










写任何有关pandas的代码前,我们应该先导入pandas
import pandas as pd我们下面出现全部的pd都代表对pandas的引用
一、简单的DataFrame对象
DataFrame是一种矩阵数据表,可以看成由多个拥有相同索引的Series。如果有过关系型数据库基础的朋友会很熟悉这种表结构,甚至我们可以想象下Execl表,也有异曲同工之妙。
对象名 = pd.DataFrame( 值 )
import pandas as pd
data = {'地区':['北京','北京','上海','上海','广州','广州'],
'年份':[2018,2019,2018,2019,2018,2019],
'人口':[3000,3100,2400,2500,1400,1500]}
df = pd.DataFrame(data)
DataFrame同样也会自动分配索引。列也会进行一定的自动排序,但对于一些数据量很大的DataFrame,一次全显示出来会对系统造成一定负担。我们可以仅显示其中的前几行。
DataFrame对象.head( 需要显示的行数 )
df.head(2) 
如果需要改变列的显示顺序或者定义索引名。可以如下方法。
pd.DataFrame( 数据 ,columns=[ 列名 ],index=[ 索引名 ] )
df1=pd.DataFrame(data,columns=['地区','年份','人口'],
index=['A01','A02','B01','B02','C01','C02'])
二、DataFrame对象检索和选取数据
DataFrame中选取一列数据,我们会获得一条Series结构的值,索引与DataFrame有相同的名称。在获取数据上有两种方法都可以,甚至后面的一种方法因为能<tab>补全,更常用一些,但是有一定局限,不能是已有的方法名。比如abs什么的。
DataFrame对象[ 列名 ] 或者 DataFrame对象.列名

DataFrame中纵向列数据我们已经可以获取了,那么横向行用如下方法也可以获得。
DataFrame对象.loc[ 索引名/行名 ]
df1.loc['A01']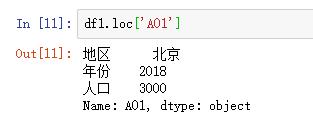
三、DataFrame对象数据操作
新建列
DataFrame中添加一列数据,我们对此列不全部赋值,因此此列显示的某些行是空值。规则是如果列存在,则改变列的值,如果列不存在,则新建一列并赋值。
DataFrame对象[ 新建索引名/行名 ] = 新列值
data = {'地区':['北京','北京','上海','上海','广州','广州'],
'年份':[2018,2019,2018,2019,2018,2019],
'人口':[3000,3100,2400,2500,1400,1500]}
df2=pd.DataFrame(data,columns=['地区','年份','人口'])
se=pd.Series([30320,32679,23000],index=[0,2,4])
df2['GDP']=se
新建列还可以使用算式添加
df2['无数据']=pd.isnull(df2.GDP)
删除列
DataFrame中删除一列
del DataFrame对象[ 列名 ]
del df2['无数据']
改变某一项数值
DataFrame对象.loc[ 索引名/行名 ,列名 ] = 值
df2.loc[1,'GDP']=33333
还可以进行转置操作,也就是常说的行列转换。
DataFrame对象.T
df2.T














 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









