







本文是对由Stanford大学Andrew Ng讲授的机器学习课程进行个人心得总结。
在机器学习中,回归算法是入门级的课程,但由于其较易理解,该算法也是生产环境中使用最为广泛的算法。本文将从线性回归开始一步一步讲述作者对回归算法的理解。
问题的引出
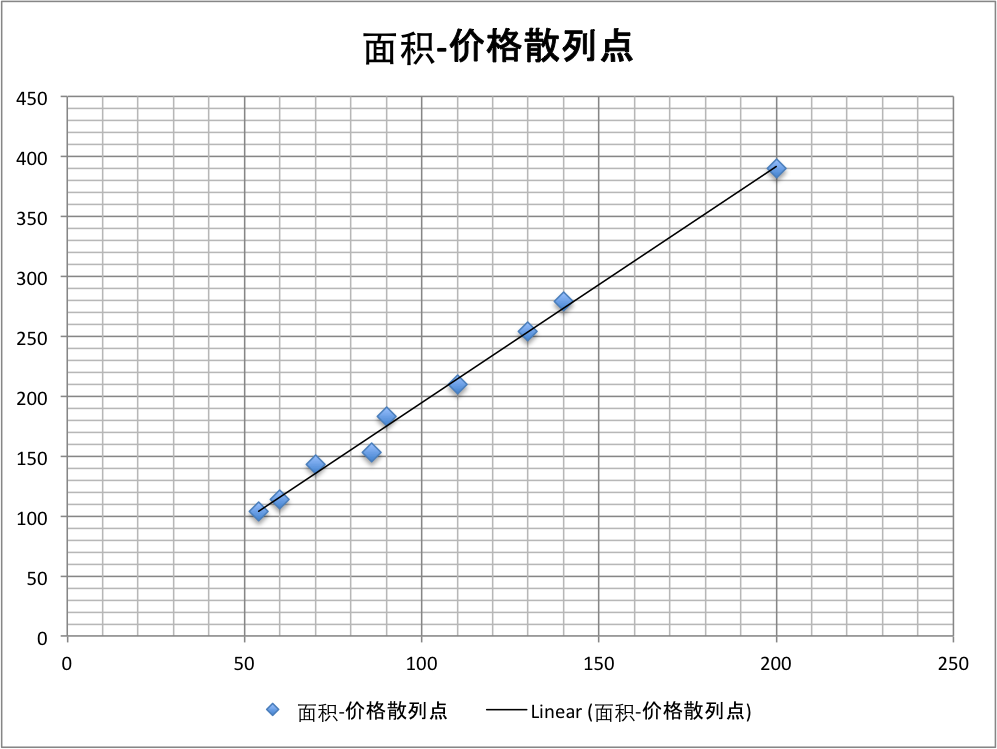
线性回归中常提到的一个例子是房价问题,比如说如下是最近北京地区交易的房屋成交价列表
| 面积 | 价格 |
|---|---|
| 90 | 183 |
| 54 | 104 |
| 60 | 114 |
| 200 | 390 |
| 130 | 254 |
| 140 | 279 |
| 70 | 143 |
| 110 | 210 |
| 86 | 153 |
目前我们想出售一个面积为100平的房屋,想问一下该房屋应该如何估价较为合理。
将该数据映射到X-Y轴上制成散列图,在图中可以看出数据目前可能满足线性分布(实际情况下房价和房屋面积之间并不是线性分布,当前我们仅以次为例),故当前我们假设房价和房屋面积之间的关系为
y=A∗x+b
这个过程可用下图表示:
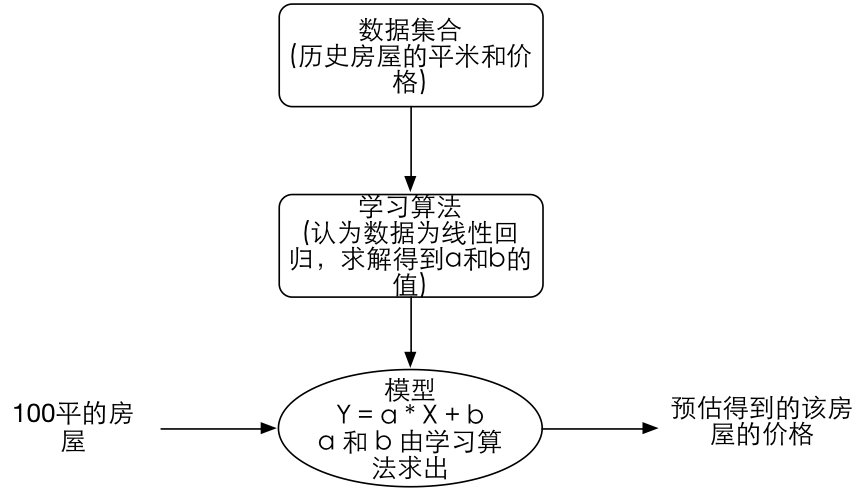
接下来我们的工作变为求解 a 和 b 的值,然后利用得到的a和b的值去预估我们想要出售的100平的房屋售价为多少。该逻辑可用下图表示:
为了将该讲解变得更有普遍性,我们将输入的“房屋面积”认为是数据的特征(feature), 输出的价格认为是目标值(target),而将
a∗X+b
认为是假设模型(hypothesis),
y=h(x)
;
另外,我们会将训练集合的数据个数(即上文用于拟合曲线的样本数)认为是 特征的维数。
线性回归模型
这里讨论线性回归模型时会注重一些通用性。
在之前我们讨论的内容里所有的输入的特征维度只是一维(房屋的面积), 但真实生活中我们遇到的问题可能更多的是多个特征存在的情况。 比如我们出售房屋时不仅仅有房屋的面积,可能还包括 税负等等, 假设税负是我们需要考虑的第二个维度。 则当前我们的输入特征x是一个二维矢量:其中,
x1
表示房子的面积,
x2
表示房屋的税负, 则
x(i)1
表示 第
i
个房子的面积;
x(i)2
表示 第
i
个房子的税负;
于是我们假设输入特征x与房价y之间满足的线性函数应该为:
hθ(x)=Θ0+Θ1x1+Θ2x2
Θi
即为输入特征x与结果y的线性函数h的相关参数, 这里我们可以假设存在
x0=1
, 则该公式可以简化为
hθ(x)=∑n(i=0)(Θixi)=ΘTx
