







计算机系统
大作业
题 目 程序人生-Hello’s P2P
专 业 ** **
学 号 ********
班 级 ****
学 生 ****
指 导 教 师 ****
*************
*******
本文以程序人生-Hello’s P2P为题,揭示了编程界的传奇hello的一生。当hello.c源程序被编写完毕时,hello开启了它的传奇一生——从预处理、编译、汇编、链接生成可执行文件到在系统上运行hello,再到运行完毕被回收,hello结束了它的传奇一生,完成了P2P与020的过程。hello的传奇一生反映了计算机系统底层的基本内容与基本原理,跟踪hello的一生就是深入理解计算机系统的过程。
关键词:计算机系统;程序生命周期;Linux;Hello程序
目 录
第1章 概述
1.1 Hello简介
Hello的P2P(Program to Process)过程是指从程序到进程的转变过程。首先,编写hello.c源文件,然后经过预处理、编译、汇编(和链接的过程,生成可执行文件。具体过程如下:
- 预处理阶段:预处理器(cpp)根据以字符#开头的命令,修改原始的C程序。比如hello.c中第1行的#include <stdio.h>命令告诉预处理器读取系统头文件stdio.h的内容,并把它直接插人程序文本中。结果就得到了另一个C程序,通常是以.i作为文件扩展名。
- 编译阶段:编译器(ccl)将文本文件hello.i翻译成文本文件hello.s,他包含一个汇编语言程序。该程序包含函数main的定义,如下所示:
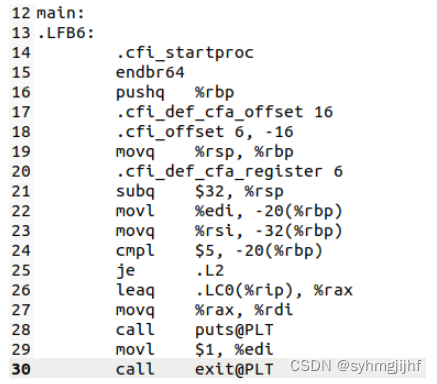
图1.1.1 编译程序
定义中14~30行的每一条语句都以一种文本格式描述了一条低级机器语言指令。汇编语言是非常有用的,因为它以不同高级怨言的不同编译器提供了一种通用的输出语言。
- 汇编阶段:接下来,汇编器( as )将he11o,翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序( relocatable obiect program )的格式,并将结果保存在目标文件hello . o中。hello .o文件是一个二进制文件,它包含的17个字节是函数main的指令编码。如果我们在文本编辑器中打开hel1o .o文件,将看到一堆乱码。
- 链接阶段:请注意,hel1o程序调用了printf函数,它是每个C编译器都提供的标准C库中的一个函数。printf函数存在于一个名为printf . o的单独的预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的hello .o程序中。链接器( ld )就负责处理这种合并。结果就得到hello文件,它是一个可执行目标文件(或者简称为可执行文件),可以被加载到内存中,由系统执行。

图1.1.2 编译系统
Hello的020(From Zero to Zero)过程是从无到有再到无的。指的是用fork()函数在shell中创建子进程,再用exceve语句加载可执行程序hello,此时,操作系统为其分配虚拟内存,映射到物理内存,完成了从无到有。内存管理器和中央处理器在执行过程中调用三级cache、快表(TLB)、内存等行物理内存上的取数据操作,再通过I/O根据代码指令输出。程序执行完后,对其进行回收,操作系统内核把它从操作系统清除,完成了从有到无。这就是整个020的过程。
1.2 环境与工具
1.2.1 硬件环境
X64 CPU;2.6GHz;16G RAM;512GHD Disk
1.2.2 软件环境
Windows11 64 位; Vmware16; Ubuntu 22.04
1.2.3 开发工具
Visual Studio 2022 64位 ,Code Blocks 64位, vi/vim/gedit+gcc
1.3 中间结果
| 文件名 | 作用 |
| hello.i | 预处理hello.c生成的文件 |
| hello.s | 对hello.i 进行编译生成的文件 |
| hello.o | 对hello.s 进行汇编生成的文件 |
| hello.elf.txt | 对hello.o 进行readelf生成的文件 |
| asm.txt | 对hello 进行objdump反汇编生成的文件 |
| hello | 可执行目标文件 |
| asm1.txt | 对hello进行objdump反汇编生成的文件 |
| hello.txt | 对hello 进行readelf生成的文件 |
1.4 本章小结
本章介绍了hello的P2P以及020的过程,并且介绍了本次大作业的软硬件环境及开发工具。同时还列出了完成大作业的中间结果文件。
第2章 预处理
2.1 预处理的概念与作用
- 概念:预处理也叫做预编译,是指在正式开始编译前的操作。预处理器(cpp)根据以字符#开头的命令,修改原始的C程序,读取系统头文件中的内容并把它直接插入程序文本,获得另一个文件后缀为.i的文件。
- 作用:
- 能够完成头文件的包含,将包含的文件插入到程序文本中;
- 可以进行宏替换,把它的符号用实际存在的常量加以替换;
- 删除注释部分;
- 实现特殊控制指令(如#error);
- 选择符合条件的代码送至编译器编译,完成条件编译,有选择地执行相关操作(如#if,#elif,#else)。
2.2在Ubuntu下预处理的命令
预处理的命令为:gcc -m64 -no-pie -fno-PIC -E hello.c -o hello.i
![]()
图2.2.1 预处理命令
图2.2.2 hello.i文件展示
生成的hello.i文件截图:

图2.2.3 hello.i
2.3 Hello的预处理结果解析
打开hello.c和hello.i程序,注意到预处理文件(hello.i)最后的代码段与原来的hello.c源程序的代码是相同的,即预处理没有对代码段进行处理。并且hello的预处理结果hello.i共有3092行,远多于hello.c。同时我们发现hello.i文件中删除了.c文件中原本的注释部分,也即预处理会删除注释部分。
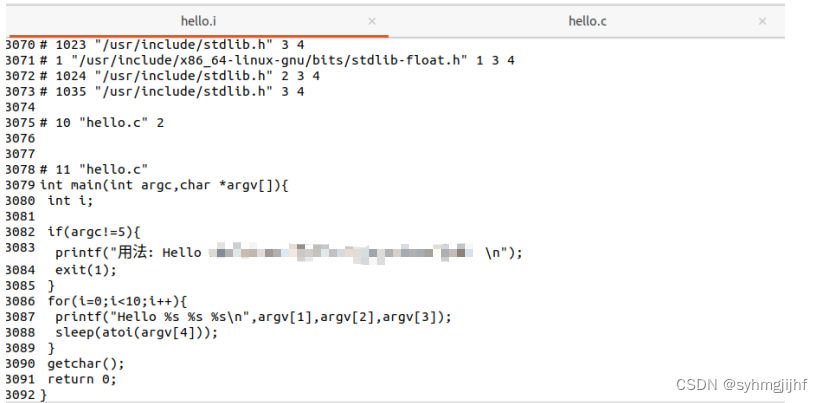
图2.3.1 预处理文件代码段截图
图2.3.2 源c代码文件头文件截图
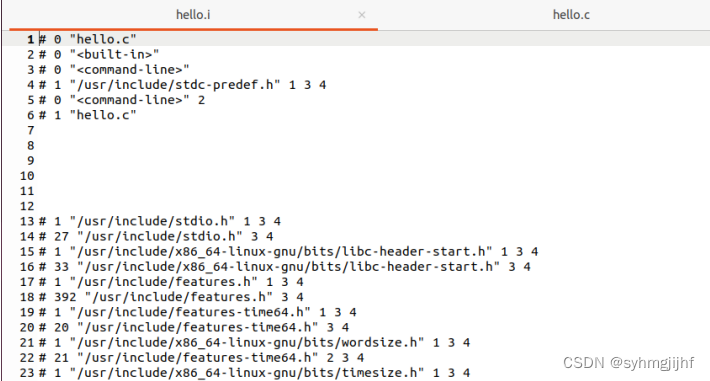
图2.3.3 预处理文件头文件截图
从下图我们还能看到,程序的最开始的几行给出了这个对该文件的解释。此外,程序中把stdio.h,unistd.h,stdlib.h三个文件解析出来,找到它们的实际地址,把其中的语句直接插入到hello.i文件中,这也是导致hello.i文件有约三千行代码,远远多于hello.c的几十行代码的最主要原因。
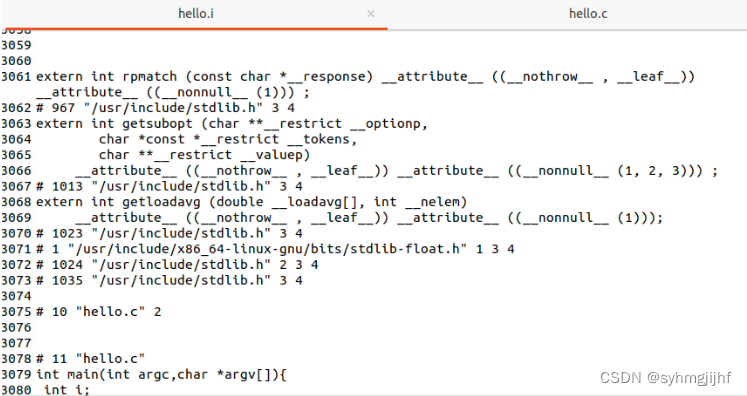
图2.3.4 预处理文件头文件解析截图
2.4 本章小结
本章详细介绍了预处理的概念和作用,并对Ubuntu系统下生成的预处理文件hello.i和源hello.c文件进行了比较,分析出其中的联系与不同。
(第2章0.5分)
第3章 编译
3.1 编译的概念与作用
- 概念:编译是把源程序直接变为机器可识别的目标代码。(将源程序一次性转换成目标代码的过程)。执行编译过程的程序叫做编译器。
- 作用:把适合人阅读的高级程序代码,转变成机器易于阅读的机器语言。同时人也可以读懂机器语言,从而对程序进行性能上的提升。
3.2 在Ubuntu下编译的命令
命令:gcc -m64 -no-pie -fno-PIC -S hello.i -o hello.s
![]()
图3.2.1 编译命令
图3.2.2 hello.s文件展示
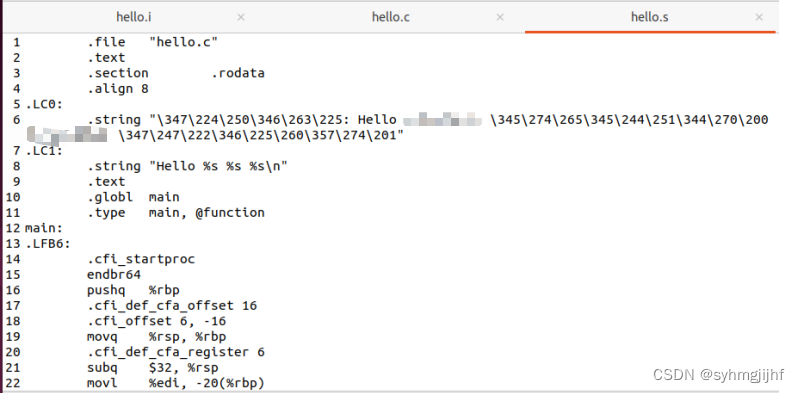
图3.2.3 hello.s部分代码
3.3 Hello的编译结果解析
- 数据
- 常量:我们可以看到第3行的.rodata(read only data)表明下面的第六行的.string数据为只读,也即源程序两个printf函数中的字符串常量。而第21行中的$32表示的是32这个立即数,是数字常量。
- 局部变量:局部变量通常保存在寄存器或栈中。我们的程序中有三个局部变量:i、argc、argv。我们以argc为例,分析其过程。程序的第22行表明如下信息:%edi中为传入的参数argc,-20(%rbp)表示要把其值送入栈中,接下来可以通过rbp的相对偏移量进行访问。

