






前言
操作日志几乎存在于每个系统中。操作日志和系统日志不一样,操作日志必须要做到简单易懂。
操作日志的使用场景
操作日志:主要是对某个对象进行新增操作或者修改操作后记录下这个新增或者修改,操作日志要求可读性比较强,因为它主要是给用户看的,比如订单的物流信息,用户需要知道在什么时间发生了什么事情。再比如,客服对工单的处理记录信息。
操作日志的记录格式大概分为下面几种: * 单纯的文字记录,比如:2021-09-1610:00 订单创建。 * 简单的动态的文本记录,比如:2021-09-16 10:00 订单创建,订单号:NO.11089999,其中涉及变量订单号“NO.11089999”。 * 修改类型的文本,包含修改前和修改后的值,比如:2021-09-16 10:00 用户小明修改了订单的配送地址:从“金灿灿小区”修改到“银盏盏小区” ,其中涉及变量配送的原地址“金灿灿小区”和新地址“银盏盏小区”。 * 修改表单,一次会修改多个字段。
实现方式
使用Canal监听数据库记录操作日志
Canal 是一款基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费的开源组件,通过采用监听数据库 Binlog 的方式,这样可以从底层知道是哪些数据做了修改,然后根据更改的数据记录操作日志。
这种方式的优点是和业务逻辑完全分离。缺点也很明显,局限性太高,只能针对数据库的更改做操作日志记录,如果修改涉及到其他团队的 RPC 的调用,就没办法监听。
通过日志文件的方式记录
log.info(" 订单创建 “)
log.info(” 订单已经创建,订单编号 :{}“, orderNo)
log.info(” 修改了订单的配送地址:从 “{}” 修改到 “{}”, " 金灿灿小区 ", " 银盏盏小区 ")
这种方式的操作记录需要解决三个问题:
问题一:操作人如何记录
借助 SLF4J 中的 MDC 工具类,把操作人放在日志中,然后在日志中统一打印出来。首先在用户的拦截器中把用户的标识 Put 到 MDC 中(MDC.put(“userId”, userNo);)。
其次,把 userId 格式化到日志中,使用 %X{userId} 可以取到 MDC 中用户标识。
” %d{yyyy-MM-dd HH:mm:ss.SSS} %t %-5level %X{userId}%logger{30}.%method:%L - %msg%n”
问题二:操作日志如何和系统日志区分开
通过配置 Log 的配置文件,把有关操作日志的 Log 单独放到一日志文件中。然后在Java代码单独的记录业务日志。
问题三:如何生成可读懂的日志文案
可以采用 LogUtil 的方式,也可以采用切面的方式生成日志模板,后续内容将会进行介绍。这样就可以把日志单独保存在一个文件中,然后通过日志收集可以把日志保存在 Elasticsearch 或者数据库中,接下来看下如何生成可读的操作日志。
通过LogUtil的方式记录日志
LogUtil.log(orderNo, " 订单创建 ", " 小明 ") 模板
LogUtil.log(orderNo, " 订单创建,订单号 "+“NO.11089999”, " 小明 “)
String template = " 用户 %s 修改了订单的配送地址:从 “%s” 修改到 “%s””
LogUtil.log(orderNo, String.format(tempalte, " 小明 ", " 金灿灿小区 ", " 银盏盏小区 "), " 小明 ")
这里解释下为什么记录操作日志的时候都绑定了一个 OrderNo,因为操作日志记录的是:某一个“时间”“谁”对“什么”做了什么“事情”。当查询业务的操作日志的时候,会查询针对这个订单的的所有操作,所以代码中加上了OrderNo,记录操作日志的时候需要记录下操作人,所以传了操作人“小明”进来.
