







常见的线性模型有两种:线性回归和逻辑回归。
- 线性回归常用语分析变量之间的关系,并试图通过从给定的数据中学习到的信息模型来预测以后的值。一般而言,它预测的结果一般是一个连续值。
- 逻辑回归:也称为对数概率回归,用于判断输入值和比较对象的“是”与“否”关系,逻辑回归本质上而言是一种“分类”算法。
一元线性回归
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
'''
1. 生成训练数据:y = x*5 + 6
'''
t_x = np.linspace(-1,1,50,dtype=np.float32)
noise = np.random.normal(0,0.05,t_x.shape)
t_y = t_x * 5.0 + 6.0 +noise
plt.plot(t_x,t_y,'b.')
plt.show()
'''
2. 定义训练模型
'''
x = tf.placeholder(dtype=np.float32,shape=t_x.shape)
y = tf.placeholder(dtype=np.float32,shape=t_y.shape)
a = tf.Variable(0.0)
b = tf.Variable(0.0)
curr_y = a*x+b
#最小均方误差
loss = tf.reduce_sum(tf.square(curr_y-y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train = optimizer.minimize(loss)
'''
3. 进行数据训练
'''
learning_rate = 0.001
train_epochs = 1000
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(train_epochs):
sess.run(train,feed_dict={x:t_x,y:t_y})
if(i % 20 ==0):
print(sess.run([a,b],feed_dict={x:t_x,y:t_y}))
a_val = sess.run(a)
b_val = sess.run(b)
print("this model is y =",a_val,"*x+",b_val)
sess.close()
y_learn = t_x * a_val + b_val
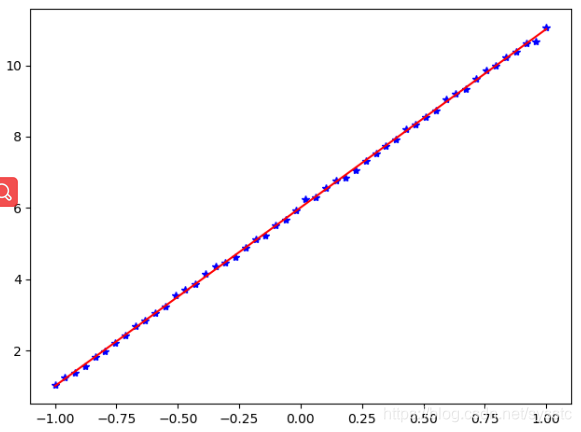
plt.plot(t_x,t_y,'b*')
plt.plot(t_x,y_learn,'r-')
plt.show()
plt.close()
图形输出:
多元线性回归
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
'''
1. 生成训练数据:y = 2*x_1+3*x_2+5
'''
learning_rate = 0.001
train_epochs = 1000
x_data = np.float32(np.random.rand(2,100)) #随机生成2*100的矩阵
y_data = np.dot(np.float32([[2.,3.]]),x_data) + 5
# 绘图
'''
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
ax.scatter(x_data[:99][0],x_data[:99][1],y_data[:99],c='r')
plt.show()
plt.close()
'''
'''
2. 生成训练模型
'''
x = tf.placeholder(dtype=tf.float32,shape=([2,None]),name='x')
y = tf.placeholder(dtype=tf.float32,shape=([None,None]),name='y')
W = tf.Variable(tf.random_uniform([1,2],-1,1))
b = tf.Variable(tf.zeros([1]))
y_curr = tf.matmul(W,x) + b
loss = tf.reduce_sum(tf.square(y_curr-y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
'''
3. 进行数据训练
'''
sess = tf.Session()
sess.run(init)
for i in range(train_epochs):
sess.run(train,{x:x_data,y:y_data})
if(i%20==0):
print(sess.run([loss,W,b],feed_dict={x:x_data,y:y_data}))
W_val = sess.run(W)
b_val = sess.run(b)
sess.close()
print(W_val[0][0],W_val[0][1],b_val)
输出:
[2890.0742, array([[ 1.5106376 , -0.01605856]], dtype=float32), array([1.5530673], dtype=float32)]
...
