false;
}
stmt.next();
// logfile.Write("maxkeyvalue=%ld\n",maxkeyvalue);
return true;
}
在业务处理主流程函数中添加调用代码:下面的sql语句代码也做了一些修改,
// 业务处理主函数。
bool _syncincrement(bool &bcontinue)
{
CTimer Timer;
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
if (findmaxkey()==false) return false;
// 从远程表查找自增字段的值大于maxkeyvalue的记录。
char remkeyvalue[51]; // 从远程表查到的需要同步记录的key字段的值。
sqlstatement stmtsel(&connrem);
stmtsel.prepare("select %s from %s where %s>:1 %s order by %s",starg.remotekeycol,starg.remotetname,starg.remotekeycol,starg.where,starg.remotekeycol);
stmtsel.bindin(1,&maxkeyvalue);
stmtsel.bindout(1,remkeyvalue,50);这部分都是在原来程序上修修改改,写起来会觉得有点乱,也不能说面面俱到全部记录下来,那样会会十分啰嗦而且没有什么意义。最好的办法是直接给出全部的代码,自己琢磨两个程序有什么不同,如果真的学会了分批刷新,增量刷新并不是什么难事。接下来对程序进行一些优化:
现在的同步程序执行一次就退出了,添加一个while循环使其常驻内存,如果同步失败,程序退出,再sleep,做一次心跳。还可以继续优化,如果这一次执行同步有数据,表示数据可能在不断的生成中,那么这一次同步完以后就不再sleep,继续下一次同步。这种处理方法在前面章节的入库程序里也用到了。变量bcontinue先在程序中先初始化为false,如果查询的结果集结果大于0,表示有数据,将它置为true。
优化日志的记录,每次同步只写一条日志
bool bcontinue;
// 业务处理主函数。
while (true)
{
if (_syncincrement(bcontinue)==false) EXIT(-1);
if (bcontinue==false) sleep(starg.timetvl);
PActive.UptATime();
}
...
_syncincrement(bcontinue):
if (stmtsel.m_cda.rpc>0)
{
logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n",starg.fedtname,starg.localtname,stmtsel.m_cda.rpc,Timer.Elapsed());
bcontinue=true;
}
return true;
}完整的代码:
#include "_tools.h"
struct st_arg
{
char localconnstr[101]; // 本地数据库的连接参数。
char charset[51]; // 数据库的字符集。
char fedtname[31]; // Federated表名。
char localtname[31]; // 本地表名。
char remotecols[1001]; // 远程表的字段列表。
char localcols[1001]; // 本地表的字段列表。
char where[1001]; // 同步数据的条件。
char remoteconnstr[101]; // 远程数据库的连接参数。
char remotetname[31]; // 远程表名。
char remotekeycol[31]; // 远程表的自增字段名。
char localkeycol[31]; // 本地表的自增字段名。
int maxcount; // 每批执行一次同步操作的记录数。
int timetvl; // 同步时间间隔,单位:秒,取值1-30。
int timeout; // 本程序运行时的超时时间。
char pname[51]; // 本程序运行时的程序名。
} starg;
// 显示程序的帮助
void _help(char *argv[]);
// 把xml解析到参数starg结构中
bool _xmltoarg(char *strxmlbuffer);
CLogFile logfile;
connection connloc; // 本地数据库连接。
connection connrem; // 远程数据库连接。
// 业务处理主函数。
bool _syncincrement(bool &bcontinue);
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
long maxkeyvalue=0;
bool findmaxkey();
void EXIT(int sig);
CPActive PActive;
int main(int argc,char *argv[])
{
if (argc!=3) { _help(argv); return -1; }
// 关闭全部的信号和输入输出,处理程序退出的信号。
CloseIOAndSignal(); signal(SIGINT,EXIT); signal(SIGTERM,EXIT);
if (logfile.Open(argv[1],"a+")==false)
{
printf("打开日志文件失败(%s)。\n",argv[1]); return -1;
}
// 把xml解析到参数starg结构中
if (_xmltoarg(argv[2])==false) return -1;
PActive.AddPInfo(starg.timeout,starg.pname);
// 注意,在调试程序的时候,可以启用类似以下的代码,防止超时。
// PActive.AddPInfo(starg.timeout*100,starg.pname);
if (connloc.connecttodb(starg.localconnstr,starg.charset) != 0)
{
logfile.Write("connect database(%s) failed.\n%s\n",starg.localconnstr,connloc.m_cda.message); EXIT(-1);
}
// logfile.Write("connect database(%s) ok.\n",starg.localconnstr);
if (connrem.connecttodb(starg.remoteconnstr,starg.charset) != 0)
