









Do We Really Need Deep Learning Models for Time Series Forecasting?
Elsayed S, Thyssens D, Rashed A, et al. Do We Really Need Deep Learning Models for Time Series Forecasting? [J]. ArXiv, 2021, abs/2101.02118
传统的时间序列预测模型往往依赖于滚动平均、向量自回归和自回归综合移动平均;较新的模型包括深度学习和矩阵分解模型,获得了更具竞争力的性能,但是该类模型往往过于复杂。
文章目录
1. 主要贡献
近几年,基于复杂深度学习的模型,例如“DeepGlo”或“LSTNet”被提出,性能上优于传统方法(例如ARIMA)和简单的机器学习模型(例如GBRT)。但是对于时序预测而言,如果对输入输入结构进行精心的设计和特征工程,即便是如GBRT这样的简单的集成模型,性能上也能超越很多DNN模型。
本文提出了基于窗的GBRT (梯度增强回归树) 模型:
- 将时序预测任务转换为基于窗的问题,再对输入和GBRT的输出结构结构进行特征工程,对于每个训练窗口,将目标值与外部特征连接,扁平化后构成一个输入
- 从经验上证明了为什么基于窗口的输入设置可以提高GBRT的预测性能
- 在9个数据集上,与8种SOTA深度学习模型进行对比。结果显示,基于窗的输入转换方法,可以将naive GBRT模型的性能提高到优于SOTA DNN模型的水平
2. 已有算法1
- ARIMA模型 (Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),为时间序列预测分析方法之一
- 时间正则化矩阵分解 (TRMF) 模型是一种高度可扩展的基于矩阵分解的方法,因为它能够对数据中的全局结构进行建模。作为本研究中较早的方法之一,该模型仅限于捕捉时间序列数据中的线性依赖关系,但还是显示了极具竞争力的结果
- 长短期时间序列网络 (LSTNet) 强调了局部多变量模式,由卷积层建模,以及长期依赖关系,由递归网络结构捕获