[1.940407e-09, array([[2.000014 , 3.0000048]], dtype=float32), array([4.999989], dtype=float32)]
2.000014 3.0000048 [4.999989]
逻辑回归
通过极大似然法求逻辑回归中预测结果和真实结果的切合程度,损失函数为:
l
o
s
s
=
−
∑
i
=
1
m
(
y
i
∗
l
o
g
(
y
p
r
e
d
)
+
(
1
−
y
i
)
l
o
g
(
1
−
y
p
r
e
d
)
loss = -\sum_{i=1}^m(y_i*log(y_{pred})+(1-y_i)log(1-y_{pred})
loss=−i=1∑m(yi∗log(ypred)+(1−yi)log(1−ypred)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
'''
生成训练数据
假设x1*2+x2>2为一个类,而x1*x2+x2<=2为另外一个类
'''
# 声明数据数组和标签
data = []
target = []
for i in range(150):
x1 = np.random.uniform(-1,1)
x2 = np.random.uniform(0,2)
if(x1*2+x2<=2):
data.append([np.random.normal(x1,0.1),np.random.normal(x2,0.1)])
target.append(0)
plt.plot(data[i][0],data[i][1],'go')
else:
data.append([np.random.normal(x1,0.1),np.random.normal(x2,0.1)])
target.append(1)
plt.plot(data[i][0],data[i][1],'r*')
data = np.array(data).reshape(-1,2)
target = np.array(target).reshape(-1,1)
'''
定义训练模型
'''
x = tf.placeholder(tf.float32,shape=(None,2))
y = tf.placeholder(tf.float32,shape=(None,1))
W = tf.Variable(tf.zeros(shape=(2,1)))
b = tf.Variable(tf.zeros([1]))
#逻辑回归模型
curr_y = tf.sigmoid(tf.matmul(x,W)+b)
#计算损失值
sample_size = len(data)
cross_entropy = -tf.reduce_sum(y*tf.log(curr_y)+(1-y)*tf.log(1-curr_y))/sample_size
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train = optimizer.minimize(cross_entropy)
'''
进行训练
'''
cost_prev = 0
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(40001):
sess.run(train,feed_dict={x:data,y:target})
train_cost = sess.run(cross_entropy, feed_dict={x: data, y:target})
if (abs(cost_prev - train_cost)) < 1e-6:
break
cost_prev = train_cost
if(i%2000==0):
print(i,sess.run([W,b,cross_entropy],feed_dict={x:data,y:target}))
W_val = sess.run(W)
b_val = sess.run(b)
sess.close()
w1 = W_val[0,0]
w2 = W_val[1,0]
k = -w1/w2
b = -b_val/w2
print(w1,w2,k,b)
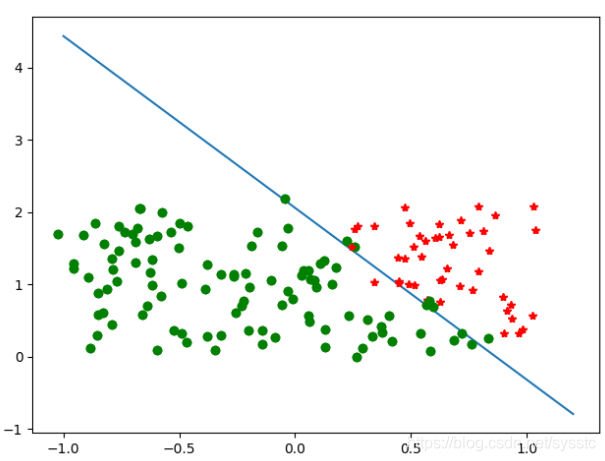
xx = np.linspace(-1,1.2,100)
yy = k*xx + b
plt.plot(xx,yy)
for i in range(150):
if(target[i]==0):
plt.plot(data[i][0],data[i][1],'go')
else:
plt.plot(data[i][0],data[i][1],'r*')
plt.show()
输出:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









