






> dose <- c(20,30,40,50,60)
> drugA <- c(16,20,40,45,60)
> drugB <- c(15,18,25,31,40)
> plot(dose,drugA,type = 'b')
效果Figure 1.所示,type = 'b' 指同时绘制线和点。
Figure 1.
修改图形的参数
有两种方式可以修改图形的参数:
1. 通过par()函数进行修改,一旦修改之后,直到下次修改参数之前所绘制的图都有效。par()是会生成一个含有当前图形设置的参数列表,par(no.readonly=TRUE)是生成可以修改的当前图形参数列表。
2. 通过键值对直接在绘图函数上修改,这样只会对只会对当前的图有效。
> opar <- par(no.readonly=TRUE)
> par(lty=2,pch=17)
> plot(dose,drugA,type='b')
> par(opar)
用键值对的方式实现同样的功能(Figure 2.):
plot(dose,drugA,type='b',lty=2,pch=17)
Figure 2.
点的符号和线条的修改
| 调控形状 | 调控大小(粗细) | |
| 点 | pch | cex |
| 线条 | lty | lwd |
pch、lty绘制点、线时使用的可能的参数:


符号21~25,还可以指定边界颜色( col= )和填充色( bg= )
颜色
有许多函数可以创建连续性颜色向量的函数:rainbow()、heat.colors()、terrain.colors()、topo.colors()、cm.colors()
> n <- 10
> mycolors <- rainbow(n)
> pie(rep(1,n), labels= mycolors, col= mycolors)
Figure 3.
> n <- 10
> mygrays <- gray(0:n/n)
> pie(rep(1,n), labels= mygrays, col= mygrays)
gray()是生成多阶灰度的颜色,颜色值在0-1之间。
Figure 4.
还有的其他颜色函数:
col.axis 坐标轴刻度文字的颜色
col.lab 坐标轴标签(名称)的颜色
col.main 标题颜色
col.sub 副标题颜色
fg 图形的前景色
bg 图形的背景色。。。。。代码应用
字号、字体、字样
图形尺寸 & 图形边界
pin()控制图形尺寸(宽高),单位是英寸
mai 用数值向量表示边界的大小,顺序初始位下,逆时针旋转。单位是英寸。
mar 和mai不同的是单位是英分。默认值为c(5, 4, 4, 2) + 0.1。一英分等于十二分之一英寸。
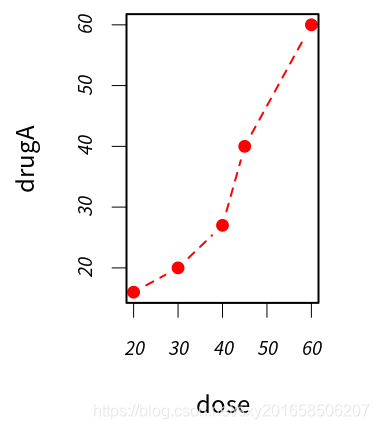
> dose <- c(20,30,40,45,60)
> drugA <- c(16,20,27,40,60)
> drugB <- c(15,18,25,31,40)
> opar <- par(no.readonly = TRUE)
> par(pin=c(2,3))
> par (lwd=2,cex=1.5)
> par(cex.axis=.75,font.axis=3)
> plot(dose,drugA,type='b',pch=19,lty=2,col='red')设置图形的宽x高=2x3英寸
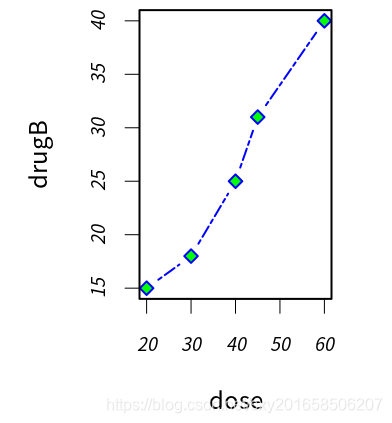
> dose <- c(20,30,40,45,60)
> drugA <- c(16,20,27,40,60)
> drugB <- c(15,18,25,31,40)
> opar <- par(no.readonly = TRUE)
> par(pin=c(2,3))
> par (lwd=2,cex=1.5)
> par(cex.axis=.75,font.axis=3)
> plot(dose,drugB,type='b',pch=23,lty=6,col='blue',bg='green')
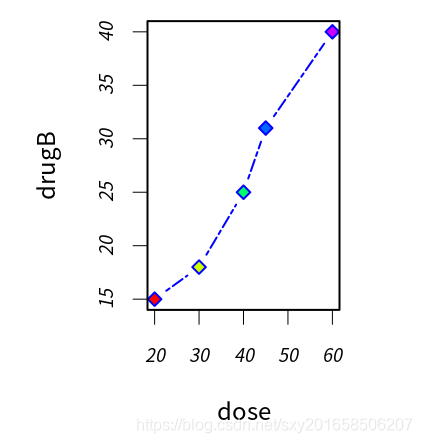
> dose <- c(20,30,40,45,60)
> drugA <- c(16,20,27,40,60)
> drugB <- c(15,18,25,31,40)
> opar <- par(no.readonly = TRUE)
> par(pin=c(2,3))
> par (lwd=2,cex=1.5)
> par(cex.axis=.75,font.axis=3)
> mycolors <- rainbow(5)
> plot(dose,drugB,type='b',pch=23,lty=6,col='blue',bg=mycolors)
练习一下bg颜色特效,col用在多条线时的颜色控制。
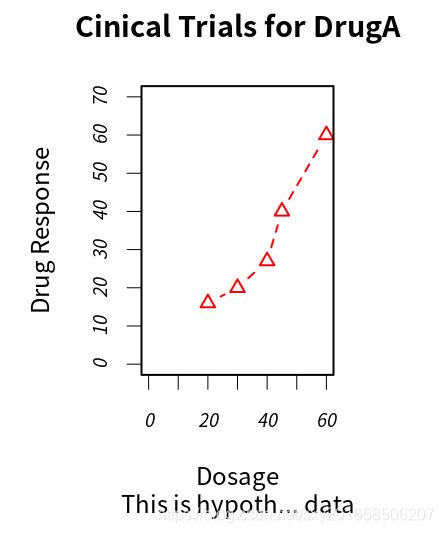
添加文本、自定坐标轴、图例
高级绘图函数(例如 plot 、 hist 、 boxplot )也允许自行设定坐标轴和文本标注选项。可以添加标题( main )、副标题( sub )、坐标轴标签( xlab 、 ylab ),指定了坐标轴范围( xlim 、 ylim )。
但并不是所有绘图函数都支持这样的自定义选项。还有些绘图函数有默认的标签和标题,可以在plot或者par函数中利用ann=FALSE来移除默认的。
> plot(dose,drugA,type='b',col='red',lty=2,pch=2,lwd=2,
+ main = "Cinical Trials for DrugA",
+ sub = "This is hypoth... data",
+ xlab = "Dosage",ylab="Drug Response",
+ xlim = c(0,60),ylim = c(0,70))
标题
title()函数
> plot(dose,drugB,type='b',pch=23,lty=6,col='blue',bg=mycolors,ann=FALSE)
> title(main="My Title",col.main="red",sub="MY Sub-title",col.sub="blue",
+ xlab = "My X label",ylab="My y label",
+ col.lab="green",cex.lab=.75)
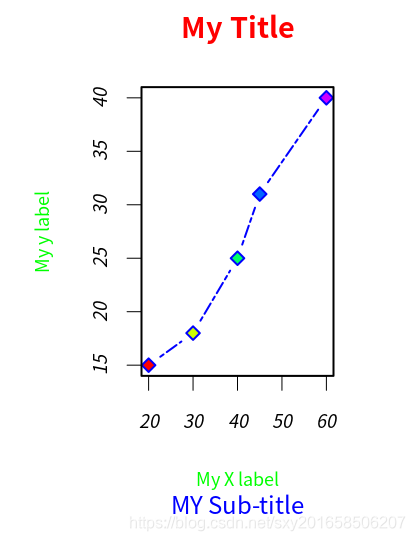
坐标轴
axis()来自定义坐标轴,其中:axis(side, at=,labels=,pos=,lty=,col=,las=,tck=, ...)