当业务变得复杂后,记录操作日志放在业务代码中会导致业务的逻辑比较繁杂,最后导致 LogUtils.logRecord() 方法的调用存在于很多业务的代码中,而且类似 getLogContent() 这样的方法也散落在各个业务类中,对于代码的可读性和可维护性来说是一个灾难。
方法注解实现操作日志
为了解决上面问题,一般采用 AOP 的方式记录日志,让操作日志和业务逻辑解耦,接下来看一个简单的 AOP 日志的例子。
@LogRecord(content=" 修改了配送地址 ")
public void modifyAddress(updateDeliveryRequest request){
// 更新派送信息 电话,收件人、地址
doUpdate(request);
}
AOP生成动态的操作日志
动态模板
@LogRecord(
content = " 修改了订单的配送地址:从 "#oldAddress", 修改到“#request.address"",
operator = "#request.userName", bizNo="#request.deliveryOrderNo")
public void modifyAddress(updateDeliveryRequest request, String oldAddress){
// 查询出原来的地址是什么
LogRecordContext.putVariable("oldAddress", DeliveryService.queryOldAddress(request.getDeliveryOrderNo()));
// 更新派送信息 电话,收件人、地址
doUpdate(request);
}
operator参数非必填。
LogRecordContext 解决了操作日志模板上使用方法参数以外变量的问题,同时避免了为了记录操作日志修改方法签名的设计.
自定义函数。如果我们可以通过自定义函数把用户 ID 转换为用户姓名和电话,那么就能解决这一问题,按照这个思路,我们把模板修改为下面的形式:
@LogRecord(content = " 修改了订单的配送员:从 {deliveryUser{#oldDeliveryUserId}}",修改到 "{deveryUser{#request.userId}}"",
bizNo="#request.deliveryOrderNo")
public void modifyAddress(updateDeliveryRequest request){
// 查询出原来的地址是什么
LogRecordContext.putVariable("oldDeliveryUserId", DeliveryService.queryOldDeliveryUserId(request.getDeliveryOrderNo()));
// 更新派送信息 电话,收件人、地址
doUpdate(request);
}
其中deliveryUser是自定义函数,使用大括号把Spring的SpEL表达式包裹起来。
进一步优化,净化业务代码:
@LogRecord(content = " 修改了订单的配送员:从 "{queryOldUser{#request.deliveryOrderNo()}}", 修改到 "{deveryUser{#request.userId}}"",
bizNo="#request.deliveryOrderNo")
public void modifyAddress(updateDeliveryRequest request){
// 更新派送信息 电话,收件人、地址
doUpdate(request);
}
通过直接增加一个自定义函数queryOldUser,查到之前的配送人员。
代码实现解析
代码结构
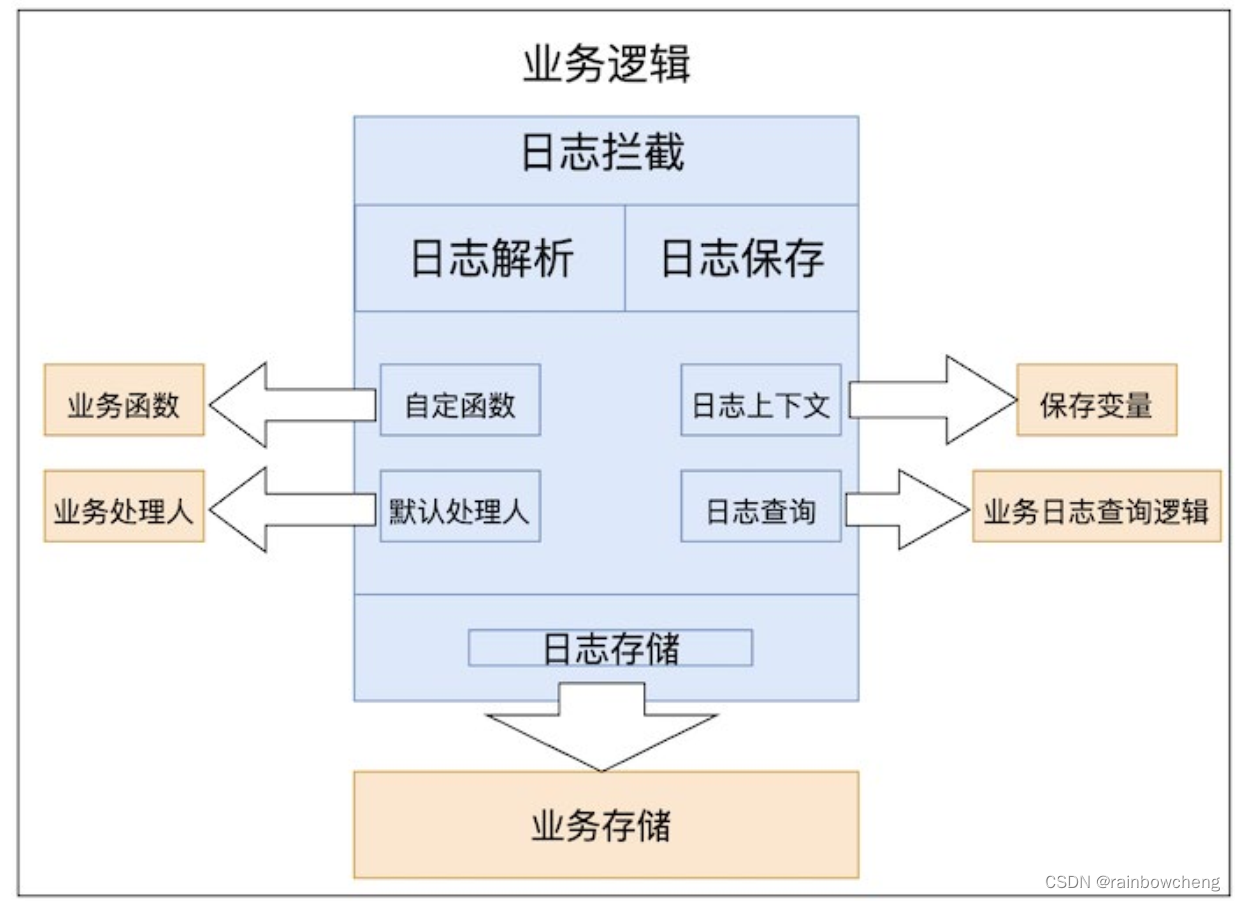
模块介绍
AOP拦截逻辑
针对@LogRecord注解分析出需要记录的操作日志,然后操作日志持久化。
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface LogRecordAnnotation {
String success();
String fail() default "";
String operator() default "";
String bizNo(); //操作日志绑定的业务对象标识
String category() default ""; //操作日志的种类
String detail() default ""; //修改详情
String condition() default ""; //记录日志的条件
}
解析逻辑
模板解析
Spring 3 提供了一个非常强大的功能:Spring EL,SpEL 在 Spring 产品中是作为表达式求值的核心基础模块,它本身是可以脱离 Spring 独立使用的。举个例子:
public static void main(String[] args) {
SpelExpressionParser parser = new SpelExpressionParser();
Expression expression = parser.parseExpression("#root.purchaseName");
Order order = new Order();
order.setPurchaseName(" 张三 ");
//打印“张三”。
System.out.println(expression.getValue(order));
}
日志上下文实现
下面是 LogRecordContext 的实现,这个类里面通过一个 ThreadLocal 变量保持了一个栈,栈里面是个 Map,Map 对应了变量的名称和变量的值。
public class LogRecordContext {
private static final InheritableThreadLocal<Stack<Map<String,
Object>>> variableMapStack = new InheritableThreadLocal<>();
// 其他省略 ....
}
上面使用了 InheritableThreadLocal,所以在线程池的场景下使用LogRecordContext 会出现问题,如果支持线程池可以使用阿里巴巴开源的 TTL 框架.