{
logfile.Write("connect database(%s) failed.\n%s\n",starg.remoteconnstr,connrem.m_cda.message); return false;
}
// logfile.Write("connect database(%s) ok.\n",starg.remoteconnstr);
// 如果starg.remotecols或starg.localcols为空,就用starg.localtname表的全部列来填充。
if ( (strlen(starg.remotecols)==0) || (strlen(starg.localcols)==0) )
{
CTABCOLS TABCOLS;
// 获取starg.localtname表的全部列。
if (TABCOLS.allcols(&connloc,starg.localtname)==false)
{
logfile.Write("表%s不存在。\n",starg.localtname); EXIT(-1);
}
if (strlen(starg.remotecols)==0) strcpy(starg.remotecols,TABCOLS.m_allcols);
if (strlen(starg.localcols)==0) strcpy(starg.localcols,TABCOLS.m_allcols);
}
bool bcontinue;
// 业务处理主函数。
while (true)
{
if (_syncincrement(bcontinue)==false) EXIT(-1);
if (bcontinue==false) sleep(starg.timetvl);
PActive.UptATime();
}
}
// 显示程序的帮助
void _help(char *argv[])
{
printf("Using:/project/tools1/bin/syncincrement logfilename xmlbuffer\n\n");
printf("Sample:/project/tools1/bin/procctl 10 /project/tools1/bin/syncincrement /log/idc/syncincrement_ZHOBTMIND2.log \"<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND2</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrement1_ZHOBTMIND2</pname>\"\n\n");
printf(" /project/tools1/bin/procctl 10 /project/tools1/bin/syncincrement /log/idc/syncincrement_ZHOBTMIND3.log \"<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND3</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><where>and obtid like '54%%%%'</where><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrement1_ZHOBTMIND3</pname>\"\n\n");
printf("本程序是数据中心的公共功能模块,采用增量的方法同步MySQL数据库之间的表。\n\n");
printf("logfilename 本程序运行的日志文件。\n");
printf("xmlbuffer 本程序运行的参数,用xml表示,具体如下:\n\n");
printf("localconnstr 本地数据库的连接参数,格式:ip,username,password,dbname,port。\n");
printf("charset 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。\n");
printf("fedtname Federated表名。\n");
printf("localtname 本地表名。\n");
printf("remotecols 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,\n"\
" 也可以是函数的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
printf("localcols 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,\n"\
" 就用localtname表的字段列表填充。\n");
printf("where 同步数据的条件,填充在select remotekeycol from remotetname where remotekeycol>:1之后,\n"\
" 注意,不要加where关键字,但是,需要加and关键字。\n");
printf("remoteconnstr 远程数据库的连接参数,格式与localconnstr相同。\n");
printf("remotetname 远程表名。\n");
printf("remotekeycol 远程表的自增字段名。\n");
printf("localkeycol 本地表的自增字段名。\n");
printf("maxcount 每批执行一次同步操作的记录数,不能超过MAXPARAMS宏(在_mysql.h中定义),当synctype==2时有效。\n");
printf("timetvl 执行同步的时间间隔,单位:秒,取值1-30。\n");
printf("timeout 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。\n");
printf("pname 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。\n\n\n");
}
// 把xml解析到参数starg结构中
bool _xmltoarg(char *strxmlbuffer)
{
memset(&starg,0,sizeof(struct st_arg));
// 本地数据库的连接参数,格式:ip,username,password,dbname,port。
GetXMLBuffer(strxmlbuffer,"localconnstr",starg.localconnstr,100);
if (strlen(starg.localconnstr)==0) { logfile.Write("localconnstr is null.\n"); return false; }