以上是对线性回归模型的定义和假设,目前我们得到了h_θ (x)的表达式,在接下的工作中我们需要做的是通过运算获得各个Θ_i的具体值。在线性回归中,我们定义了一个代价函数, 该函数用来描述h(x) 和 y 之间的接近程度:
J(Θ)=1/2∑ni=0[(hθ(x(i))−y(i))]2
该公式本质上就是不停的求
hθ(x)
与y之间的差值,当该差值最小时,我们此时认为
hθ(x)
能最好的预测y的值。该公式中的1/2 是为了在计算导数时方便消除掉平方而临时添加的常数。
基于该公式,我们推出了下一步的研究方向:梯度下降法。
梯度下降法
对于
J(Θ)
来说,我们想要取得该变量的最小值,其在数学上常用的方法为求
J(Θ)
的导数,然后不停的向导数的反方向移动,使得该值不断地减小,借用Androw Ng课程中的表述图片如下所示:
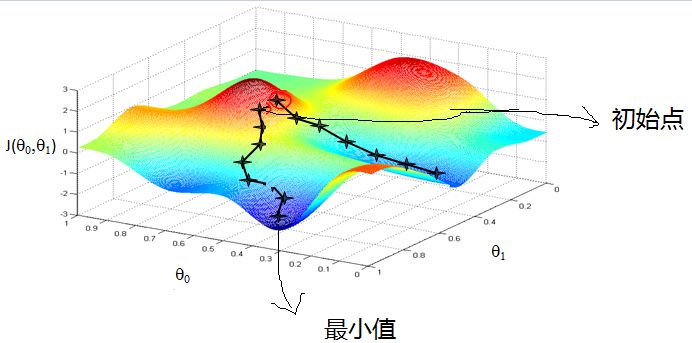
在上图中蓝色部分为
J(Θ)
的极小值区域,红色部分为
J(Θ)
的极大值区域。我们目前所要做的工作是在图中随机选择一个初始点,然后将该点移动到极小值的区域。
在数学上处理这个问题的方式是让初始点一直沿着导数的反方向移动,在机器学习里将该方法称为 梯度下降法。其数学公式表示为:
Θj:=Θj−α∂∂ΘjJ(Θ)
其中,
:=
为赋值符号;
α
被称为学习率,即梯度下降的速率。
梯度的方向由
J(Θ)
对
Θ
的偏导所决定, 因此我们需要做的是对偏导数取负方向得到最小值,将
J(Θ)
带入到上式中可推知(里面仅对
Θj
求导,故其他无关项可以消除掉):
Θj:=Θj−α(hΘ(x)−y)xj
以上就是在有一个训练样本的情况下推得的梯度下降公式,如果将样本扩展到m个的情况下,其梯度下降公式会变为:
Θj:=Θj−α∑m(i=0)(hΘ(x(i))−y)x(i)j
基于该公式,我们的参数更新算法如下所示:
Repeat until convergence{
Θj:=Θj−α∑m(i=0)(hΘ(x(i))−y)x(i)j
(for every j)
}
即不停地迭代计算
Θj
直到收敛为止。
以上算法被称为批量梯度下降。其中需要将全部变量带入进行梯度下降的计算,故该算法耗时较长。
为了提高计算速度,一种被称为随机梯度下降的方法被提出。该算法表示为
Repeat until convergence{
Θj:=Θj−α(hΘ(x(i))−y)x(i)j
(for every j)
}
其中每次迭代仅使用单个训练样本对 Θ 的值进行更新,其梯度下降速度大大加快。对于较大的数据集而言,一般倾向于采用随机梯度下降的方法。

















 2199
2199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









