







 超级会员免费看
超级会员免费看
分布式dataX CDC有两种可选方式,分布式作业和分布式时间槽
分布式作业在《分布式dataX详细(落地)设计》介绍过,dataX CDC单分片,使用分布式作业,只有一个worker作业工作,其他worker作业备用状态,资源利用率不高,因此,分布式时间槽比较合适
参考
《分布式dataX详细(落地)设计》
《Datax CDC 可靠channel》
《CDC增量同步框架与关系/neo4j增量同步设计》
《分布式时间槽elastic timeslot架构设计》
技术架构
下面介绍分布式dataX CDC的技术架构,下图是分布式datax CDC和分布式datax技术架构对比, 前者使用分布式时间槽,后者分布式作业,通过对比更好了解分布式dataX CDC
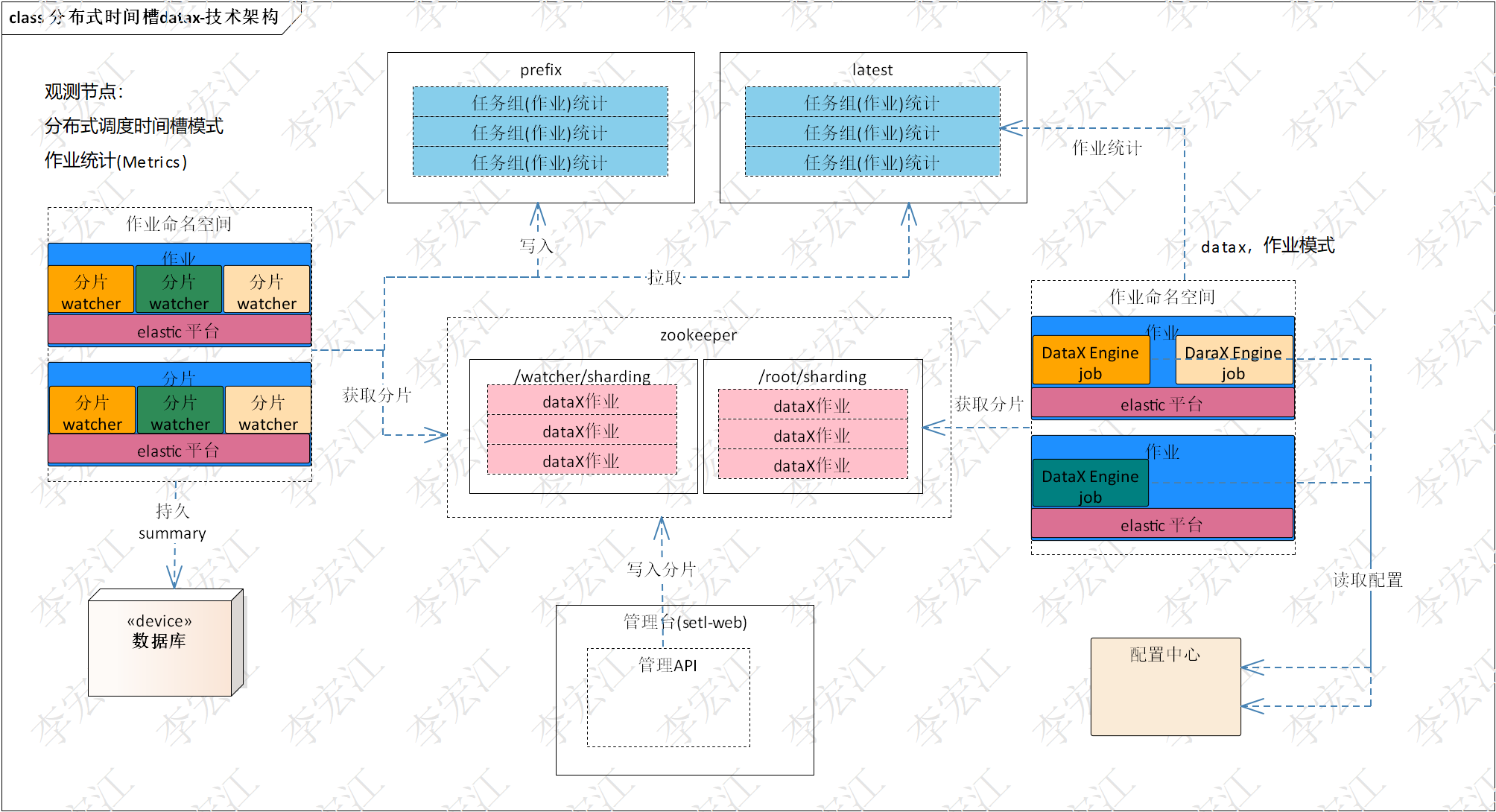
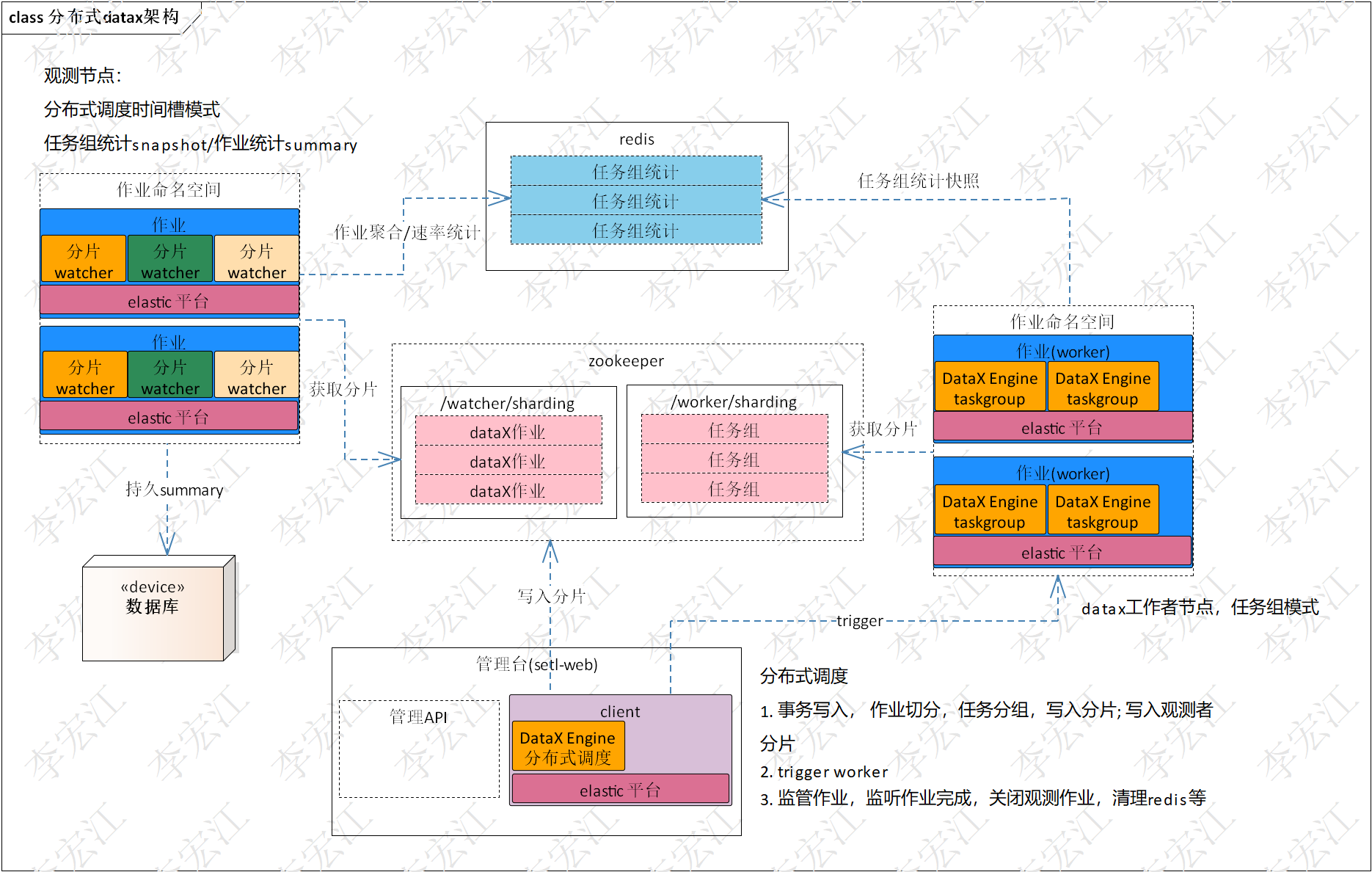
上为分布式dataX CDC, 使用分布式时间槽模式;下为分布式dataX,使用分布式作业模式
1. 作业节点
dataX CDC:作业分片对应dataX作业,是standalone模式的datax engine
dataX:作业(worker)节点分片是dataX作业分片,是任务组模式的datax engine
2. Client
dataX CDC:管理台api写入分片,没有专用client
dataX:专用的client,作业模式下Datax Engine,使用分布式调度器,负责分片和分配分片
3. 配置中心
