







一、检查where子句和连接条件列
下面是不带where子句的select语句组成
select
p.Name,
p.StandardCost,
p.Weight,
p.ProductID
from Production.Product p表 'Product'。扫描计数 1,逻辑读取 15 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
为了理解where子句在查询优化器决策上的影响。添加一个检索但一行的where子句
set statistics io on
select
p.Name,
p.StandardCost,
p.Weight,
p.ProductID
from Production.Product p
where p.ProductID=738
set statistics io off表 'Product'。扫描计数 0,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
有了where子句,查询优化器检查where子句列ProductId,确定了ProductId上索引PK_Product_ProductId的可用性,产生的逻辑读取次数减少。
这也适用于两个表之间的连接条件中使用的列。
二、使用窄索引
先创建一个具有20行的测试表和一个索引
if(select OBJECT_ID('t1')) is not null
drop table t1;
go
create table t1(c1 int,c2 int);
with Nums
as(
select 1 as n
union all
select n+1
from Nums
where n<20
)
insert into t1(c1,c2)
select n,2
from Nums
create index i1 on t1(c1)因为索引列是窄的(int数据类型为4字节),一个8KB的索引行可以容纳索引的索引行
select i.name,
s.page_count,
i.type_desc,
s.record_count,
s.index_level
from sys.indexes i
join sys.dm_db_index_physical_stats(db_id(N'AdventureWorks2008'),object_id(N'dbo.t1'),null,null,'detailed') as s
on i.index_id=s.index_id
where i.object_id=object_id(N'dbo.t1')

为了看出宽索引的劣势,可以将索引列的c1数据类型从int改为char(500)。
drop index t1.i1
alter table t1 alter column c1 char(500)
create index i1 on t1(c1)再次执行索引相关的动态视图

因为char(500)数据类型列宽度为500字节。因为索引列的宽度很大,所以包含所有20个索引行需要2个索引页面。大的索引键值增加了索引页面的数量,从而增加了索引所需的内存和磁盘活动数量。
三、检查列的唯一性
比如说通过在表HumanResource.Employee,查找
select *
from HumanResources.Employee
where Gender='F' and SickLeaveHours=59 and MaritalStatus='M'
可以看出,返回的数据来自于扫描聚集索引(数据存储的地方)查找Gender=‘F’的相应值。
如果在该表上面的Gender列创建索引
create index ix_Employee on HumanResources.Employee(Gender)再次执行上述查询
select *
from HumanResources.Employee
where Gender='F' and SickLeaveHours=59 and MaritalStatus='M'执行计划任然相同。使用以下复合索引
create index ix_Employee on HumanResources.Employee(MaritalStatus,SickLeaveHours,Gender)
with (drop_existing =on)再次执行查询
select *
from HumanResources.Employee
where Gender='F' and SickLeaveHours=59 and MaritalStatus='M'
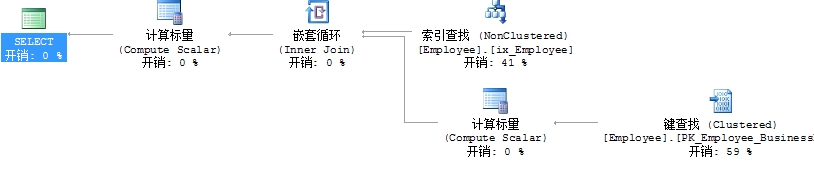
可以看出比用扫描聚集索引做的好。一个清晰的索引查找操作话费大约一半时间来收集数据,其余时间用作键值查找。
四、检查列数据类型
索引的数据列是重要的,例如,在一个整数键值上的索引查询是非常快的,这是应为int数据尺寸很小。
五、考虑列顺序
比如在Person.Address表上添加索引.
create index ix_test on Person.Address(City,PostalCode)运行这个表上将使用新的索引的一个简单的select语句
select * from Person.Address as a
where a.City='Warrington'表 'Address'。扫描计数 1,逻辑读取 188 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
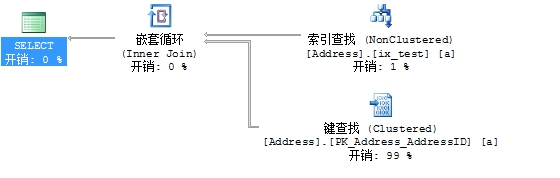
所以这个查询利用了索引的前沿来执行行查找操作,以检索数据。如果不适用前沿。
执行查询语句便是:
set statistics io on
select * from Person.Address as a
where a.PostalCode='WA3 7BH'
set statistics io off查询I\O和执行时间
表 'Address'。扫描计数 1,逻辑读取 173 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
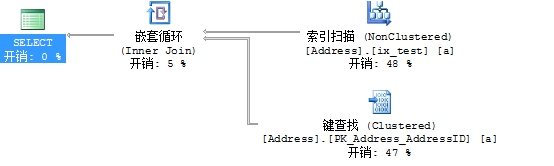
最后将查询改成下面的
set statistics io on
select a.AddressID,
a.City,
a.PostalCode
from Person.Address as a
where a.PostalCode='WA3 7BH' and a.City='Warrington'
set statistics io off表 'Address'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

I/O和执行计划的根本变化表现了复合索引的真正用处,--------覆盖索引
六、考虑索引类型(默认一张表的主键上面建索引都是聚族索引)
SQL SERVER有聚族索引和非聚族索引。都为B-树结构。主要区别是聚族索引叶子页面是表的数据页面。
表行物理上按照聚族索引列排序,因为表数据只能有一种物理顺序,所以一个表只有一个聚族索引
堆表,没有聚族索引的表称为堆表。堆表的数据列没有任何特别的顺序。与访问大的非堆表相比,堆表无组织结构增加了访问堆表的开销。
如表dbo.DatabaseLog没有聚族索引,只有一个非聚族索引。执行下面查询
select d.DatabaseLogID,d.PostTime
from dbo.DatabaseLog d
where d.DatabaseLogID=115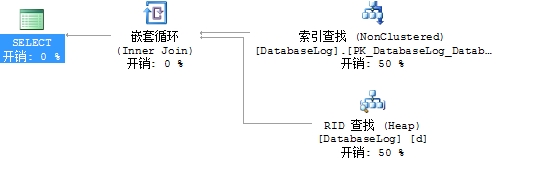
可以看到有RID查找开销,因为非聚集索引通过RID查找操作来检索数据。
如果是聚族索引查找,在HumanResources.Department表中有个个聚族索引。DepartmentID
select d.DepartmentID,
d.ModifiedDate
from HumanResources.Department as d
where d.DepartmentID=10
大多数的开销都是聚集索引查找。
聚族索引如果列值为1、2、4、5.如果想在其中插入聚族索引3的列值在4、5之间,如果该位置没有足够的可用空间,数据页面将发生一次页面分割。
然而非聚族索引便不会















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