使用堆栈:但是使用 LogRecordAnnotation 的方法里面嵌套了另一个使用 LogRecordAnnotation 方法的时候,就可以看到,当方法二执行了释放变量后,继续执行方法一的 logRecord 逻辑,此时解析的时候 ThreadLocal <
后记
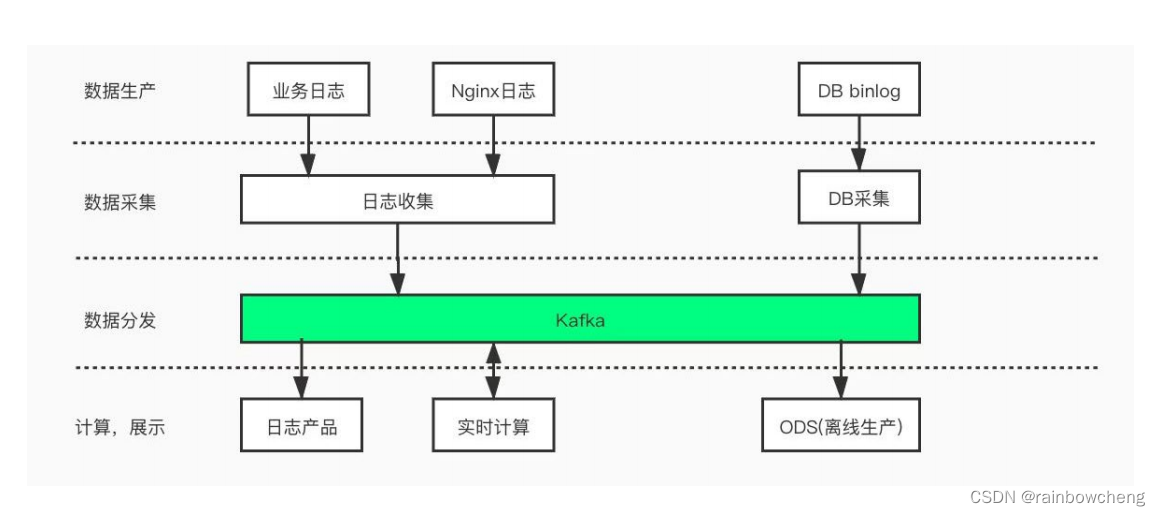
- 对于Produce请求:Server 端的 I/O 线程统一将请求中的数据写入到操作系统的PageCache 后立即返回,当消息条数到达一定阈值后,Kafka 应用本身或操作系统内核会触发强制刷盘操作(如左侧流程图所示)。
- 对于 Consume 请求:主要利用了操作系统的 ZeroCopy 机制,当 Kafka Broker接收到读数据请求时,会向操作系统发送 sendfile 系统调用,操作系统接收后,首先试图从 PageCache 中获取数据(如中间流程图所示);如果数据不存在,会触发缺页异常中断将数据从磁盘读入到临时缓冲区中(如右侧流程图所示),随后通过 DMA 操作直接将数据拷贝到网卡缓冲区中等待后续的 TCP 传输。
综上所述,Kafka 对于单一读写请求均拥有很好的吞吐和延迟。处理写请求时,数据写入 PageCache 后立即返回,数据通过异步方式批量刷入磁盘,既保证了多数写请求都能有较低的延迟,同时批量顺序刷盘对磁盘更加友好。处理读请求时,实时消费的作业可以直接从 PageCache 读取到数据,请求延迟较小,同时 ZeroCopy 机制能够减少数据传输过程中用户态与内核态的切换,大幅提升了数据传输的效率。但当同一个 Broker 上同时存在多个 Consumer 时,就可能会由于多个 Consumer竞争 PageCache 资源导致它们同时产生延迟。
Kafka 引擎在读写行为上具有如下特性:
● 数据的消费频率随时间变化,越久远的数据消费频率越低。
● 每个分区(Partition)只有 Leader 提供读写服务。
● 对于一个客户端而言,消费行为是线性的,数据并不会重复消费
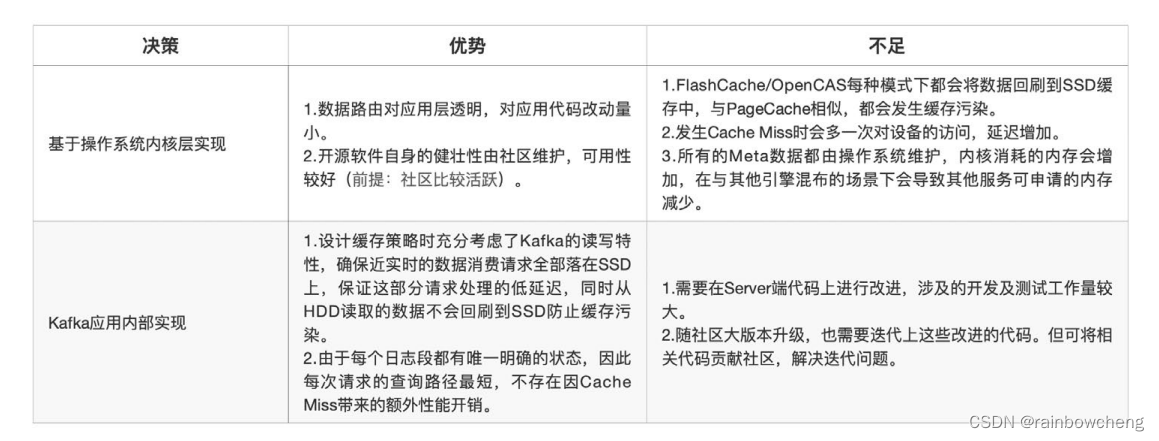
基于操作系统内核层实现