| side | 一个整数,代表axis将要绘制的一维的坐标轴在那个位置(1=下,2=左,3=上,4=右) |
| at | 数值型向量,表示在对应位置上所绘制的数据 |
| labels | 字符型向量,表示置于刻度线旁边的文字标签,如果位NULL,直接使用at中的值 |
| pos | 设定两条轴线相交位置的值。 |
| lty | 线条类型 |
| col | 线条(col)和刻度线(col.axis)颜色 |
| las | 轴标签平行(=0)还是垂直(=2)于坐标轴 |
| tck | 刻度线的长度,相对于绘图区域的大小而言,负值表示在图行外侧,正直表示在图形内侧,默认值是 -.01,0表示禁用刻度线,1表示绘制网格线 |
> x <- c(1:10)
> y <- x
> z <- 10/x
> opar <- par(no.readonly = TRUE)
> par(mar=c(5,4,4,8)+0.1)
> plot(x,y,type='b',pch=21,col="red",yaxt="n",lty=3,ann=FALSE)
> lines(x,z,type='b',pch=22,col="blue",lty=2)
> axis(2,at=x,labels=x,col.axis="red",las=2)
> axis(4,at=z,labels=round(z,digits=2),col.axis="blue",las=2,cex.axis=.7,tck=-.01)
> mtext("y=1/x",side=4,line=3,cex.lab=1,las=2,col="blue")
> title("An Example of Creative Axes",xlab="X values",ylab="Y=x")其中的ann=FALSE是为了消除plot函数中自带的标签和标题,目的是为了和下面的axis配合使用。
yaxt="n"是为了消除y轴的刻度和标签,也可以使用xaxt="n"来消除x轴刻度和标签,也是为了配合axis的使用
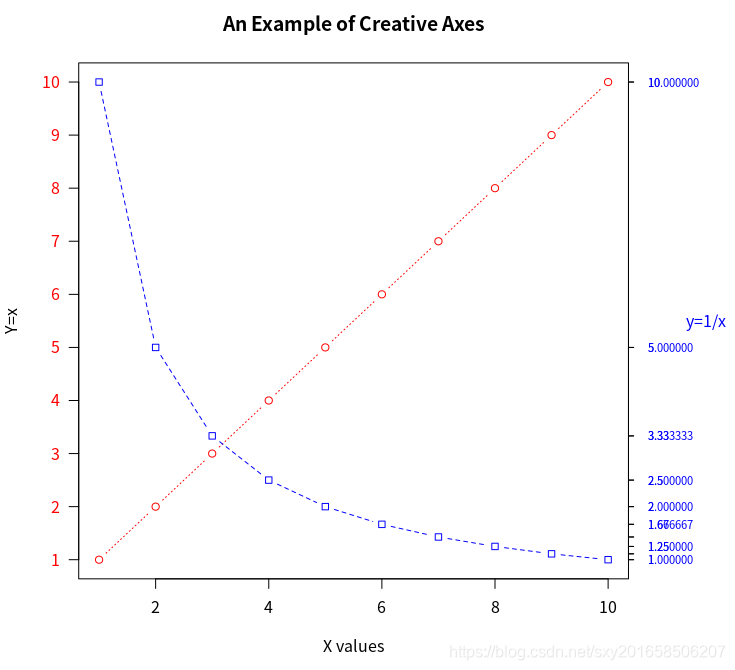
次要刻度线
需要使用 Hmisc 包中的 minor.tick() 函数
> library(Hmisc)
载入需要的程辑包:lattice
载入需要的程辑包:survival
载入需要的程辑包:Formula
载入需要的程辑包:ggplot2
载入程辑包:‘Hmisc’
The following objects are masked from ‘package:base’:
format.pval, units
> minor.tick(nx=2,ny=3,tick.ratio=0.5)nx、ny指在X轴和Y轴每两条刻度线之间用次要刻度线划分成的区间个数,tick.ratio 表示次要刻度线相对于主刻度线的大小比例,当前主刻度线的大小可以用par("tck")获取。
参考线
abline(h = yvalues, v = xvalues), h是在添加水平线,v是添加垂直线。函数中还可以制定图形的其他参数。
abline(v=seq(1,10,2),lty=2,col="blue")在x为1,3,5,7,9位置上添加了4条垂直方向的蓝色虚线
对图形的注释(图例)
legend(location, title, legend, ...)
location:可以有多种形式进行表示,直接给定左上角的x,y的坐标;也可以执行locator(1),然后通过鼠标点击确定其位置;还可以使用关键字bottom、bottomleft、left、topleft、top、topright、right、bottomright、center来放置位置,在使用关键之后还可以同时使用inset=向图形内侧移动的大小(单位是相对的百分数表示)。title 图例标题的字符串(可选)。legend 图例标签组成的字符型向量。
help(legend)可以得到一些提示。
> dose <-c(20,30,40,45,60)
> drugA <- c(16,20,27,40,60)
> drugB <- c(15,18,25,31,40)
> opar <-par(no.readonly=TRUE)
> par(lwd=2,cex=1.5,font.lab=2)
> plot(dose,drugA,type='b',pch=15,lty=1,col="red",ylim=c(0,60),main="DrugA vs DrugB",xlab="Drug Dosage",ylab="Drug Response")
> lines(dose,drugB,type='b',pch=17,lty=2,col="blue")
> abline(h=c(30),lwd=1.5,lty=2,col= "gray")
> library(Hmisc)
> minor.tick(nx=3,ny=3,tick.ratio=.5)
> legend("topleft",inset=.05,title="Drug Type",c("A","B"),lty=c(1,2),col=c("red","blue"))
> par(opar)
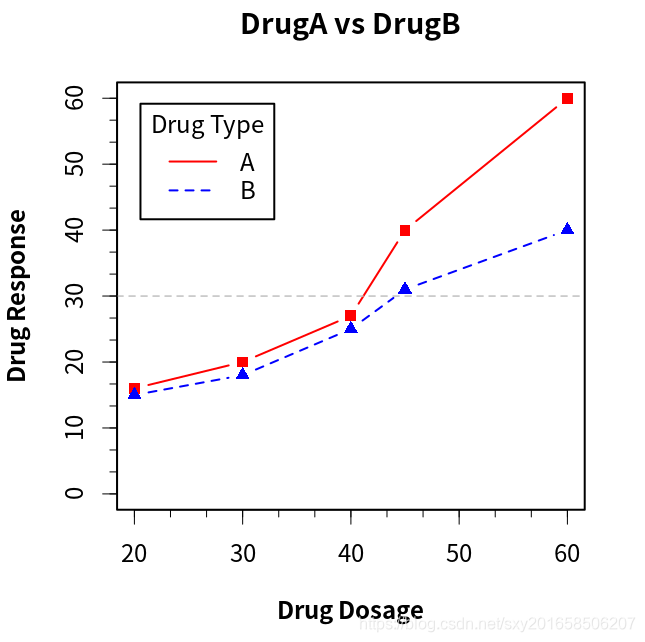
将文本添加到图形上(文本标注)
分为向绘图内部(text)和绘图的外部四个边界上(mtext)添加文本。
text(location,"text to place",pos, ...)
mtext("text to place",side,line=n, ...)