// 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。
GetXMLBuffer(strxmlbuffer,"charset",starg.charset,50);
if (strlen(starg.charset)==0) { logfile.Write("charset is null.\n"); return false; }
// Federated表名。
GetXMLBuffer(strxmlbuffer,"fedtname",starg.fedtname,30);
if (strlen(starg.fedtname)==0) { logfile.Write("fedtname is null.\n"); return false; }
// 本地表名。
GetXMLBuffer(strxmlbuffer,"localtname",starg.localtname,30);
if (strlen(starg.localtname)==0) { logfile.Write("localtname is null.\n"); return false; }
// 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,也可以是函数
// 的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
GetXMLBuffer(strxmlbuffer,"remotecols",starg.remotecols,1000);
// 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,就用localtname表的字段列表填充。
GetXMLBuffer(strxmlbuffer,"localcols",starg.localcols,1000);
// 同步数据的条件,即select语句的where部分。
GetXMLBuffer(strxmlbuffer,"where",starg.where,1000);
// 远程数据库的连接参数,格式与localconnstr相同,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"remoteconnstr",starg.remoteconnstr,100);
if (strlen(starg.remoteconnstr)==0) { logfile.Write("remoteconnstr is null.\n"); return false; }
// 远程表名,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"remotetname",starg.remotetname,30);
if (strlen(starg.remotetname)==0) { logfile.Write("remotetname is null.\n"); return false; }
// 远程表的自增字段名。
GetXMLBuffer(strxmlbuffer,"remotekeycol",starg.remotekeycol,30);
if (strlen(starg.remotekeycol)==0) { logfile.Write("remotekeycol is null.\n"); return false; }
// 本地表的自增字段名。
GetXMLBuffer(strxmlbuffer,"localkeycol",starg.localkeycol,30);
if (strlen(starg.localkeycol)==0) { logfile.Write("localkeycol is null.\n"); return false; }
// 每批执行一次同步操作的记录数,不能超过MAXPARAMS宏(在_mysql.h中定义),当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"maxcount",&starg.maxcount);
if (starg.maxcount==0) { logfile.Write("maxcount is null.\n"); return false; }
if (starg.maxcount>MAXPARAMS) starg.maxcount=MAXPARAMS;
// 执行同步的时间间隔,单位:秒,取值1-30。
GetXMLBuffer(strxmlbuffer,"timetvl",&starg.timetvl);
if (starg.timetvl<=0) { logfile.Write("timetvl is null.\n"); return false; }
if (starg.timetvl>30) starg.timetvl=30;
// 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。
GetXMLBuffer(strxmlbuffer,"timeout",&starg.timeout);
if (starg.timeout==0) { logfile.Write("timeout is null.\n"); return false; }
// 以下处理timetvl和timeout的方法虽然有点随意,但也问题不大,不让程序超时就可以了。
if (starg.timeout<starg.timetvl+10) starg.timeout=starg.timetvl+10;
// 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。
GetXMLBuffer(strxmlbuffer,"pname",starg.pname,50);
if (strlen(starg.pname)==0) { logfile.Write("pname is null.\n"); return false; }
return true;
}
void EXIT(int sig)
{
logfile.Write("程序退出,sig=%d\n\n",sig);
connloc.disconnect();
connrem.disconnect();
exit(0);
}
// 业务处理主函数。
bool _syncincrement(bool &bcontinue)
{
CTimer Timer;
bcontinue=false;
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
if (findmaxkey()==false) return false;
// 从远程表查找自增字段的值大于maxkeyvalue的记录。
