







 本文是一个基础教程,讲解如何手动优化神经网络模型,包括二值分类感知器和多层感知器。通过随机爬山算法进行权重优化,展示神经网络的训练过程和优化的重要性。在训练数据集上,优化后的感知器模型达到88.5%的准确率,多层感知器模型达到87.3%的准确率。
本文是一个基础教程,讲解如何手动优化神经网络模型,包括二值分类感知器和多层感知器。通过随机爬山算法进行权重优化,展示神经网络的训练过程和优化的重要性。在训练数据集上,优化后的感知器模型达到88.5%的准确率,多层感知器模型达到87.3%的准确率。

翻译:陈丹
校对:车前子
本文约5400字,建议阅读15分钟
本文是一个教授如何优化神经网络模型的基础教程,提供了具体的实战代码供读者学习和实践。
标签:神经网络优化
深度学习的神经网络是采用随机梯度下降优化算法对训练数据进行拟合。
利用误差反向传播算法对模型的权值进行更新。优化和权值更新算法的组合是经过仔细挑选的,是目前已知的最有效的拟合神经网络的方法。
然而,也可以使用交替优化算法将神经网络模型拟合到训练数据集。这是一个有用的练习,可以了解更多关于神经网络的是如何运转的,以及应用机器学习时优化的中心性。具有非常规模型结构和不可微分传递函数的神经网络,也可能需要它。
在本教程中,您将了解如何手动优化神经网络模型的权重。
完成本教程后,您将知道:
如何从头开始开发神经网络模型的正向推理通路。
如何优化二值分类感知器模型的权值。
如何利用随机爬山算法优化多层感知器模型的权值。
我们开始吧。

图源土地管理局,权利归其所有
教程概述
本教程分为三个部分:它们是:
优化神经网络
优化感知器模型
优化多层感知器
优化神经网络
深度学习或神经网络是一种灵活的机器学习。
它们是受大脑结构和功能的启发而来的,由节点和层次组成的模型。神经网络模型的工作原理是将给定的输入向量传播到一个或多个层,以产生可用于分类或回归预测建模的数值输出。
通过反复将模型暴露在输入和输出示例中,并调整权重以使模型输出相对于期望输出的误差最小来训练模型。这就是所谓的随机梯度下降优化算法。模型的权值是使用微积分中的一个特定规则来调整的,即将误差按比例分配给网络中的每个权重。这被称为反向传播算法。
利用反向传播进行权值更新的随机梯度下降优化算法是训练神经网络模型的最佳方法。然而,这并不是训练神经网络的唯一方法。
可以使用任意的优化算法来训练神经网络模型。
也就是说,我们可以定义一个神经网络模型结构,并使用给定的优化算法为模型找到一组权重,从而使预测误差最小或分类精度达到最大。
交替优化算法通常来说比反向传播的随机梯度下降算法效率更低。然而,在某些特定情况下,它可能更有效,例如非标准网络体系结构或不可微分的传递函数。
在训练机器学习的算法中,特别是神经网络中,展示优化的中心性是一个有趣的练习。
接下来,让我们探索如何使用随机爬山算法训练一个称为感知器模型的简单单节点神经网络。
优化感知器模型
感知器算法(https://machinelearningmastery.com/implement-perceptron-algorithm-scratch-python/)是最简单的人工神经网络。
它是一个单神经元模型,可用于两类分类问题,为以后开发更大的网络提供了基础。
在本节中,我们将优化感知器神经网络模型的权重。
首先,让我们定义一个综合二进制分类问题,我们可以用它作为优化模型的焦点。
我们可以使用make_classification()(https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html)函数定义一个包含1000行和5个输入变量的二分类问题。
下面的示例创建数据集并总结数据的形状。
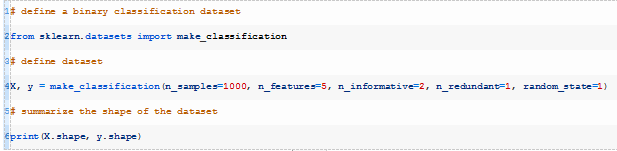
运行上述示例,打印出所创建数据集的形状,以确定符合我们的预期。

接下来,我们需要定义一个感知器模型。
感知器模型有一个节点,它对数据集中的每一列都有一个输入权重。
每个输入值乘以其相应的权重得到一个加权和,然后添加一个偏差权重,就像回归模型中的截距系数一样。这个加权和称为活性值。最后,对活性值进行解释并用于预测类标签,1表示正激活,0表示负激活。
在优化模型权重之前,我们必须建立模型并相信它的运作方式。
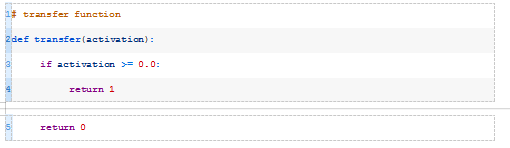
让我们从定义一个用于解释模型激活的函数开始。
这被称为激活函数,或传递函数;后一个名称更传统,是我的首选。
下面的transfer()函数接受模型的激活并返回一个类标签,class=1表示正激活或零激活,class=0表示负激活。这称为阶跃函数。
接下来,我们可以开发一个函数,该函数计算来自数据集的给定输入行的模型活性值。
此函数将获取模型的数据行和权重,并计算输入的加权和以及偏差权重。下面的activate()函数实现了这一点。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