其他常用的选项有cex、col、font来调整字体大小、颜色、字体样式。
> attach(mtcars)
The following object is masked from package:ggplot2:
mpg
> plot(wt,mpg,main="Mileage vs. Car Weight",xlab="Weight", ylab="Mileage",pch=18,col="blue")
> text(wt,mpg,row.names(mtcars),cex=0.6,pos=4,col="red")
cex是指添加的文字相对于原先的缩放比例,cex=.6标签大小被缩小了40%
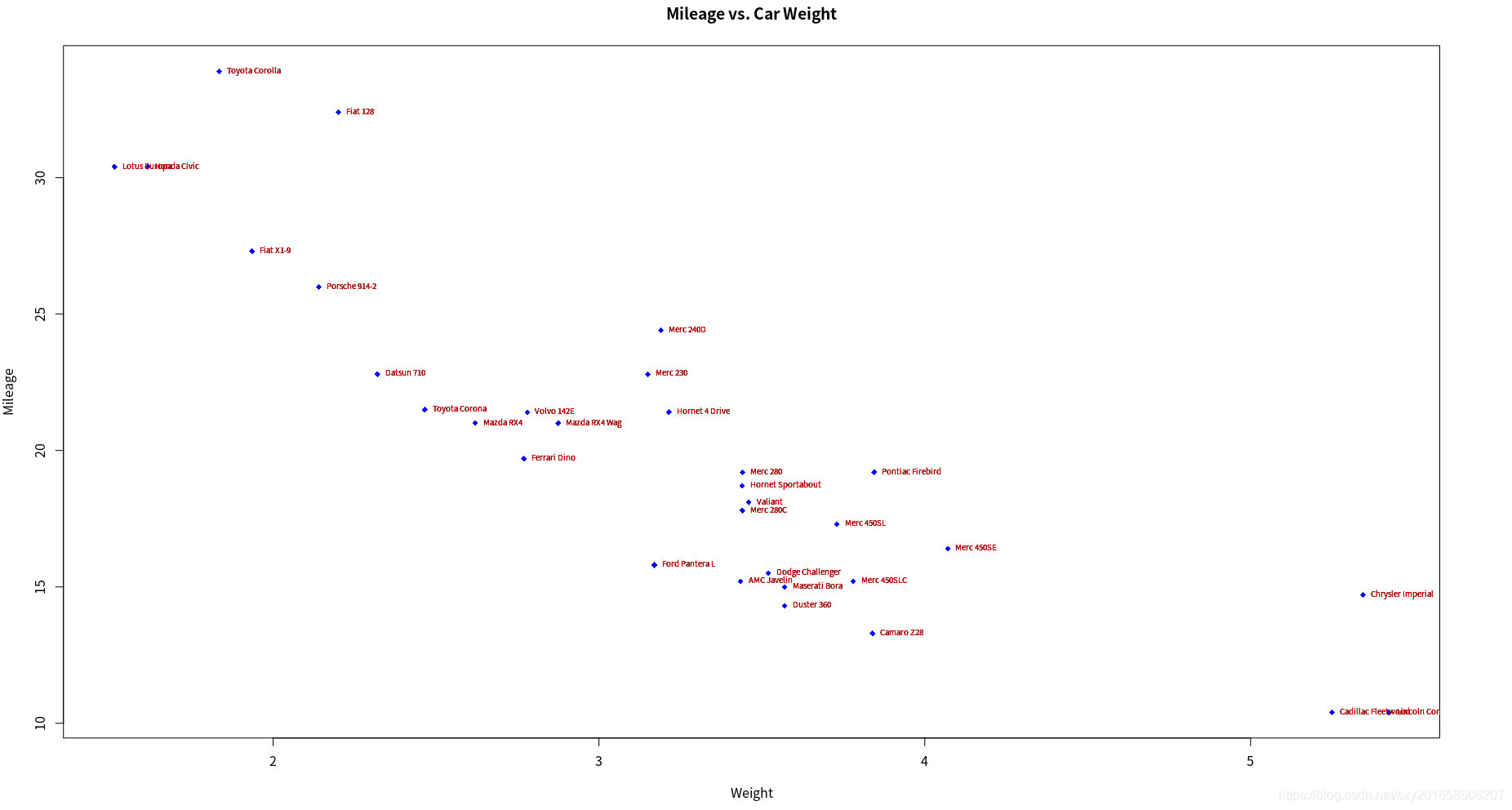
对不同字体族的示例:
> opar <- par(no.readonly=TRUE)
> par(cex=1.5)
> plot(1:7,1:7,type="n")
> text(3,3,"Example of default text")
> text(4,4,family="mono","Example of mono-spaced text")
> text(5,5,"Example of serif text",family="serif")
> par(opar)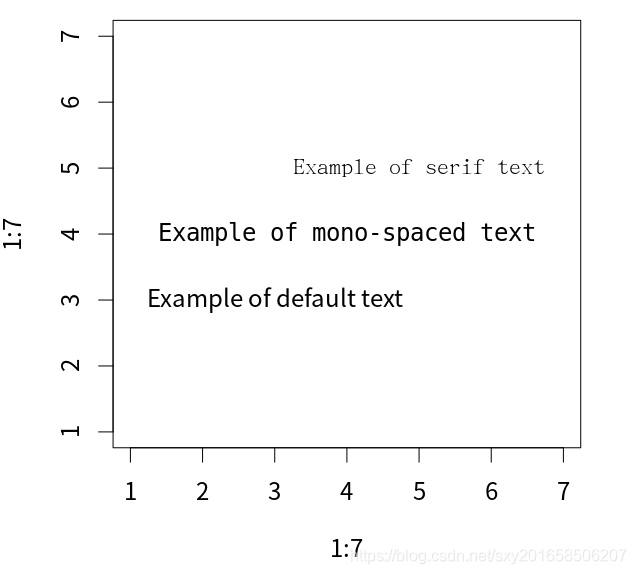
数学标注
一个面板中分区域画多幅图
有两种方式可以实现:
par( mfrow = c(nrows,ncols) ) 按行进行填充;mfcol = c( nrows, ncols)是按照列进行填充的方式。
layout(matrix=, nrows, ncols, byrow=,) matrix是一个矩阵表示着将要放置的位置,byrow说明了是否要按照行排还是列排,省略默认的是按照列排。对于更高精度的设置:widths=各列宽度指组成的一个向量,heights=隔行高度组成的一个向量值。相对宽度可以直接通过数值指定,绝对宽度(以厘米为单位)可以通过函数 lcm() 来指定。
> attach(mtcars)
The following objects are masked from mtcars (pos = 3):
am, carb, cyl, disp, drat, gear, hp, mpg, qsec, vs, wt
The following object is masked from package:ggplot2:
mpg
> opar <- par(no.readonly=TRUE)
> par(mar=c(5,4,4,2)+0.1)
> layout(matrix(c(1,1,2,3),2,2,byrow=TRUE)
> hist(wt)
> hist(mpg)
> hist(disp)
> par(opar)
> detach(mtcars)matrix(c(1,1,2,3),byrow=TRUE;是指第一个图按在矩阵的第一行 一二两列,第二张图在第二行第一列,第三张图在第二行第三列。
martix(c(1,0,2,3), byrow=TRUE; 是指第一张图在第一行第一列,第二张图在第二行第一列,第三张图在第二章第二列。0表示对应的位置没有图。
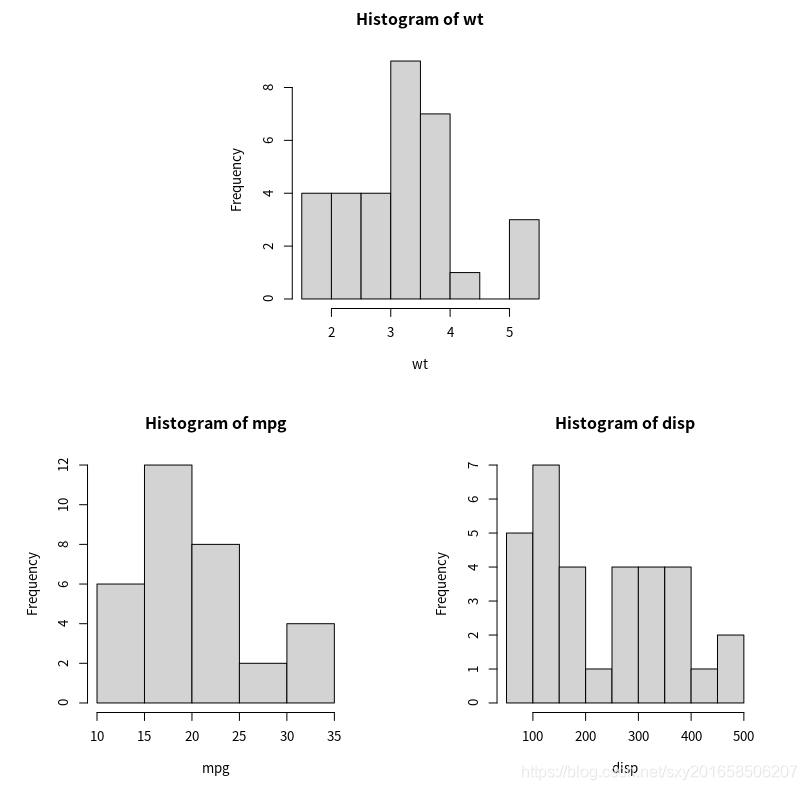
widths和heights的控制:
第1行中图形的高度是第2行中图形高度的三分之一。除此之外,右下角图形的宽度是左下角图形宽度的四分之一????
