







Python版本: Python3.x 作者:崔家华
运行平台: Windows 编辑:黄俊嘉
IDE: Sublime text3
一、前言
上篇文章Python3《机器学习实战》学习笔记(四):朴素贝叶斯基础篇之言论过滤器讲解了朴素贝叶斯的基础知识。本篇文章将在此基础上进行扩展,你将看到以下内容:
1.拉普拉斯平滑
2.垃圾邮件过滤(Python3)
3.新浪新闻分类(sklearn)
二、朴素贝叶斯改进之拉普拉斯平滑
上篇文章提到过,算法存在一定的问题,需要进行改进。那么需要改进的地方在哪里呢?利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算 。如果其中有一个概率值为0,那么最后的成绩也为0。我们拿出上一篇文章的截图。
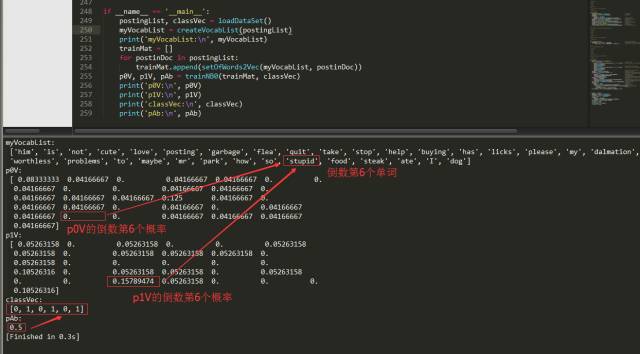
从上图可以看出,在计算的时候已经出现了概率为0的情况。如果新实例文本,包含这种概率为0的分词,那么最终的文本属于某个类别的概率也就是0了。显然,这样是不合理的,为了降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。这种做法就叫做拉普拉斯平滑(Laplace Smoothing)又被称为加1平滑,是比较常用的平滑方法,它就是为了解决0概率问题。
除此之外,另外一个遇到的问题就是下溢出,这是由于太多很小的数相乘造成的。学过数学的人都知道,两个小数相乘,越乘越小,这样就造成了下溢出。在程序中,在相应小数位置进行四舍五入,计算结果可能就变成0了。为了解决这个问题,对乘积结果取自然对数。通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。下图给出函数f(x)和ln(f(x))的曲线。

检查这两条曲线,就会发现它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。因此我们可以对上篇文章的trainNB0(trainMatrix, trainCategory)函数进行更改,修改如下:


运行代码,就可以得到如下结果:
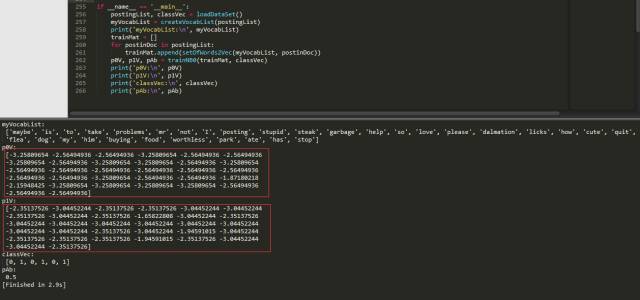
瞧,这样我们得到的结果就没有问题了,不存在0概率。当然除此之外,我们还需要对代码进行修改classifyNB(vec2Classify, p0Vec, p1Vec, pClass1)函数,修改如下:

为啥这么改?因为取自然对数了。
这样,我们的朴素贝叶斯分类器就改进完毕了。
三、朴素贝叶斯之过滤垃圾邮件
在上篇文章那个简单的例子中,我们引入了字符串列表。使用朴素贝叶斯解决一些现实生活中的问题时,需要先从文本内容得到字符串列表,然后生成词向量。下面这个例子中,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









