







下文整理自清华大学大数据能力提升项目能力提升模块课程“Innovation & Entrepreneurship for Digital Economy”(数字经济创新创业课程)的精彩内容。
主讲嘉宾:
Kris Singh: CEO at SRII, Palo Alto, California
Visiting Professor of Tsinghua University
Yingbo Liu, Associate Research Fellow of School of Software, Tsinghua University
Pengcheng Zheng,Timecho
今天我们将分享两个来自清华软件学院的非常重要的项目。这两个项目都与数据有关,如何管理大量数据,如何创造数据价值。未来是数据经济时代,谁拥有最多的数据,谁能够挖掘数据价值,谁就是赢家。

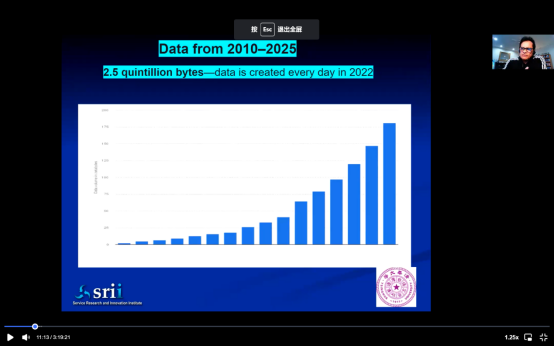
数据量呈现指数级增长,因为数字经济,现在万物皆可数字化。一切过程、系统和沟通都是通过数据来完成。上述图表展示了数据体量的爆炸性增长趋势。而大部分的数据是在近十年甚至是近五年之内形成的,所以根据这种趋势可以预测未来五年的情况。

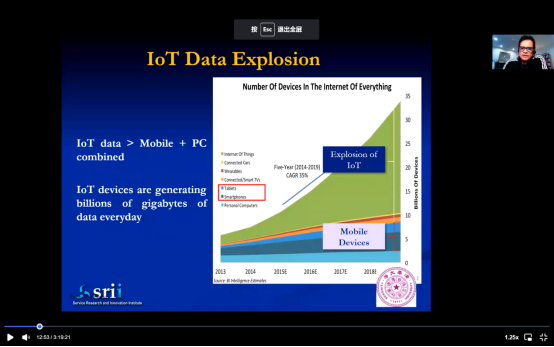
大部分数据来源从之前的计算机、到笔记本再到只能手机,而现在则来自于传感器IOT。传感器产生的数据比其余来源加起来还要多得多。在未来几年内将会有总量超过650亿传感器,其产生的数据量可想而知。


那么数据量是如何爆炸式增长的呢?我们从最开始的ERP企业管理系统,再到客户管理系统再到网络,再到所有其他的活动项目,因为我们所使用的技术和工具,数据量越来越庞大。你可能听说过大数据的5V,即体量(volume)、价值(value)、多样性(variety)、速度(velocity)、veracity(准确性)。数据体量庞大,数据的指数级增长已经超过了可控的范围,而体量大不足以让我们理解数据的价值,如何创造价值,如何理解数据的含义。数据多样性是指数据来源的多样性,数据是多种类型的混合。速度则是指数据运行有多快,可以用于理解我们的社会交往、智能手机和传感器的运行速度。最后一点是数据质量的多样性,数据真实程度以及有用性。数据符合二八定律,当我们处理数据时,只有20%的工作是真正用于数据分析,所以在分析数据之前,要先理解数据的含义。

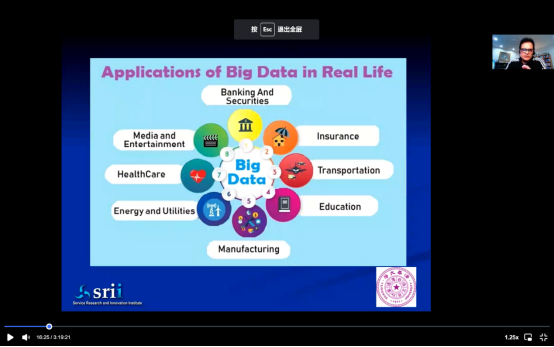
上述图表展示了数据并非特定于某一个部分,某一种行业或某一个地区,每一种行业都面临着机遇和挑战。数据不仅仅关乎医疗、电子商务,它涉及经济和商业的方方面面。数据是基础。你需要理解数据的价值,不同领域的数据有独特的含义、价值、技术和工具,但都需要处理大量的数据。


数据分为不同类型,有结构化数据、半结构化数据和无结构化数据。大部分数据都是结构化数据,结构化数据是我们经典的数据库,我们在IT系统当中理解并使用。但现在爆炸的社交媒体、手机和传感器里的数据大部分都是无结构化的,这也是我们最大的机遇和挑战。我们如何理解结构化数据、无结构化数据以及介于两者之中的半结构化数据呢?


