









优化篇 -> 配置篇 -> 服务器 -->部署 --> 进阶索引 --> 大数据概念 --> 数据仓
基础
概念
数据库体系结构的三级模式为:外模式、概念模式和内模式。
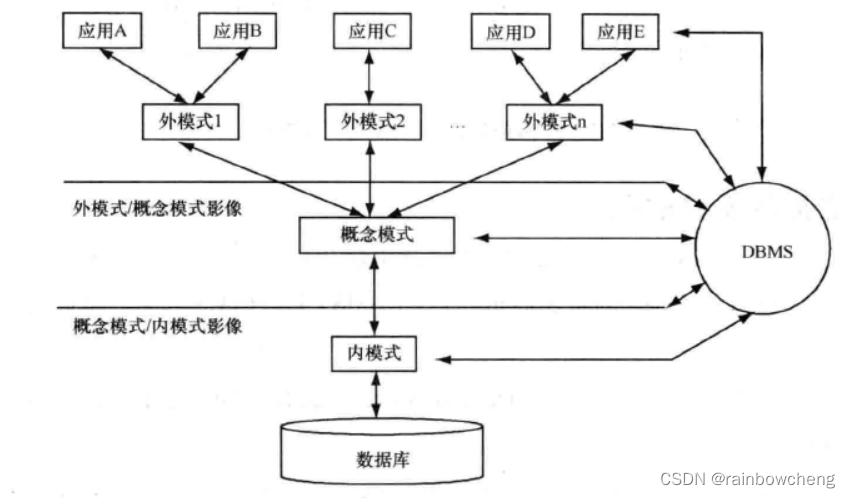
- 内模式:存储模式,对数据的物理结构和存储方式的描述。提供数据定义语言定义的。如顺序还是索引存储(将概念模式定义的数据进行组织存储,达到较好运行效率)
- 概念模式:数据库模式,数据的逻辑结构的描述。数据模型为基础。不涉及数据的存储细节和硬件环境。
- 外模式:用户模式或子模式,是概念模式子集,定义允许用户操作的数据。
- 内模式/概念模式映像:当数据的物理结构发生变化时,如增加索引、改变数据的存储位置、改变存储设备等,不影响数据的逻辑结构。
- 概念模式/外模式映像:数据逻辑结构发生变化时,如增加新的数据类型、在原记录类型增加新的联系,可以通过修改此层而外模式不受影响。
关系模型是由实体和联系构成的。需要满足Codd博士提出的十二条法则:
信息法则(列值/属性)、授权存储法则(表名+主键+列名访问)、Null值的系统处理、数据字典作为表来储存、数据存取语言、视图更新法则、集合级增删改、数据的物理独立性、数据逻辑独立性、数据完整性、分布独立性、非破坏性原则。
虽然没有一个数据库完全遵循所有12条法则,但规则有助于判断是否关系模型。
范式
1NF:第一范式就是无重复的列。
2NF:第二范式就是设置主键,非主属性依赖于主关键字。
3NF:第三范式就是不能冗余字段。
SQL语言
SQL(Structured Query Language)是结构化查询语言。可以创建、维护、保护数据库对象,并且可以操作对象中的数据。
- DDL(Data Definition Language)数据定义语言:主要创建、修改和删除数据库对象,如表-table、视图-view、索引-index、模式-schema、触发器-trigger和存储过程-procedure等。create / alter / drop
- DQL(Data Query Language)数据查询语言:用于数据的检索查询。select
- DML(Data Manipulation Language)数据操纵语言:用于添加、修改或删除存储在数据库对象中的数据。insert / update / delete
- DCL(Data Control Language)数据控制语言:控制访问数据库中特定对象的用户,控制用户对数据库的访问类型。grant授予 / deny拒绝 / revoke解除
- ALE(Additional Language Elements)其他语言要素:如事务控制(commit、rollback、set transaction)、程序化语言(declare游标、explan计划、open打开游标、fetch、close、prepare、execute动态执行、describe描述)等。
层次
目录(Catalog)–》模式(schema)–》表/视图/域/约束/触发器
比如创建一个学生模式(studentSchema),包括学生(student)、课程(course)和学生选课(student_course)等3个表和计算机系学生视图(computerDeptStud)。
set schema studentSchema:学生模式作为当前模式。
表
基础
表由行和列组成。每个表通常都有一个主关键字,用于确定一条记录。
- 永久表:create table。最常用的表。
- 临时表:create global/local temporary table生命周期对话结束,不能从一个sql会话访问另一个会话中创建表。分全局与临时(区别局部是模块内,全局是会话内)
数据类型
字符型、数字型、日期类型、二进制类型、文本类型、图形类型、自定义类型
表操作
CREATE TABLE `xxx_order_status_process` (
`id` int NOT NULL AUTO_INCREMENT,
`process` varchar(10) DEFAULT NULL COMMENT '流程',
`before_business_status` varchar(10) DEFAULT NULL COMMENT '前置状态',
`after_business_status` varchar(10) DEFAULT NULL COMMENT '后置状态',
`audit_flag` varchar(2) DEFAULT NULL COMMENT '通过标记-1:关闭,0:未通过,1:通过',
`note` varchar(100) DEFAULT NULL COMMENT '备注',
`del_flag` varchar(1) DEFAULT '0' COMMENT '是否删除:0表示未删除,1表示删除',
`create_by` varchar(32) DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_by` varchar(32) DEFAULT NULL COMMENT '更新人',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='受理单状态流程';
Insert into tableName [()] values ();
// 默认是column 可以不写
alter table tableName add columnName dataType COMMENT '' after
alter table tableName drop [column] columnName
//如果提示删除列错误 dependent on
alter table tableName drop constraint name
alter table tableName modify columnName dataType
//表的重命名
RENAME table oldName to newName
drop table tableName
索引与视图
表的存储两部分组成,一存放表的数据页面,另一存放索引页面。
簇索引:一个表只能有一个簇索引(主键)。簇索引与数据混为一体的,它的叶节点存储是实际的数据。- 非簇索引:叶节点存储关键字和行定位器。如果数据是以簇索引方式存储,行定位器存储是簇索引的索引键(主键),反之存储是指向数据行的指针。(最多建249个)
CREATE [unique] INDEX indexName ON tableName (columnName(length));
ALTER TABLE tableName ADD INDEX indexName(columnName);
//如下
ALTER TABLE t_user_action_log ADD INDEX ip_address_idx (ip_address(16));
//显示表索引
show index from tableName;
索引的原则
- ⨯ 对小数据表,使用索引并不能提高检索效率,因此不需对其创建索引。 ⨉
- ⩗ 当用户要索引字段的数据包含很多数值或很多空值(NULL)时,为该字段创建索引,会大大提高检索效率。
- ⩗ 查询结果包含行数小于总数的25%时,索引会显著提高查询效率。
- ⩗ 索引列在where子句中应频繁使用。
- ⩗ 先数据后索引。
- ⩗ 如果要对表中数据进行大量更新,最好销毁索引,等数据更新完毕再创建索引(索引提高查询速度,降低了更新速度)。
视图
视图是虚表。所对应的数据存储再各自的表中。修改视图数据对应表数据会发生变化,反之亦然。
- 优点:简化操作(视图本身是一个复杂查询结果集)、定制数据(重新过滤列)、合并分割数据、安全性等方面。
- 缺点:性能(复杂语句集)、更新限制(不能使用聚集函数、group by)
CREATE view result_view(aname,bname) as
select a.name as aname,b.name as bname from a,b where a.bid=b.id;
select * from result_view;
drop view view_name;
视图不是物理存在的,只是一个查询结果,一个被存储的查询。
简单查询 (❁´◡`❁)