图3.3.1 hello.s数据和代码段
- 赋值
在汇编语言中,通常使用mov指令进行赋值,根据赋值的字长不同,后面跟上不同的字母。如汇编代码中第22行把edi寄存器的值赋值给rbp寄存器地址-20对应内存地址处,第28行把1赋值给%edi寄存器内部等等。
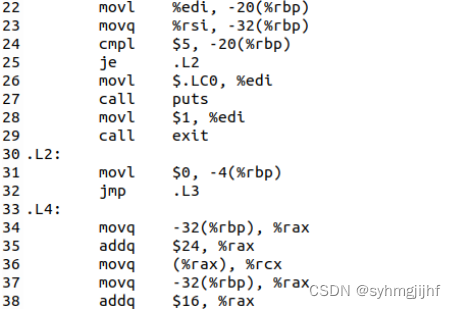
图3.3.2 编译代码
- 类型转换
在程序的第51行,跳入atoi函数把字符串显式转换成整型int
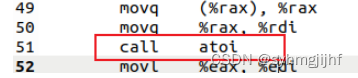
图3.3.3 call指令
- 算术操作
在程序的51行,完成了一个加法操作,并且结合下面的代码可以看出,这是对存放于栈中-4(%rbp)位置的局部变量i的值进行加法操作,每次加1直到它的值达到5才不发生跳转而是继续执行。
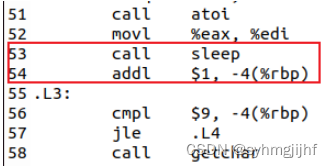
图3.3.4 addl指令
- 关系操作
使用cmpl指令,比较rbp寄存器-20的内存地址处的值和立即数5的大小,如果相等则跳转到.L2继续执行,如果不相等则跳过该指令向下执行。这是一个关系操作。
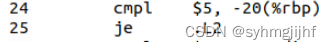
图3.3.5 cmpl指令
- 数组、指针、结构操作
如图所示,源代码中对数组的操作在汇编程序中变为对地址的加减操作。其中-32(%rbp)存放数组首地址即argv[0],后续在其基础上进行地址偏移,完成了对数组的访问。
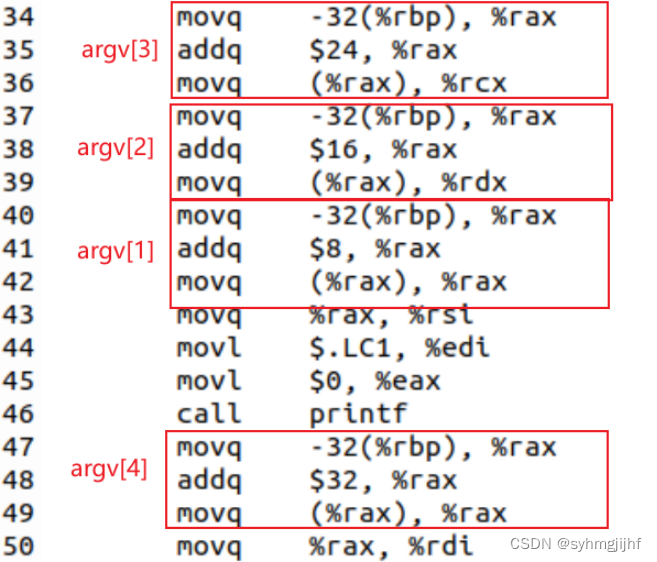
图3.3.6 数组访问
- 控制转移
如图所示,.L3的第一二行是一个有条件跳转,只有当-4(%rbp)的值小于等于9时才会发生跳转,跳转到.L4。
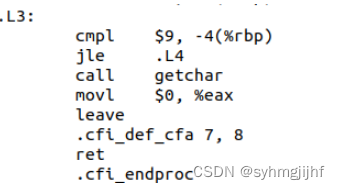
图3.3.7.1 有条件跳转
如下图所示,展示的是一个无条件跳转,程序执行到第32行直接执行跳转指令,跳转到.L3。
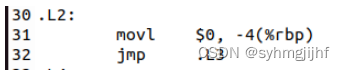
图3.3.7.2 无条件跳转
- 函数操作
(1)参数传递
调用函数之前,编译器会将参数存储在寄存器中,以供调用的函数使用。
(2) 函数调用
如图所示,在hello.c源程序中共有5个函数调用,由于printf函数调用了2次,而其他函数都是1次,所以总的调用次数是6次。
图3.3.8.1函数调用
- 15行, 调用printf函数, 编译器采用调用puts函数
![]()
图3.3.8.2 hello.s的puts函数实现printf函数
- 16行,调用exit函数,结束进程。

图3.3.8.2 .3.8.2 hello.s的exit函数
- 19行,调用 printf函数,实现printf(“Hello %s %s %s\n”,argv[1],argv[2],argv[3])
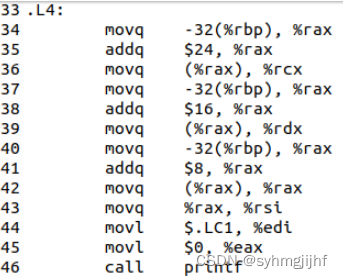
图3.3.8.3 hello.s的printf函数
- 调用atoi函数, 将字符串类型转化为整型(int)

图3.3.8.4 hello.s的atoi函数
⑤ 20行,调用sleep函数, 将atoi函数的返回作为sleep的参数调用,实现让函数进入x秒休眠,如果在休眠结束前停止则会返回剩余时间。
![]()
图3.3.8.5 hello.s的sleep函数
- 22行,调用getchar函数
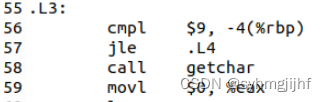
图3.3.8.6 hello.s的getchar函数
(3)函数返回
程序使用汇编指令ret从调用的函数中返回,并且还原栈帧,并且函数的返回值存放在寄存器%rax中。