char remkeyvalue[51]; // 从远程表查到的需要同步记录的key字段的值。
sqlstatement stmtsel(&connrem);
stmtsel.prepare("select %s from %s where %s>:1 %s order by %s",starg.remotekeycol,starg.remotetname,starg.remotekeycol,starg.where,starg.remotekeycol);
stmtsel.bindin(1,&maxkeyvalue);
stmtsel.bindout(1,remkeyvalue,50);
// 拼接绑定同步SQL语句参数的字符串(:1,:2,:3,...,:starg.maxcount)。
char bindstr[2001]; // 绑定同步SQL语句参数的字符串。
char strtemp[11];
memset(bindstr,0,sizeof(bindstr));
for (int ii=0;ii<starg.maxcount;ii++)
{
memset(strtemp,0,sizeof(strtemp));
sprintf(strtemp,":%lu,",ii+1);
strcat(bindstr,strtemp);
}
bindstr[strlen(bindstr)-1]=0; // 最后一个逗号是多余的。
char keyvalues[starg.maxcount][51]; // 存放key字段的值。
// 准备插入本地表数据的SQL语句,一次插入starg.maxcount条记录。
// insert into T_ZHOBTMIND2(stid ,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid)
// select obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid from LK_ZHOBTMIND1
// where keyid in (:1,:2,:3);
sqlstatement stmtins(&connloc); // 向本地表中插入数据的SQL语句。
stmtins.prepare("insert into %s(%s) select %s from %s where %s in (%s)",starg.localtname,starg.localcols,starg.remotecols,starg.fedtname,starg.remotekeycol,bindstr);
for (int ii=0;ii<starg.maxcount;ii++)
{
stmtins.bindin(ii+1,keyvalues[ii],50);
}
int ccount=0; // 记录从结果集中已获取记录的计数器。
memset(keyvalues,0,sizeof(keyvalues));
if (stmtsel.execute()!=0)
{
logfile.Write("stmtsel.execute() failed.\n%s\n%s\n",stmtsel.m_sql,stmtsel.m_cda.message); return false;
}
while (true)
{
// 获取需要同步数据的结果集。
if (stmtsel.next()!=0) break;
strcpy(keyvalues[ccount],remkeyvalue);
ccount++;
// 每starg.maxcount条记录执行一次同步。
if (ccount==starg.maxcount)
{
// 向本地表中插入记录。
if (stmtins.execute()!=0)
{
// 执行向本地表中插入记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtins.execute() failed.\n%s\n%s\n",stmtins.m_sql,stmtins.m_cda.message); return false;
}
// logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n",starg.fedtname,starg.localtname,ccount,Timer.Elapsed());
connloc.commit();
ccount=0; // 记录从结果集中已获取记录的计数器。
memset(keyvalues,0,sizeof(keyvalues));
PActive.UptATime();
}
}
// 如果ccount>0,表示还有没同步的记录,再执行一次同步。
if (ccount>0)
{
// 向本地表中插入记录。
if (stmtins.execute()!=0)
{
logfile.Write("stmtins.execute() failed.\n%s\n%s\n",stmtins.m_sql,stmtins.m_cda.message); return false;
}
// logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n",starg.fedtname,starg.localtname,ccount,Timer.Elapsed());
connloc.commit();
}
if (stmtsel.m_cda.rpc>0)
{
logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n",starg.fedtname,starg.localtname,stmtsel.m_cda.rpc,Timer.Elapsed());
bcontinue=true;
}
return true;
}
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
bool findmaxkey()
{
maxkeyvalue=0;
sqlstatement stmt(&connloc);
stmt.prepare("select max(%s) from %s",starg.localkeycol,starg.localtname);
stmt.bindout(1,&maxkeyvalue);
if (stmt.execute()!=0)
{
logfile.Write("stmt.execute() failed.\n%s\n%s\n",stmt.m_sql,stmt.m_cda.message); return false;
}
stmt.next();
// logfile.Write("maxkeyvalue=%ld\n",maxkeyvalue);
return true;
}
第一段运行参数是不带where条件的,可以自己向远程表手工插入一条记录看看程序执行的效果。