> opar <- par(no.readonly=TRUE)
> par(mar=c(5,4,4,2)+0.1)
> attach(mtcars)
The following objects are masked from mtcars (pos = 3):
am, carb, cyl, disp, drat, gear, hp, mpg, qsec, vs, wt
The following object is masked from package:ggplot2:
mpg
> layout(matrix(c(1,1,2,3),2,2,byrow = TRUE),widths=c(3,1),heights=c(1,2))
> hist(wt)
> hist(mpg)
> hist(disp)
> detach(mtcars)
> par(opar)
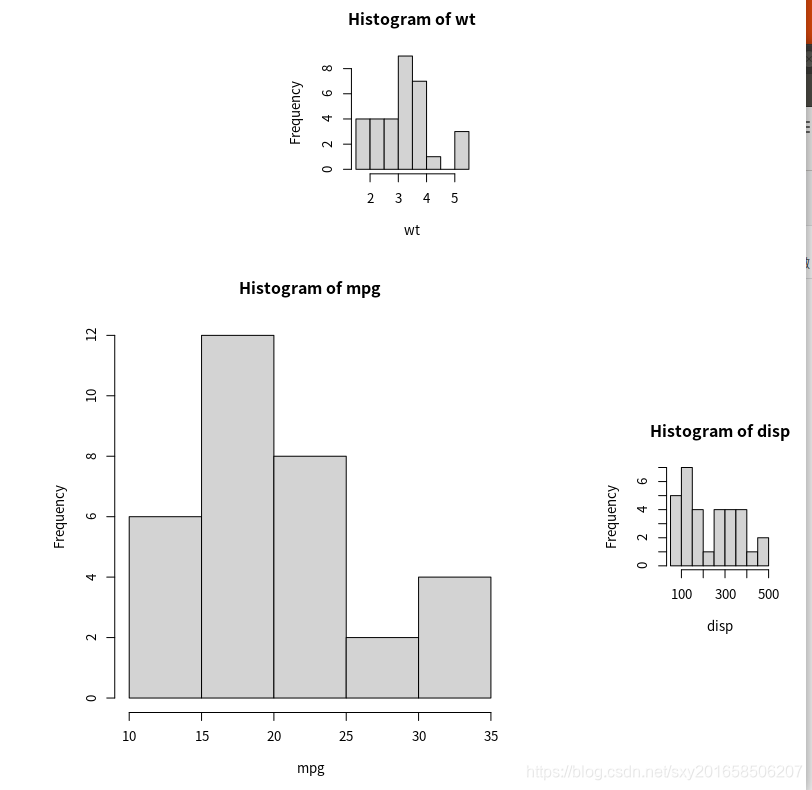
图形布局或者叠加进行画图
通过fig()函数来实现。
> par(opar)
> opar <- par(no.readonly=TRUE)
> par(mar=c(5,4,4,2)+0.1)
> par(fig=c(0,0.8,0,0.8))
> plot(mtcars$wt,mtcars$mpg,xlab="Miles Per Gallon",ylab="Car Weight")
> par(fig=c(0,0.8,0.55,1),new = TRUE)
> boxplot(mtcars$mpg,axes=FALSE)
> par(fig=c(0.65,1,0,0.8),new=TRUE)
> boxplot(mtcars$wt,axes=FALSE,horizontal=TRUE)
> mtext("Enhanced Scatterplot",side=3,outer=TRUE,line=-3)
> par(opar)
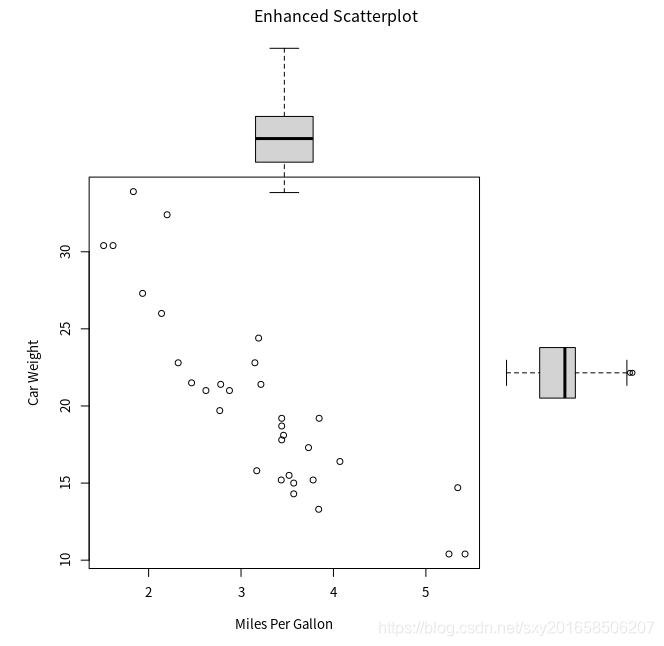
这幅图的绘制原理,请试想完整的绘图区域:左下角坐标为(0,0),而右上角坐标为(1,1)。参数 fig= 的取值是一个形如 c(x1, x2, y1, y2) 的数值向量。 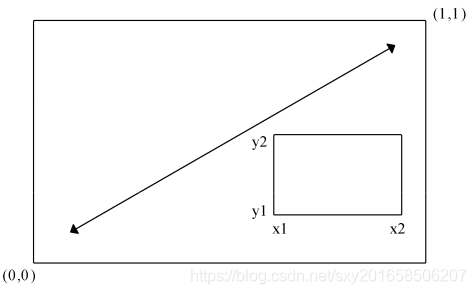
第一个 fig= 将散点图设定为占据横向范围0~0.8,纵向范围0~0.8。上方的箱线图横向占据 0~0.8,纵向0.55~1。右侧的箱线图横向占据0.65~1,纵向0~0.8。 fig= 默认会新建一幅图形,所
以在添加一幅图到一幅现有图形上时,设定参数 new=TRUE 。最优的位置需要不断尝试找到合适的位置参数。
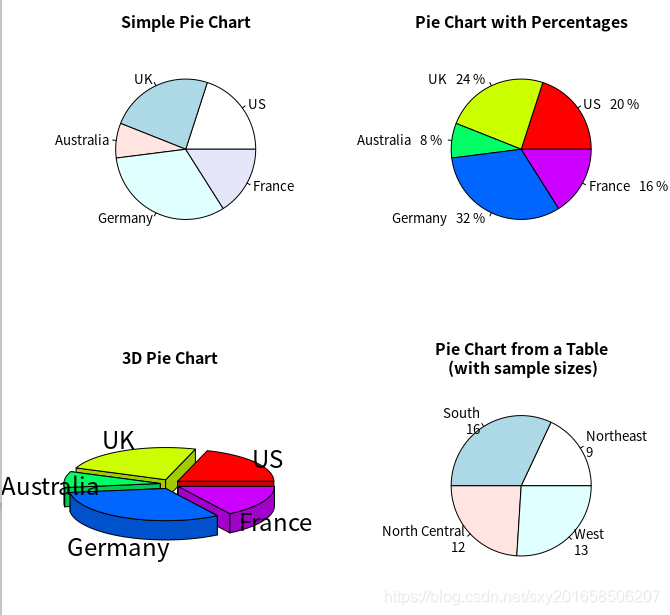
饼图
> par(mfrow=c(2,2))
> slices <-c(10,12,4,16,8)
> lbls <- c("US","UK","Australia","Germany","France")
> pie(slices,labels=lbls,main="Simple Pie Chart")
> n <- sum(slices)
> pct <- round(slices/n*100)
> labls2 <- paste(lbls," ",pct,"%",sept="")
> pie(slices,labels=labls2,col=rainbow(length(labls2)),main="Pie Chart with Percentages")
> library(plotrix)
> pie3D(slices,labels=lbls,explode=0.1,main="3D Pie Chart")
> mytable <- table(state.region)
> lbls3 <- paste(names(mytable),"\n",mytable,sep="")
> pie(mytable,labels = lbls3,main="Pie Chart from a Table\n (with sample sizes)")paste()函数
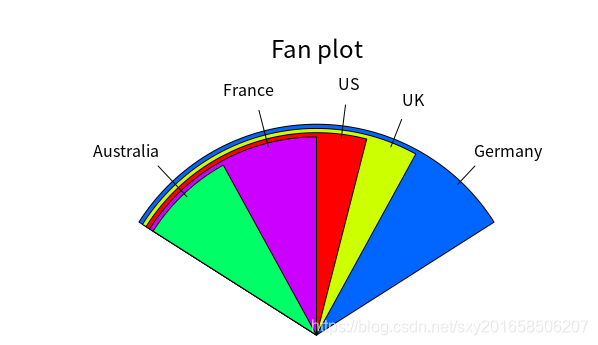
扇形图
> library(plotrix)
> slices <- c(10,12,4,16,8)
> lbls <- c("US","UK","Australia","Germany","France")扇形图有不同的半径,使得每个区域都可以明显的比较出大小,但是真正区分大小的是其宽度。
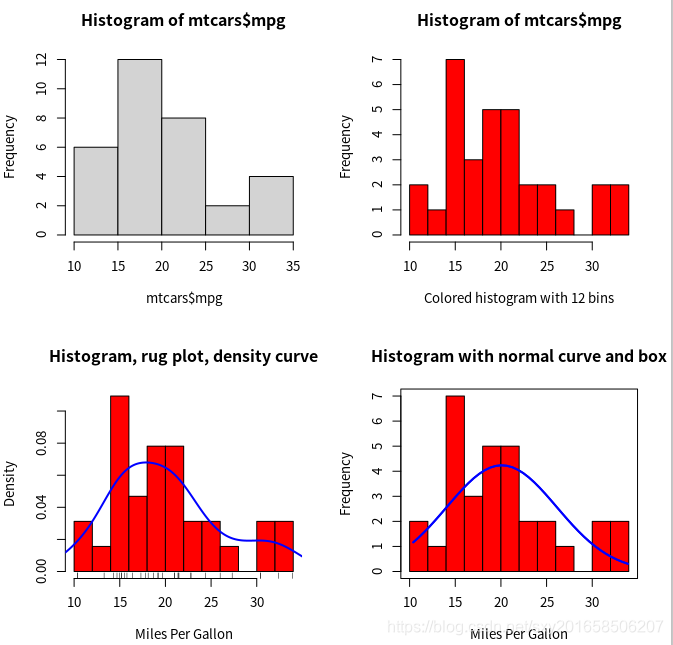
直方图
hist()函数、其中参数freq=FLASE可以设定位画出的直方图是按照密度画的,而不是按照频数来画的。
breaks=, 可以指定要分组的数量。
rug( jitter( ) ) 是添加虚轴图(rug plot),实际数据值的一种呈现方式,若数据中有很多相同的值(被称为结),可以使用rug(jitter(mtcars$mpg,amount=.01 ) )将虚轴图的数据打散(每个点添加了一个小的随机值在amount区间内上下均匀分布的进行取数,来避免重叠数据产生影响)。
可以使用lines( density() )来添加密度曲线。
box()可以为图形田家园一个框。
lines()向已经存在的图上添加密度曲线
> mtcars$mpg
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
[16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
[31] 15.0 21.4上面先看一下数据组成
> par(mfrow=c(2,2))
> hist(mtcars$mpg)
> hist(mtcars$mpg,breaks=12,col="red",xlab="Colored histogram with 12 bins")
> hist(mtcars$mpg,freq=FALSE,breaks=12,col="red",xlab="Miles Per Gallon",main="Histogram, rug plot, density curve")
> rug(jitter(mtcars$mpg))
> lines(density(mtcars$mpg),col="blue",lwd=2)
> x <- mtcars$mpg
> h <- hist(x, breaks=12,col="red",xlab="Miles Per Gallon",main="Histogram with normal curve and box")
> xfit <- seq(min(x),max(x),length=40)
> yfit <- dnorm(xfit,mean=mean(x),sd=sd(x))
> yfit <- yfit*diff(h$mids[1:2]) * length(x)
> lines(xfit,yfit,col="blue",,lwd=2)最有困惑性的应该是yfit <- yfit*diff(h$mids[1:2]) * length(x) ,先看一下h的数据成分:
> h
$breaks
[1] 10 12 14 16 18 20 22 24 26 28 30 32 34
$counts
[1] 2 1 7 3 5 5 2 2 1 0 2 2
$density
[1] 0.031250 0.015625 0.109375 0.046875 0.078125 0.078125 0.031250 0.031250
[9] 0.015625 0.000000 0.031250 0.031250
$mids
[1] 11 13 15 17 19 21 23 25 27 29 31 33
$xname
[1] "x"
$equidist
[1] TRUE
attr(,"class")
[1] "histogram"
diff基本功能可以用来计算序列数值之间的差值(还有在时间序列分析中的应用?数学菜鸡......逃。。。。)
diff:
> args(diff.default)
function (x, lag = 1L, differences = 1L, ...)