- 基于注意力的双阶段RNN (DARNN) 首先将模型输入通过一个输入注意力机制,随后采用一个配有额外时间注意力机制的编码器-解码器模型
- Deep Global Local Forecaster (DeepGlo) 是基于一个全局matrix factorization结构,该结构被一个时间卷积网络所规范化。该模型包含了来自日期和时间戳的额外通道
- 时空融合转化器 (Temporal Fusion Transformer) 模型是本研究中最新的DNN方法,通过将用于局部处理的递归层与捕捉数据中长期依赖关系的转化器典型的自我注意层相结合,该模型不仅可以在学习过程中动态地关注相关的特征,而且还可以通过门控机制抑制那些被认为是不相关的特征。
- DeepAR模型是一个自动回归的概率RNN模型,在附加时间和分类协变量的帮助下,从时间序列中估计参数分布。
- 深度状态空间模型 (DeepState) 是一个概率生成模型,使用RNN学习参数化的线性状态空间模型。
- 深度空气质量预测框架 (DAQFF) 包括一个两阶段的特征表示;数据通过三个一维卷积层,然后是两个双向LSTM层和一个次级线性层进行预测
3. 基于窗的GBRT
时间序列预测问题分为两类:
- 单变量 (uni-variate) 时间序列预测问题:数据只有一个通道,预测值仅由目标通道向量序列组成
- 具有单个目标通道的多变量 (multi-variate) 时间序列预测问题:其中预测器由向量对序列 ( x , y ) (\mathbf x,\mathbf y) (x,y) 组成,但任务是仅预测单个目标通道。1(注意,同一变量的多个独立的单目标时间序列不能视为多变量时间序列预测的特征,而是多个独立的单变量时间序列)
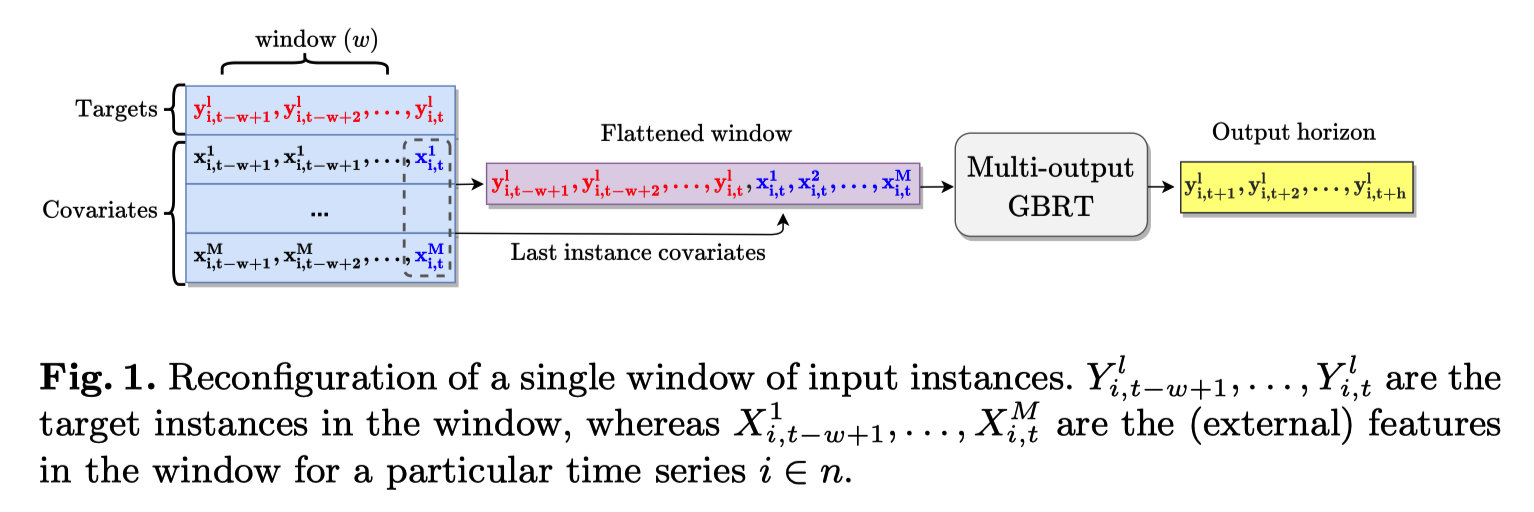
以多变量情景为例,对于第 i i i 个时间序列:
-
将2D的时间序列输入窗口reshape为1D窗口向量,其由 ( x , y ) (\mathbf x,\mathbf y) (x,y) 两部分拼接而成:
- w w w 个目标值 y = y i , t − w + 1 1 , y i , t − w + 2 1 , ⋯ , y i , t 1 \mathbf y = y^1_{i,t-w+1}, y^1_{i,t-w+2}, \cdots, y^1_{i,t} y=yi,t−w+11,yi,t−w+21,⋯,yi,t1
- M M M 个协变量序列分别在窗口的最后一个时间样点处 t t t 的值 x = x i , t 1 , x i , t 2 , ⋯ , x i , t M \mathbf x = x^1_{i,t}, x^2_{i,t}, \cdots, x^M_{i,t} x=xi,t1,xi,t2,⋯,xi,tM (即“外部特征”)
-
将输入序列向量传入多输出GBRT,预测未来 h h h 个时刻的值 y ′ = y i , t + 1 1 , y i , t + 2 1 , ⋯ , y i , t + h 1 \mathbf y' = y^1_{i,t+1}, y^1_{i,t+2}, \cdots, y^1_{i,t+h} y′=yi,t+11,yi,t+21,⋯,yi,t+h1
-
将预测器包装为支持多输出的MultiOutputRegressor。这种设置会导致预测范围内的目标变量是独立预测的,模型无法从它们之间的潜在关系中获益。但是GBRT基于窗口数据的输入设置不仅将预测问题转化为回归任务,还能够捕捉目标变量中的自相关效应,弥补了多输出独立预测的缺陷。1
4. 模型评估
4.1 数据集
其中协变量个数
M
≠
0
M \ne 0
M=0 的为多变量时间序列。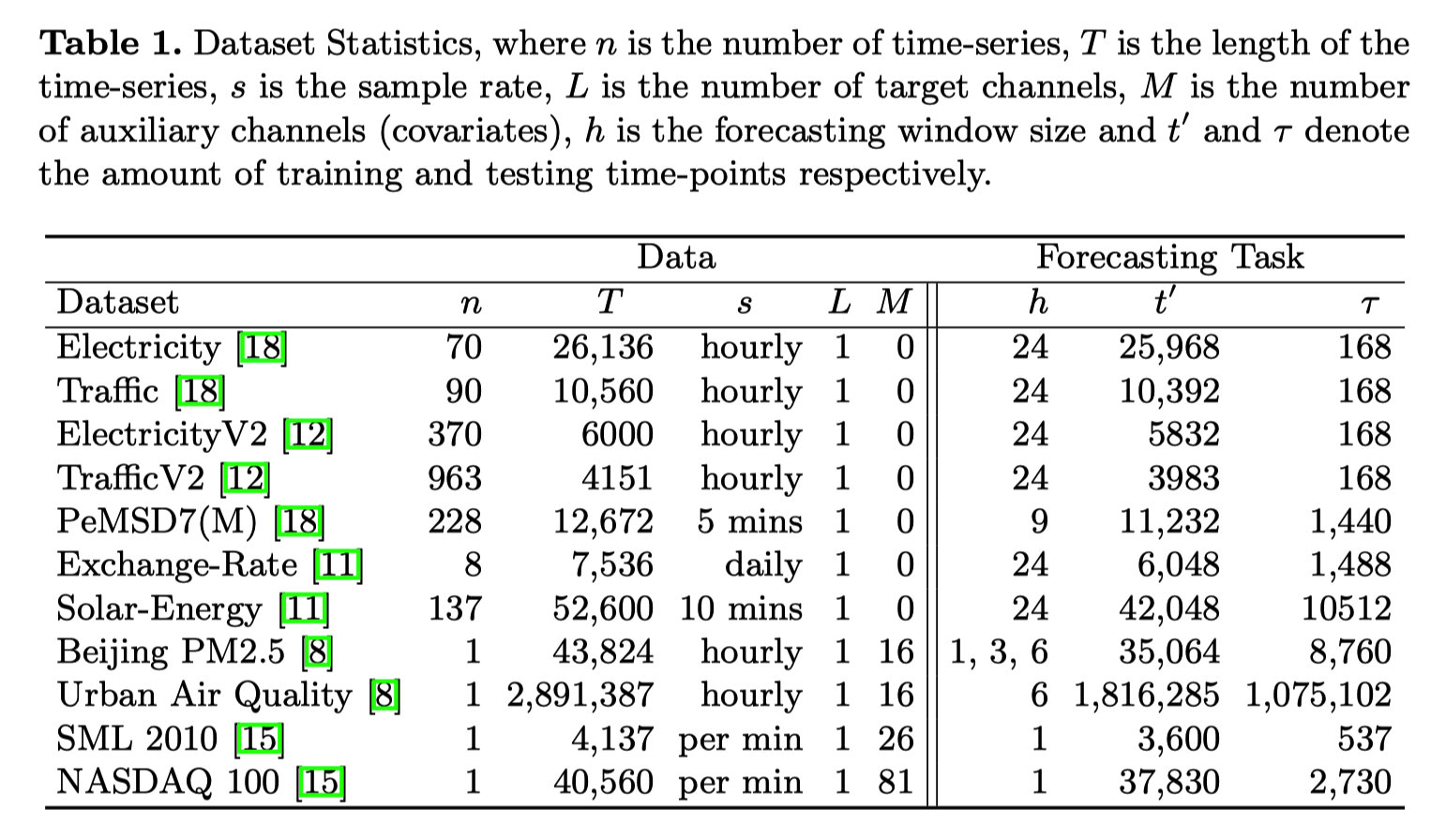
4.2 单变量数据集
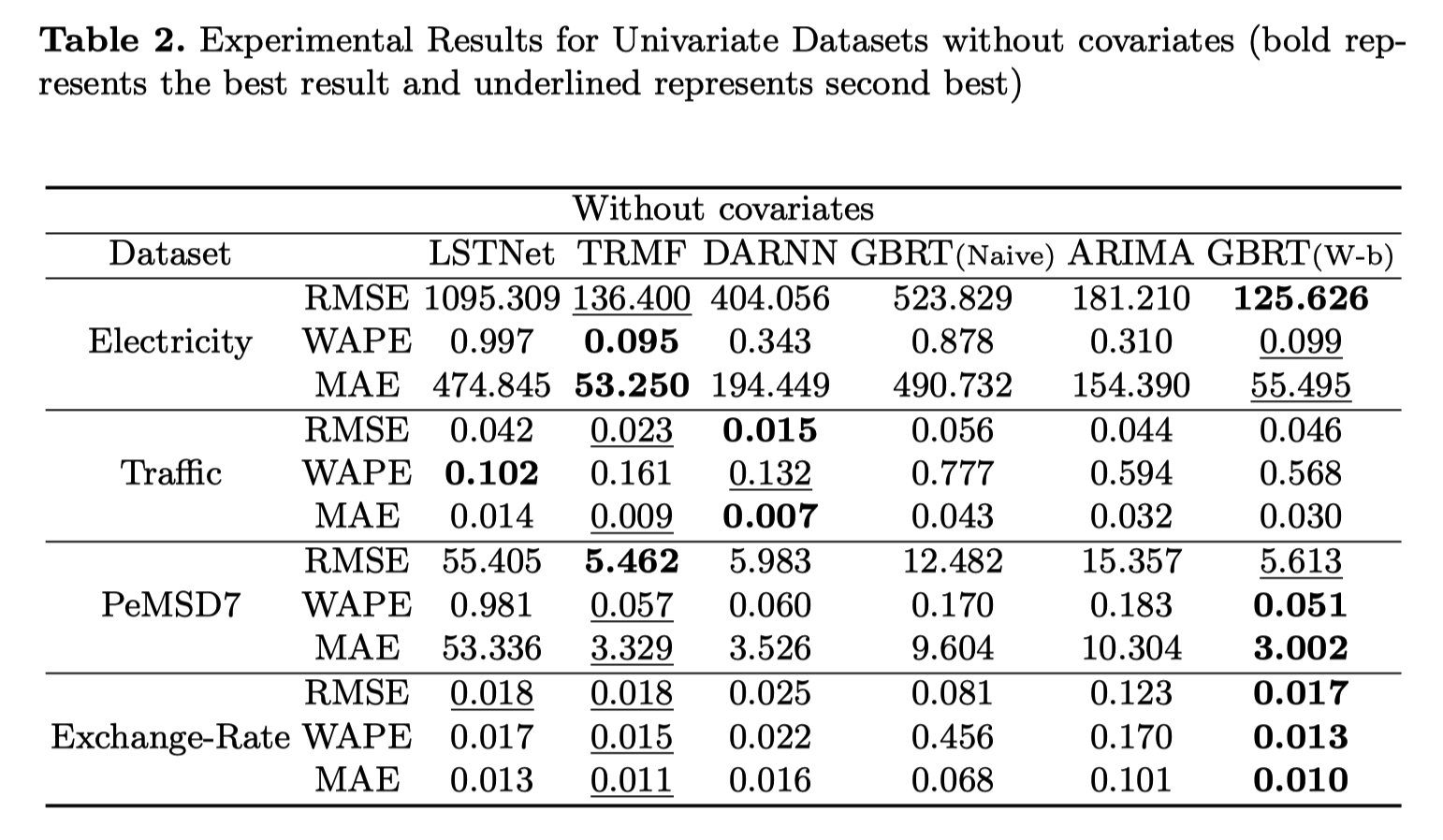
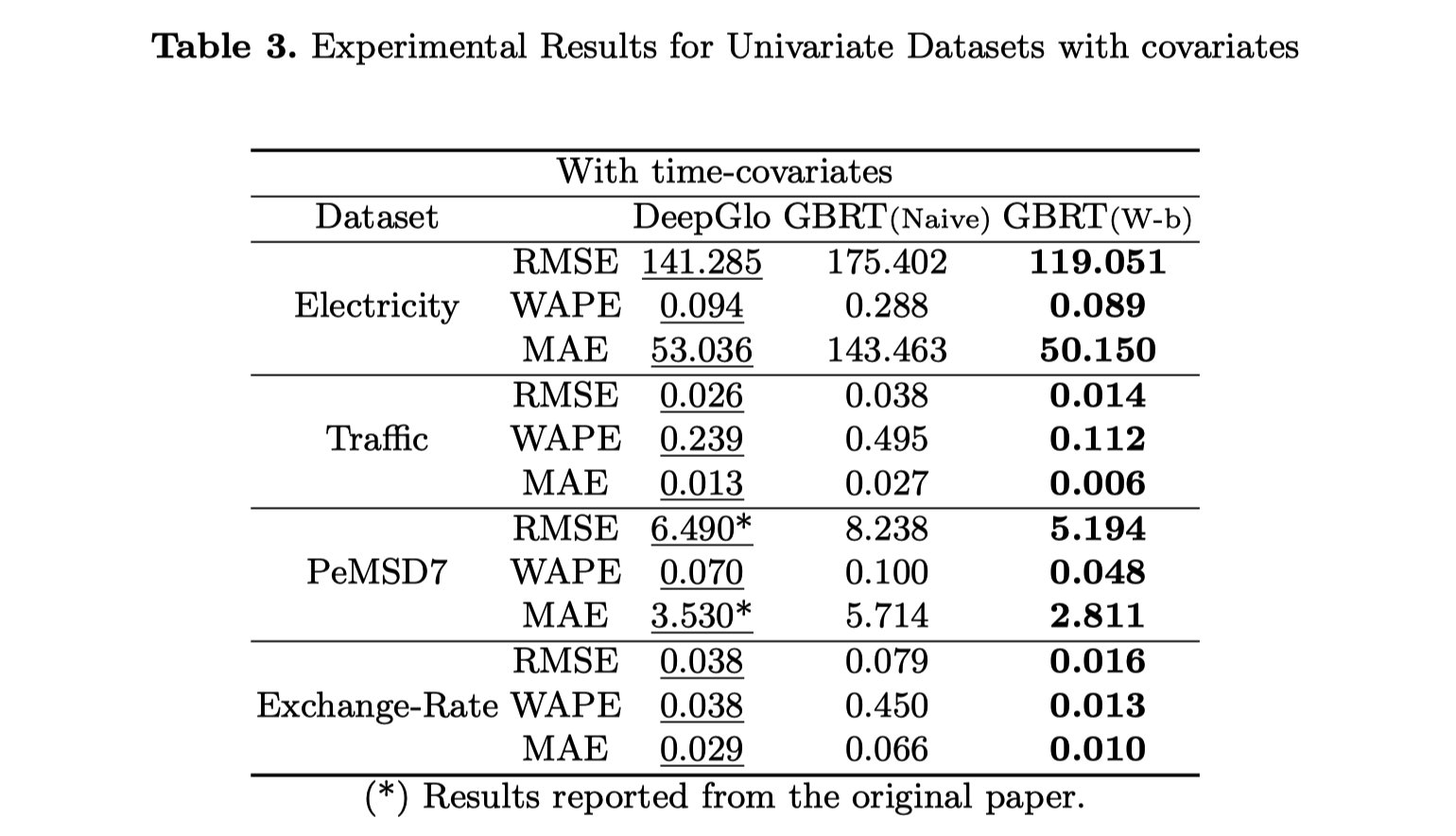
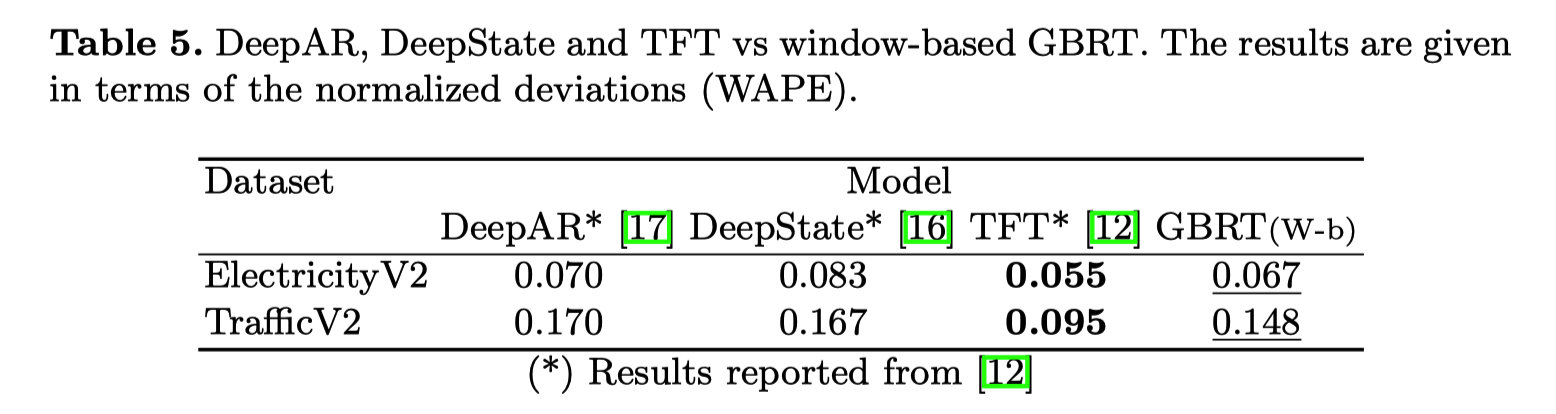
结果说明:
- (Table 2) 仔细配置和调整机器学习的baseline可以有效提高模型性能
- (Table 2) 没有协变量的参与下,仅时间窗口便可给GBRT模型带来性能提升