select [distinct|all] column_name //5 从指定表中取出指定列的数据
from table_name... //1 指定要查询表的名字 或者 子查询
[where search_condition] //2 规定一种选择查询的标准
[group by expression] //3 归纳信息类型,汇总相关数据,对结果集进行分组,常与聚合函数一起使用
[having search_condition] //4 通过group产生的结果筛选,返回选取的结果集中行的数目
[order by expression [ASC|DESC]] //6 排序
//例如 查询至少有两名女教师的系以及拥有女老师数量,并且按女老师的数量升序的顺序排列结果
select 系名,count(性别) as num_girl
from 教师表
where 性别='女'
group by 系名
having count(性别)>=2
order by num_girl
- distinct 关键字如果查询列为多列,那么只有这些列的信息同时重复的记录才能被去除。对结果关系进行排序,相同的元组排在一起,才能去掉重复值。
- NULL值:参与
任何比较运算,结果都将视为false。(<>, >=, !=)- between and 是[]括号,包含两边。
NULL值
判断列中的值是否为NULL(is [not] null)。
聚合函数都忽略null值,即把null值的行排除在外,不进线分析。
ifnull(columnName,‘’)
复杂查询
AND运算符 false》null》true
| 表达式一 | 表达式二 | 结果 |
|---|---|---|
| true | true | true |
| true | false | false |
| true | null | null |
| false | false | false |
| false | null | false |
| null | null | null |
OR运算符 true>null>false
| 表达式一 | 表达式二 | 结果 |
|---|---|---|
| true | true | true |
| true | false | true |
| true | null | true |
| false | false | false |
| false | null | null |
| null | null | null |
AND、OR组合 and>or
c1 OR c2 AND c3 == c1 OR ( c2 AND c3)
IN 运算符
column IN( first value,…,last value)。相反运算是NOT IN。
IN运算符比OR有以下两个优点:
- 当条件多的时候,采用IN运算符显得很简便,运行效率比OR运算符要高
- 使用IN运算符,其后面所列的条件可以是一条select语句,即子查询
IN实现集合交和集合差╰(°▽°)╯
尽量使用内连接 替换 IN等。
-- IN(交) 实现即学习1课程又学习10课程的学生
select SNO,sname,dname
from student
where cno=1 and sno IN (select sno from student where cno=10)
//改成 and sno not in 就是差
where cno=1 and cno=10
EXISTS
子查询返回true或者false,数据内容不重要(IN需要数据内容)。
-- 查询开设课程有学生学习 全表教师的数据,每行去处理student表,看有没有返回值
select TNO,tname,dname,cno
from teacher t
where EXISTS (select sno from student where cno=t.cno)
-- 教师开的课在7月份考试的(交)
select TNO,tname,dname,cno
from teacher t
where tsex='女' and exists( select cno from course where month(ctest)=7 and cno = t.cno)
-- 改成内连接(交) 推荐 ಠ_ಠ
select t.cno,tname,dname from teacher t,course c
where c.cno=t.cno and tsex='女' and month(ctest)=7
NOT 运算符
NOT null 还是NULL。NOT与<>区别:NOT可以与其他运算符组合使用。
如:“AGE NOT between 40 and 50” ; " NOT SAL>1000 "
like 运算符
通配符 %(任意多个字符) 、-(任意一个字符)、[ ](指定一系列的字符)、*。只有char、varchar和text类型数据才能使用。
如:查询课程名6个字的
where cname like ‘______’ and cname not like ’ _____';(第一个6个下划线,第二个5个下划线) 有些版本不需要后面not
使用ESCAPE定义转义符
like ‘%m%’ ESCAPE ‘m’:告诉DBMS将第二个百分号作为实际值,而不是通配符。
like ‘AB&_%’ ESCAPE ‘&’ : 查询条件为以AB_开头的字符串。
连接符、数值运算与函数
连接符 CONCAT
+(sql server)或||(Oracle)。mysql数据库不支持连接符用CONCAT(name,‘-’,age)函数。
注意:使用连接符,如果其中一个列为null,连接后的数据也是null。
数值运算 + - / *
| 运算符号 | 说明 | 运算符号 | 说明 |
|---|---|---|---|
| + | 加 | / | 除 |
| - | 减 | % | 求余 |
select book_name,book_price*0.8 as off_price
from bookitem
where book_price*0.8 > 30
order by off_price;(排序是最后执行,所以可以用列别名)
类型转换 CAST
cast( value expression as dataType)。
// 2021-01-26 12:39:04 时间类型 转换为 2021-01-26 字符串
SELECT CAST(create_time as char(11)) as chardate,create_time from demo
表达式 CASE
CASE when search_condition then result_expression [… WHEN last search THEN last result]
[ELSE else_result_expression] END
SELECT age,
case
WHEN age>18 then '成年'
WHEN age>6 then '未成年'
else '婴儿'
end age_name
from demo
函数
curdate()、now()获取当前日期;convert()日期形式转换;substring()截取字符串中部分字符
聚合分析与分组
聚合函数都忽略null值,即把null值的行排除在外,不进线分析。
select count(*) as num,MAX(sal),min(age),avg(distinct sal) from demo
求和函数 SUM()
sum只能作用于数值型数据。会忽略NULL值
计数函数 count()
count(column) 只有列没有null时候 等于count(*)。count(distinct column)
最值函数 MAX/MIN
最值一般用于子查询中
SELECT * from demo
WHERE age=(SELECT MAX(age) FROM demo)
注意:虽然会忽略null,但是如果全部是null,则返回null。 作用于 数值、日期、字符串
均值函数 AVG
avg(age) == sum(age)/count(age) != sum(age)/count(*)
组合查询 group by
select column_name , SUM(column_name)
from table_name...