NULL
构造出一个序列:
> x <- cumsum(cumsum(1:10))
> x
[1] 1 4 10 20 35 56 84 120 165 220
> diff(x)
[1] 3 6 10 15 21 28 36 45 55
> diff(x,lag=2)
[1] 9 16 25 36 49 64 81 100
> diff(x,lag=2,differences=2)
[1] 16 20 24 28 32 36
第二个参数lag指明了要计算的间隔,differences是指要计算的次数,比如在第一次没有指明次数时得到的差值9,16.....,当differences=2时又对上次得到的差值再一次计算,这样就是计算出两次。
核密度图
核密度函数是由数据统计出来的和真实密度函数只相差一些无关项得到的。
> par(mfrow=c(2,1))
> d <- density(mtcars$mpg)
> plot(d)
> plot(d,main="Kernel Density of Miles Per Gallon")
> polygon(d,col="red",border="blue")
> rug(mtcars$mpg,col="brown") polgon()是根据x,y坐标值绘制多边形,这儿的坐标值是由density函数提供的。
rug添加了虚轴。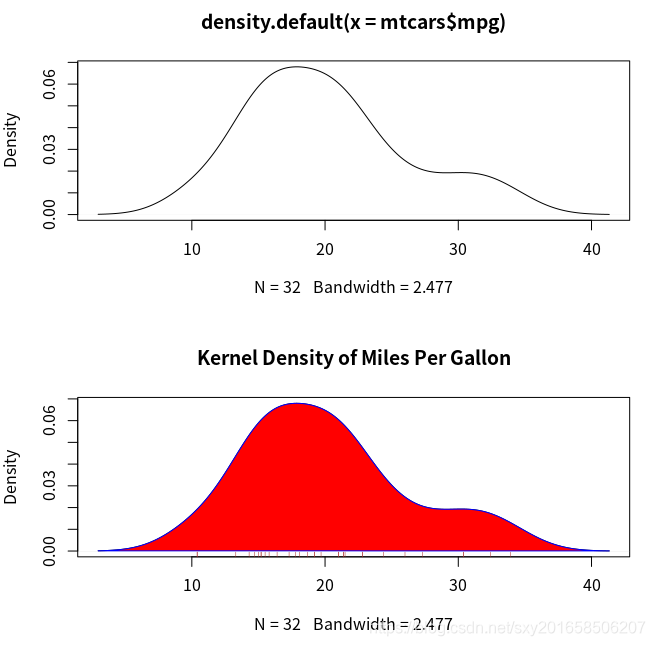
核密度图可用于比较组间差异。普遍缺乏方便好用的软件,这种方法其实完全没有被充分利用。sm 包填补了这一缺口。
sm.density.compare(x, factor)。x 是一个数值型向量, factor 是一个分组变量。允许多个组绘出他们的核密度函数。
> par(lwd=2)
> library(sm)
> attach(mtcars)
> cyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
> mpg
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
[16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
[31] 15.0 21.4
> cyl.f <- factor(cyl,levels=c(4,6,8),labels=c("4 cylinder","6 cylinder","8 cylinder"))
> sm.density.compare(mpg,cyl,xlab="Miles Per Gallon")
> title(main="MPG Distribution by Car Cylinders")
> colfill <- c(2:(1+length(levels(cyl.f))))
> legend(locator(1),levels(cyl.f),fill=colfill)
> detach(mtcars)
fill来填充颜色
我的疑问点在compare中mpg和cyl是怎么联系起来的。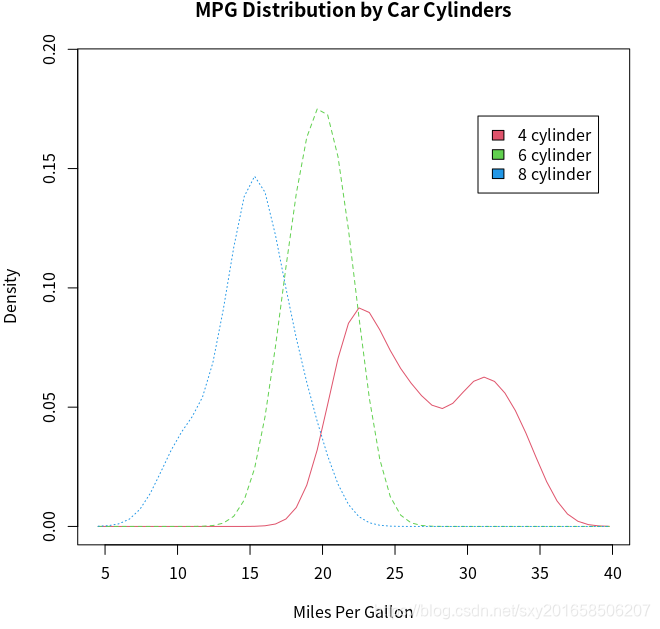
箱图
绘制连续型变量的五个数: 最小值、下四分位数(25%)、中位数、上四分位数。还能够显示出可能为离群点的观测(限制的范围在±1.5*IQR以外的值,IQR表示四分位距,即上四分位数与下四分位数的差值)
> boxplot(mtcars$mpg,main="Box plot",ylab="Miles per Gallon")使用 boxplot可以查看具体的统计量
> boxplot.stats(mtcars$mpg)
$stats
[1] 10.40 15.35 19.20 22.80 33.90
$n
[1] 32
$conf
[1] 17.11916 21.28084
$out
numeric(0)
中位数是19.2,50%的值都落在了15.3和22.8之间,最小值为10.4,最大值为33.9,下面的图还没有离群点。且略微偏正(上侧的比下册的更长)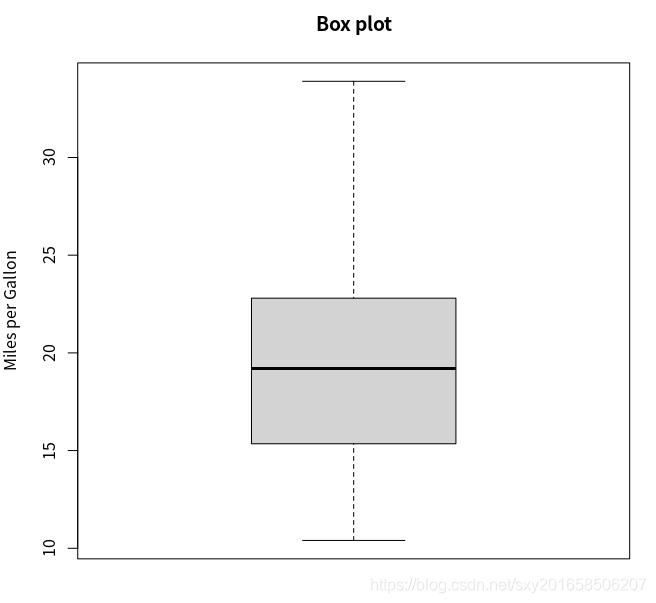
使用并列箱线图进行夸组比较