数据分析不是新领域,它已经存在了将近60年时间。数字化数据始自60年代计算机刚出现的时候,网络也是在这一时期出现的。所以数据爆炸也是从这时开始的。首先是一个简单的数据库,然后是数据仓库,你学习如何将数据恢复到某个系统中,然后是数据挖掘。开始应用统计和其他一些技术和工具来帮助更好地理解。在过去的7年里,这个新的数据分析领域已经发展起来,处理所有新类型的数据。这也是我邀请英博和鹏程来讨论这一话题的原因。我们需要理解所有这些不同的数据源,最重要的是我们如何分析数据、如何创造数据的价值,仅仅拥有数据并不意味着什么,分析数据更重要,分析可以获取信息,信息可以帮助你采取行动,行动则可以创造价值。这是我们需要遵循的经典流程。


尝试描述和理解数据,捕获数据并实现其意义,之后再采取行动做出预测,我们能从数据中获得些信息,以便于以后不会再犯类似的错误或可以创造更好的价值,再进一步实现数据分析过程的优化。这就叫做数据成熟度。以下图片中展示了你们需要学习和使用的数据分析工具。Hadoop用于数据存储和分析,MangoDB用于变化频率高的数据集,Talend用于数据整合和管理,Cassandra用于分布式数据集,Spark用于实时加工和分析大体量数据。


数据分析和数据科学彼此相关,但是关注点不同。数据科学是在学校里学的课程,学习算法统计模型和代码,用知识来帮助你更好地理解数据。


下图展示了数据分析的10个主要趋势。AI对数据知识简化助力颇多,我们有了更好的工具和技术,可以帮助我们分析数据。但问题是数据过于碎片化,对于决策而言,其涵盖不同方面,如何在采取行动前从不同途经捕获数据,另外一点是混合云服务,我们无法将所有数据都存储在学校内,因为数据量过于庞大,所以我们使用云计算,现在是混合云服务,包括公共云和隐私云,每一种各有利弊。我们如何在两种云结构中处理好数据。万物始自数据,数据是整个学科的中心。谈论所有话题之前都要先学习理解该学科的数据。


接下来有请清华大学的Yingbo向大家介绍他们目前的项目。
——Chris


非常荣幸能向大家介绍我们目前的工作。今天我向大家介绍的是快速数据驱动的应用程序发展。其实大数据在今天并不是一个新的转折。我们中国有很多互联网行业的领导者,比如阿里巴巴、百度,他们是大数据的强势玩家。而且大部分都是面向消费者的。不过,如果仔细看看中国经济,可能会发现,还有一些主要行业仍然在追不上大数据的潮流,例如制造业建筑运输等。而今天这些行业正面临两大挑战,第一是从需求方面,行业仍然缺乏对先进的大数据应用程序有深刻理解的人才,如果我们回头看看我们今天提供的技术,也不足以让他们解决他们的具体问题。然而,大数据有许多新的重点领域,如人工智能机器学习和数据科学等,所以我们希望我们正在做的是面向主要经济部门的技术和应用创新。基于这一使命,我们清华大学还成立了“大数据研究中心”,而这些研究中心是基于两个由国家发改委支持成立的研究中心。