group by column_name
rollup 运算符
在group by子句中使用。各个组一起汇总。(往上一级汇总)
group by sex with rollup : 除了按性别分组外,加上组汇总。
having 子句
having可以理解 针对group的 where。 having count(columnName) >1
可以作用于group by 、where 、from,当没有前面子句就作用与后面的子句。
多表查询
from join_table JOIN_TYPE join_table ON condition
自然连接 natural join
将表中具有相同名称的列自动进行记录匹配。不需要指定任何同等连接条件。
内连接 inner join
返回结果集是两个表中所有相匹配的数据。
外连接 left join 、right join
左外连接 = 内连接 + 左边表中失配的元组(where a.id *= b.aid 实现左连接)
右外连接 = 内连接 + 右边表中失配的元组 (where a.id =* b.aid 实现右连接)
全外连接 = 内连接 + 左边表中失配的元组 +右边表中失配的元组
交叉连接 cross join
from a ,b == a cross join b
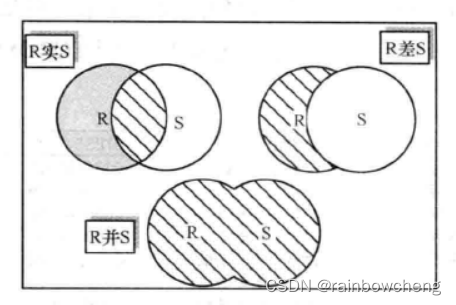
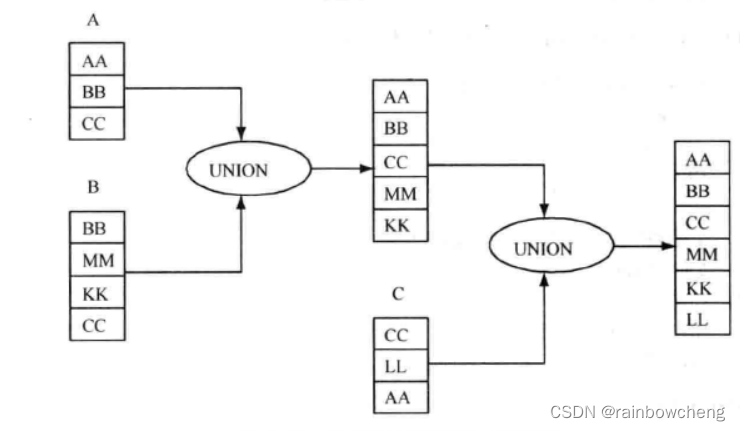
UNION 与UNION JOIN
并(拥有两个集合所有数据),交(同时在两个集合的数据),差(只在一个集合中数据) – union只能实现并,交与差需要IN帮助
-- 集合并操作
select * from r where column=1 UNION select * from s
注意:
UNION运算符与OR区别是,前者自动去除重复元组,而OR不会去重。(OR == UNION ALL)。- 不同表union需要两个表选择相同数量的列,并且相应的列必须具有相同的类型。
union join 是把两个表中列全部展示出来(像单表一样使用两个表中的所有行)- UNION运算符的select语句中,不能有order by;可以加在最后,对结果排序。
多表连接的运用
select tname 教师名,t.dname 系名,cname 课名,sname 学生名,mark 分数
from teacher t
left join course c //左连接,需要所有老师
on t.cno = c.cno
inner join student s //内连接,需要老师课必须有学生听
on t.cno = s.cno
order by tname
-- 取修过“计算机基础” 或者“生物工程” 学生的姓名 成绩
select SNO,sname,cname,mark
from student s , course c
where s.cno=c.cno and cname='计算机基础'
union //并集
select SNO,sname,cname,mark
from student s
inner join course c
on s.cno=c.cno
where cname = '生物工程'
order by sno
子查询 (●’◡’●)
查询结果作为另一个查询的参数。子查询可以使用在select、insert、update、delete语句中。
select SNO,sname,mark
from student s
where s.cno=(select cno from course where cname='计算机基础')
-- 改写
select SNO,sname,cname,mark
from student s , course c
where s.cno=c.cno and cname='计算机基础'
-- 查询年龄高于平均年龄的教师
select TNO,tname,dname,age
from teacher
where age > (select avg(age) from teacher)
order by age
-- 3.系的平均年龄大于总平均年龄 == 值得研究 ==
select TNO,tname,dname,cno,age
from teacher t
where (select avg(age) from teacher where dname=t.name) > (select avg(age) from teacher)
-- (4).统计课程学生数
select TNO,tname,dname,cno,
(select count(*) from student where cno=t.cno) s_num
from teacher t
-- (5).查询平均成绩高于70分的课程的课程号
select cno,cname,ctest
from course
where cno in (select cno from student group by cno having avg(mark) > 70)
-- (6).系的老师数量小于系中学生数
select t.dname from teacher t
group by t.dname
having count(tno)<(select count(sno) from student
where cno in (select cno from teacher t2 where t2.dname=t.dname))
-- (7).按天统计
select qudao_id,setting_id,type,date_format(create_time,'%Y-%m-%d') as qudao_name,count(0) as cnt from caozuo_archive
where date_format(create_time,'%Y-%m-%d') between '2017-01-01' and '2019-01-01'
group by qudao_id,setting_id,type,qudao_name;
-- 导出
select id,sys_code from cue
where date_format(create_date,'%Y-%m-%d')>='2021-11-01' and date_format(create_date,'%Y-%m-%d')<='2022-07-13' and ( contactor=''or contactor is null)
into outfile '/var/lib/mysql-files/data20220713.csv';
-- 混合排序(优化只用于字段状态少的 如 is_reply 0,1)ORDER BY a.is_reply ASC,a.appraise_time DESC
SELECT *
FROM ((SELECT *
FROM my_order o
INNER JOIN my_appraise a
ON a.orderid = o.id
AND is_reply = 0