boxplot(formula, data=dataframe) formula指一个公式,dataframe代表提供数据的数据框或者列表。formula: y~A, 把A的每个值并列的生成变量y的箱线图。y~A*B 则将A和B的所有水平的两两组合生成数值型变量y的箱线图。???啊?怎么生成且比较
varwidth=TRUE 将 使 箱 线 图 的 宽 度 与 其 样 本 大 小 的 平 方 根 成 正 比 。 参 数horizontal=TRUE 可以反转坐标轴的方向。
> boxplot(mpg~cyl,data=mtcars,main="Car Mileage Data",xlab="Number of Cylinders",ylab="Miles Per Gallon")
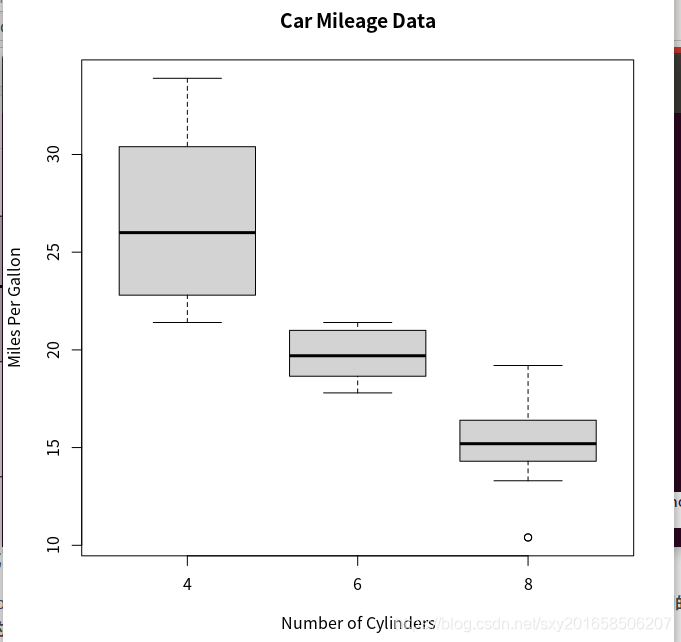
小提琴图
点图
dotchart(x,labels=) x是数值型向量,labels是每个点的标签组成的向量,可以通过添加参数groups 来选定一个因子,用以指定 x 中元素的分组方式。
则参数 gcolor 可以控制不同组标签的颜色, cex 可控制标签的大小。
> dotchart(mtcars$mpg,labels=row.names(mtcars),cex=.7,main="Gas Mileage for Car Models", xlab="Miles Per Gallon")
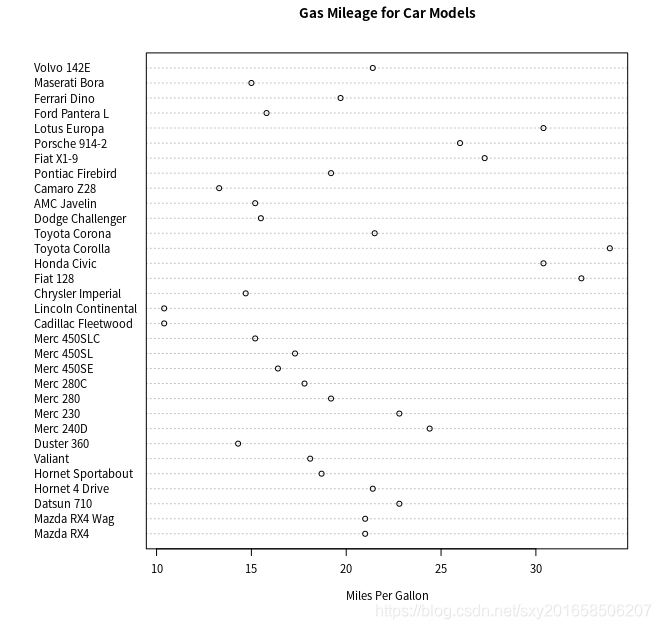
> x <- mtcars[order(mtcars$mpg),]
> x
mpg cyl disp hp drat wt qsec vs am gear carb
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
...
> x$cyl <- factor(x$cyl)
> x$cyl
[1] 8 8 8 8 8 8 8 8 8 8 8 8 6 6 8 6 8 6 6 6 6 4 4 4 4 4 4 4 4 4 4 4
Levels: 4 6 8
> x$color[x$cyl==4] <- "red"
> x$color[x$cyl==6] <- "blue"
> x$color[x$cyl==8] <- "darkgreen"
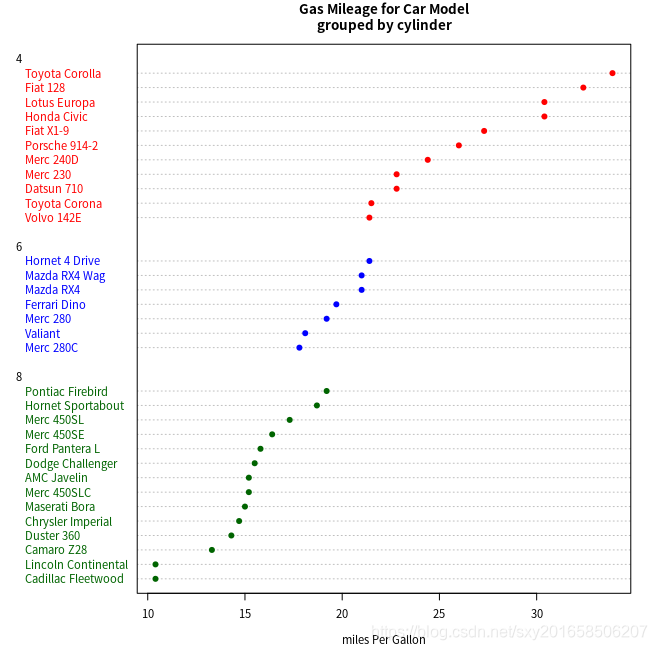
>dotchart(x$mpg,labels=row.names(x),cex=.7,groups=x$cyl,gcolor="black",color=x$color,pch=19,main="Gas Mileage for Car Model\ngrouped by cylinder",xlab="miles Per Gallon")
对数据框 mtcars 进行排序,结果保存为数据框 x 。x的数值向量 cyl 被转换为一个因子 ;字符型向量( color )被添加到了数据框x 中;根据 cyl 的值,它所含的值为 "red" 、 "blue" 或 "darkgreen";数据点的标签来自数据框的行名;点和标签的颜色来自向量 color;
散点图
> attach(mtcars)
> plot(wt,mpg,main="Basic Scatter plot of MPG vs. Weight",xlab="Car Weight(lbs/1000)",ylab="Miles Per Gallon ",pch=19)
> abline(lm(mpg~wt),col="red",lwd=2,lty=1)
> lines(lowess(wt,mpg),col="blue", lwd=2,lty=2)
abline()是得到一条最优拟合的线性直线;
R两个平滑曲线拟合函数:
lowess()函数是用来添加一条平滑的曲线,基于局部加权多项式回归的非参数方法;
loess() 是基于lowess()表达式版本的进一步更新或者说更强大的拟合函数;
。。。。一大波内容被误删了
高密度散点图
> n <- 1000
> c1 <- matrix(rnorm(n,mean=0,sd=.),ncol=2)
Error in rnorm(n, mean = 0, sd = .) : 找不到对象'.'