图3.3.8.7 hello.s的函数返回
3.4 本章小结
本章介绍了编译的概念与作用, 并在linux下对hello.i进行了编译操作,分析了编译的生成结果hello.s的数据, 赋值,算术操作,关系操作,数组/指针/结构操作,控制转移,函数操作方面的内容。
第4章 汇编
4.1 汇编的概念与作用
- 概念:汇编是指经过汇编器(as)把汇编语言程序(hello.s)翻译成机器指令,并把这些指令打包成可重定位目标程序的形式,并保存在hello.o文件中。
- 作用:把汇编语言翻译成计算机能够直接执行的0、1机器语言,把文本文件转化成二进制文件。
4.2 在Ubuntu下汇编的命令
命令:gcc -m64 -no-pie -fno-PIC -c hello.s -o hello.o
![]()
图4.2.1 汇编命令
4.3 可重定位目标elf格式
查看hello.o的ELF格式并分析,把其输出到文本文件elf.txt中
![]()
图4.3.1 查看elf格式
ElF文件包括ELF头、节头表、重定位节、符号表等,并且在其中列出了各节的基本信息,包括类型、地址等等,具体的分析如下:
(1)ELF头
如图4.3.2所示,ELF头中描述了文件类别、数据存放方式、版本号、操作系统等信息。并且给出了入口点地址和程序头起点以及节头表的偏移。

图4.3.2 elf头
(2)节头表
如图4.3.3所示,节头表中描述了文件中各个节的类型、大小、地址、偏移、读写访问权限等信息。

图4.3.3 节头表
(3)重定位节
文件中有两个重定位节,分别是.rela.text和.rela.eh_frame节。不同的重定位节对应不同节的重定位信息。连接器在处理目标是要对目标文件进行重定位,这时需要重定位节中的信息才能知道如何进行重定位。如图4.3.4所示,偏移量指出重定位的字节偏移量,类型指出重定位类型等。有了这些信息才能正确地进行重定位。
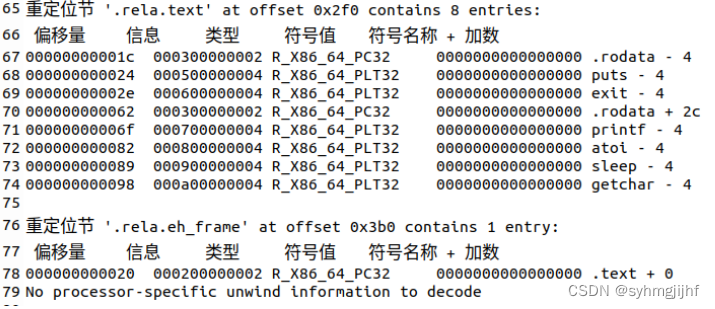
图4.3.4 重定位节
(4)符号表
如图4.3.5所示,在符号表中列出了程序中所有定义和引用的全局变量以及函数的信息:

图4.3.5 符号表
4.4 Hello.o的结果解析
(以下格式自行编排,编辑时删除)
objdump -d -r hello.o 分析hello.o的反汇编,并请与第3章的 hello.s进行对照分析。
说明机器语言的构成,与汇编语言的映射关系。特别是机器语言中的操作数与汇编语言不一致,特别是分支转移函数调用等。
在Ubuntu下利用反汇编指令生成asm.txt反汇编文件,如图4.4.1和图4.4.2所示:
![]()
图4.4.1 hello.o的结果解析
图4.4.2 asm.txt文件展示
对反汇编文件asm.txt和汇编程序hello.s对比分析如下:
如图所示左侧是asm.txt右侧是hello.s文件
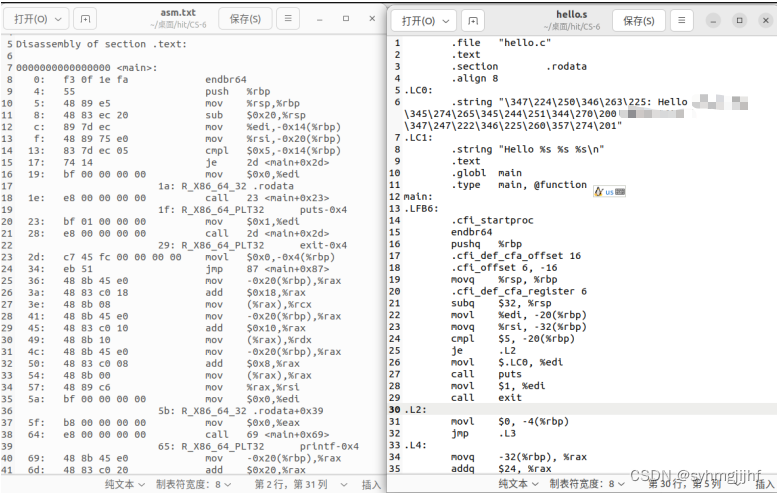
图4.4.3 asm.txt与hello.s对比
- 函数调用:在hello.s中函数调用直接引用函数名称即可,而在反汇编文件asm.txt中,函数调用是使用call指令就加上被调用函数的首地址形成的一条跳转指令。
- 操作数的进制表示:在hello.s中在进行栈指针移动的时候,使用的是十进制数,而在反汇编文件asm.txt中使用的是十六进制数。
- 分支转移:在hello.s中分支转移目标的位置是使用.L表示的,即给出一个跳转的索引位置,而在反汇编文件asm.txt中每一个跳转指令的目标位置都是对应的跳转地址。
4.5 本章小结
本章介绍了汇编的概念与作用,并在Ubuntu下实际操作进行汇编,将hello.s被转化为hello.o,通过readelf分析了hello.o的ELF格式,分析了其各节的基本信息。同时还使用objdump将hello.o反汇编生成asm.txt反汇编文件,并与汇编程序hello.s文件进行比对分析。
第5章 链接
5.1 链接的概念与作用
- 概念:链接(linking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。
- 作用:链接器在软件开发中扮演着一个关键的角色,因为它们使得分离编译(separate compilation)成为可能,我们不用将一个大型的应用程序组织为一个巨大的源文件,而是可以把它分解为更小,更好管理的模块,可以独立的修改和编译这些模块,当我们改变这些模块中的一个时,只需简单的重新编译它,并重新链接应用,而不必重新编译其他文件。
5.2 在Ubuntu下链接的命令
命令:
ld -o hello -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o /usr/lib/x86_64-linux-gnu/libc.so /usr/lib/x86_64-linux-gnu/crtn.o

图5.2.1 链接命令
图5.2.2 hello链接文件展示
5.3 可执行目标文件hello的格式
分析hello的ELF格式,用readelf等列出其各段的基本信息,包括各段的起始地址,大小等信息。
通过指令readelf -a hello > elf1.txt来把elf文件写入到elf1.txt中如下图所示:

图5.3.1 elf1.txt文件展示
打开elf1.txt,如图5.3.2所示,可以看到可执行文件hello的elf格式,其中最左侧一列为节名,第二列为节类型,第三列为起始地址,第四列是偏移量。
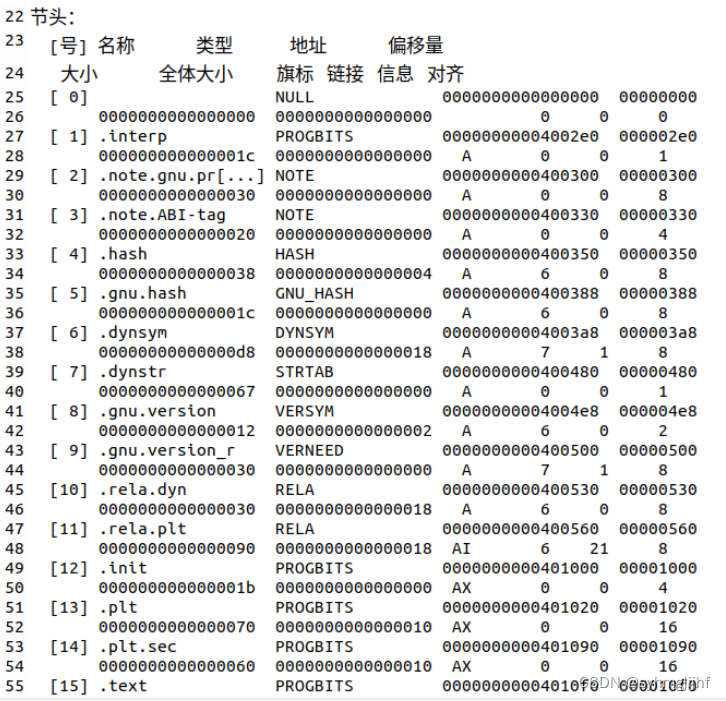
图5.3.2 elf1.txt节头
5.4 hello的虚拟地址空间
使用edb加载hello,查看本进程的虚拟地址空间各段信息,并与5.3对照分析说明。
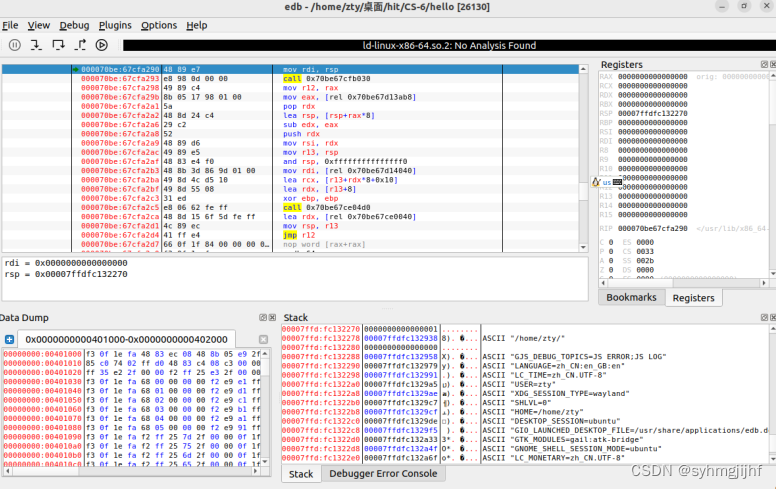
图5.4.1 edb查看虚拟地址空间
使用edb加载hello,查看本进程的虚拟地址空间各段信息,edb中显示的虚拟地址和elf文件中看到的虚拟地址是对应相同的。
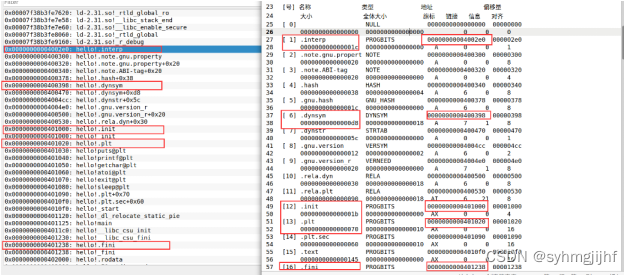
图5.4.2 虚拟地址空间对比
.init节: 该段代表程序的开始,存放着指令的机器码.可知该段地址从0x401000开始,偏移量为0x1000.
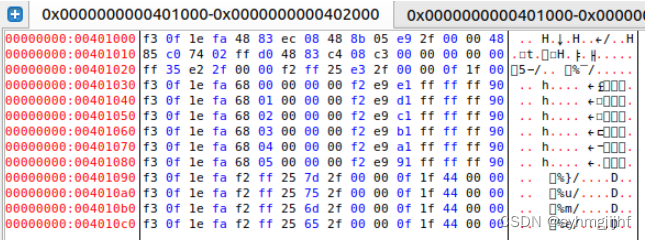
图5.4.3 edb查看.init节
5.5 链接的重定位过程分析
运用objdump -d -r hello > asm1.txt把hello反汇编写入asm1.txt如图5.5.1和图5.5.2所示,接下来我们对asm1.txt(hello的反汇编文件)和asm.txt(hello.o的反汇编文佳)进行分析比对,这实际上就是在比较hello与hello.o的不同,具体分析如下:

图5.5.1 重定位命令

图5.5.2 asm1.txt文件展示
(1)为指令分配虚拟地址
如图5.5.3所示,左侧是链接前的反汇编,右侧是链接后的。在hello.o的反汇编程序中,函数中的语句前面的地址都是从函数开始从依次递增的,而不是虚拟地址;而经过链接后,在右侧的返回变种每一条指令都被分配了虚拟地址。
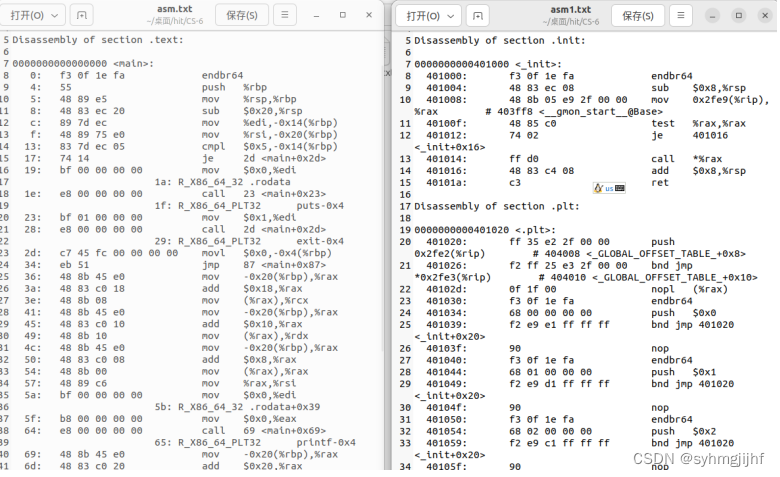
图5.5.3为指令分配虚拟地址
(2)函数调用
如图5.5.4所示,在左侧helllo.o的反汇编程序中,图中选中的函数调用指令由于还没有分配虚拟地址,所以只能用偏移量跳转,而右侧链接后已经分配好了虚拟地址,可以直接用call虚拟地址进行跳转.

图5.5.4函数调用
(3)跳转指令
同理函数调用,链接后可以采用虚拟地址跳转,如图5.5.5所示

图5.5.5跳转指令
(4)调入C标准库函数
在hello.o中只有main函数段,还没有把标准库函数插入,经过链接后,调用的C标准库函数的代码被插入其中,如图5.5.6所示。
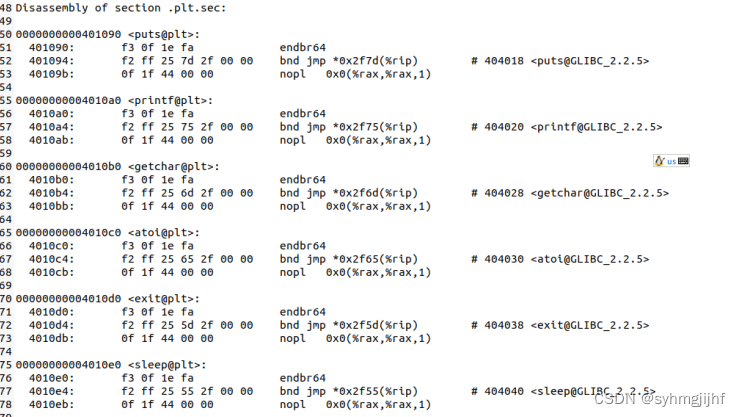
图5.5.6链接过程插入C语言标准库函数
综上所述,链接的过程主要分为两个过程:符号解析和重定位。
符号解析时解析目标文件定义和引用符号,并建立每个符号引用和符号定义之间的关联。
重定位时分为两个步骤,先重定位节和符号定义,把相同类型的节合并,并为其分配内存。接下来进行符号引用的重定位,修改代码和数据中对符号的引用,使得他们指向正确地址。
5.6 hello的执行流程
其调用与跳转的各个子程序名或程序地址如下:
<_init>:401000
<.plt>:401020
<puts@plt> :401090
<printf@plt>:4010a0
<getchar@plt>:4010b0
<atoi@plt>:4010c0
<exit@plt>:4010d0
<sleep@plt>:4010e0
<_start>:4010f0
<_dl_relocate_static_pie>:401120
<main> :401125
<_libc_scu_init>:4011c0
<_libc_csu_fini>:401230
<_fini>: 401238
5.7 Hello的动态链接分析
当程序在调用共享函数库的时候,我们无法预测这个函数的地址,因为定义他的模块可以在再运行时加载到任意位置。此时,使用延迟绑定的策略,把这个过程地址的加载推迟到第一次调用该进程的时刻。
延迟绑定是通过两个数据结构之间的交互来实现的,分别是GOT和PLT,GOT是数据段的一部分,而PLT是代码段的一部分。PLT与GOT的协作可以在运行时解析函数的地址,实现函数的动态链接。
过程链接表PLT是一个数组,每个条目是16字节代码。PLT[0]是一个特殊条目,跳转到动态链接器中。每个被可执行程序调用的库函数都有它自己的PLT条目。
动态连接器使用GOT和PLT实现函数的动态链接。其中GOT存放的是函数的目标地址,PLT使用GOT中地址跳转到目标函数。GOT和PLT信息如下图所示:

图5.7.1 GOT和PLT信息
可以在edb中找到该节的内容并观察其在运行dl_int前后内容的变化,如图5.7.2和5.7.3所示,有内容发生变化。

图5.7.2 调用dl_init前的情况

图5.7.3 调用dl_init后的情况
5.8 本章小结
本章介绍了链接的概念和作用,链接的命令,分析了可执行目标文件hello的格式,通过edb展示了hello的虚拟地址空间,分析链接重定位过程,分析hello的执行流程,动态链接过程。
第6章 hello进程管理
6.1 进程的概念与作用
- 概念:进程的经典定义就是一个执行中程序的实例,系统中的每个程序都运行在某个进程的上下文中,上下文是由程序正确运行所需的状态组成的,这个状态包括存放在内存中的程序的代码和数据、它的栈、通用目的寄存器的内容,程序计数器、环境变量,以及打开文件描述的集合。
- 作用:提供给应用程序两个关键抽象,(1)一个独立的逻辑控制流,它提供一个假象,好像我们的程序独占的使用处理器。(2)一个私有的地址空间,它提供一个假象,好像我们的程序独占的使用内存系统
6.2 简述壳Shell-bash的作用与处理流程
- 作用:Shell是一种命令行解释器,它为应用程序的执行提供一个界面,用户通过这个界面访问操作系统内核的服务,shell读取用户输入的字符解释并执行。
- 处理流程:
(1)shell从终端读入用户输入的命令。
(2)将输入字符串进行划分以获得所有参数。
(3)判断是否是内置命令,是则立即执行,否则调用相应的程序为其分配子进程并运行。
(4)Shell接受键盘输入信号并对这些信号进行相应处理。
6.3 Hello的fork进程创建过程
在终端输入./hello的输入命令后,shell进行命令行解释,由于不是内置shell指令,shell会调用fork函数创建一个子进程并执行可执行程序hello。新创建的子进程几乎与父进程相同,子进程得到与父进程用户及虚拟地址空间相同的但是独立的一份副本,包括代码和数据段、堆、共享库以及用户栈,子进程还获得与父进程任何打开文件,描述符相同的副本,这就意味着,当父进程调用fork函数时,子进程可以读写父进程中打开的任何文件。
6.4 Hello的execve过程
执行exexve过程时,会加载并运行程序。加载器将删除子进程现有的虚拟内存段,创建一组新的段(该栈堆的初始化为0),新程序启动后栈的结构如图所示,并将虚拟地址空间中的页映射到可执行文件的页大小的片chunk中,新的代码段与数据段被初始化为可执行文件的内容,然后转到_start。执行过程中还会覆盖当前进程的代码段,数据段,栈,保留有相同的PID,继承已经打开的文件描述符和信号上下文,exexve函数调用一次且一般不返回(有错误情况除外)。
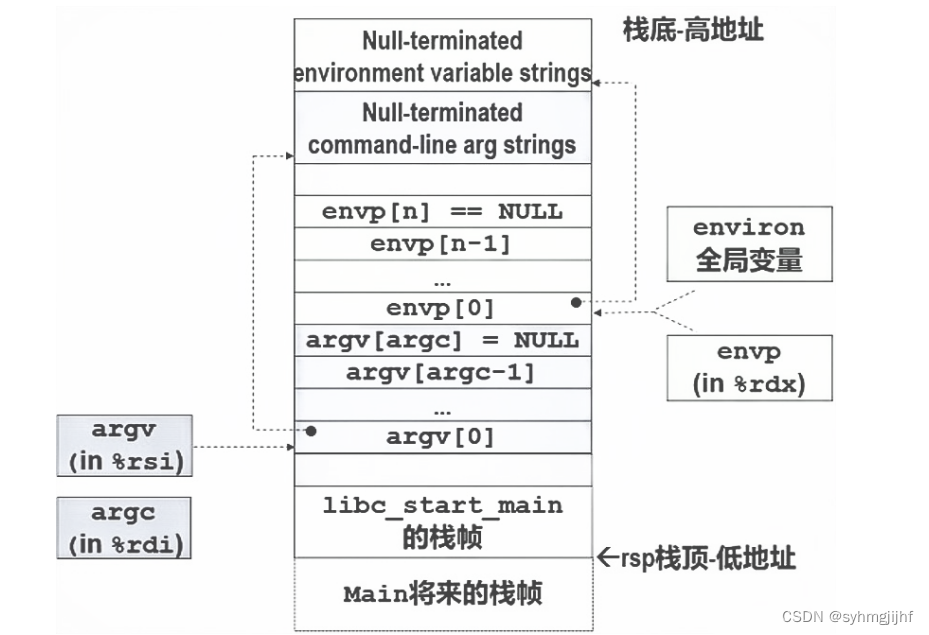
图6.4.1新栈的结构
6.5 Hello的进程执行
(1) 上下文信息:上下文信息是操作系统内核重新启动一个挂起的进程所需要恢复的状态。它由通用寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈和各种内核数据结构等对象的信息构成。
(2)时间片;一个进程执行它的控制流的一部分的每一时间段叫做时间片。
(3)进程调度:在进程执行过程中,操作系统内核可以决定抢占当前进程,并重新开始一个先前被挂起的进程,这样的一种决策叫做进程调度。当抢占进程时,要完成以下三个任务:①保存之前进程的上下文;②恢复要执行的新进程的上下文;③把控制转让给新恢复的进程完成上下文切换。
(4)用户模式和内核模式:处理器通常使用一个寄存器来区分两种模式,这个寄存器描述了当前进程的权限情况。简单来说,两种模式有不同的“权限”,用户模式权限较低,不允许执行特权指令,也不允许直接引用地址空间中内核区内的代码和数据;内核模式权限较高,可以执行任何命令,并且可以访问系统中的任何内存位置。
(5)进程执行与用户态核心态转换:当开始运行hello时,内存为hello分配时间片,若一个系统同时运行多个进程,则它们轮流使用处理器,物理控制流被划分成多个交错的逻辑控制流,存在并发执行的现象。然后在用户态下执行并保存上下文。如果在此期间内发生了异常或系统中断,则内核会休眠该进程,并在核心态中进行上下文切换,把控制权让给其他进程。当hello进程执行到sleep时,hello会进入休眠状态,此时再次进行上下文切换,控制交付给其他进程,一段时间后hello休眠结束,此时再次完成上下文切换,恢复休眠前的上下文信息,此时控制权送回hello并继续执行。循环结束后,程序调用 getchar() ,hello从用户模式进入内核模式,并再次上下文切换,控制交付给其他进程。最后,内核会从其他进程回到 hello 进程。
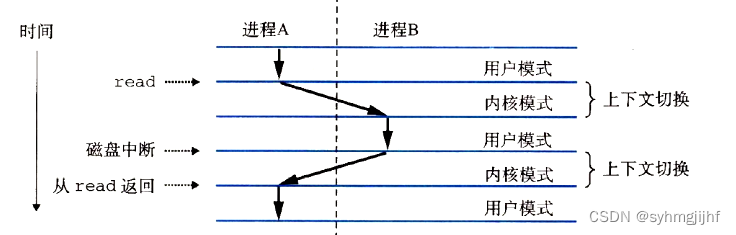
图6.5.1 进程上下文切换的流程
6.6 hello的异常与信号处理
hello执行过程中会出现哪几类异常,会产生哪些信号,又怎么处理的。
程序运行过程中可以按键盘,如不停乱按,包括回车,Ctrl-Z,Ctrl-C等,Ctrl-z后可以运行ps jobs pstree fg kill 等命令,请分别给出各命令及运行结截屏,说明异常与信号的处理。
6.6.1执行过程中可能出现的异常
(1)异步异常(中断)
在程序执行过程中由处理器外部IO设备引起的异常,如键盘上敲击Ctrl-C。处理
过程如图6.6.1所示。
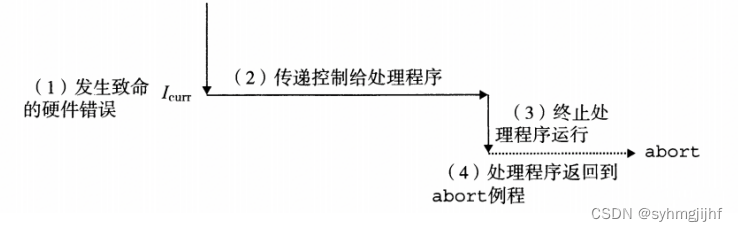
图6.6.1中断的处理过程
(2)同步异常之陷阱
陷阱是有意的异常,是指令的执行结果,如系统调用。处理过程如图6.6.2所示。
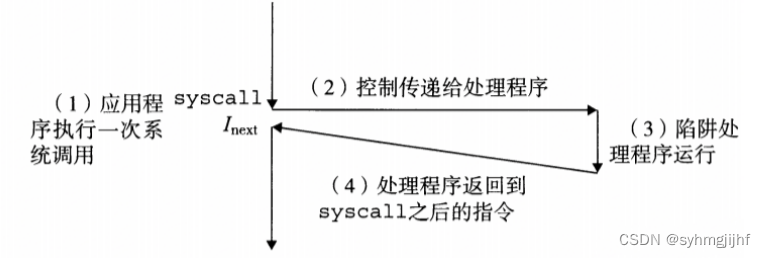
图6.6.2陷阱的处理过程
(3)同步异常之故障
故障不是有意的,但可能被修复,如缺页故障是可恢复的,但保护故障是不可恢复的,其处理过程如图6.6.3所示。
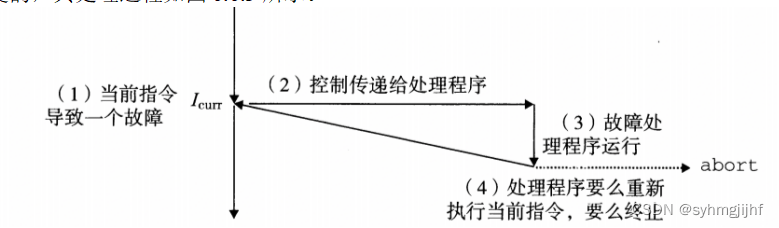
图6.6.3故障的处理过程
(4)同步异常之终止
终止是非故意的,不可恢复的致命错误造成的,如非法指令。其处理过程如图6.6.4所示。
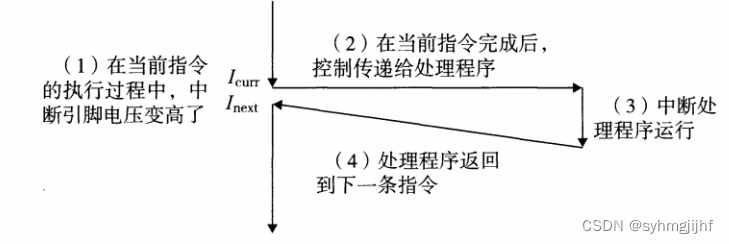
图6.6.4终止的处理过程
6.6.2可能出现的信号
hello执行过程中可能出现的信号有:SIGINT、SIGKILL、SIGSEGV、SIALARM、SIGCHLD。
6.6.3程序的运行
(1)正常运行
在终端输入./hello ********** zty *********** 1,终端每隔1秒打印输出一次Hello ********** zty ***********,共5次。输出后不会立刻结束程序,由于有一个getchar()函数的存在,键入一个回车后停止程序执行。如图6.6.5所示。
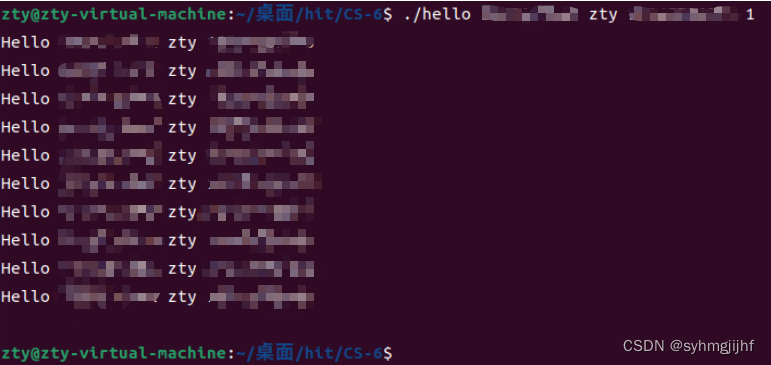
图6.6.5正常运行
(2)不停乱按
执行过程中不断乱按,会把按的内容显示在屏幕上,最后依然要由getchar()函数接受到键盘输入的一个回车后结束执行。
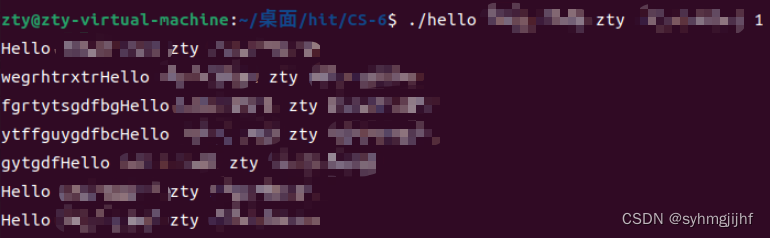
图6.6.6不断乱按
(3)输入回车
在程序执行过程中按入四个回车,它们被保存在缓冲区中,最后程序结束时,最后一个回车被getchar()读走,结束程序,还有两个回车会输出出来,如图6.6.7所示,程序结束后,会有三个换行输出。
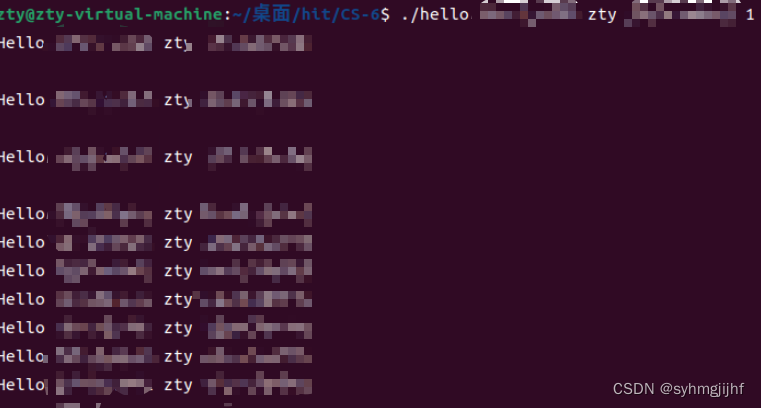
图6.6.7键入四个回车
(4)按下Ctrl-C
在执行过程中如果按下Ctrl-C会立即停止程序的执行。因为这个键盘输入会导致发送SIGINT信号给hello,该信号要求hello立刻终止该进程,如图6.6.8所示。