ORDER BY appraise_time DESC
LIMIT 0, 20)
UNION ALL
(SELECT *
FROM my_order o
INNER JOIN my_appraise a
ON a.orderid = o.id
AND is_reply = 1
ORDER BY appraise_time DESC
LIMIT 0, 20)) t
ORDER BY is_reply ASC,
appraisetime DESC
LIMIT 20;
(6)的执行过程
- 将teacher表中的记录依据系名进行分组
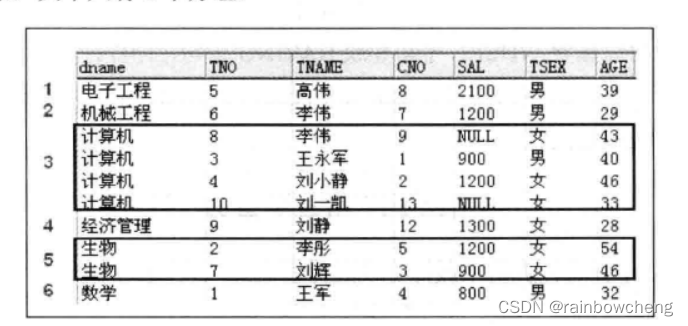
- 处理分组信息。假定取出第一组信息,“电子工程”。
- having 右边是一个相关子查询。子查询中含有一个子查询。执行where中 子查询开始,查询“电子工程”系所授课程的课程号 8。
- 然后执行where中 in 统计学习这些课程的学生数量(select count(sno) from student where cno in (8))。
- 然后,比较运算符左边与右边的值。如果成立 having子句返回true,将“电子工程”写入结果表中。
- 接着系统按照同样的方式依次处理中间表中第2组,第3组 …
some/all
与>、<号区别 是 可以多个值。使用的时候必须同时存在比较运算符。
| 表达式 | 含义 |
|---|---|
| >some | 大于子查询结果中的某个值 |
| >all | 大于子查询结果中的所有值 |
| !=some | 不等于子查询结果中的某个值 |
| !=all | 不等于子查询结果中的任何一个值 |
- 查询平均成绩最高的学生的学号以及平均成绩信息
select sno,avg(mark) avg_score from student
group by sno
having avg(mark) >= all (select avg(mark) from student group by sno)
- 按执行顺序,先执行group,将表中数据按学号分组,得到分组后的中间表
- 执行having子句,从分组后的中间表中取出一组,执行avg函数,得到其平均成绩
- 而后执行子查询,子查询返回的结果是学生表中每个同学的平均成绩。
- 如果步骤(2)与步骤(3)比较,满足条件加到主查询的结果表中。再执行2下一组
- 其他系比计算机系最小老师都小的老师(用
聚集函数比all效率高)
| 表达式 | 对应的聚集函数 | 表达式 | 对应的聚集函数 |
|---|---|---|---|
| >some | >min | <=some | <=max |
| >all | >max | <=all | <=min |
| =some | in | =all | - |
| >=some | >=min | !=some | - |
| >=all | >=max | !=all | not in |
select TNO,tname,dname,age
from teacher
where age < all (select age from teacher where dname='计算机') and dname <> '计算机'
-- age < (select min(age) from teacher where dname='计算机') and dname <> '计算机'
order by age
unique
判断集合是否存在重复元组。与exists判式相似,与子查询结合使用。
-- 课程被一个学生修过的。
select cno,cname,ctime,ctest
from course c
where unique (select sno from student where cno=c.cno)
--改成
select cno,cname,ctime,ctest
from course c
where (select count(sno) from student where cno=c.cno) =1
相关子查询(避免使用)
子查询执行需要依赖于上一层查询元组的当前值。实际中应该避免使用。
尽量用内连接来实现。效率高,灵活(可以用任意表中数据)
-- 错误示范1
SELECT *
FROM my_neighbor n
LEFT JOIN my_neighbor_apply sra
ON n.id = sra.neighbor_id
AND sra.user_id = 'xxx'
WHERE n.topic_status < 4
AND EXISTS(SELECT 1 --嵌套子查询 用到n.id
FROM message_info m
WHERE n.id = m.neighbor_id
AND m.inuser = 'xxx')
AND n.topic_type <> 5
-- 正确示范(用内连接) 条件语句中exists 改成 inner join
SELECT *
FROM my_neighbor n
INNER JOIN message_info m
ON n.id = m.neighbor_id
AND m.inuser = 'xxx'
LEFT JOIN my_neighbor_apply sra
ON n.id = sra.neighbor_id
AND sra.user_id = 'xxx'
WHERE n.topic_status < 4
AND n.topic_type <> 5
-- 错误示范2
UPDATE operation o
SET status = 'applying'
WHERE o.id IN (SELECT id
FROM (SELECT o.id,
o.status
FROM operation o
WHERE o.group = 123
AND o.status NOT IN ( 'done' )
ORDER BY o.parent,
o.id
LIMIT 1) t);
-- 正确示范 条件中IN 改成 join
UPDATE operation o
JOIN (SELECT o.id,
o.status
FROM operation o
WHERE o.group = 123
AND o.status NOT IN ( 'done' )
ORDER BY o.parent,
o.id
LIMIT 1) t
ON o.id = t.id
SET status = 'applying'
子查询创建视图
子查询创建视图(如:需要频繁查询课程学生的平均成绩,可以创建学生平均成绩视图)
create view <view_name> [(column1,column2)]
as
select <column_names> from <table_name>
树查询
数据插入操作
单行插入
指定字段插入数据,如果该字段可以接受空值,而且没有缺省值,则会被插入空值;如果该字段不能接受空值,而且没有缺省值,就会出现错误。
insert into table_name [column1,column2,...] values (value1,value2,...)
