




 本文深入探讨了JDK1.7及以前版本中HashMap的工作原理,包括其数据结构、插入操作及线程安全性问题。
本文深入探讨了JDK1.7及以前版本中HashMap的工作原理,包括其数据结构、插入操作及线程安全性问题。
1. 前言
能用图说清楚的,就坚决不用代码。能用代码撸清楚的,就坚决不写解释(不是不写注释哦)。
以下所有仅针对JDK 1.7及之前中的HashMap。
2. 数据结构
HashMap内部通过维护一个Entry<K, V>数组(变量为table),来实现其基本功能,而Entry<K, V>是HashMap的内部类,其主要作用便是存储键值对,其数据结构大致如下图所示。
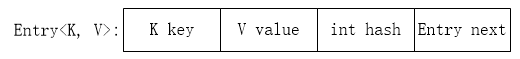
从Entry的数据结构可以看出,多个Entry是可以形成一个单向链表的,HashMap中维护的Entry<K, V>数组(之后简称为Entry数组,或table,容易区分)其实就是存储的一系列Entry<K, V>链表的表头。那么HashMap中存储数据table数组的数据结构,大致可以如下图所示(假设只有部分数据)。
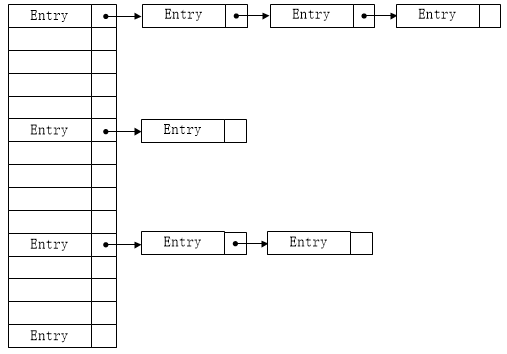
注:Entry数组的默认长度为16,负载因子为0.75。
将上图中的每一行,称为桶(bucket),那么table的索引便是bucketIndex。而HashMap中的插入、获取、删除等操作最主要的便是对table和桶(bucket)的操作。下面将主要通过插入操作,看其数据结构的变化。
3. 插入
对于上图中的数据结构,插入操作便是将要插入的键 - 值(key - value)对根据key计算hash值来选择具体的存储位置。
插入函数的源码如下(以Mark开头的或者中文注释,非JDK源码中的注释,下同):
public V put(K key, V value) {
// Mark A Begin
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
// Mark A End
int hash = hash(key); // 计算hash值
int i = indexFor(hash, table.length); // 计算桶的位置索引(bucketIndex)
// Mark B begin
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// Mark B end
modCount++; // 记录修改次数,迭代的时候会据此判断是否有被修改
addEntry(hash, key, value, i);
return null;
}在上面的代码中,代码段A(Mark A Begin - Mark A End,下同)的主要作用是如果table为空则初始化数组以及插入key为null时的操作,代码段B则是插入相同key时覆盖原有的值,并返回原有的值。这里重点关注的是addEntry(hash, key, value, i)方法。
addEntry方法源码如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩充table数组的大小
resize(2 * table.length);
// 重新计算hash值
hash = (null != key) ? hash(key) : 0;
// 重新计算桶的位置索引
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}createEntry方法源码如下:
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 将新的Enrty元素插入到对应桶的表头
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}Entry<>实例化的源码如下:
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n; // 将原先桶的表头向后移动
key = k;
hash = h;
}在整个插入操作中,有一个很重要的操作,便是对table数组扩容,扩容的算法相对简单,但是在多线程下它却容易引发一个线程安全的问题。
注:扩容需要会把原先table中的值移动到新的数组中,再赋值给table变量,一个合适的初始大小和负载因子能够提高效率。
4. 线程不安全
在多线程环境下,假设有容器map,其存储的情况如下图所示(淡蓝色为已有数据)。

此时的map已经达到了扩容阈值12(16 * 0.75 = 12),而此时线程A与线程B同时对map容器进行插入操作,那么都需要扩容。此时可能出现的情况如下:线程A与线程B都进行了扩容,此时便有两个新的table,那么再赋值给原先的table变量时,便会出现其中一个newTable会被覆盖,假如线程B扩容的newTable覆盖了线程A扩容的newTable,并且是在A已经执行了插入操作之后,那么就会出现线程A的插入失效问题,也即是如下图中的两个table只能有一个会最后存在,而其中一个插入的值会被舍弃的问题。
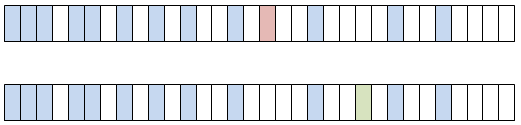
这便是HashMap的线程不安全性,当然这只是其中的一点。而要消除这种隐患,则可以加锁或使用HashTable和ConcurrentHashMap这样的线程安全类,但是HashTable不被建议使用,推荐使用ConcurrentHashMap容器。

















 1729
1729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