<maxcount>300</maxcount>代表着每批同步的记录数,这个参数的取值很有讲究,取值为1时的效率比取值为200时的效率慢了好几倍,这是显而易见的。但是取值也不是越大越好,取值为100时数据库的吞吐能力大概到了极限,再大也没有意义。
配置启动脚本与清理程序:停止脚本我就不写上去了。
# 采用全表刷新同步的方法,把表T_ZHOBTCODE1中的数据同步到表T_ZHOBTCODE2
/project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTCODE2.log "<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTCODE1</fedtname><localtname>T_ZHOBTCODE2</localtname><remotecols>obtid,cityname,provname,lat,lon,height/10,upttime,keyid</remotecols><localcols>stid,cityname,provname,lat,lon,altitude,upttime,keyid</localcols><synctype>1</synctype><timeout>50</timeout><pname>syncupdate_ZHOBTCODE2</pname>"
# 采用分批同步的方法,把表T_ZHOBTCODE1中obtid like '54%'的记录同步到表T_ZHOBTCODE3
/project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTCODE3.log "<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTCODE1</fedtname><localtname>T_ZHOBTCODE3</localtname><remotecols>obtid,cityname,provname,lat,lon,height/10,upttime,keyid</remotecols><localcols>stid,cityname,provname,lat,lon,altitude,upttime,keyid</localcols><where>where obtid like '54%%'</where><synctype>2</synctype><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><remotetname>T_ZHOBTCODE1</remotetname><remotekeycol>obtid</remotekeycol><localkeycol>stid</localkeycol><maxcount>10</maxcount><timeout>50</timeout><pname>syncupdate_ZHOBTCODE3</pname>"
# 采用增量同步的方法,把表T_ZHOBTMIND1中全部的记录同步到表T_ZHOBTMIND2
/project/tools1/bin/procctl 10 /project/tools1/bin/syncincrement /log/idc/syncincrement_ZHOBTMIND2.log "<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND2</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrement1_ZHOBTMIND2</pname>"
# 采用增量同步的方法,把表T_ZHOBTMIND1中obtid like '54%'的记录同步到表T_ZHOBTMIND3
/project/tools1/bin/procctl 10 /project/tools1/bin/syncincrement /log/idc/syncincrement_ZHOBTMIND3.log "<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND3</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><where>and obtid like '54%%'</where><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrement1_ZHOBTMIND3</pname>"清理程序
/project/idc1/sql
delete from T_ZHOBTMIND1 where ddatetime<timestampadd(minute,-120,now());
delete from T_ZHOBTMIND2 where ddatetime<timestampadd(minute,-120,now());
delete from T_ZHOBTMIND3 where ddatetime<timestampadd(minute,-120,now());8.5不使用federated引擎的刷新同步
实际上,不使用该引擎完成同步的实用性会更高。思路还是从远程表中查询数据,放入内存变量中,再插入本地表中,程序的代码建议自己思考。我直接放出源码方便对照学习。编译失败时请更新一下头文件_tools.h,添加了一个新的成员变量,在/project/tools/c/_tools.h文件
中给出,同时本程序也是下一章的基础,请务必研究一下。
/*
* 程序名:syncincrementex.cpp,本程序是数据中心的公共功能模块,采用增量的方法同步MySQL数据库之间的表。
* 注意,本程序不使用Federated引擎。
* 作者:sxixia
*/
#include "_tools.h"
struct st_arg
{
char localconnstr[101]; // 本地数据库的连接参数。
char charset[51]; // 数据库的字符集。
char localtname[31]; // 本地表名。
char remotecols[1001]; // 远程表的字段列表。
char localcols[1001]; // 本地表的字段列表。
char where[1001]; // 同步数据的条件。
char remoteconnstr[101]; // 远程数据库的连接参数。
char remotetname[31]; // 远程表名。
char remotekeycol[31]; // 远程表的自增字段名。
char localkeycol[31]; // 本地表的自增字段名。
int timetvl; // 同步时间间隔,单位:秒,取值1-30。
int timeout; // 本程序运行时的超时时间。