多行插入
insert into table_name [column1,column2,...] values (value11,value12,...),(value21,value22,...)
使用select 语句插入值
通常用于创建查找表。就是多库多表创建到一张表中。或者创建备份表。备份将要删除、截断数据装入新的表。
insert into table_name (column1,column2,...)
select column1,column2,...
from table_name2 //table_name2不能等于 table_name
where search_condition
表中数据的复制
-- mysql oracle
create table demotest AS
SELECT * from demo;
-- server sql
select column1,column2,...
into new_table //表不需要预先创建(与insert ... select ... 区别)
from table_name
where search_condition
数据更新和删除
update table_name set column1=value1,column2=value2 ... where search_condition
--例如
update teacher set sal=sal+100 where tsex='女'
-- 子查询平均值不会受更新后的数值影响,一直采用更新前的数值计算平均值。
update teacher set sal = sal+sal*0.05 where tsex = '男'
and sal < (select avg(sal) from teacher where tsex = '男')
-- 用join 替换条件语句中in 连避免嵌套子查询
UPDATE operation o
JOIN (SELECT o.id,
o.status
FROM operation o
WHERE o.group = 123
AND o.status NOT IN ( 'done' )
ORDER BY o.parent,
o.id
LIMIT 1) t
ON o.id = t.id
SET status = 'applying'
1.分布更新表的时候,注意执行顺序。要不一条数据可能会执行多次更新。
2.子查询如果是同一个表的时候,函数计算的值用的是旧值,而不是更新后的值。
delete from table_name where search_condition
-- 清空表数据(不能用于有外键依赖,慎用)
truncate table demotest //快的原因是不会更新事务处理日志。不能rollback。
安全性控制
授权ID
- 用户ID:一个个人的安全账户。大部分数据库采用提供用户名和口令的方法来标识和签别用户ID。
- 角色:一个定义的权限集。可以分配给用户,也可以分配给角色。
角色管理(GRANT)
create role MyRole identified mima; --创建角色
drop role role_name --删除角色
-- with 允许被授权的用户将指定的系统特权给其他用户或角色
grant role_name,role_name,... to user|role|public [with admin option]
grant MyRole to rainbow with admin option --授予角色
revoke [admin option for] role_name,... from user|role|public
-- 授予权限
grant object_privillege(增删改查)|All on schema.object(库或表) to user|role|public
grant select,insert,update,delete on demoTable to rainbow with grant option --授权
-- 取消授权 [grant]是取消把权限给别人,自己权限没有取消
revoke [grant option for] object_privillege|ALL on schema.object
from user|role|public restuict(传递过的权限不被取消)|cascade(传递的其他用户一并取消)
revoke insert on demoTablbe from rainbow --收回用户插入权限
Oracle安全管理
oracle对资源的管理是通过概要文件(profile)来实现的。
概要文件:一个资源限制的集合,也被称为资源配置文件。
模式:某个用户所拥有的所有对象的集合,如表、索引、触发器、存储过程等。(可以理解用户==模式)
oracle用户管理
口令验证:概要文件实现口令管理功能。(口令使用权、口令历史)
| 参数 | 含义 | 功能描述 |
|---|---|---|
| failed_login_attempts | 登录失败次数 | 用户连续登录失败超过了所设置的次数,系统将锁定用户账户 |
| password_lock_time | 锁定时间 | 用户账户被锁定的时间长短 |
| password_grace_time | 口令宽限期 | 口令有效期结束后,允许用户更改密码的时间。超过时间仍未更改,锁定账户 |
| password_life_time | 口令有效期 | 口令存在多长时间。到时间后,登录时将提示用户更改口令 |
| password_reuse_max | 口令重用次数 | 用户想要重新使用某个口令时中间必须经历的口令更改次数 |
| password_reuse_time | 口令重用时间 | 用户想要重新使用某个口令时必须等待的最少时间 |
| password_verify_function | 复杂性校验函数 | 参数使用某个PL/SQL程序校验口令是否满足一定的复杂度标准 |
-- 更改概要文件
alter profile pro_gsc limit failed_login 4 password_lock_time 10 ...
-- 创建用户
create user "rainbow" profile "default"
identified by "rainbow" default tablespace "users" account unlock
/*【系统权限】选项卡的配置*/
grant create any table to "rainbow" with admin option
/*【对象权限】选项卡的配置*/
