







今天我们分享一个数据库被异常改写的案例,通过该案例我们可以学习总结出常规的文件被改写问题定位思路。
问题现象
1、测试环境在进行特定压力测试时发现页面登陆异常,且调试日志多个进程持续打印“数据库打开失败”日志。
2、测试环境在进行多个压力测试时产生了coredump,每次产生coredump数量不止一个,且产生coredump的进程并不完全相同。
问题分析
首先对所有产生的coredump进行分析,发现它们的较低层栈回溯完全相同,都是在调用lmdb数据库接口lmdb_get获取数据时,lmdb在查询数据判断一些管理数据结构,发现异常数据然后产生了abort信号杀死了进程并产生了coredump。所有的进程最后都挂在了这样的流程中,只是它们的上层调用业务不同、数据库数据的key不同,因此我们怀疑问题是由于数据库被改写破坏了数据库管理结构,导致所有使用lmdb数据库的进程在使用到该异常数据块时被lmdb流程判定异常并发出abort信号杀死了进程并产生coredump。观察同一设备产生的几个coredump产生时间,发现它们基本都是同时产生的,前后只相差几秒。另外,出现问题时对数据库的应用层调用接口lmdb_get的传参也正确。因此,我们更坚信是由于数据库本身被改写导致进程异常。
为了确认在问题复现时数据库确实被改写了,我们在coredump的收集脚本中打包core文件时也收集lmdb数据库文件,这样我们就获得了问题数据库文件。在同一台设备相同环境下运行时也获取正常使用时的lmdb数据库文件。由于业务特点,该lmdb数据库保存的都是静态数据,我们所使用的数据库文件在初始化写入后将不再改写,后面全部是读数据库场景,这样同一台设备无论重启多少次,每次数据库记录的数据都应该相同。因此,我们通过BeyondCompare软件以二进制格式比较获取的同一设备的问题数据库文件和异常数据库文件,查看两者差异。
经过比较分析,发现确实两个数据库文件存在差异,且差异项全部集中在文件的开头,差异项数据都被改写成8字节的“00000000 00000001”,如此反复,这带有较明显的特征。因此,我们可以确认数据库被改写了,且全部被改写成了多个8字节数据“00000000 00000001”。另外,我们阅读lmdb数据库源码,发现数据库的开头应该为一个管理数据结构,其中一些标志位明显异常,此时若需要打开数据库,则肯定会打开失败,这也符合问题现象1。