char pname[51]; // 本程序运行时的程序名。
} starg;
// 显示程序的帮助
void _help(char *argv[]);
// 把xml解析到参数starg结构中
bool _xmltoarg(char *strxmlbuffer);
CLogFile logfile;
connection connloc; // 本地数据库连接。
connection connrem; // 远程数据库连接。
CTABCOLS TABCOLS; // 读取数据字典,获取本地表全部的列信息。
// 业务处理主函数。
bool _syncincrementex(bool &bcontinue);
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
long maxkeyvalue=0;
bool findmaxkey();
void EXIT(int sig);
CPActive PActive;
int main(int argc,char *argv[])
{
if (argc!=3) { _help(argv); return -1; }
// 关闭全部的信号和输入输出,处理程序退出的信号。
CloseIOAndSignal(); signal(SIGINT,EXIT); signal(SIGTERM,EXIT);
if (logfile.Open(argv[1],"a+")==false)
{
printf("打开日志文件失败(%s)。\n",argv[1]); return -1;
}
// 把xml解析到参数starg结构中
if (_xmltoarg(argv[2])==false) return -1;
PActive.AddPInfo(starg.timeout,starg.pname);
// 注意,在调试程序的时候,可以启用类似以下的代码,防止超时。
// PActive.AddPInfo(starg.timeout*100,starg.pname);
if (connloc.connecttodb(starg.localconnstr,starg.charset) != 0)
{
logfile.Write("connect database(%s) failed.\n%s\n",starg.localconnstr,connloc.m_cda.message); EXIT(-1);
}
// logfile.Write("connect database(%s) ok.\n",starg.localconnstr);
if (connrem.connecttodb(starg.remoteconnstr,starg.charset) != 0)
{
logfile.Write("connect database(%s) failed.\n%s\n",starg.remoteconnstr,connrem.m_cda.message); return false;
}
// logfile.Write("connect database(%s) ok.\n",starg.remoteconnstr);
// 获取starg.localtname表的全部列。
if (TABCOLS.allcols(&connloc,starg.localtname)==false)
{
logfile.Write("表%s不存在。\n",starg.localtname); EXIT(-1);
}
if (strlen(starg.remotecols)==0) strcpy(starg.remotecols,TABCOLS.m_allcols);
if (strlen(starg.localcols)==0) strcpy(starg.localcols,TABCOLS.m_allcols);
bool bcontinue;
// 业务处理主函数。
while (true)
{
if (_syncincrementex(bcontinue)==false) EXIT(-1);
if (bcontinue==false) sleep(starg.timetvl);
PActive.UptATime();
}
}
// 显示程序的帮助
void _help(char *argv[])
{
printf("Using:/project/tools1/bin/syncincrementex logfilename xmlbuffer\n\n");
printf("Sample:/project/tools1/bin/procctl 10 /project/tools1/bin/syncincrementex /log/idc/syncincrementex_ZHOBTMIND2.log \"<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><localtname>T_ZHOBTMIND2</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrementex1_ZHOBTMIND2</pname>\"\n\n");
printf(" /project/tools1/bin/procctl 10 /project/tools1/bin/syncincrementex /log/idc/syncincrementex_ZHOBTMIND3.log \"<localconnstr>127.0.0.1,root,root,ltbo1,3306</localconnstr><remoteconnstr>127.0.0.1,root,root,ltbo,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><localtname>T_ZHOBTMIND3</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><where>and obtid like '54%%%%'</where><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrementex1_ZHOBTMIND3</pname>\"\n\n");
printf("本程序是数据中心的公共功能模块,采用增量的方法同步MySQL数据库之间的表。\n\n");
printf("logfilename 本程序运行的日志文件。\n");
printf("xmlbuffer 本程序运行的参数,用xml表示,具体如下:\n\n");
printf("localconnstr 本地数据库的连接参数,格式:ip,username,password,dbname,port。\n");
printf("charset 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。\n");