grant "connect角色" to "rainbow" with admin option
-- 更改用户
alter user "rainbow" identified by "000000"
--删除用户
drop user rainbow cascade
外部验证
全局验证
资源管理
create profile profile_GSC limit
sessions_per_user 5 /*每个用户最多并发会话数为5*/
cpu_per_session unlimited /*会话期间所允许的总的cpu执行时间不受限*/
idle_time 20 /*会话期间所允许的空闲时间最多为20分*/
connect_time 200 /*用户每次会话与数据库的连接时间最长200分*/
cpu_per_call 800 /*每次语句执行期间允许的总的cpu执行时间为8秒*/
-- 启动概要文件生效
alter system set resource_limit = true; //false停用概要文件,不实施资源限制
-- 查看
select * from user_resource_limits
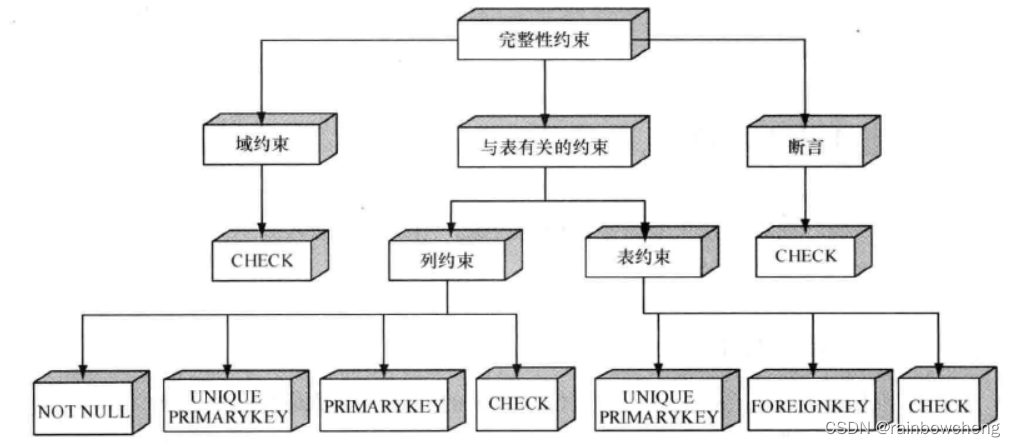
完整性控制
sql 数据库不只存储数据,还必须保证所存储的数据是正确的。数据完整性分为以下四类:实体完整性、域完整性、参照完整性、用户定义的完整性。
create table demo ( id int,salary decimal(5,2),bank_account char(8),
constraint ValidSal check(id in(1,2,3,4) and (salary>=800 and salary<=5000))
)
check约束:用于检查字段值所允许的范围(如:0~100)。可以定义表约束、列、域或者断言中。
- column datetype check(search condition)
- constratnt name check (search condition)创建约束
外键:当表的多列外键约束,如果任何一列为null,约束失效。
域约束与断言
域约束和断言只能使用check约束。
域与域约束domain
域是列中合法数据值的集合。需要绑定
create domain name as datatype [ default value ] [ constraint name] chieck(value condtion expression)
create `domain` valid_no as int constraint c_no check (value between 100 and 999)
create table demo ( id valid_no)
断言assertion
与域相似,断言也是一种数据库对象,但它不必与特殊的列绑定,因此必须独立创建断言。
create assertion name check search condition
--emp_sal表对应员工表emp中姓名不能null。就是子表中外键id只能存主表名字不能空的ID。
create assertion name_constr check(emp_sal.emp_id in(select id from emp where name is not null))
存储过程与函数
函数和过程都是预定义的sql语句,能执行一定的操作。
create procedure name; create function name;
create procedure usp_select_teacher @departName char(10),
@avg_age int output,@max_age int output
as
select @max_age = max(age) from teacher where dname=@departName
select @avg_age = avg(age) from teacher where dname=@departName
if @avg_age <=30
select '年龄结构'='年龄结构偏年轻','平均年龄' = @avg_age
if @avg_age >30 and @avg_age <=40
select '年龄结构'='年龄结构合理','平均年龄' = @avg_age
if @avg_age >40
select '年龄结构'='年龄结构偏大','平均年龄' = @avg_age
-- 执行
execute usp_select_teacher '计算机' ,@avg_age output,@max_age output
-- 年龄结构 | 平均年龄
-- 年龄结构合理 | 40
select @avg_age,@max_age
-- 40 | 46
存储过程的优点:
- 允许组件式编程。可以在程序中多次调用而不必重新编写该存储过程的sql语句,提高了可移植性。
- 实现较快的执行速度。如果操作包含大量的sql代码,或分别被多次执行,使用存储过程能够提高执行速度。
- 减少网络流量。网络传送只是方法名而不是多条sql语句。
- 存储过程可作为一种安全机制。
控制语句
begin … end ; if … else ; while ; break ; continue ; goto label ; return ; waitfor(定义某天中立的一个时刻,执行一个语句块) ; print
declare:定义局部变量。declare @varName datatype ; select @varName=min(mark) from ;
@@error 是全局变量。
waitfor {dealy time | time time} waitfor time ‘22:20’ 晚上10点20分执行
SQL触发器
触发器是一种特殊的存储过程,它在表的数据变化时发生作用。触发器可以维护数据完整性。(不能接收参数)通过insert、update、delete来触发。
SQL中游标的使用
事务控制与并发处理
当多用户同时访问或修改同一数据表时,可能造成由于一个用户的行为结果导致另一个用户使用的数据无效。
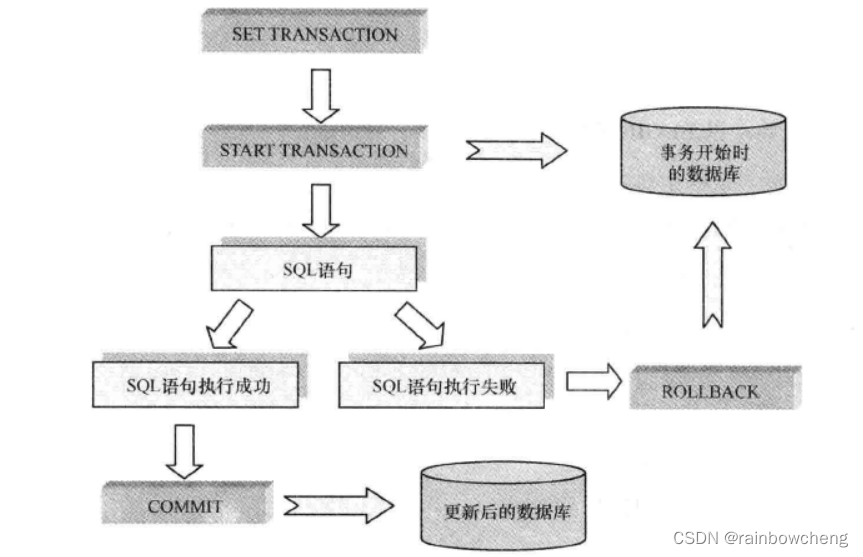
SQL事务控制
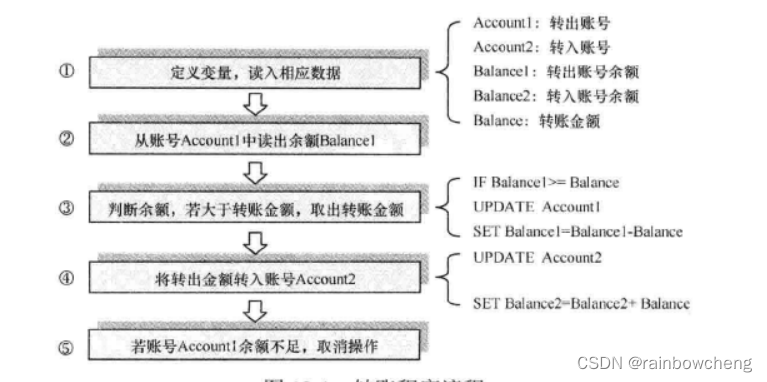
要么都执行,要么都不执行。
ACID:atomic原子性、consestent一致性、isolated隔离性、durable永久性
并发控制
1.数据丢失
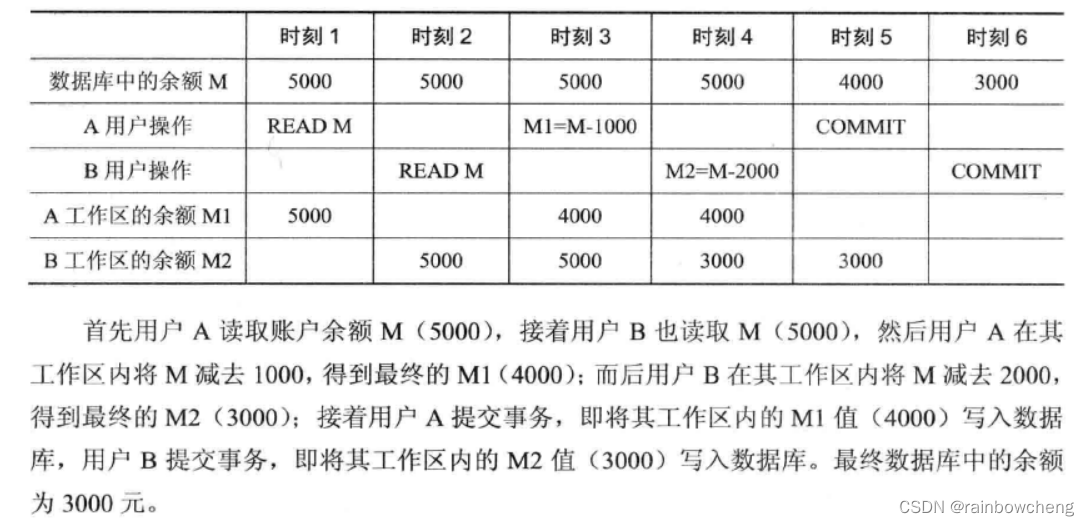
2.未提交的数据读取(错读)
3.不一致的读(不可重复读)