> c1 <- matrix(rnorm(n,mean=0,sd=.5),ncol=2)
> c2 <- matrix(rnorm(n,3,2),ncol=2)
> mydata <- rbind(c1,c2)
> mydata <- as.data.frame(mydata)
> names(mydata) <-c("x","y")
> with(mydata,plot(x,y,pch=19,main="Scatter Plot with 10000 Obersvations"))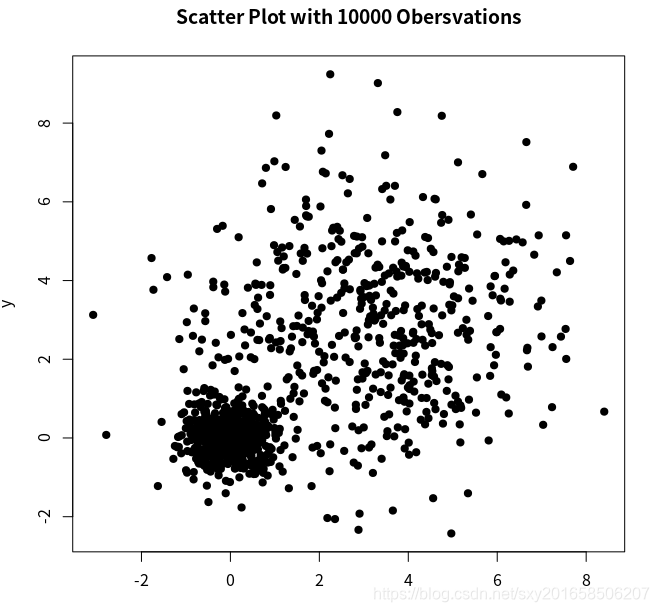
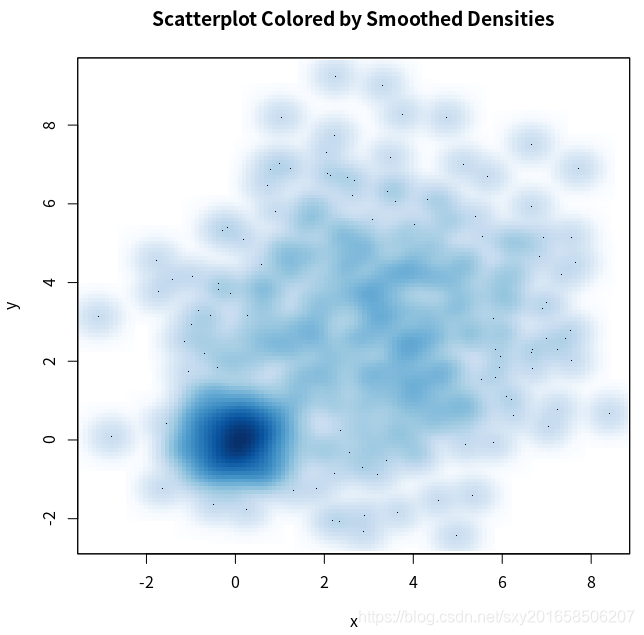
上面的散点图因为有很多数据点的重叠影响了x 和y之间的关系,解决办法之一是用smoothScatter()函数可以利用核密度估计生成用颜色密度来表示点分布的散点图。图中的小黑点就是表示的具体的值,高度阴影区域也有点。
> with(mydata,smoothScatter(x,y,main="Scatterplot Colored by Smoothed Densities"))
> with(mydata,{
+ bin <- hexbin(x,y,xbin=50)
+ plot(bin,main="Hexagonal Binning with 10000 Obervations")
+ })
hexbin包中的hexbin()函数把二元变量的封箱放在六边形单元格中。
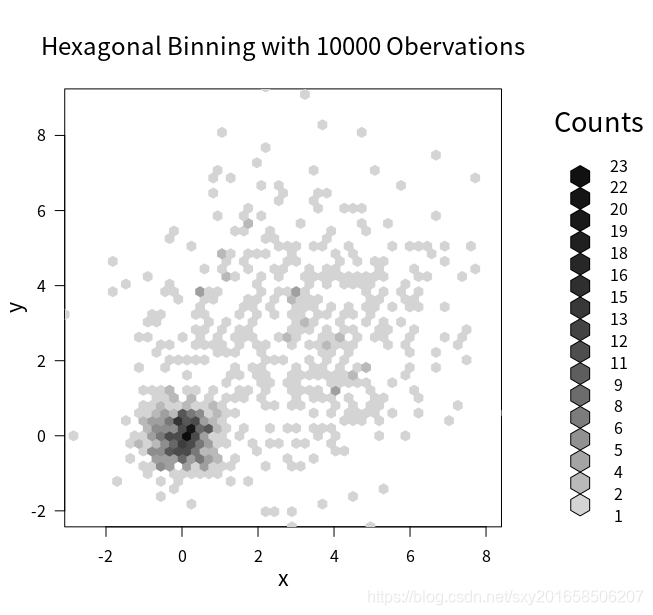
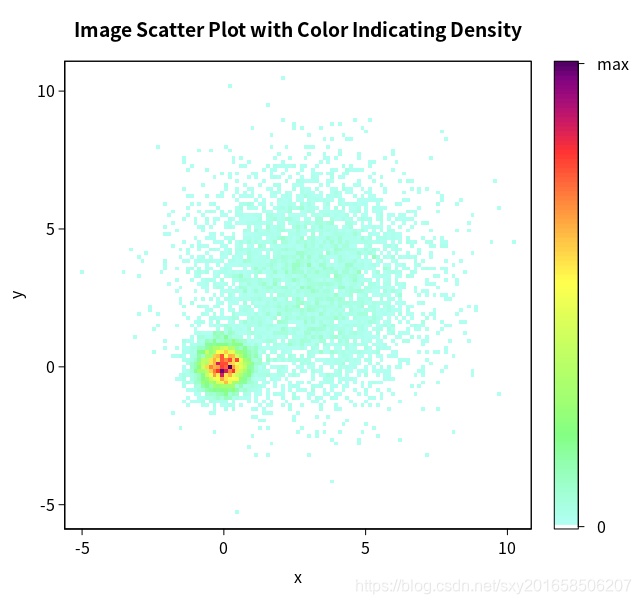
iplot()函数可以通过颜色来展示点的密度(在某特定点上的数据点的数目)
> with(mydata,iplot(x,y,main="Image Scatter Plot with Color Indicating Density"))
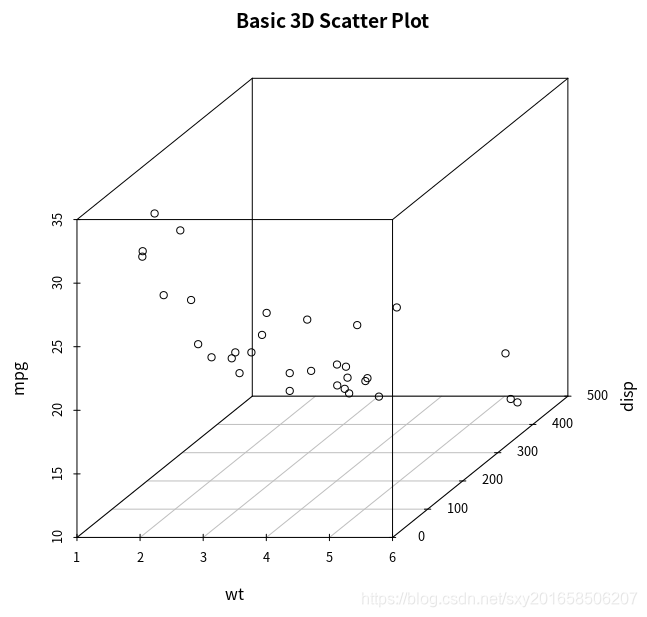
三维散点图
> library(scatterplot3d)
> attach(mtcars)
> scatterplot3d(wt,disp,mpg,main="Basic 3D Scatter Plot")
> attach(mtcars)
The following objects are masked from mtcars (pos = 3):
am, carb, cyl, disp, drat, gear, hp, mpg, qsec, vs, wt
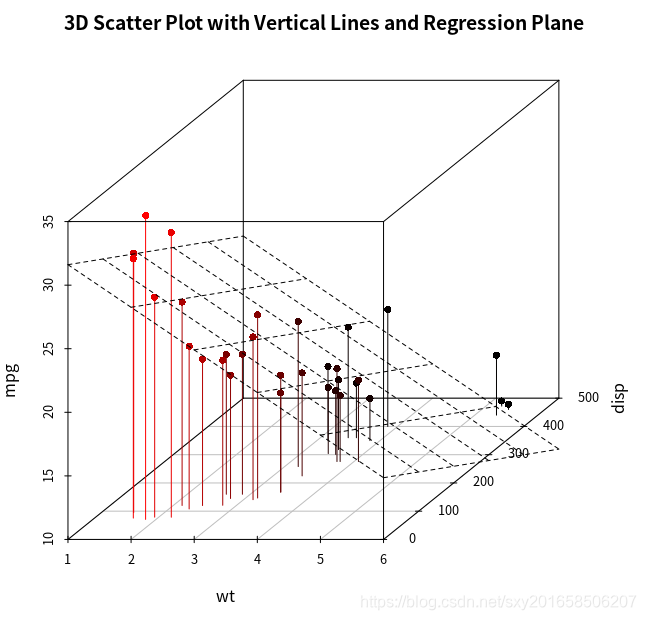
> scatterplot3d(wt,disp,mpg,pch=16,highlight.3d=TRUE,type="h",main="3D Scatter Plot eith Vertical Lines")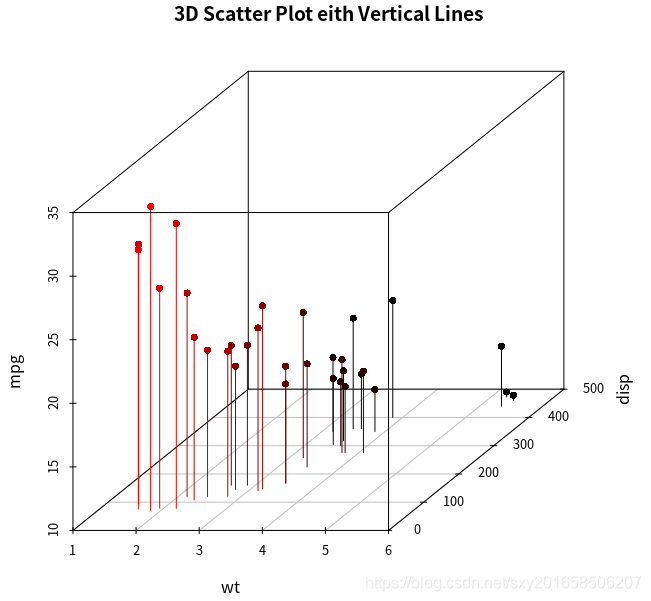
在上面的图中添加一个回归面:
s3d
> s3d <- scatterplot3d(wt,disp,mpg,pch=16,highlight.3d=TRUE,type="h",main="3D Scatter Plot with Vertical Lines and Regression Plane")
> fit <- lm(mpg~ wt + disp)
> s3d$plane3d(fit)
图形利用多元回归方程,对通过车重和排量预测每加仑英里数进行了可视化处理。平面代表预测值,图中的点是实际值。平面到点的垂直距离表示残差值。若点在平面之上则表明它的预测值被低估了,而点在平面之下则表明它的预测值被高估了。
交互的三维散点图
函数:plot3d( x, y, z),还可以控制col,size....属性
> library(rgl)
> attach(mtcars)
> plot3d(wt,disp,mpg,col="red",size=5)
图
