







 本文介绍了如何利用mmpose框架训练AnimalKingdom数据集来预测鸟类的骨架。过程包括安装mmpose和数据集,注册AK数据集,编写配置文件调整模型参数,训练模型并计算PCK精度,以及使用官方Demo进行预测和结果展示。
本文介绍了如何利用mmpose框架训练AnimalKingdom数据集来预测鸟类的骨架。过程包括安装mmpose和数据集,注册AK数据集,编写配置文件调整模型参数,训练模型并计算PCK精度,以及使用官方Demo进行预测和结果展示。
本文主要讲述了使用mmpose训练AnimalKingdom数据集来预测鸟类骨架
1、下载mmpose,AnimalKingdom数据集补充代码
安装 — MMPose 1.0.0 文档根据官方文档安装mmpose可以跑通demo
2、将AK补充代码下的ak.py复制到到mmpose-main的configs\ _base_\datasets

3、在mmpose\datasets\datasets\animal\__init__.py里注册AK数据集,在头文件from .ak_dataset import AKDataset,并且在此文件下创建一个ak_dataset.py,将下边的内容复制进去
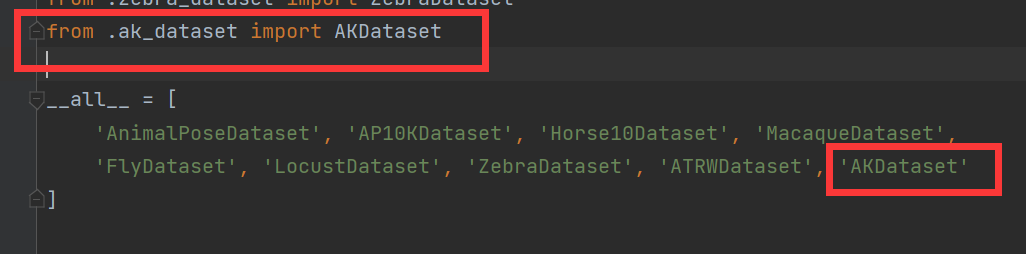
新建一个文件将代码复制进去,注册AK数据集
from ..base import BaseCocoStyleDataset
@DATASETS.register_module()
class AKDataset(BaseCocoStyleDataset):
"""Animal Kingdom dataset for animal pose estimation.
"[CVPR2022] Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding"
More details can be found in the `paper <https://www.researchgate.net/publication/359816954_Animal_Kingdom_A_Large_and_Diverse_Dataset_for_Animal_Behavior_Understanding>`__ .
Website: <https://sutdcv.github.io/Animal-Kingdom>
The dataset loads raw features and apply specified transforms
to return a dict containing the image tensors and other information.
Animal Kingdom keypoint indexes::
0: 'Head_Mid_Top',
1: 'Eye_Left',
2: 'Eye_Right',
3: 'Mouth_Front_Top',
4: 'Mouth_Back_Left',
5: 'Mouth_Back_Right',
6: 'Mouth_Front_Bottom',
7: 'Shoulder_Left',
8: 'Shoulder_Right',
9: 'Elbow_Left',
10: 'Elbow_Right',
11: 'Wrist_Left',
12: 'Wrist_Right',
13: 'Torso_Mid_Back',
14: 'Hip_Left',
15: 'Hip_Right',
16: 'Knee_Left',
17: 'Knee_Right',
18: 'Ankle_Left ',
19: 'Ankle_Right',
20: 'Tail_Top_Back',
21: 'Tail_Mid_Back',
22: 'Tail_End_Back
Args:
ann_file (str): Annotation file path. Default: ''.
bbox_file (str, optional): Detection result file path. If
``bbox_file`` is set, detected bboxes loaded from this file will
be used instead of ground-truth bboxes. This setting is only for
evaluation, i.e., ignored when ``test_mode`` is ``False``.
Default: ``None``.
data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
``'bottomup'``. In ``'topdown'`` mode, each data sample contains
one instance; while in ``'bottomup'`` mode, each data sample
contains all instances in a image. Default: ``'topdown'``
metainfo (dict, optional): Meta information for dataset, such as class
information. Default: ``None``.
data_root (str, optional): The root directory for ``data_prefix`` and
``ann_file``. Default: ``None``.
data_prefix (dict, optional): Prefix for training data. Default:
``dict(img=None, ann=None)``.
filter_cfg (dict, optional): Config for filter data. Default: `None`.
indices (int or Sequence[int], optional): Support using first few
data in annotation file to facilitate training/testing on a smaller
dataset. Default: ``None`` which means using all ``data_infos``.
serialize_data (bool, optional): Whether to hold memory using
serialized objects, when enabled, data loader workers can use
shared RAM from master process instead of making a copy.
Default: ``True``.
pipeline (list, optional): Processing pipeline. Default: [].
test_mode (bool, optional): ``test_mode=True`` means in test phase.
Default: ``False``.
lazy_init (bool, optional): Whether to load annotation during
instantiation. In some cases, such as visualization, only the meta
information of the dataset is needed, which is not necessary to
load annotation file. ``Basedataset`` can skip load annotations to
save time by set ``lazy_init=False``. Default: ``False``.
max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
None img. The maximum extra number of cycles to get a valid
image. Default: 1000.
"""
METAINFO: dict = dict(from_file='configs/_base_/datasets/ak.py')
4、仿照着写一个配置文件
mmpose-main\configs\animal_2d_keypoint\topdown_heatmap\animalpose随便挑一个仿着写
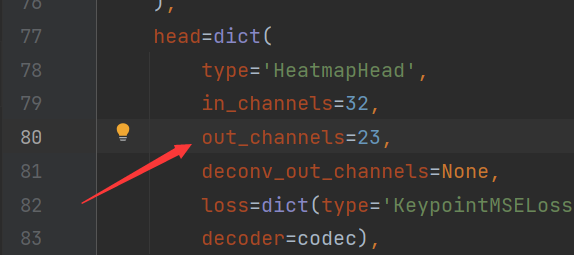
首先更改hook,改为pck准确率计算