- (Table 3) 对于GBRT,加入协变量(主要从时间戳中获取信息),可以大幅提升性能
- (Table 5) 基于Transformer的TFT模型性能优于GBRT
4.3 多变量数据集
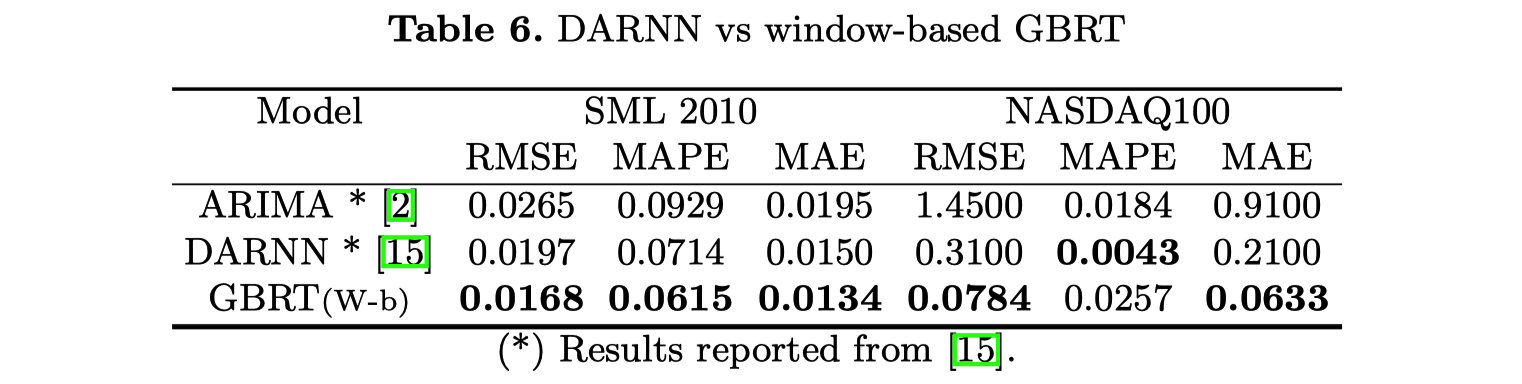
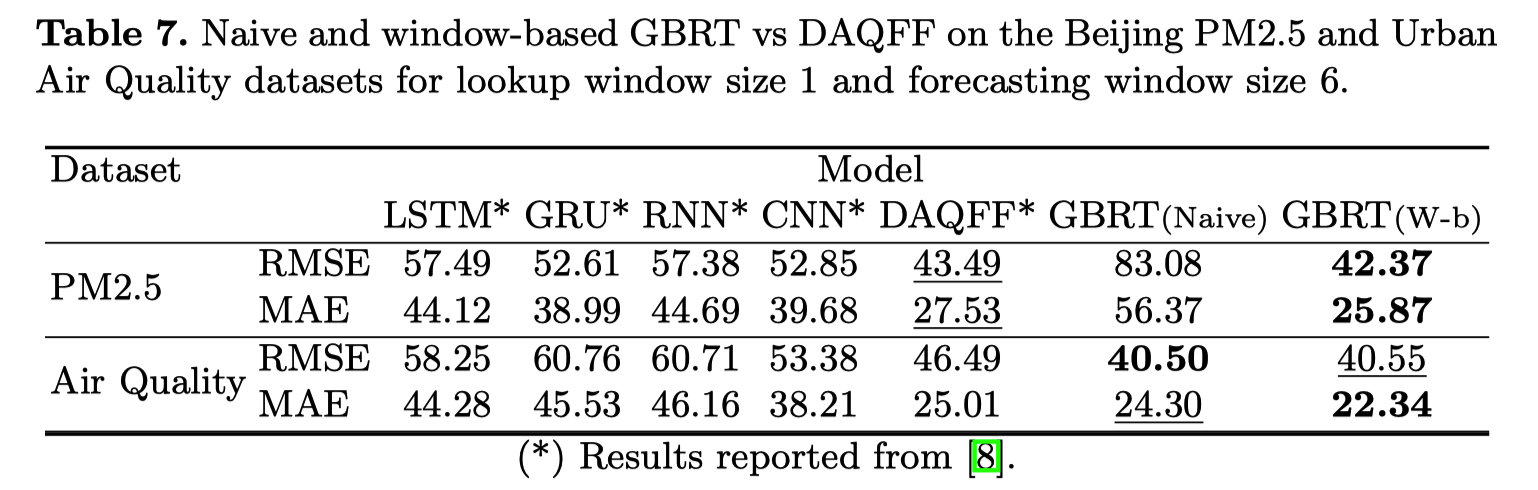
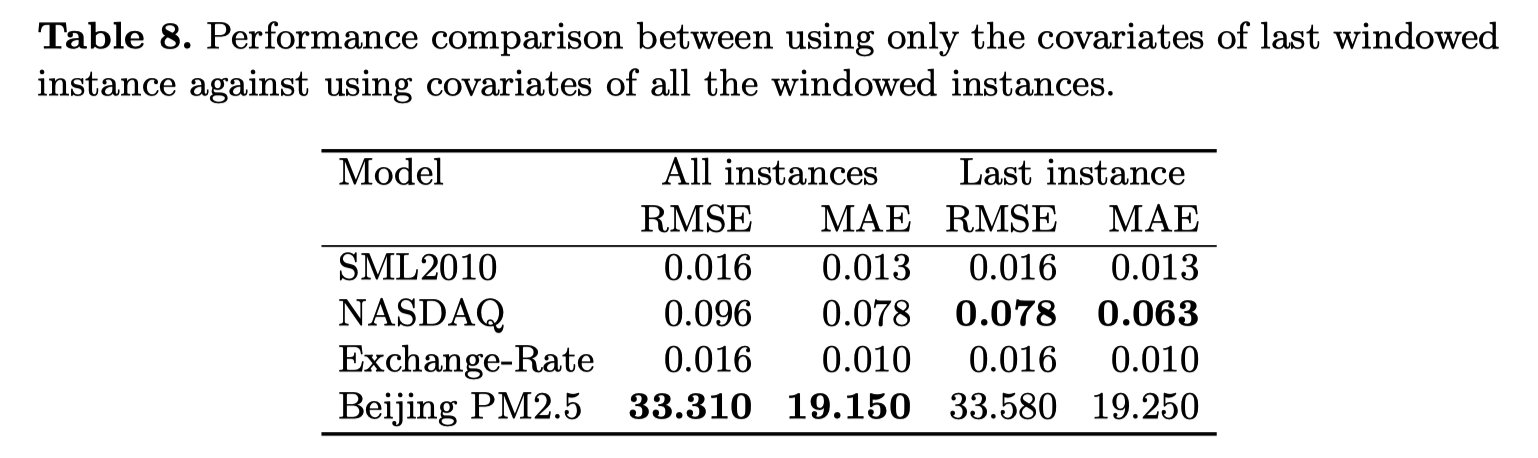
结果说明:
- (Table 6) 在配置可能不太强大的机器学习基线时,不仅要小心,而且在创建评估基线池时也要小心
- (Table 8) 对于协变量序列,只考虑时间窗的最后一个实例几乎不会造成信息损失,反而可以节省很多计算资源
5. 展望
基于窗的方法可以应用于其他简单的机器学习模型,例如多层感知机、支持向量机等。















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









