







来源:专知
本文为论文介绍,建议阅读5分钟
什么样的进一步优化途径能够在受限设备上部署和高效执行复杂且性能更好的模型?
经过十年机器学习(ML)不同领域的加速发展,在我们的日常生活中,几乎不可能不与ML驱动的应用和服务交互。推荐系统、计算摄影、语音翻译或导航只是我们的智能手机或其他智能设备(有时是电池供电的)可以完成的工作的一小部分例子,这些设备出现在我们生活、工作和社交的地方。然而,尽管在设备上运行这类应用有众所周知的好处(例如隐私、离线工作、实时潜力),但它们依赖于数百万(甚至数十亿!)的参数和日益复杂的执行模式,使它们无法离开进行模型推断的云。因此,只有一小部分由机器学习支持的应用(如关键字发现和下一个单词预测)在内存和计算占用方面足够轻量级,可以在设备上运行。
在迫切需要在商用设备上部署更先进的ml驱动应用程序的驱使下,研究界主要依赖三组技术来降低其运行时成本: 剪枝,通过丢弃模型参数,导致在推理过程中模型压缩和加速; 量化,通过用更少的比特表示参数来节省模型的大小,当使用较低的精度算法时,通常转化为更快的推理; 并且,通过使用轻量级网络架构设计,可以更好地映射到目标平台的硬件。然而,在许多情况下,上述技术不足以提供所需的计算、内存和节能,以在设备上运行大多数机器学习驱动的应用程序。什么样的进一步优化途径能够在受限设备上部署和高效执行复杂且性能更好的模型?
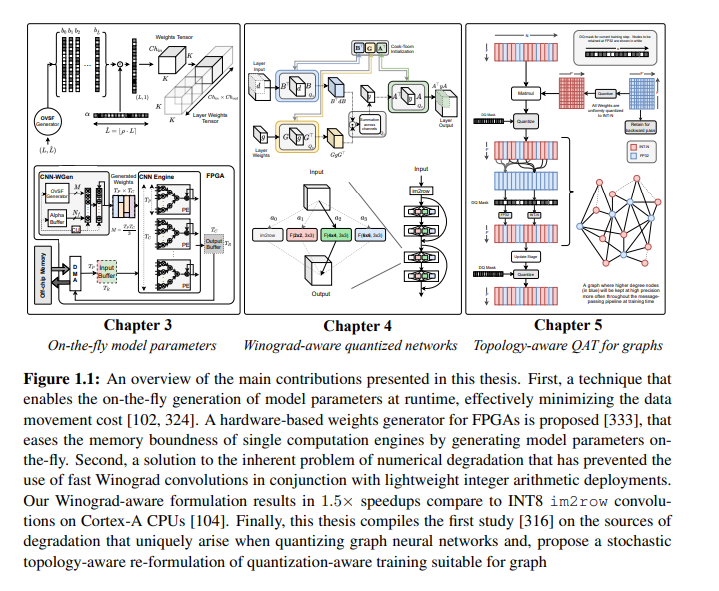
本文从三个不同的角度研究了这一具有挑战性的问题: 首先,通过识别动态生成模型参数的压缩框架的新范式,通过减少数据移动成本的影响实现推理加速;第二,解决了数值退化的固有问题,该问题阻碍了对使用整数算术的模型采用和部署快速Winograd卷积;第三,通过提出能够学习量化图神经网络的机制,以适应在不规则网格上运行的各种应用。这些贡献都体现在三个不同的框架中,即unzipFPGA、wiNAS和Degree-Quant,通过广泛的实验和消融研究对它们进行了全面评估。这些贡献在三个不同的方面推动了技术的发展,并可以与其他现有的加速技术结合使用,共同实现在资源受限设备上部署高性能深度学习应用。
https://ora.ox.ac.uk/objects/uuid:6ed40a29-614c-4207-a240-c107c16c8bd2






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