接着更改模型的输出,AK的输出骨架时23个节点,因此把out_channels更改为23
更改数据集的名字,和图片和标签的路径
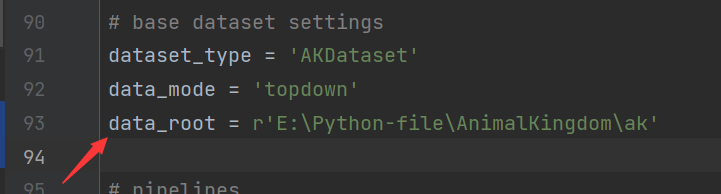
更改标签路径,并在img填上图片文件夹的名字
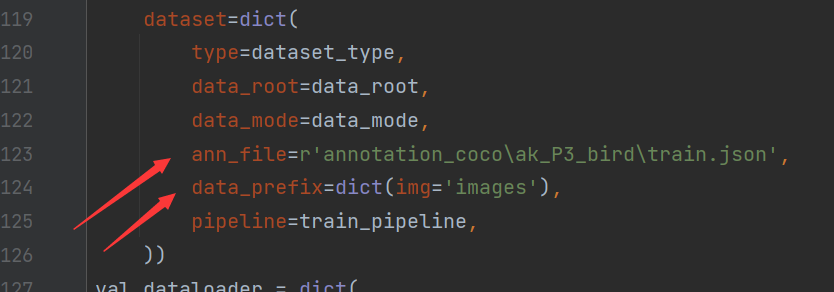
还可以改batch和其他参数
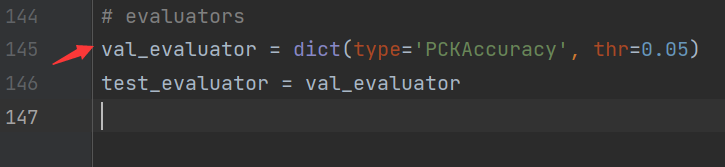
最后将val也改为PCK,给文件改个名
5、开始训练
直接终端训练,找到刚才的配置文件
python tools/train.py configs/animal_2d_keypoint/topdown_heatmap/ak/td-hm_hrnet-w32_8xb64-210e_ak-256x256.py
6、得到测试结果
官方有出demo可以预测视频图片Demos — MMPose 1.0.0 文档
预测需要同时全部安装mmdet和mmengine,按照官方文档,全部安装即可
###安装mmdet
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -v -e .
#安装mmengine
git clone https://github.com/open-mmlab/mmengine.git
cd mmengine
pip install -e . -v安装完成后,我是预测鸟,所以id为14,检测的模型和py文件运行官方的demo会下载
!python demo/topdown_demo_with_mmdet.py \
demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
configs/animal_2d_keypoint/topdown_heatmap/ak/td-hm_hrnet-w32_1xb32-210e_ak-256x256.py \
best_PCK_epoch_210.pth \
--input new.mp4 \
--output-root vis_result --det-cat-id=14最终效果还不错能识别多只鸟并且加上骨架



















 2817
2817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









