






一、文章信息
作者:徐安滢 吉宗诚 王 斌
单位:中国科学院 计算技术研究所 信息工程研究所
期刊:中文信息学报
题目:基于用户回答顺序的社区问答答案质量预测研究
二、背景、目的、结论
背景:摘要:近年来,随着互联网的普及和知识爆炸性的增长,社区问答网站积累了大量的用户和内容,同时也产生了大量的低质量文本﹐极大地影响了用户检索满意答案的效率,因此如何提升答案质量预测的性能十分重要。
目的:如何预测答案质量﹐提高检索内容的质量。如何在大量数据中识别出高质量的内容﹐减少数据冗余。如何更合理地表示答案特点,以及如何找到更多优质的特征。
结论:在前人的工作基础上,文章使用点对方式( pairwise)的Ranking SVM算法对答案质量进行预测,并发现在时间差与答案数量共同作用下,答案相对位置顺序对高质量答案预测的影响。经过实验证明,其性能在MRR上可提升4.47个百分点﹐在s@2 上可提升5.55个百分点。
三、结果与讨论
本文使用Ranking sVM(点对方式)来进行模型学习和预测,通过同一问题下两两答案之间的偏序关系,对答案质量进行排序,以提高预测效果。同时还提出了一种使用用户回答顺序的新特征来进行答案质量预测。
将同一问题内的答案排序,利用时间顺序与答案数量的比值作为特征进行计算,此特征也称为答案之间的相对位置顺序,统一称其为K值,其计算方法如下所示。