目前开源的缓存技术有 FlashCache、BCache、DM-Cache、OpenCAS 等,其中 BCache 和 DM-Cache 已经集成到 Linux 中,但对内核版本有要求,受限于内核版本,我们仅能选用 FlashCache/OpenCAS。
FlashCache 以及 OpenCAS 二者的核心设计思路类似,两种架构的核心理论依据为“数据局部性”原理,将 SSD 与 HDD 按照相同的粒度拆成固定的管理单元,之后将 SSD 上的空间映射到多块 HDD 层的设备上(逻辑映射 or 物理映射)。在访问流程上,与 CPU 访问高速缓存和主存的流程类似,首先尝试访问 Cache层,如果出现 CacheMiss,则会访问 HDD 层,同时根据数据局部性原理,这部分数据将回写到 Cache 层。如果 Cache 空间已满,会通过 LRU 策略替换部分数据。

Kafka应用内部实现
核心的理论依据“数据局部性”原理与 Kafka 的读写特性并不能完全吻合,“数据回刷”这一特性依然会引入缓存空间污染问题。同时,上述架构基于 LRU 的淘汰策略也与 Kafka 读写特性存在矛盾,在多 Consumer 并
发消费时,LRU 淘汰策略可能会误淘汰掉一些近实时数据,导致实时消费作业出现性能抖动。
整体设计思路如下,将数据按照时间维度分布在不同的设备中,近实时部分的数据缓存在 SSD 中,这样当出现 PageCache 竞争时,实时消费作业从 SSD 中读取数据,保证实时作业不会受到延迟消费作业影响。
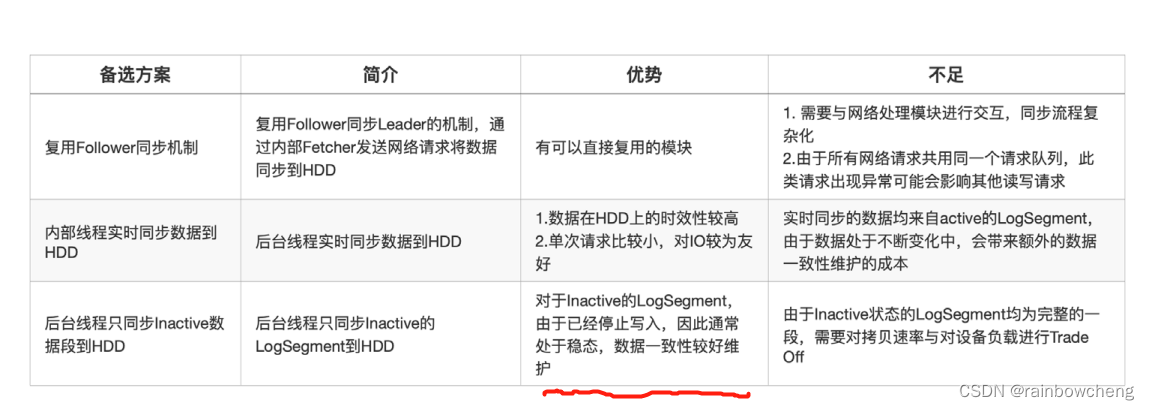
由于写入流量的上升,在刷盘过程中会产生大量的毛刺,而毛刺的值几乎接近磁盘最大的写入带宽,这会使读写请求延迟发生抖动。
我们修改了刷盘的机制,将原本的按条数限制修改为按实际刷盘的速率限制,对于单个 Segment,刷盘速率限制为 2MB/s。该值考虑了线上实际的平均消息大小,如果设置过小,对于单条消息较大的 Topic 会过于频繁的进行刷新,在流量较高时反而会加重平均延迟。
















 6871
6871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