针对数据库本身可能被改写,具体有2种场景:
- 由于lmdb数据库本身的特性,为了提高读数据库的效率,在具体使用时会将数据库文件通过mmap映射到进程的虚拟地址空间中。若在数据库映射空间的前面部分内存越界改写,可能破坏数据库前面的数据,从而出现问题。
- 由于数据库文件也是一个文件,它也有自己的句柄。若进程的某个模块误操作该句柄,写入一些数据则可能导致数据库被改写,出现数据库异常现象。
针对上述2种可能,我们分别进行分析并排查。
数据库映射时被越界访问
由于数据库通过mmap映射到进程的虚拟地址空间中,在低位地址空间可能越界改写导致数据库异常。为了验证这种可能,我们采用本地模拟的方式进行复现。具体操作步骤如下:
- 创建一个独立的进程,调用lmdb_open通用接口打开数据库,并通过返回的数据库句柄信息获取数据库文件mdb.data映射到进程虚拟地址空间的起始地址pMmapAddr。
- 在独立进程中接着从pMmapAddr往前推0x20个字节开始通过memcpy写入0x50个字节“00000000 00000001”数据,实现对这种情况的模拟,结果模拟的进程产生了coredump。
- 经对该coredump解析,发现在对pMmapAddr进程memcpy操作时产生了段错误。因此,我们怀疑对数据库文件映射进的虚拟地址空间前面部分没有写权限。通过在原环境产生的coredump中利用info proc mappings命令可以看到数据库映射的位置,我们再在本地正常设备查看业务进程的/proc/pid/maps虚拟地址空间,确认数据库文件mdb.data映射到虚拟地址空间的前面部分确实是只读的,因此我们无权修改该部分内存。
经上面的验证,由于数据库文件mdb.data最前面被改写的部分是通过只读方式进行映射的,其前面的内存无法通过虚拟地址空间直接改写,因此排除了这种可能。
文件句柄误操作改写
为了验证某个进程可能直接通过数据库句柄利用write系统调用误写入数据,我们采用了和上面类似的模拟方法。具体步骤如下:
- 创建一个独立的进程,调用lmdb_open通用接口打开数据库,并通过返回的数据库句柄信息获取数据库文件mdb.data的文件句柄fd。
- 在独立进程中通过write系统调用直接对数据库文件mdb.data从开头写入和问题现场相同数量的“00000000 00000001”数据。
- 在2的基础上再利用lmdb_open打开数据库文件失败,即复现了问题现象1。