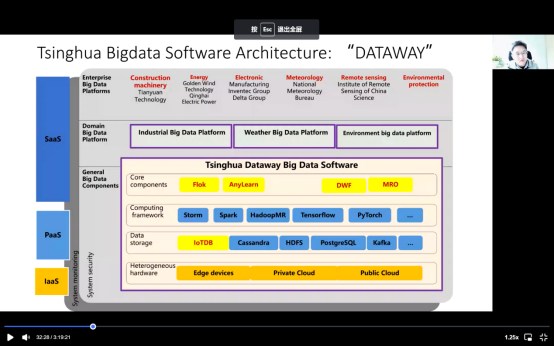
我们有三个主要研究方向,第一个是数据库技术,最具代表性的是IOTDB。第二个是数据分析,包括Flok和Anylearn。第三个方向是数据vacation开发包括dataway框架,我将在接下来几分钟向大家介绍。
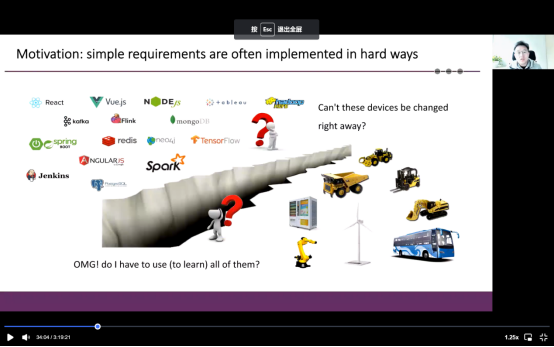
 我们开发dataway框架的动机是因为在中国我们发现有很多传统行业在尝试数字化,但这些行业总是受到现实世界的限制。对于工程机械来说,它的增长速度是受到材料技术发展和一些现实问题的限制。但如果在另一边我们可以看看左边,会发现我们也见过被世界公认的著名项目包括 mongoDB,Tensor Flow和最古老的东西。传统工业和数字化之间存在着巨大的差距,左侧的软件可以迅速地更新迭代,但不幸的是,在另一边,他们发现必须全部使用它们或全部学习它们。一个简单的要求经常以艰难的方式实施。
我们开发dataway框架的动机是因为在中国我们发现有很多传统行业在尝试数字化,但这些行业总是受到现实世界的限制。对于工程机械来说,它的增长速度是受到材料技术发展和一些现实问题的限制。但如果在另一边我们可以看看左边,会发现我们也见过被世界公认的著名项目包括 mongoDB,Tensor Flow和最古老的东西。传统工业和数字化之间存在着巨大的差距,左侧的软件可以迅速地更新迭代,但不幸的是,在另一边,他们发现必须全部使用它们或全部学习它们。一个简单的要求经常以艰难的方式实施。


在中国,我们也面临诸多挑战,工具太过笨重,人才价格昂贵,企业缺乏现成的应用程序,因为IT行业快速发展,新的需求无法第一时间得到满足。结果是薄弱的,数字化转型的增长预期与工业内部的开发规则之间存在矛盾。

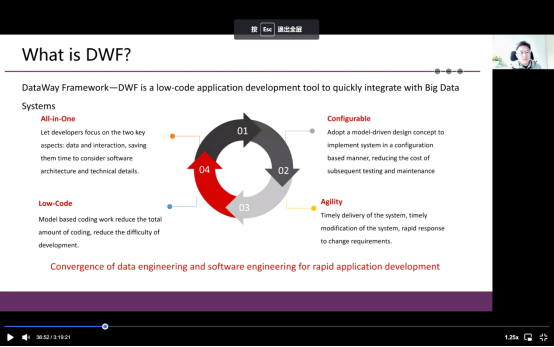
因此,基于这种演变,我们希望改变我们只想专注于大数据的想法,我们必须做一些大数据的应用程序开发工具。我们定义了开发环节的四个指标,第一个是一体化,开发人员关注两个重要方面:数据和交互,节约时间来考虑软件架构和技术细节。第二点是高度整合性,我们采用了一个模型驱动的设计概念来推行基于整合行为的系统,减少后续测试和维护的成本。第三点是敏感性,系统适时交付、适时修改、对改变需求及时响应。最后一点是少代码化。基于模型的代码减少代码总量,降低开发难度。Dataway 架构与传统架构不同之处在于,更关注应用程序。

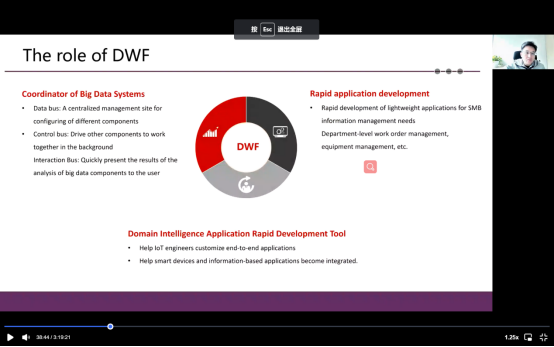
基于数据框架,它通常用于三个主要场景。第一个是大数据系统协作,我们都知道大数据系统非常复杂,我们不能要求每个人都成为程序员去使用它,而使用dataway 框架就可以实现用户与数据的交互。另外一个是快速应用开发,为了给中小企业检验新的想法是否可行。最后一个是智能应用程序快速开发工具。该工具整合了IOT和AI。以上关于大数据的内容,接下来我会展示一个例子。Dataway 框架有两个主要的部分,第一个是现代工具,包括一个数据模型、形成模型、功能模型、组织模型和授权模型。数据整合也是现代管理。这是一种模型驱动的编辑工具。另外一个是解释模型的应用程序,最终用于用户教育。对于前者来说,如果我们从简单的教育开始,比如一个Excel表格文件,dataway框架的数据会自动分析表格内容,并迅速创建模型。
——YingBo


