







 本文探讨了AI算法透明性的重要性及其面临的挑战,包括技术、评估和制度三个方面。提出了一种以法律规制和技术适配为基础的治理范式,并详细介绍了在学术、法律和技术领域的实施措施。此外,构建了面向算法使用者和监管方的透明度评估清单及等级表,以促进算法透明度的合规要求。最后,通过推荐系统实例展示了透明性在实践中的应用,采用知识图谱与强化学习提供解释,从而提高用户信任度和监管效能。
本文探讨了AI算法透明性的重要性及其面临的挑战,包括技术、评估和制度三个方面。提出了一种以法律规制和技术适配为基础的治理范式,并详细介绍了在学术、法律和技术领域的实施措施。此外,构建了面向算法使用者和监管方的透明度评估清单及等级表,以促进算法透明度的合规要求。最后,通过推荐系统实例展示了透明性在实践中的应用,采用知识图谱与强化学习提供解释,从而提高用户信任度和监管效能。

以下内容整理自清华大学《数智安全与标准化》课程大作业期末报告同学的汇报内容。

我们主要从分析问题、解决问题、效果评估和实际验证四方面,推动这一课题的研究,并形成相应的研究成果。
第一部分:AI算法透明概述
第一部分,AI算法透明概述,主要凝练了当前AI算法透明性存在的挑战。


近年来,人工智能技术的发展使得其透明性问题日益凸显,为保障用户对算法知情,实现监管机构对算法进行有效规范治理与问责,算法透明性必不可少。


然而,算法透明性更类似于原则性的提议,具体如何落实透明性要求,并对其进行有效评估,尚未形成共识。

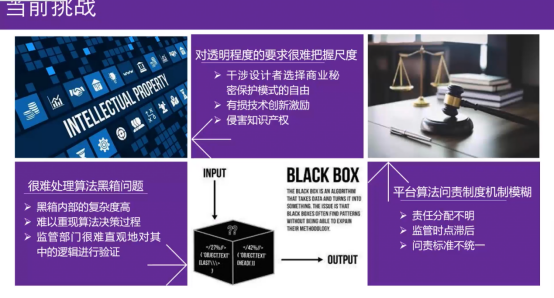
因此,我们对AI算法透明当前存在的诸多挑战进行了总结,主要涉及三个维度:技术、评估和制度。
技术上,很难处理AI算法的黑箱问题;
评估上,对透明程度的要求很难把握尺度;
制度上,算法问责机制仍然模糊。


为有效应对这些挑战,我们首先给出<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









