







来源:计量经济学服务中心
本文约2700字,建议阅读8分钟
本文为你介绍了因果推断书籍的代码合集。1、Causal Inference: The Mixtape
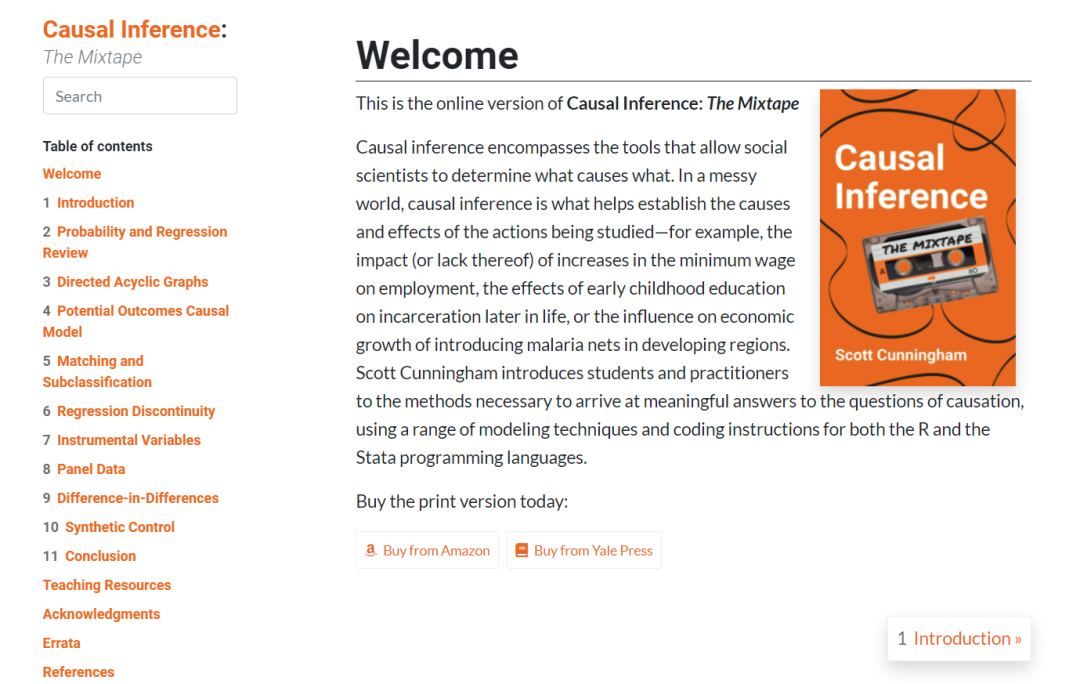
来源:
https://mixtape.scunning.com/index.html
简介
这是《Causal Inference: The Mixtape》的在线版本,因果推理包括一些工具,让社会科学家能够确定什么导致什么。在一个混乱的世界里,因果推理有助于确定所研究行为的因果关系——例如,提高最低工资对就业的影响(或缺乏影响),幼儿教育对以后生活中的监禁的影响,或者在发展中地区引进蚊帐对经济增长的影响。Scott Cunningham使用一系列建模技术和用于R和Stata编程语言的编码指令,向学生和实践者介绍了获得因果关系问题有意义答案的必要方法。
书籍目录
1介绍
2概率与回归回顾
3有向无环图
4潜在结果因果模型
5匹配与子分类
6断点回归
7工具变量
8面板数据
9双重差分
10合成控制
11结论
教学资源
致谢
勘误表
参考文献代码链接
为了方便大家学习,我们将相关代码fork到了码云仓库,大家可以在线收藏学习
https://gitee.com/econometric/causal--inference--the--mixtape
2、Causal Inference: What If