- 在2的基础上再启动一个写数据库的进程保持运行不结束(不需要真的写数据库),对于2中的进程在通过write将异常数据写入数据库后再去读数据库,在和问题环境相同位置产生了abort信号,读进程立刻挂掉,即复现了问题现象2。而且获取本地复现的数据库文件,并和同设备正常数据库文件进行对比,确实改写了数据库文件mdb.data文件的开头部分,成功地将一系列“00000000 00000001”数据库写入到了数据库文件中,这也和测试环境复现的问题数据库文件保持一致。
通过上面的实验验证,我们可以确认是数据库被异常改写了,且较大概率是某个进程通过write系统调用直接写入异常数据导致。下一步就是需要确认是哪个进程什么场景下通过write改写了数据库文件。
定位根因
在上面我们已知数据库文件被改写后的异常数据为一系列重复的“00000000 00000001”,虽然该数据带有一定的特征,但我们无法凭此找到“肇事者”。因此,为了定位根因我们还需要想起他办法。
考虑到问题数据库只有在product_init进程启动时才会写入数据初始化,后面其他业务进程只会进行读操作,因此只要是非product_init进程对数据库文件的写入都可以认为是非法的。根据这个特征,我们去寻找那些写入数据库的非product_init进程。由于通过write系统调用必将走内核的一套写文件流程:write--->sys_write--->vfs_write...。因此,我们可以考虑修改内核中write相关代码,在写文件的必经途径vfs_write函数中添加打印,具体步骤如下:
- 首先根据句柄信息获取待写入文件名,然后判断待写入文件名是否为数据库文件“mdb.data”。若不是,则结束;否则继续下面的判断流程。
- 判断当前进程名是否为product_init。若是,则结束;否则说明当前进程在误写入数据库文件,其为“罪魁祸首”,继续下面的操作。
- 为了帮助我们获取更多的现场信息,通过调用do_send_signal函数给当前进程发送SIGSEGV信号杀死当前进程,并产生coredump。这样我们可以当问题复现时,通过分析coredump找到具体误写入数据库的进程以及调用流程,帮助我们更清晰地还原现场、定位根因。