图6.6.8按下Ctrl-C结束进程
(5)按下Ctrl-Z及相关操作
程序在运行过程中按下Ctrl-Z会产生中断异常,发送SIGSTP信号,暂时挂起hello进程并打印相关信息。如图6.6.9所示。

图6.6.9暂时挂起进程
且挂起后还可以执行若干命令,如输入ps,将打印各进程的PID,如图6.6.10所示;

图6.6.10打印各进程PID
输入jobs将打印出被挂起的hello的相关信息,如图6.6.11所示;

图6.6.11打印hello的相关信息
输入pstree指令将打印进程树,如图6.6.12所示;
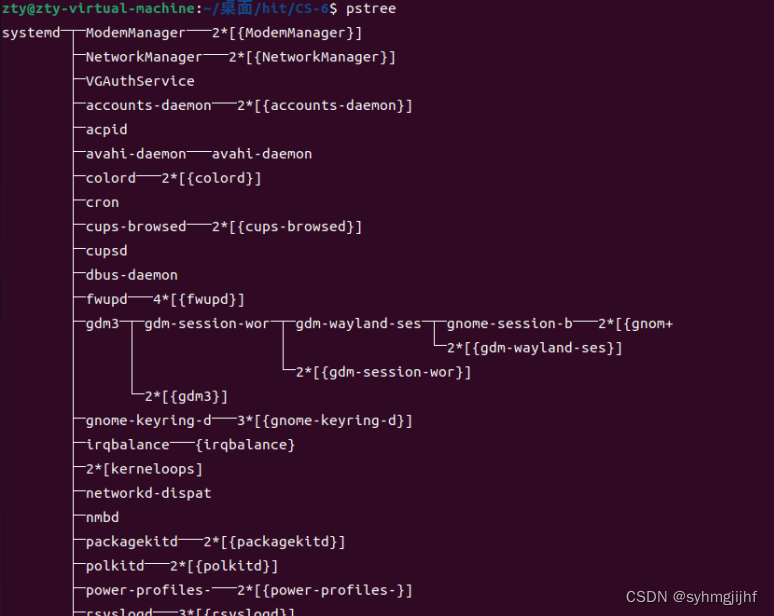
图6.6.12打印进程树
输入fg会让其继续执行,如图6.6.13所示;
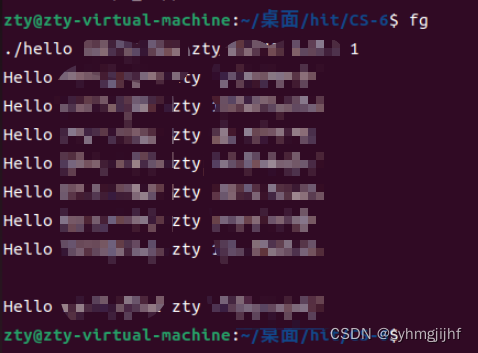
图6.6.13继续执行进程
输入kill将发送SIGINT信号,杀死进程,如图6.6.14所示。