printf("localtname 本地表名。\n");
printf("remotecols 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,\n"\
" 也可以是函数的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
printf("localcols 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,\n"\
" 就用localtname表的字段列表填充。\n");
printf("where 同步数据的条件,填充在select remotekeycol from remotetname where remotekeycol>:1之后,\n"\
" 注意,不要加where关键字,但是,需要加and关键字。\n");
printf("remoteconnstr 远程数据库的连接参数,格式与localconnstr相同。\n");
printf("remotetname 远程表名。\n");
printf("remotekeycol 远程表的自增字段名。\n");
printf("localkeycol 本地表的自增字段名。\n");
printf("timetvl 执行同步的时间间隔,单位:秒,取值1-30。\n");
printf("timeout 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。\n");
printf("pname 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。\n\n\n");
}
// 把xml解析到参数starg结构中
bool _xmltoarg(char *strxmlbuffer)
{
memset(&starg,0,sizeof(struct st_arg));
// 本地数据库的连接参数,格式:ip,username,password,dbname,port。
GetXMLBuffer(strxmlbuffer,"localconnstr",starg.localconnstr,100);
if (strlen(starg.localconnstr)==0) { logfile.Write("localconnstr is null.\n"); return false; }
// 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。
GetXMLBuffer(strxmlbuffer,"charset",starg.charset,50);
if (strlen(starg.charset)==0) { logfile.Write("charset is null.\n"); return false; }
// 本地表名。
GetXMLBuffer(strxmlbuffer,"localtname",starg.localtname,30);
if (strlen(starg.localtname)==0) { logfile.Write("localtname is null.\n"); return false; }
// 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,也可以是函数
// 的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
GetXMLBuffer(strxmlbuffer,"remotecols",starg.remotecols,1000);
// 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,就用localtname表的字段列表填充。
GetXMLBuffer(strxmlbuffer,"localcols",starg.localcols,1000);
// 同步数据的条件,即select语句的where部分。
GetXMLBuffer(strxmlbuffer,"where",starg.where,1000);
// 远程数据库的连接参数,格式与localconnstr相同,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"remoteconnstr",starg.remoteconnstr,100);
if (strlen(starg.remoteconnstr)==0) { logfile.Write("remoteconnstr is null.\n"); return false; }
// 远程表名,当synctype==2时有效。
GetXMLBuffer(strxmlbuffer,"remotetname",starg.remotetname,30);
if (strlen(starg.remotetname)==0) { logfile.Write("remotetname is null.\n"); return false; }
// 远程表的自增字段名。
GetXMLBuffer(strxmlbuffer,"remotekeycol",starg.remotekeycol,30);
if (strlen(starg.remotekeycol)==0) { logfile.Write("remotekeycol is null.\n"); return false; }
// 本地表的自增字段名。
GetXMLBuffer(strxmlbuffer,"localkeycol",starg.localkeycol,30);
if (strlen(starg.localkeycol)==0) { logfile.Write("localkeycol is null.\n"); return false; }
// 执行同步的时间间隔,单位:秒,取值1-30。
GetXMLBuffer(strxmlbuffer,"timetvl",&starg.timetvl);
if (starg.timetvl<=0) { logfile.Write("timetvl is null.\n"); return false; }
if (starg.timetvl>30) starg.timetvl=30;
// 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。
GetXMLBuffer(strxmlbuffer,"timeout",&starg.timeout);
if (starg.timeout==0) { logfile.Write("timeout is null.\n"); return false; }