感谢Kris对大数据现状的介绍,而我们所做的正是管理大数据。今天我想跟大家分享的是清华大学开发的IOTDB项目,这是目前世界上顶尖的开源项目。


首先,我将向大家介绍什么是时序数据。时序是在特定时间点序列采集的标准化记录,占据了80%的数据席位。时序数据随处可见,渗透到工业和人类活动的方方面面。实际上,时序数据在几年前的工业革新关键基础设施中就已经为人所知。通用电气早在十年前就已经强调了时序数据的重要性。
电力行业也有一些场景显露出时序数据管理的重要。从传统角度来看,我们有一些不错的去中心化控制系统用于管理实时数据,但现在我们需要的不仅是堆积如山的实时数据,还有历史数据的管理。例如,变电站和能源发电站已经变得越来越需求导向,对于实时数据,我们可以进行远程监控和远程操作,但是如果我们有一批历史数据,我们就有更多的事可以做。可以做机器的数字配置文以评估机器健康状况,如果有机器备件,我们也可以在变电站出现设备失灵的情况之前及时进行调拨。再者,如果我们拥有全生命过程数据,我们可以尝试改善生产或发电流程。


过去几年,我们曾经使用DCS系统,但现在我们不仅在数据中心的工厂,而且在设备中部署软件。我们的管理容量也从十年或二十年前的几万个数据点到几千万个数据点。以前我们可能只需存储百分之一到百分之十的数据,现在为了更多的分析,我们可能需要存储所有的数据。近几年有一个非常火的新词叫做”边缘到云同步”(edge-to-cloud synchronization),它也要求为数据处理更好地管理数据。

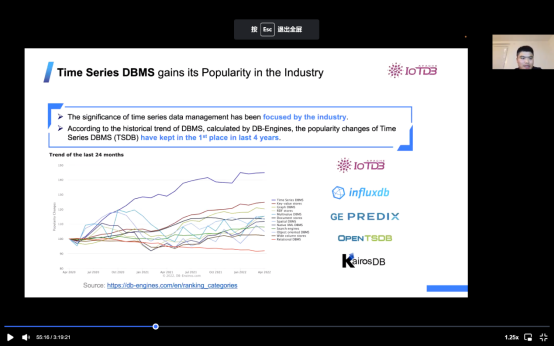
上图是使用DB-engines生成的图表,它表明,时序数据的重要性在最近一段时间内已经引起了业界的关注。数据库还是数据库管理系统有很多种,例如传统的关系数据库或键值数据库,但现在我们有一个非常热门的时序数据库,例如Influxdb和GE PREDIX以及KairosDB等是分布式非关系型数据库。


下面我将介绍的是Apache IOTDB。你可能会疑惑,为什么已经有这么多种类型的数据库,还要再开发新的呢?那是因为许多数据库有自身缺陷,例如关系型数据库,目前用于90%的系统,但是其模型数量有限,不能储存大量数据,如果我们有一个表格,表格只能设置1000列和1000万行以内的数据。另一种类型是键值数据库,它的缺陷也是数据存储量限制。例如MangoDB对管理大数据表现很差。也有一些时序数据库,但是其中大部分也是基于关系型数据库或键值数据库管理系统。而IOTDB则解决了上述缺陷。它是在十年前由清华大学团队打造的新型数据库,于2018年11月进入捐赠给Apache,进行了为期1年10个月的孵化,两年后成为世界顶尖的项目,并荣获了许多奖项。


IOTDB是一个IOT native数据管理系统,IOT native意味着专门针对IOT场景使用,非常轻便易用,并且能够深度整合进入大数据生态系统的软件。例如Apache PLC4X。物联网旨在解决典型物联网用例的痛点,例如海量数据生成和高频采样。这是 Apache IOTDB 的架构。我们可以从图片中看到,有两个部分实际上是一个文件层和引擎层。ts文件是优化了记录数据的文件格式,它将被上传到IOTDB服务器。而Grafana连接器是可视化的仪表板。对于与大数据系统的集成,有许多连接器。