图6.6.14杀死进程
再次用ps查看,发现hello已经被终止.hello进程被杀死了。
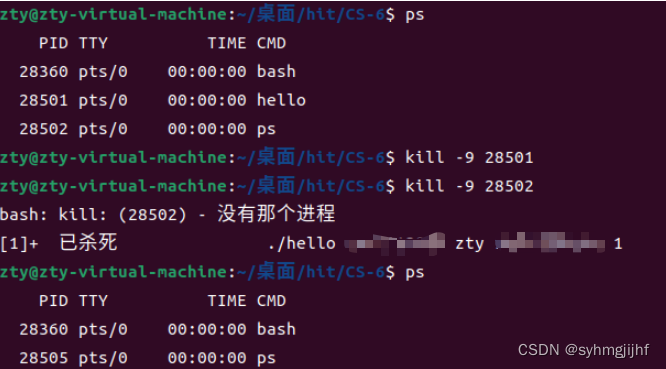
图6.6.15查看杀死进程
6.7本章小结
本章介绍了进程的概念以及作用,详细分析了shell,fork,execve以及进程的调度和上下文的切换。最后分析了异常的种类,并且用具体的命令分析了不同情况下信号的处理。
第7章 hello的存储管理
7.1 hello的存储器地址空间
2、线性地址:逻辑地址向物理地址转换时的中间环节,hello中的偏移地址加上相应段的基地址就是线性地址。
3、虚拟地址:就是线性地址
4、物理地址:实际出现在CPU外部地址总线上的地址信号,表示实的物理内存所对应的地址。
7.2 Intel逻辑地址到线性地址的变换-段式管理
一个逻辑地址由两部分组成,段标识符,段内偏移量。段标识符是一个16位长的字段组成,称为段选择符,其中前13位是一个索引号。可以通过段标识符的前13位,直接在段描述符表中找到一个具体的段描述符,这个描述符就描述了一个段。
转换的具体过程:首先,给定一个完整的逻辑地址,它的格式如下:[段选择符:段内偏移地址]然后,看段选择符的T1=0还是1,知道当前要转换是全局段描述符表(存储全局的段描述符),还是局部段描述符表(存储进程自己的段描述符),再根据相应寄存器,得到其地址和大小,得到一个数组。最后,拿出段选择符中前13位,查找到对应的段描述符,进而找到基地址,base+offset得到线性地址。
7.3 Hello的线性地址到物理地址的变换-页式管理
线性地址到物理地址的变换由页式管理实现,它通过分页机制对虚拟内存空间进行分页,然后把页式虚拟地址与物理内存地址建立一一对应页表,并用相应的硬件地址变换机构(MMU)来解决离散地址变换问题。页式管理采用请求调页或预调页技术实现了内外存存储器的统一管理。页表是一个由页表项(PTE)组成的数组,存储在内存中,将虚拟页地址映射到物理页地址。
如下图所示,一个虚拟地址(VA)包含两个部分:虚拟页号(VPN)和虚拟页偏移量(VPO),其中VPO和PPO(物理页偏移量)是相同的。MMU利用VPN选择适当的PTE,如果PTE的有效位为1,也即PTE命中,则直接将PTE中存储的物理页号(PPN)和虚拟地址中的虚拟页偏移量(VPO)串联起来就得到一个相应的物理地址。如果页表项(PTE)不命中,则会触发缺页故障,调用缺页处理子程序进行相应处理。
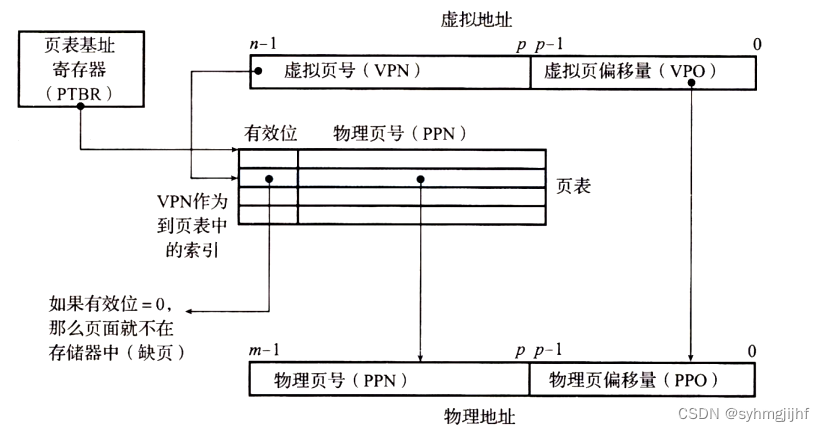
图7.3.1使用页表的地址翻译
7.4 TLB与四级页表支持下的VA到PA的变换
首先在TLB中查找PTE,若能直接找到则直接得到对应的PPN,具体的操作是将VPN看作TLBI和TLBT,前者是组号,后者是标记,根据TLBI去对应的组找,如果TLBT能够对应的话,则能够直接得到PTE,进而得到PPN。
其中若是在TLB中找不到对应的条目,则应去多级页表中查找,VPN被分为了四块。有一个叫做CR3的寄存器包含L1页表的物理地址,VPN1提供到了一个L1
PET的偏移量,这个PTE包含L2页表的基地址,VPN2提供到一个L2
PTE的偏移量。依次类推,最终找到页表中的PTE,得到PPN。
而VPO和PPO相等,最终的PA等于PPN+PPO。
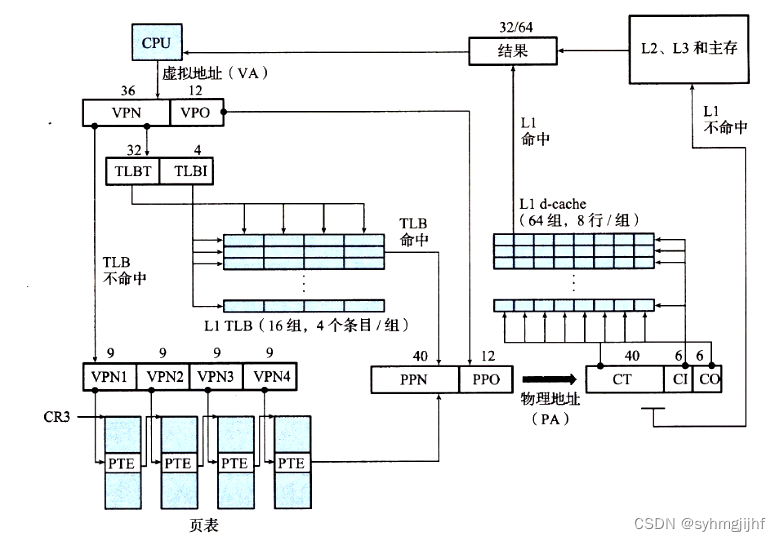
图7.4.1 TLB与四级页表支持下的地址翻译
7.5 三级Cache支持下的物理内存访问
对于一个虚拟地址请求,首先将去TLB寻找,看是否已经在TLB中缓存。如果命中的话就直接MMU获取,没有命中的话就先在结合多级页表,得到物理地址,去cache中找,到了L1里面以后,寻找物理地址又要检测是否命中,不命中则紧接着寻找下一级cache L2,接着L3。这里就是使用到CPU的高速缓存机制了,逐级向下找,直到找到对应的内容。
7.6 hello进程fork时的内存映射
当fork函数被当前进程调用时,操作系统内核为新进程创建各种数据结构,并分配给它一个唯一的 PID,然后通过以下步骤为其创建虚拟内存:
①创建当前进程的的mm_struct、区域结构和页表的原样副本;
②将两个进程中的每个页面都标记为只读;
③将两个进程中的每个区域结构都标记为私有的写时复制;
当fork在新进程中返回时,新进程现在的虚拟内存刚好和调用fork时存在的虚拟内存相同。当这两个进程中的任一个在后面进行写操作时,写时复制机制就会创建新页面,因此,也就为每个进程保持了私有地址空间的抽象概念。
7.7 hello进程execve时的内存映射
execve 函数的函数声明为int execve(char *filename ,char *argv[], char *envp[]);加载hello并执行需要以下几个步骤:
(1)删除已存在的用户区域。删除当前进程虚拟地址的用户部分中的已存在的区域结构。
(2)映射私有区域。为新程序的代码、数据、bss和栈区域创建新的区域结构。所有这些新的区域都是私有的、写时复制的。
(3)映射共享区域。如果filename程序与共享对象(或目标)链接,那么这些对象是动态链接到这个程序的,然后映射到用户虚拟地址空间中的共享区域内。
(4)设置程序计数器(PC)。execve做的最后一件事情就是设置当前进程上下文中的程序计数器,使之指向代码区域的入口点。
当再次调度这个进程时,它将从入口点开始执行。Linux将根据需要换入代码和数据页面。
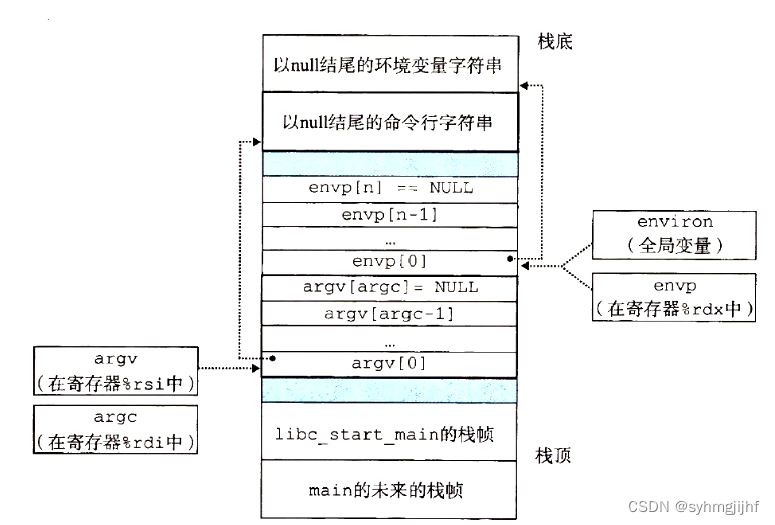
图7.7.1 用户栈典型组织结构
7.8 缺页故障与缺页中断处理
当发生缺页中断时,系统的处理流程如下图所示:
①处理器将虚拟地址发送给MMU;
②MMU生成PTE地址(PTEA),并从高速缓存/主存请求得到它;
③高速缓存/主存向MMU返回PTE;
④PTE有效位为0, MMU触发缺页异常,传递CPU中的控制到操作系统内核的缺页异常处理程序;
⑤缺页处理程序确定出物理内存中的牺牲页 ,若页面被修改,则把它写回到磁盘中。
⑥缺页处理程序调入新的页面,并更新内存中的PTE;
⑦缺页处理程序返回到原进程,再次执行导致缺页的指令,CPU将VA重新送给MMU并执行相应访问操作,此时将不会再出现缺页的情况。
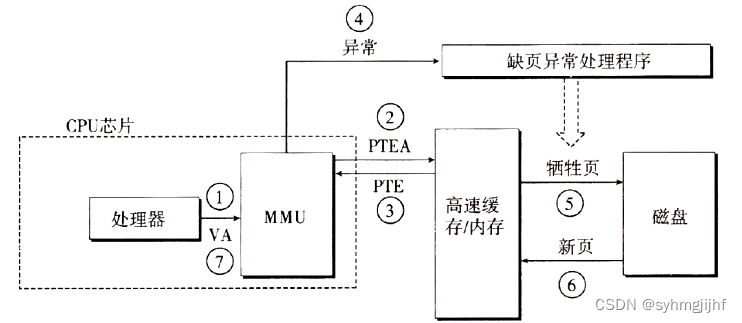
图7.8.1 缺页操作
7.9动态存储分配管理
动态内存分配是指在程序运行时程序员使用动态内存分配器(如malloc)获得虚拟内存。动态内存分配器维护着一个进程的虚拟内存区域,称为堆。堆被分配器视为一组不同大小的块的集合,每个块仅会是以下两种状态之一;“已分配”和“空闲”。已分配的块显式保留为应用程序使用;空闲块保持空闲只到被分配使用。
分配器有两种方式:显式分配器和隐式分配器。显式分配器要求应用显式地释放任何已分配的快,如C语言中的malloc和free的组合对内存进行分配与释放;隐式分配器要求分配器自动完成上述任务。