内容简介:本书由哈佛大学 Miguel Hernan、Jamie Robins 教授编著,对因果推理的概念和方法做了系统性阐述。该书在知乎等各大平台一直是呼声很高的书籍,众多计量学者期待已久,目前该书。
书籍开源地址:
https://www.hsph.harvard.edu/miguel-hernan/causal-inference-book/
下载地址:
https://cdn1.sph.harvard.edu/wp-content/uploads/sites/1268/2019/10/ci_hernanrobins_14oct19.pdf
代码链接
https://gitee.com/econometric/causal_inference_python_code
3、Mostly Harmless Econometrics


由Joshua D. Angrist和Jörn-Steffen Pischke合作撰写的计量经济学经典著作Mostly Harmless Econometrics: An Empiricist's Companion详细介绍了应用实证研究中的核心计量工具,为社会科学研究者提供了一份精炼的操作指南。
作者从因果关系及其识别的角度展开了本书的论述。对于社会科学研究者而言,其所关心的一个核心问题便是因果推论,即探讨某一事件产生的原因及其影响。这对于结果预测和政策制定都具有重要意义。那么,因果推论该如何进行呢?通常而言,利用观测数据对受某一事件影响的群体和未受该事件影响的群体进行比较是最直观的研究方法。然而,由于反事实的无法获得及选择性偏误(selection bias)的存在,上述影响并非真正的因果联系。在本书作者看来,要展开因果推论,随机实验是最具可信度、最有影响力的一种研究设计,并从数学推导和研究例证(如Tennessee STAR experiment)两方面为此提供了充分证据。
然而,随机实验耗时长、成本高、可能遭遇学术伦理问题,因此对大多数学者来说未必具有现实可操作性。为此,本书作者以随机实验为基准(benchmark),把目光转向了自然实验(natural experiment)及准自然实验(quasi-experiment)。利用自然实验及准自然实验进行因果推断,需要充分利用本书所关注的核心计量工具:多元回归分析、工具变量方法(IV)和双重差分策略(DID)。本书在第三章主要讨论了多元回归分析方法。这一方法主要是指在控制了其他与残差项不相关的变量之后,用被解释变量对核心解释变量进行回归分析。该方法对提高估计准确性并揭示可能的因果关系大有裨益,而且也是接下来讨论的IV、DID等工具之基础。IV在本书第四章得到讨论。尽管工具变量不易寻找,但一旦找到合适的工具变量之后,使用两阶段普通最小二乘法便可较为精准地获得因果联系。当然,工具变量方法并非万无一失,局部有效性(LATE)等问题也受到了作者高度关注。DID在本书第五章得到呈现。作为处理遗漏变量问题、进行因果推论的有效方法,双重差分同样备受作者重视。与此相关,作者还在本章中就固定效应及面板数据处理进行了细致分析。以上便是本书的核心内容。接下来本书还进行了一些拓展讨论,主要涉及断点回归分析、分位数回归分析及回归分析中的标准差处理。
值得一提的是,不同于一般的计量经济学教科书,本书具有如下几方面有必要说明的特点:首先,本书并不对各种计量方法进行面面俱到的介绍,而是主要讨论在实证操作中处于核心地位的几类方法,对基本概念和技术问题的强调也穿插于核心方法的介绍及操作例证的讲解之中;其次,一般的计量经济学教科书非常关注经典假设及其违反的情况,本书则对此保持更为宽容的态度,并未在此花费太多篇幅;最后,在回归结果的统计性质中,本书更重视无偏性与一致性,对有效性的关注相对较弱。

评价:

“Finally – An econometrics book for practitioners! Not only for students, Mostly Harmless Econometricsis a fantastic resource for anyone who does empirical work.” — Sandra Black, UCLA
“This is a remarkable book–it does the profession a great service by taking knowledge that is usually acquired over many years and distilling it in such a succinct manner.” — Amitabh Chandra, Harvard Kennedy School of Government
“MHE is a fantastic book that should be read cover-to-cover by any young applied micro economist. The book provides an excellent mix of statistical detail, econometric intuition and practical instruction. The topic coverage includes the bulk of econometric tools used in the vast majority of applied microeconomics. I wish there was an econometric textbook this well done when I was in graduate school.” — Bill Evans, University of Notre Dame
Mostly Harmless Replication
一个大胆的尝试,用以下语言复制了《无害计量经济学》一书中的表格和数字: Stata R Python Julia
为什么要这么疯狂呢?我的主要动机是看看我是否可以在我的工作流中用R、Python或Julia替换Stata,所以我尝试用这些语言复制大部分无害的计量经济学。
目录如下:
Questions about Questions
The Experimental Ideal
Making Regression Make Sense
Instrumental Variables in Action
Parallel Worlds
Getting a Little Jumpy
Quantile Regression
Nonstandard Standard Error Issues查看Wiki中的入门指南,了解使用每种语言设置机器的技巧。
代码链接:
https://gitee.com/econometric/mostly-harmless-replication
4、基本有用的计量经济学(MUSE)
简介 该书主要特色是利用潜在结果语言和因果图介绍各种识别策略。全书以随机化实验为基础,首先介绍了潜在结果和分配机制的概念,并利用潜在结果定义因果效应。然后介绍了随机化实验,一种特殊的分配机制,可以消除选择偏差,成为观测研究中各种识别策略的基础。所有的识别策略都是通过一定的设计模拟随机化实验,从而得到可信的因果效应估计。另外,作者还简要介绍了因果图方法,它是与潜在结果框架完全等价的因果模型,但是更加直观,容易使用。在这三个理论的基础上,本书介绍了线性回归、匹配方法、工具变量法、面板数据方法和断点回归设计等几种在观测研究中常用的因果效应识别策略。最后,对于每种识别策略,作者还利用具体实例讲解各策略在Stata软件中的实现。
代码链接:
https://gitee.com/econometric/causalinference
5、The Effect: An Introduction to Research Design and Causality

简介
这本书旨在向学生(和非学生)介绍在观察数据的背景下研究设计和因果关系的概念。这本书以一种直观和平易近人的方式编写,没有过多的技术细节。既然回归和研究设计是两种根本不同的东西,为什么要同时讲授呢?首先了解为什么要以某种方式构建设计,以及您想对数据做什么,然后了解如何运行适当模型的技术细节。
这本书由第一部分专门研究设计和因果关系,使用因果图使识别的概念直接,和第2部分专门实现和常见的研究设计,如回归与控制和断点。你可以在左边看到各个章节并在它们之间导航(如果你在一个小屏幕上,在顶部的下拉菜单中)。
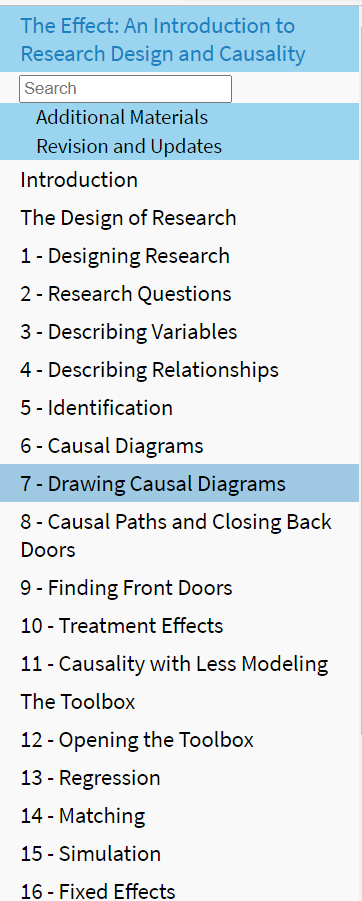

如果您想运行本书中的代码示例,您将需要causaldata包,它包含大多数代码块的示例数据。可以在R中使用install.packages(' Causaldata ')安装Causaldata,在Stata中使用ssc install causaldata,或者在Python中使用 pip install causaldata。
代码链接:
https://gitee.com/econometric/CausalitySlides
编辑:王菁
















 3006
3006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