在一段时间内,读取结果要保存一致
4.幻影读(假读)
事务两次读取一样的操作,结果不一样。通过set transaction设置隔离,事务与事务之间的隔离性。
事务隔离级别
多用户环境中保证每个用户都在一人专用数据库的目的,同时仍然让尽量多的用户同时访问数据库中的数据。
- 未提交的读取:read uncommitted 级别最低,上面4个问题都可能发生。
- 提交读取:read committed 只解决错读,不能解决幻读、不可重复读。
- 可重复读取:repeatable read 会影响效能,慎用
- 可串行化:serializable 指将事务以一种顺序方式连接起来,防止一个事务影响其他事务。

锁的分类
行row、索引key、页page、盘区extent、表table、库tadabase等锁定对象
数据库角度:
| 锁分类 | 实现功能 |
|---|---|
| 共享锁 shared lock | 共享锁锁定的资源可以被其他用户读取,但不能修改(默认select执行)。一般情况下,加共享锁的数据页被读取完毕后,共享锁就会立即被释放 |
| 独占锁 Exclusive | 独占锁锁定的资源只允许进行锁定操作的程序使用,对它的任何其他操作均不会被接受。但当对象上有其他锁存在时,无法对其加独占锁。 |
| 更新锁 Update | 是为了防止死锁而设立的。准备更新数据时,首先对数据对象作更新锁锁定,这样数据不能修改,但可以读取。等到进行更新操作时,自动将更新锁换为独占锁。 |
程序员角度:
| 锁的分类 | 实现功能 |
|---|---|
| 乐观锁 | 在处理数据时,不需要应用程序的代码中做任何事情就可以直接在记录上加锁,完全依靠数据库来管理锁的工作。 |
| 悲观锁 | 不采用数据库系统的自动管理,需要程序员直接管理数据或对象上的加锁处理。 |
防止死锁:
- 尽量避免并发执行涉及到修改数据的语句
- 要求每个事务一次就将所有要使用的数据全部加锁,否则就不予执行。
- 预定一个封锁顺序,所有的事务都必须按这个顺序对数据执行封锁。
- 每个事务的执行时间不可太长,对程序段长的事务可考虑将其分割为几个事务。
select * from demo where id=4 for update
嵌入式SQL
将sql语句嵌入宿主语言中来使用。
- 由DBMS的预处理程序对源程序进行扫描,识别出sql语句
- 把识别出的sql语句转换成主语言调用语句,以使主语言编译程序能识别它
- 由主语言的编译程序将整个源代码编译成目标码
总结
- 尽量使用内连接替换IN等相关子查询。
- 聚集函数比all效率高
管理命令
---------------------------------常见的binlog命令-----------------------------------------
| 说明 | 语句 |
|---|---|
| 是否启用binlog日志 | show variables like ‘log_bin’; |
| 查看binlog类型 | show global variables like ‘binlog_format’; |
| 查看详细的日志配置信息 | show global variables like ‘%log%’; |
| mysql数据存储目录 | show variables like ‘%dir%’; |
| 查看binlog的目录 | show global variables like “%log_bin%”; |
| 查看当前服务器使用的biglog文件及大小 | show binary logs; |
| 查看最新一个binlog日志文件名称和Position | show master status; |
| 查询binlog 变动信息 | show binlog events; |
| 查看某个用户权限 | show grants for ‘canal’@‘%’; |
| 查看用户 | select Host,User from user; |
| 查看当前会话时区 | SELECT @ @session.time_zone ; |
| 设置当前会话时区 | SET time_zone = ‘Europe/Helsinki’ ; SET time_zone = “+00:00” ; |
| 数据库全局时区设置 | SELECT @ @global.time_zone ; |
| 设置全局时区 | SET GLOBAL time_zone = ‘+8:00’ ; SET GLOBAL time_zone = ‘Europe/Helsinki’ ; |
授权 : GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON . TO ‘canal’@‘%’ IDENTIFIED BY ‘canal’ ; 或 GRANT ALL PRIVILEGES ON 数据库名.* TO ‘supplier’@‘%’ IDENTIFIED BY ‘密码’ WITH GRANT OPTION;
FLUSH PRIVILEGES;
用户 :CREATE USER ‘supplier’@‘172.25.27.60’ IDENTIFIED BY ‘supplier2019’;
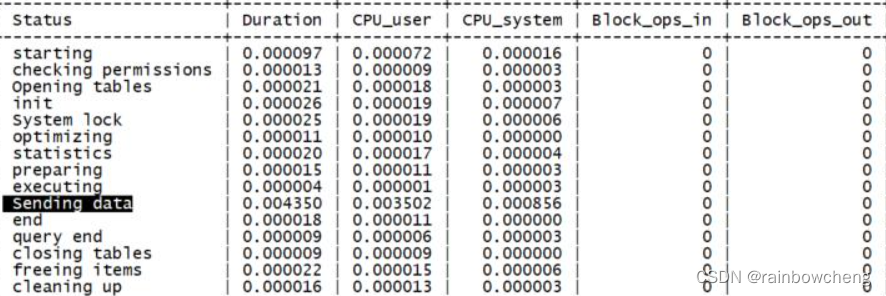
profile详细信息 查看语句性能
mysql> set profiling =1;
mysql> show profiles\G;
mysql> show profile cpu,block io for query 1;
常用命令语法
| 命令 | 语法 | 说明 |
|---|---|---|
| alter database | database_name | 改变数据库的大小或设置 |
| alter user | user_name | 改变用户的系统设置,如口令 |
| alter table | alter table demo add ‘name’ int null comment ‘备注’ after ‘colName’ | 增加列(drop-删除) |
| create database | database_name | 创建数据库 |
| create index | 创建索引 | |
| create procedure | 创建存储过程 | |
| create table | 创建表 | |
| create trigger | 创建触发器 | |
| create user | 创建账号 | |
| create view | 创建视图 |
CREATE TABLE `tpm_order` (
`id` varchar(32) NOT NULL COMMENT '主键id',