dataX CDC:配置放入配置中心,避免每个节点存放,影响动态伸缩和维护,当然也支持本地配置文件,每个worker节点配置所有的dataX CDC作业,用于failover
dataX:作业配置直接写入分片的config节点,其他配置也可使用配置中心
4. 作业/任务租统计
dataX CDC:cdc作业单分片,任务组的统计也是作业统计,因此不需要聚合为作业统计,直接拉取复制到prefix,latest/prefix按设定的时间段计算速率;cdc没有最终summary,持久多个summary,设定保存时限自动删除
dataX:设计比较复杂,参考《分布式datax详细(落地)设计》
5. 分片策略
dataX CDC:eager模式,一次分配完分片,尽可能早地执行所有分片,达成用户触发时间要求
dataX:on demand模式,按需分配工作量,获得更小的总体执行时间
6. 故障转移
两者故障转移机制一致,节点下线,其他节点接替分片,不同的有两点,
6.1 CDC处理事件流,事件流经channel,需要可靠channel,节点切换后继续执行未ack的channel内的事件,作业整个分片重新处理;
6.2 cdc持续运行,需要保证一定的空闲节点数,需监控告警空闲节点数
动态分片新增和撤销
分布式时间槽支持cancel分片,设置cancel标志,待下次重启删除cancel分片,但cdc一直运行,该功能不能生效,因此目前未有动态分片新增和撤销
znode结构
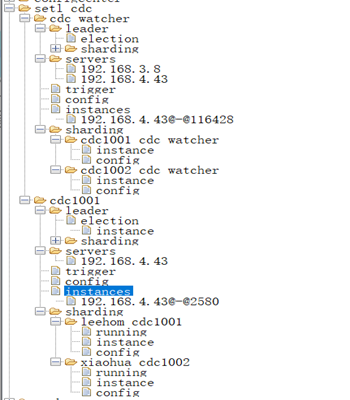
setl_cdc 根节点,可以看成一个用户域,用户定义
cdc_watcher 观测节点,一个域只需一个观测者,其分片与域内所有作业的所有分片一一对应,用户定义
