







参考:目标检测算法之SSD
概述
目前目标检测算法的主流算法主要分为两类:
- two-stage方法。比如R-CNN系算法。主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类和回归。two-stage方法的优点是准确度高。
- one-stage方法。比如yolo和SSD。主要思路是均匀的在图片的不同位置上密集抽样,抽样时可以采用不同的比例和长宽比,然后用CNN提取特征后直接分类与回归,整个过程只需要一步,所以优点是速度快。但是均匀的密集采样的缺点是训练困难,主要是因为正样本与负样本(背景)及其不均衡,导致模型准确度较低。
下图是不同算法的基本框架图:

解释
- Fast R-CNN首先通过CNN得到候选框,然后再分类与回归。
- yolo和SSD可以一步到位完成检测。
- SSD相比较yolo的三个不同点:
(1)SSD采用CNN直接检测,而不是像yolo一样在全连接层后面做检测。
(2)SSD提取不同尺寸的特征图做检测。大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。
(3)SSD采用不同尺度和长宽比的先验框(prior box/default box,这个概念在Fast R-CNN中叫做锚,anchors) - yolo算法的缺点是难以检测小目标,且定位不准,上面提到的SSD相较于yolo改进的三点使得SSD克服了yolo的缺点。
SSD算法
Single shot MultiBox Detector即SSD。single shot说明SSD是one-stage方法。MultiBox说明SSD是多框预测。SSD算法普遍在准确度和速度上都优于yolo。
设计理念
SSD和yolo都是采用一个CNN来检测,但是SSD采用多尺度的特征图。设计理念总结为三点。
- 设计理念一——采用多尺度特征图用于检测。
采用多尺度也就是采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用strid=2的卷积或者是pool来降低特征图大小。如下面的基本架构图所示,前面是大的特征图,后面是小的特征图。这两个不同尺度的特征图都用来做检测。目的是为了:大的特征图用来检测小目标,小特征图用来检测大目标。

下图表示不同尺寸的特征图。

8*8的特征图是大的特征图,可以划分更多的单元,但是其每个单元的先验框尺度都比较小。所以大尺度的特征图用来检测小目标。而4*4的特征图是小的特征图,但是其每个单元的先验框尺度都比较大。所以小尺度的特征图用来检测大目标。 - 设计理念二——采用卷积检测
与yolo最后采用全连接层不同,SSD直接用卷积对不同的特征图提取检测结果。 - 设计理念三——设置先验框
yolo中,每个单元预测多个边界框,其都是相对这个单元本身(正方块)。但是真实目标的形状是多变的,所以yolo在训练过程中需要自适应目标的形状。
SSD借鉴Fast R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding box)是以这些先验框为基准,一定程度上减少训练难度。每个单元会设置多个先验框,其尺度和长宽比存在差异,如下图所示,下图中每个单元采用了四个先验框,真实图片中的猫和狗都分别选择最适合它们形状的先验框训练。
SSD的检测值也和yolo不太一样,对于每个单元的每个先验框,都输出一套独立的检测值,对应一个边界框,主要分为两个部分:
(1)第一部分是各个类别的置信度或者评分,要注意的是SSD将背景也当成了一个特殊的类别。如果检测目标共有C个类别,SSD需要预测C+1个置信度值,其中第一个置信度就是指的不含目标或者说是属于背景的评分。所以要注意的是:当说C个类别置信度时,里面包含了背景这个特殊类别,真实类别是C-1个。预测时,置信度最高的那个类别就是边界框所属的类别。当第一个置信度值最高时,表示边界框中不含有目标即是属于背景。
(2)第二部分就是边界框的location。包含4个值(cx,cy,w,h),分别表示边界框的中心坐标和宽高。
真实预测值是边界框相对于先验框的转换值。
先验框位置如下:
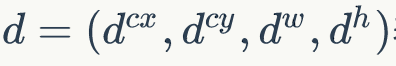
对应的边界框位置如下:
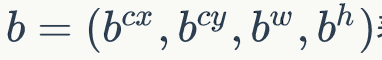
边界框的预测值l就是b相对于d的转换值,即边界框位置相对于先验框位置的转换值。计算式子如下:

在预测时,需要反向上面的这个过程,从预测值l中得到边界框的真实位置b。计算式子如下:

综上,对于一个大小为mn的特征图,共有mn个单元,每个单元设置的先验框数目记为k,那么每个单元需要(c+4)k个预测值。(解释:c是表示c个类别,包括了特殊的背景类别。4表示的是4个位置参数即中心坐标和宽和高,共4个值。)故特征图所有单元共需要mn*(c+4)*k个预测值。
SSD采用卷积做检测,需要(c+4)*k个卷积核完成这个特征图的检测。
SSD的基本架构图

SSD的网络结构
SSD采用VGG16作为基础模型,在VGG16的基础上新增卷积层以获得更多的特征图以用于检测。
SSD和yolo的网络结构图如下

SSD网络结构采用一种Atrous Algorithm,就是conv6采用扩展卷积或者是带孔卷积,其在不增加参数和模型复杂度的条件下指数级扩大卷积的视野。如下图所示:第一张图是普通的33卷积,视野就是33。第二张图扩张率为2,视野变为77。第三张图扩张率为4时,视野扩大为1515,但是视野的特征更稀疏了。
VGG16的conv4_3层作为检测的第一个特征图,conv4_3层特征图大小是38*38。但是该层较靠前,norm较大,所以在其后增加了一个L2 normalization层,以保证和后面的检测层差异不是很大。这个和batch normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化。而bacth normalization层是在[batch_size width height]三个维度上做归一化。
下图表示基于卷积得到检测结果:

训练过程
第一步 先验框匹配
训练过程中首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。yolo中ground truth的中心落在哪个单元格,该单元格与其IOU最大的边界框负责预测它。
SSD不一样,SSD先验框与ground truth的匹配原则有两点:
- 对于图片中的每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样可保证每个ground truth一定与某个先验框匹配,与ground truth相匹配的先验框为正样本。若一个先验框没有与任何一个ground truth相匹配则说明该先验框只能与背景相匹配,就是负样本。
一个图片中ground truth是很少的,而先验框却很多,如果仅仅按照上面第一个原则进行匹配,那么很多先验框会是负样本,正负样本是及其不平衡的。所以需要第二个原则。 - 对于剩下的未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth匹配。
SSD匹配示意图如下

上图中绿色的GT是ground truth。红色为先验框,FP表示负样本,TP表示正样本。
数据扩增
data augmentation数据扩增可以提升SSD性能。采用的技术有:水平翻转horizontal flip、随机裁剪加颜色扭曲random crop / color distortion、随机采集块域randomly sample a patch(获取小目标训练样本)。如下图所示:

SSD预测过程
- 对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)及其置信度值,并过滤掉属于背景的预测框.
- 根据置信度阈值(如0.5)过滤掉阈值较低的预测框。
- 对于留下的预测框进行解码,根据先验框得到真实的位置参数(解码后一般要做clip,防止预测框位置超出图片)
- 解码之后,根据置信度降序排列,然后仅仅保留top-k个预测框。
- 最后进行NMS算法,过滤掉那些重合度较大的预测框。
- 最后剩余的预测框是检测结果。
小结论
- 数据扩增对于mAP的提升很大。
- 使用不同长宽比的先验框可以得到更好的结果。
- 采用多尺度的特征图用于检测很重要。















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