当答案的相对位置越靠后时﹐即用户回答的时间相对越晚,K值越大﹔反之,K值越小。
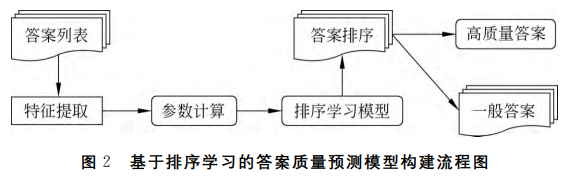
Ranking SVM算法使用支持向量机( support vector machine,sVM)的相关技术来实现训练、测试过程,其中利用成对问题的偏序思想,将排序问题转换为分类问题,其构建流程图如下图所示。
之后获取实验数据,并确定所用的评价指标:倒数排名均值MRR和在第N个位置上的成功率Success@ N(1≤N≤5)。公式如下:
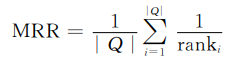
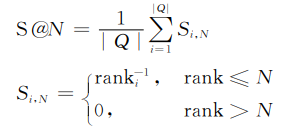
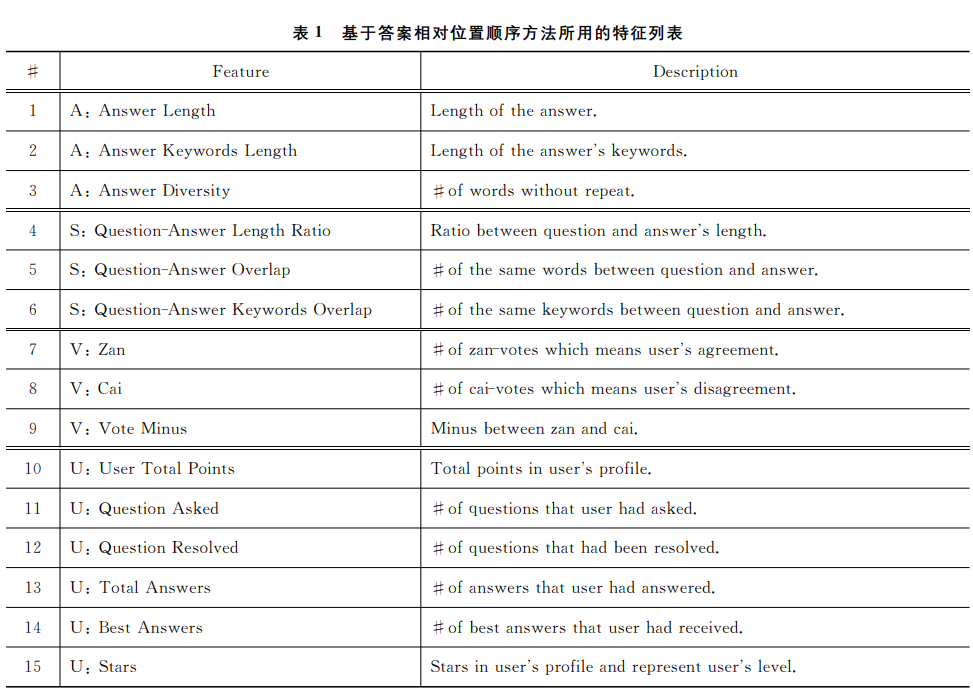
本文采用了文本、统计、用户、投票等多维度的15个特征作为基准值(表1)并确定参数c=0.0001。
以表1中的15个特征对系统的贡献值作为Baseline,添加答案相对位置顺序特征对系统的贡献值作为实验对比项,添加答案数量特征(AnsCnt)和时间差特征(TimeDiff)对系统的贡献值作为参考项﹐用以验证本文方法的有效性。
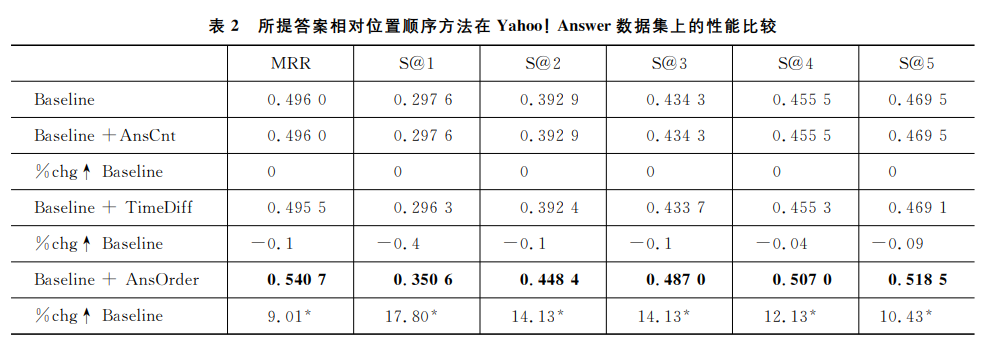
观察表⒉可知,相比于基准方法(Baseline),添加答案相对位置顺序特征(AnsOrder)后答案质量
预测效果在MRR和S@ N(1≤N≤5)上均有显著提高:在MRR指标上提升了9.01个百分点,对于
最佳答案排在第2位(S@2)的效果优化了14.13个百分点。
特别地,参考项答案数量特征(AnsCnt)和时间差特征(TimeDiff)的结果表明这两类特征并不能给对答案质量预测的性能带来提升﹐反而会带来干扰。而本文提出的综合考虑以上两个特征的新特征(即答案相对位置顺序特征)可以非常显著地提升答案质量预测的性能。
四、文章好在哪里
用实际存在的问题引出我们所需要解决的问题,点出现有研究方式的缺陷并说明研究方向,说明研究目的。自己也可以运用此方法。
相关工作充足,寻找了许多他人的研究模型或框架,取其精华去其糟粕,值得借鉴。
研究很饱满,多次总结前人的工作,获得启发。
采用新的Ranking sVM(点对方式)来进行模型学习和预测,根据新结论:时间因素应根据不同问题而有所变化,即在限定范围内进行时间对比。创造了新的K值计算法。利用成对问题的偏序思想,将排序问题转换为分类问题,而且答案质量的评价不是针对所有问题-答案对数据进行对比,而是在同一个问题下的答案列表之间进行对比,这样更有针对性。实验结果也证明这是一个较好的答案质量预测的方法。值得学习。
————————————————
版权声明:本文为CSDN博主「szx6984」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/szx6984/article/details/128504909















 5192
5192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