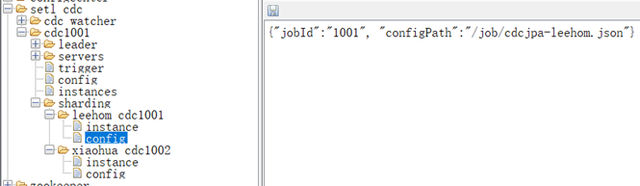
cdc1001 逻辑作业,其分片是datax CDC作业,job模式的datax Engine,这里有两个作业概念,分布式作业和dataX作业,域内可有多个作业,每个不同作业类型,上图两个分片对应两个dataX CDC作业,分片名称 userId+作业名称;
作业/分片的配置
观测分片配置是任务组统计的reids key前缀
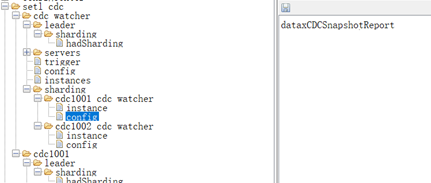
dataX CDC作业配置,dataX作业jobId,作业配置,下图配置是本地文件,若使用配置中心,url 以 ”cc://” 开始
Dbz引擎配置示例

几个重要的配置
connector.class 数据源,mysql,oracle等
offset.storage.file.filename binlog偏移存储文件位置,通常多个CDC作业,需启动多个debezium引擎,文件路径要区分,同样,databases.history.file.filaname 数据库schema文件位置
database.server.name 每个引擎配置不同的名称,否则出现异常:
javax.management.InstanceAlreadyExistsException: debezium.mysql:type=connector-metrics,context=schema-history,server=localhost
















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