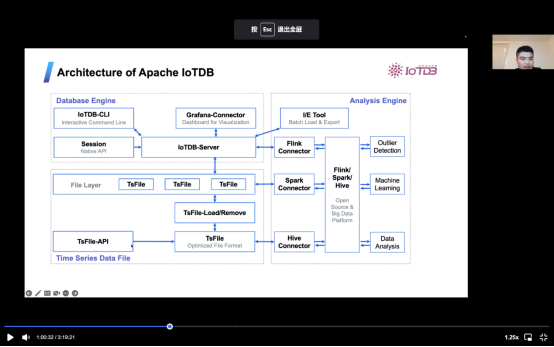
IOTDB有许多特点。例如,它的跨平台部署能力强。它是一个开源的,有一个非常广泛的生态系统。而且其特有的数据格式ts文件具有非常高的压缩率,可以节省大量存储空间。


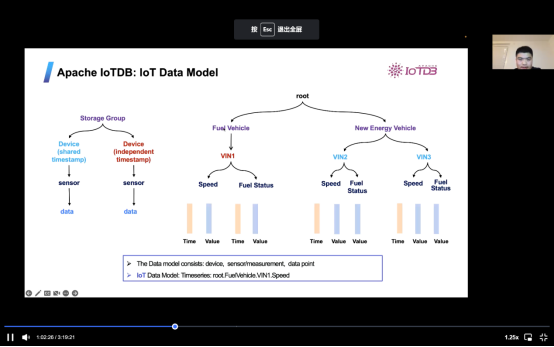
IOTDB拥有大量的数据模型。以车辆数据为例,燃油车辆可以有一个唯一的ID,它的速度或燃油状态将单独存储,而不在这里的可以随时根据需要扩展。对ts文件来说,有很多不同数据类型,可以随时根据需要存储。

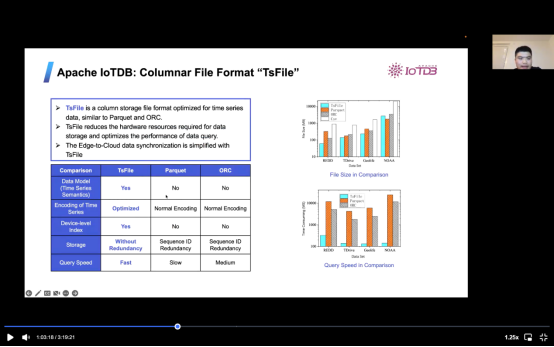
目前有两种非常流行的文件格式Parquet和ORC。Ts文件与之相类似性能却优于两者。不仅有多种数据模型,其时序编码也是优化的。除此之外,它还有设备水平指数,这在我们导入数据的时候可以获得更多关于数据本身的信息。通常,如果我们想从边缘设备(例如我们的手机)或从车辆上传数据到云,我们需要有两个过程,首先我们需要对数据进行编码,然后上传包。而云必须解码数据并做进一步的处理。但是对于 T S 文件,T S 文件本身可以只上传到云或数据中心,可以只导入数据,这样我们可以节省大量的时间和计算资源。

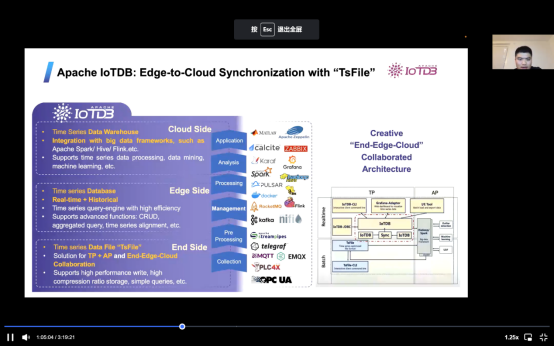
简单介绍一下边云协同。它有两个含义,第一,IOTDB可以部署在云上或数据中心或者在边缘设备上。而在另一方面, ts文件可以在三个不同的平台上同步。而且IOTDB还有一个非常广泛的生态系统,它能够与大数据系统深度集成。

Apache IOTDB有一些已经非常广泛的用例,不仅在中国而且在美国和欧洲都有使用,并且涵盖了卫星航空和铁路和船舶业。从重点央企和国内龙头企业都有使用。


这是上海地铁的一个非常典型的用例,他们在尝试IOTDB之前使用Cassandra数据库管理系统,但后来他们发现其性能不佳。而IOTDB一台服务器可以取代15个原始数据库服务器。而且可以管理300条列车的数据,每条列车每200毫秒可以收集3200条数据,日均数据量达到4000亿。在IOTDB被使用之前,大约是两百太字节的数据存储,但在IOTDB使用之后,数据量减少到大约十六太。IOTDB在其他领域也有着非常广泛的应用。

最后,我想介绍一下Apache IOTDB开源社区,这是一个开源项目,如果大家感兴趣,都可以加入进来。
 ——Pengcheng
——Pengcheng
编辑:于腾凯
校对:林亦霖
















 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