`corp_id` int(11) NOT NULL AUTO_INCREMENT,
`order_code` varchar(32) NOT NULL COMMENT '订单号(WX+yyyyMMddHHmmss+6位数字(id号,不足补零))',
`item_info` mediumtext NOT NULL COMMENT '订单明细商品名称+id,不用于展示,用于搜索,JSON格式',
`offline_stores_id` varchar(32) DEFAULT '' COMMENT '受理门店id',
`user_id` varchar(32) NOT NULL DEFAULT '' COMMENT '用户ID',
`nickname` varchar(50) DEFAULT '' COMMENT '用户昵称',
`user_name` varchar(100) DEFAULT NULL COMMENT '收货人/报修人',
`mobile_phone` varchar(20) DEFAULT NULL COMMENT '电话',
`state_code` int(11) DEFAULT NULL COMMENT '省编码',
`city_code` int(11) DEFAULT NULL COMMENT '市编码',
`ditrict_code` int(11) DEFAULT NULL COMMENT '区编码',
`address` varchar(500) DEFAULT NULL COMMENT '详细地址',
`appointment_time` datetime NOT NULL COMMENT '预约时间',
`appointment_end_time` datetime NOT NULL COMMENT '预约结束时间',
`payment_type` tinyint(4) DEFAULT '1' COMMENT '支付类型,1微信,9线下',
`order_type` tinyint(4) DEFAULT '1' COMMENT '订单的类型:1 清洗,2 维修,3 安装',
`order_fee` decimal(10,2) NOT NULL DEFAULT '0.00' COMMENT '订单价格',
`pay_amount` decimal(10,2) NOT NULL DEFAULT '0.00' COMMENT '支付金额',
`pay_time` datetime DEFAULT NULL COMMENT '支付时间',
`status` tinyint(4) DEFAULT '10' COMMENT '状态,10待付款/待接单,11已付定金,12待付尾款,20待发货/已派单,21待收货/待上门,22待完成,30已到货/待支付,40已完成,90取消',
`refund_status` tinyint(4) DEFAULT '0' COMMENT '退款状态,0未申请,1申请中,11审核拒绝,20已退款',
`evaluation_status` tinyint(4) DEFAULT '0' COMMENT '评价状态,0待评价,1已评价,2已追评',
`product_count` int(11) NOT NULL COMMENT '商品总数量',
`express_fee` decimal(10,2) NOT NULL DEFAULT '0.00' COMMENT '快递费用',
`express_code` varchar(10) DEFAULT NULL COMMENT '快递代码',
`express_no` varchar(100) DEFAULT NULL COMMENT '快递号',
`send_time` datetime DEFAULT NULL COMMENT '发货时间/派单时间',
`img_info` mediumtext NOT NULL COMMENT '图片补充说明,JSON格式',
`remark` varchar(500) DEFAULT '' COMMENT '备注',
`create_by` varchar(32) DEFAULT '' COMMENT '创建人',
`create_time` datetime DEFAULT NULL COMMENT '创建时间/下单时间',
`update_by` varchar(32) DEFAULT '' COMMENT '更新人',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`del_flag` tinyint(1) DEFAULT '0' COMMENT '删除状态(0-正常,1-已删除)',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表';
-
CREATE USER ‘supplier’@‘172.25.27.60’ IDENTIFIED BY ‘supplier20’;
-
grant select,delete,update,INSERT on 数据库名.* to ‘supplier’@‘172.25.27.60’;
或
GRANT ALL PRIVILEGES ON 数据库名.* TO ‘supplier’@‘%’ IDENTIFIED BY ‘密码’ WITH GRANT OPTION; -
FLUSH PRIVILEGES;
-
SHOW GRANTS FOR ‘supplier’@‘172.25.27.60’;
-
show variables like ‘%character%’;
-
show variables like ‘lower%’;
-
查看当前会话时区 SELECT @ @session.time_zone ;
-
设置当前会话时区 SET time_zone = ‘Europe/Helsinki’ ; SET time_zone = “+00:00” ;
-
数据库全局时区设置 SELECT @ @global.time_zone ;
-
设置全局时区 SET GLOBAL time_zone = ‘+8:00’ ; SET GLOBAL time_zone = ‘Europe/Helsinki’ ;
profile详细信息 查看语句性能
> set profiling =1 ;
>select 语句;
>show profiles\G
>show profile CPU,BLOCK IO for query 1;
`
















 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