还可以用Rcmde中的函数scatter3d(),还可以包含各种回归曲面,比如线性、二次、平滑以及附加的类型。
> library(Rcmdr)
>attach(mtcars)
> scatter3d(wt,disp,mpg)
图
气泡图
通过三维散点图来展示三个定量变量间的关系。现在介绍另外一种思路:先创建一个二维散点图,然后用点的大小来代表第三个变量的值。这便是气泡图 (bubble plot);可以在指定的(x, y)坐标上绘制圆圈图、方形图、星形图、温度计图和箱线图。以绘制圆圈图为例:
symbols(x,y,circle = radius) 分别表示x、y坐标和圆圈半径。
> attach(mtcars)
> r <- sqrt(disp/pi)
> symbols(wt,mpg,circle=r,inches=.3,fg="white",bg="lightblue",main="Bubble Plot with point size proportional to displacement",ylab="Miles Per Gallon",xlab="Weight of Car")
> text(wt,mpg,rownames(mtcars),cex=.6)
> detach(mtcars)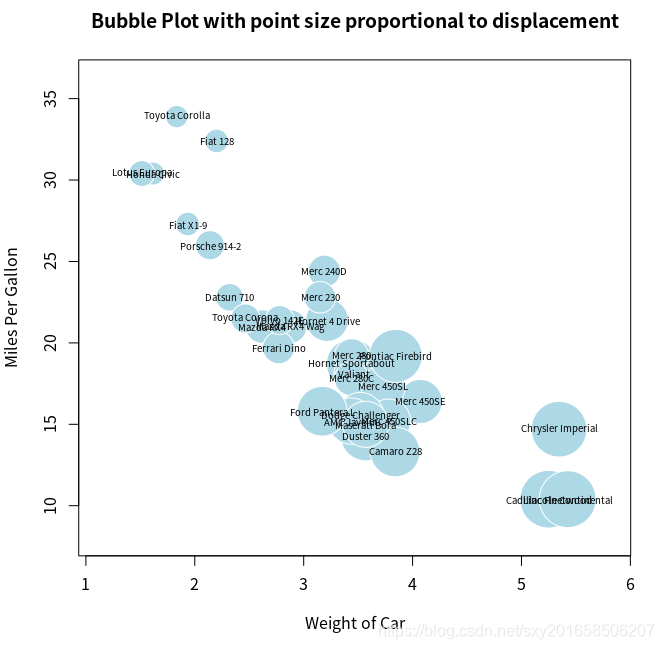
折线图
将散点图上的点从左往右连接起来, 那么就会得到一个折线图
> opar <- par(no.readonly=TRUE)
> par(mfrow=c(1,2))
> t1 <- subset(Orange,Tree==1)
> plot(t1$age,t1$cirumference,xlab="Age (days)",ylab="Circumference(mm)",main="Orange Tree 1 Growth")
> plot(t1$age,t1$circumference,xlab="Age (days)",ylab="Circumference(mm)",main="Orange Tree 1 Growth",type="b")
subset()是从数据中选取一定的符合条件的数据,用逻辑运算符进行操作。subset(x, subset, select, drop = FALSE, ...)相当于数据库的查询语句。
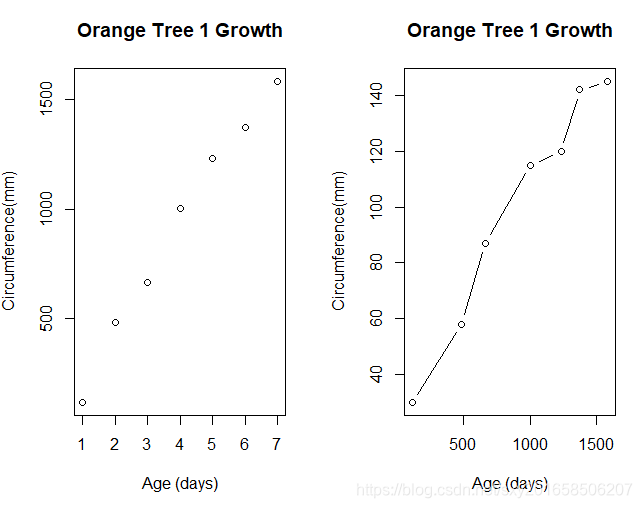
其中的参数type=,主要的赋值有一下几种:

> Orange$Tree <- as.numeric(Orange$Tree)
> ntrees <- max(Orange$Tree)
> xrange <- range(Orange$age)
> yrange <- range(Orange$circumference)
> plot(xrange,yrange,type="n",xlab="Age(days)",ylab="Circumference(mm)")
> colors <- rainbow(ntrees)
> linetye <-c(1:ntrees)
> plotchar <- seq(18,18+ntrees,1)
> for(i in 1:ntrees){
+ tree <- subset(Orange,Tree==i)
+ lines(tree$age,tree$circumference,type="b",lwd=2,lty=linetye[i],col=colors[i],pch=plotchar[i])
+ }
> title("Tree Growth","example of line polt")
> legend(xrange[1],yrange[2],1:ntrees,cex=.8,pch=plotchar,lty=linetye,title="Tree")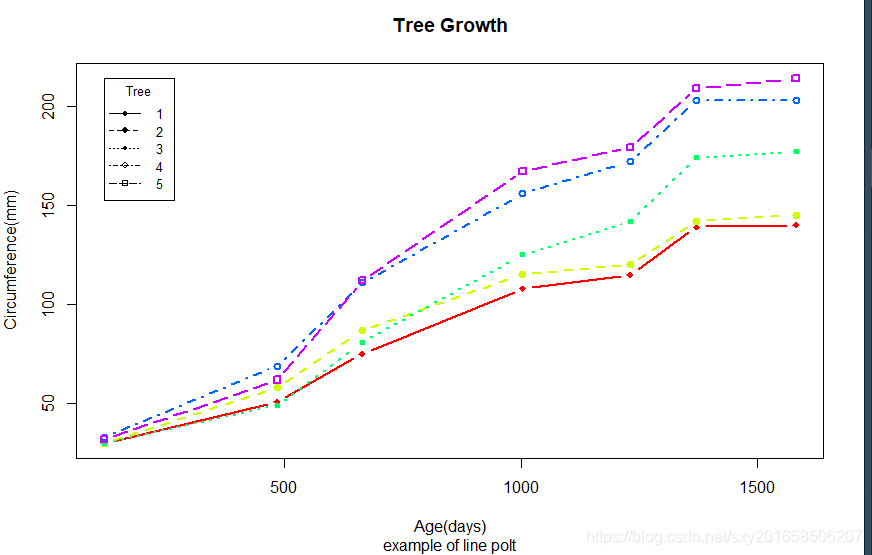


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