// 以下处理timetvl和timeout的方法虽然有点随意,但也问题不大,不让程序超时就可以了。
if (starg.timeout<starg.timetvl+10) starg.timeout=starg.timetvl+10;
// 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。
GetXMLBuffer(strxmlbuffer,"pname",starg.pname,50);
if (strlen(starg.pname)==0) { logfile.Write("pname is null.\n"); return false; }
return true;
}
void EXIT(int sig)
{
logfile.Write("程序退出,sig=%d\n\n",sig);
connloc.disconnect();
connrem.disconnect();
exit(0);
}
// 业务处理主函数。
bool _syncincrementex(bool &bcontinue)
{
CTimer Timer;
bcontinue=false;
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
if (findmaxkey()==false) return false;
// 拆分starg.localcols参数,得到本地表字段的个数。
CCmdStr CmdStr;
CmdStr.SplitToCmd(starg.localcols,",");
int colcount=CmdStr.CmdCount();
// 从远程表查找自增字段的值大于maxkeyvalue的记录,存放在colvalues数组中。
char colvalues[colcount][TABCOLS.m_maxcollen+1];
sqlstatement stmtsel(&connrem);
stmtsel.prepare("select %s from %s where %s>:1 %s order by %s",starg.remotecols,starg.remotetname,starg.remotekeycol,starg.where,starg.remotekeycol);
stmtsel.bindin(1,&maxkeyvalue);
for (int ii=0;ii<colcount;ii++)
stmtsel.bindout(ii+1,colvalues[ii],TABCOLS.m_maxcollen);
// 拼接插入SQL语句绑定参数的字符串 insert ... into starg.localtname values(:1,:2,...:colcount)
char bindstr[2001]; // 绑定同步SQL语句参数的字符串。
char strtemp[11];
memset(bindstr,0,sizeof(bindstr));
for (int ii=0;ii<colcount;ii++)
{
memset(strtemp,0,sizeof(strtemp));
sprintf(strtemp,":%lu,",ii+1); // 这里可以处理一下时间字段。
strcat(bindstr,strtemp);
}
bindstr[strlen(bindstr)-1]=0; // 最后一个逗号是多余的。
// 准备插入本地表数据的SQL语句。
sqlstatement stmtins(&connloc); // 向本地表中插入数据的SQL语句。
stmtins.prepare("insert into %s(%s) values(%s)",starg.localtname,starg.localcols,bindstr);
for (int ii=0;ii<colcount;ii++)
{
stmtins.bindin(ii+1,colvalues[ii],TABCOLS.m_maxcollen);
}
if (stmtsel.execute()!=0)
{
logfile.Write("stmtsel.execute() failed.\n%s\n%s\n",stmtsel.m_sql,stmtsel.m_cda.message); return false;
}
while (true)
{
memset(colvalues,0,sizeof(colvalues));
// 获取需要同步数据的结果集。
if (stmtsel.next()!=0) break;
// 向本地表中插入记录。
if (stmtins.execute()!=0)
{
// 执行向本地表中插入记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtins.execute() failed.\n%s\n%s\n",stmtins.m_sql,stmtins.m_cda.message); return false;
}
// 每1000条提交一次。
if (stmtsel.m_cda.rpc%1000==0)
{
connloc.commit(); PActive.UptATime();
}
}
// 处理最后未提交的数据。
if (stmtsel.m_cda.rpc>0)
{
logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n",starg.remotetname,starg.localtname,stmtsel.m_cda.rpc,Timer.Elapsed());
connloc.commit();
bcontinue=true;
}
return true;
}
// 从本地表starg.localtname获取自增字段的最大值,存放在maxkeyvalue全局变量中。
bool findmaxkey()
{
maxkeyvalue=0;
sqlstatement stmt(&connloc);
stmt.prepare("select max(%s) from %s",starg.localkeycol,starg.localtname);
stmt.bindout(1,&maxkeyvalue);
if (stmt.execute()!=0)
{
logfile.Write("stmt.execute() failed.\n%s\n%s\n",stmt.m_sql,stmt.m_cda.message); return false;
}
stmt.next();
// logfile.Write("maxkeyvalue=%ld\n",maxkeyvalue);
return true;
}















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