常用的分配器有显式链表和隐式链表。前者的特点是堆中的空闲块通过头部中的大小字段隐含地连接;后者则是在在每个空闲块中,都包含一个前驱(pred)与后继(succ)指针,从而减少了搜索与适配的时间。
7.10本章小结
本章介绍了储存器的地址空间,讲述了虚拟地址、物理地址、线性地址、逻辑地址的概念,还有进程fork和execve时的内存映射的内容。描述了系统如何应对缺页异常。
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
设备的模型化:所有IO设备都被模型化为文件,所有的输入输出均可作为文件的读写来执行。
设备管理:Linux内核有一个简单、低级的接口,称为Unix I/O,使得所有的输入输出都能以统一方式来执行。
8.2 简述Unix IO接口及其函数
- Unix IO接口:Unix IO接口提供了打开、关闭、读取和写入文件的功能。通过打开文件,操作系统内核会返回一个文件描述符,应用程序可以使用这个文件描述符来操作文件。应用程序可以使用seek操作来改变文件的当前位置,从而可以在文件中进行定位读写操作。读取和写入文件时,操作系统会在文件和应用程序之间进行信息传输。当应用程序不再需要访问文件时,可以通知内核关闭文件,从而释放文件占用的资源。
- Unix IO函数:
- open()函数:打开文件
- lseek()函数:将文件指针定位到相应位置
- read()函数 读文件
- write()函数:写文件
- close()函数:关闭文件
8.3 printf的实现分析
当我们调用vsprintf函数对需要输出的字符串进行格式化并存放在缓冲区中后,系统函数write会被调用以在屏幕上打印缓冲区中的前i个字符,即输出我们要显示的字符串。调用write系统函数后,程序将进入内核态,并通过系统调用 int 0x80或syscall等方式,字符驱动子程序会被执行,将我们的字符串内容按照ASCII码转换为字模库,然后写入显示vram中以存储每个点的RGB颜色信息。
显示芯片会按照刷新频率逐行读取vram中的内容,并通过信号线传输RGB分量信息到液晶显示器,从而显示出要显示的字符串内容。最后程序将返回实际输出的字符数量i。整个过程实现了将格式化后的字符串内容显示在屏幕上的功能。
8.4 getchar的实现分析
在异步异常-键盘中断的处理过程中,当用户按下键盘时,键盘接口会接收到代表该按键的键盘扫描码,并产生中断请求,系统会调用键盘中断处理子程序。该处理子程序首先从键盘接口获取按键的扫描码,然后将扫描码转换成对应的ASCII码,并将ASCII码保存到系统的键盘缓冲区中。
当应用程序中调用getchar函数时,实际上会调用系统函数read来读取键盘缓冲区中的ASCII码,直到读取到回车符为止,然后将读取到的ASCII码组成的字串作为getchar函数的返回值返回给应用程序。这个过程可以实现从键盘输入字符并将其返回给应用程序的功能。整个过程是异步的,即用户按下键盘引发的中断请求会被及时处理并将按键信息传递给应用程序。
8.5本章小结
本章阐述了系统级IO,介绍了IO设备的管理方法,UnixIO接口及其函数,最后简要分析了printf函数和getchar函数的实现过程。
结论
Hello的一生:
- 源程序编写:Hello诞在文本编辑器或IDE中编写C语言代码,生成了最初的hello.c源程序。Hello在这里被赋予了它最初的存在
- 预处理:Hello进入预处理阶段,预处理器解析宏定义、文件包含和条件编译等指令,生成一个ASCII码的中间文件hello.i。
- 编译:Hello通过编译器进行编译,将C语言代码转换为汇编指令,生成一个ASCII汇编语言文件hello.s。
- 汇编:汇编器将汇编指令翻译成机器语言,并生成重定位信息,生成可重定位目标文件hello.o。
- 链接:链接器进行符号解析、重定位和动态链接等操作,将可重定位目标文件hello.o与其他目标文件链接在一起,生成一个可执行目标文件hello。现在,Hello终于可以真正地被执行了。
- 在shell输入./hello 2022112042 zty 12345678910 1 调用命令行解释功能
- 创建进程:用fork函数为hello创建子进程。
- 运行阶段:通过shell命令运行hello程序时,shell调用fork函数创建子进程,为hello程序提供执行环境。子进程中通过execve函数加载hello程序,进入hello的程序入口点,hello开始运行。
- 执行指令:CPU为hello分配时间片,执行控制逻辑流。
- 内存管理和协作:在运行阶段,操作系统的内核负责调度进程,并对可能产生的异常和信号进行处理。硬件组件如MMU、TLB、多级页表、cache和DRAM内存等与操作系统协作,共同完成内存的管理。
- 动态申请内存:hello运行过程中printf中调用malloc动态的申请堆中的内存空间
- I/O交互:Hello程序可以利用操作系统提供的Unix I/O功能与文件进行交互。
- 信号与异常:hello运行过程中可能会产生各种异常信号,系统会做出相应处理。
- 终止:Hello进程运行结束后,由shell负责回收终止的hello进程,操作系统内核删除为hello进程创建的所有数据结构。Hello短暂又灿烂一生在这里结束。
感悟:
计算机系统的设计与实现也需要硬件、操作系统和软件等多个方面的配合,才能更好地完成各种任务。
在Hello的传奇一生中,我们可以看到硬件提供了支持和基础,操作系统为软件提供了运行环境和资源管理,软件则实现了具体的功能和应用。这种分工合作的模式不仅可以提高系统的效率和稳定性,也能更好地满足用户的需求。
因此,在设计和实现计算机系统时,我们需要综合考虑硬件、操作系统和软件等方面的因素,确保它们能够协同工作,达到预期的功能和性能。只有这样,才能打造出更加强大和可靠的计算机系统,服务于人类的各种需求和创新。
附件
hello.c:C语言源程序文件
hello.i:预处理后生成的文件
hello.s:编译产生的汇编程序文件
hello.o:汇编产生的可重定位目标文件
hello:链接产生的可执行文件
elf.txt:hello.o的elf格式文件
elf1.txt:hello的elf格式文件
asm.txt:hello.o反汇编的结果文件
asm1.txt:hello反汇编的结果文件
参考文献
[1] Pianistx.printf 函数实现的深入剖析[EB/OL].2013[2021-6-9].
https://www.cnblogs.com/pianist/p/3315801.html.
[2] Randal E.Bryant, David O'Hallaron. 深入理解计算机系统[M]. 机械工业出版社.2018.4















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