基于上述思路,编写临时版本给测试进行复现。在经过较长时间压力测试后问题终于复现,产生了coredump。通过解析该coredump,可以发现shdmain进程在调用write写入数据产生的coredump。通过x /wx命令打印待写入的内存地址,发现地址正常,因此怀疑产生coredump的原因是由于我们上面在write添加的调试流程导致,而不是真的产生了段错误。
接下来,我们看到write需要写入的数据长度是8,而刚刚通过x /wx命令打印出的待写入内存的前8个字节数据刚好为“00000000 00000001”,这和问题复现被改写的数据库异常部分完全一致,进一步验证了猜想,即shdmain进程通过write系统调用改写了lmdb数据库破坏了数据库的管理结构,导致在使用时产生了多个coredump。
虽然我们通过上面的调试打印找到了改写数据库的进程以及流程,但由于该流程是一个开源进程,肯定不会直接对数据库进行写入,大概率是其他流程误操作了数据库导致。那么问题来了,又是哪个模块导致开源线程没有写自己的文件,而误写入数据库文件呢?本来这一步定位挺棘手的,刚好另外一个模块的同学在定位问题时发现当前代码中存在重复关闭文件的问题,这给我带来了启发。我们可以假设一个场景,同一个进程下有A、B、C3个线程都需要操作文件,它们的操作分别如下:
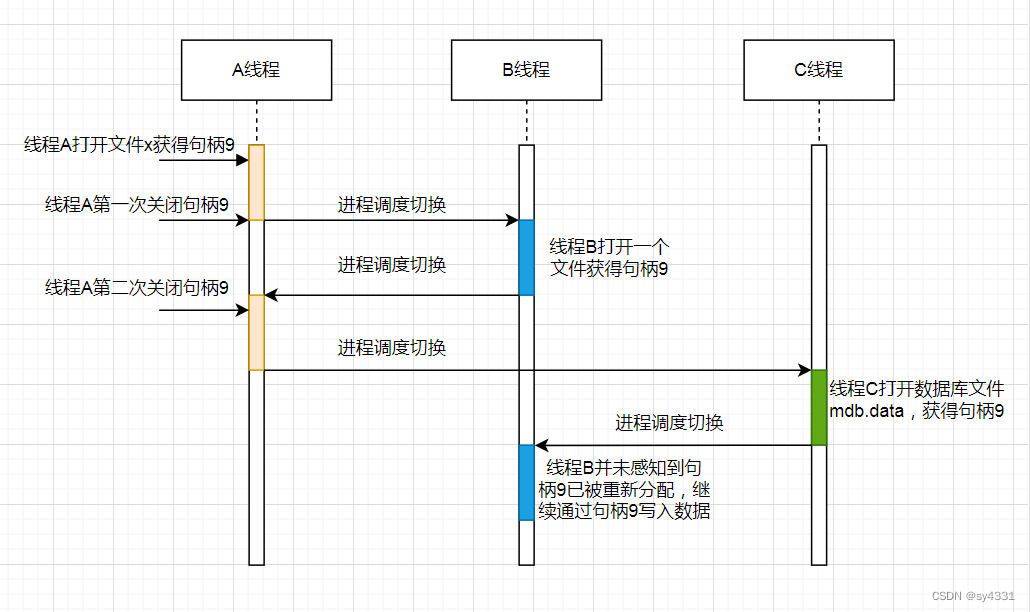
- A线程打开了文件x获得了句柄9。
- A线程在使用完后关闭了文件x,释放了句柄9,此后发生了进程调度切换,开始执行B线程。
- B线程根据业务需要,打开了文件y。由于刚刚A线程已经释放了句柄9,同一个进程下不同线程共享文件资源,此时内核将句柄9分配给文件y。执行一段时间后发生了进程调度切换,又开始执行A线程。
- A线程此时由于编码错误,再次关闭了句柄9。此后又发生了进程调度切换,开始执行C线程。
- C线程由于业务需要,打开了lmdb数据库文件mdb.data。由于在步骤4中A线程第二次关闭了句柄9,此时内核将句柄9分配给了数据库文件mdb.data。此后又发生了进程调度切换,又开始执行B线程。
- B线程并不感知到句柄9已经被重新分配给数据库文件mdb.data,不再指向自身原有的文件y。B线程继续通过句柄9写入数据,其实际即写入了数据库文件mdb.data,从而改写了数据库文件,造成数据库异常。
经过上面的详细分析,我们基本可以还原数据库文件被改写的流程。根据其他模块同学的定位结论,目前代码中存在的句柄重复关闭场景如下:
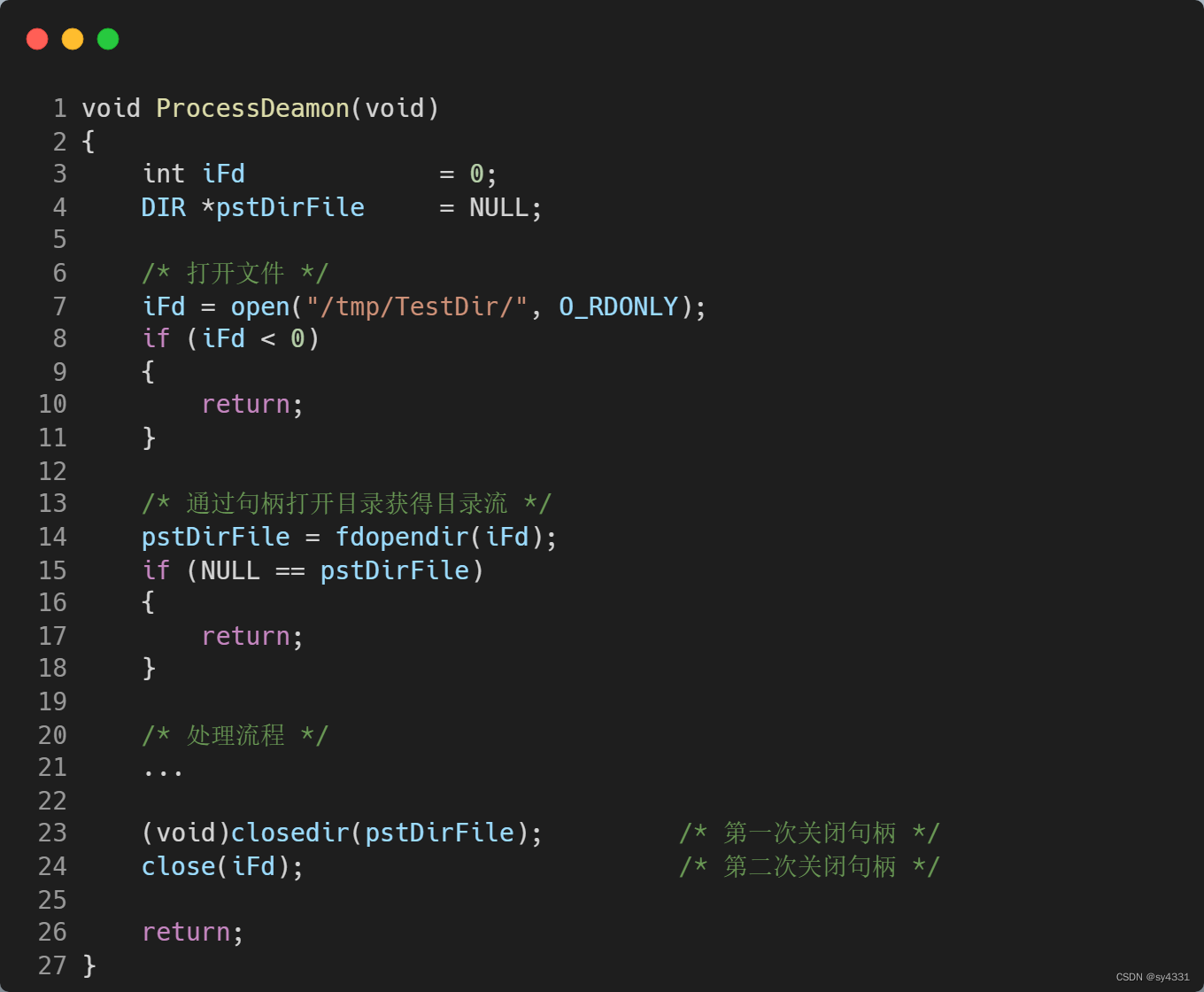
在上面的实例代码中,我们首先通过open获取了文件夹句柄iFd,然后又通过iFd调用fdopendir获得了目录流。注意,此时iFd和pstDirFile指向同一个文件file结构体。处理结束后,调用closedir和close先后关闭了pstDirFile和iFd。由于两者指向的是同一个文件file结构体,因此该句柄关闭了两次,这有可能异常关闭了其他文件,导致数据异常。因此,我们只需要调用closedir和close其中一个即可完成关闭文件的操作。
还有另外一组文件接口也可能存在类似的问题:open和fdopen。
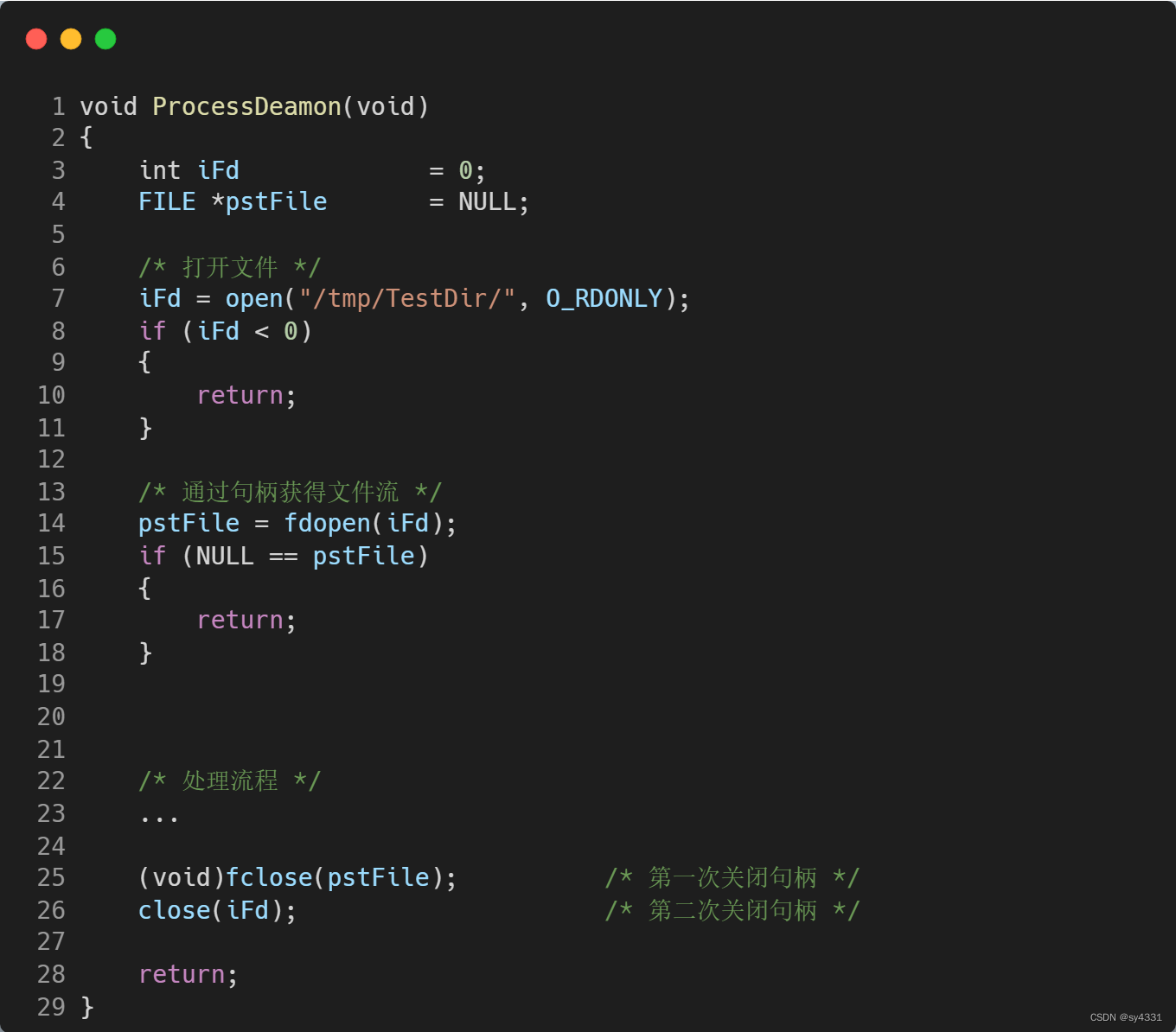
当我们使用fdopen完成文件句柄转化为高级文件流FILE *时,在使用完毕后也只需要选择fclose和close其中之一完成文件的关闭即可,不能重复调用,否则会重复关闭句柄,出现异常。
当我们梳理所有使用fdopendir/fdopen接口的场景,完成修改所有重复关闭句柄的错误代码后,再进行多次的压力测试尝试复现,运行多天后仍然未复现,说明问题即为上述的因fdopendir/fdopen错误使用出现重复关闭句柄导致数据库异常。
其实为了找到异常关闭数据库的具体位置,我们也可以继续仿照查找改写数据库位置的流程,在内核中关闭文件的接口close的必经流程中添加特殊处理。若关闭的文件是数据库文件mdb.data,且当前进程不是product_init,则说明数据库文件被异常关闭,此时发送SIGSEGV信号杀死进程并产生coredump。当问题复现后,我们分析coredump即可找到数据库文件具体被关闭的流程,从而找出问题根源。
问题总结
fdopendir/fdopen接口返回的目录流DIR *和文件流FILE *和open接口返回的句柄是指向的同一个文件file结构体,因此我们在使用fdopendir/fdopen接口完后,只需要选择close和closedir/fclose其中一个即可完成文件的关闭。若我们同时调用两类接口关闭文件将出现重复关闭句柄的现象,有可能关闭了其他正在使用的文件,造成数据异常。















 3210
3210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









