







题目
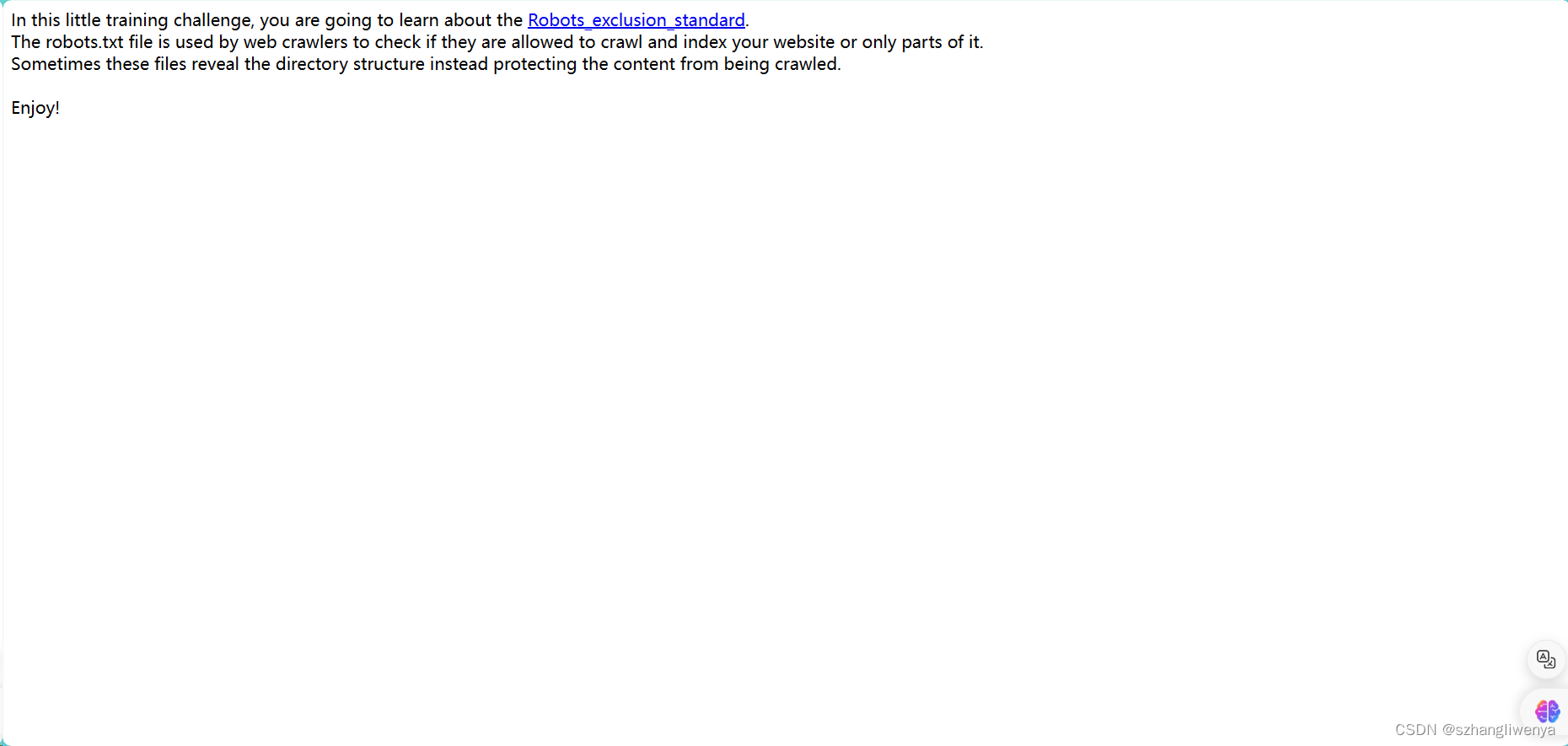
In this little training challenge, you are going to learn about the Robots_exclusion_standard.
The robots.txt file is used by web crawlers to check if they are allowed to crawl and index your website or only parts of it.
Sometimes these files reveal the directory structure instead protecting the content from being crawled.
Enjoy! 在这个小的训练挑战中,您将学习机器人排除标准。
robots.txt文件被网络爬虫用来检查他们是否被允许对您的网站或仅对其部分进行爬网和索引。
有时,这些文件会显示目录结构,而不是保护内容不被爬网。
享受
没什么好说的直接访问robots.txt
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。 要注意的是,robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
robots.txt是一种文本文件,用于告知搜索引擎爬虫哪些页面可以被抓取、哪些页面不应被抓取。通常,网站管理员会在网站的根目录下放置一个名为robots.txt的文件,并使用该文件指定他们希望搜索引擎索引和不索引的页面。

提示fl0g.php
访问
















 3335
3335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









