







本文约4000字,建议阅读5分钟本文将介绍因果推断在翼支付智能决策场景中的一些探索与实践。主要内容包括:
1. 什么是因果推断
2. 因果推断在智能决策中的探索
3. 关于因果推断的个人思考
01 什么是因果推断
1. 因果推断和因果关系
因果推断是研究如何科学识别变量之间因果关系的一门科学。当一个事件的出现导致、产生或决定了另一个事件的出现,这两个事件之间的关系就被称为因果关系。
2. 因果性 ≠ 相关性
我们来看下面两个场景:
场景一:研究发现一个国家吃的巧克力数量越多,该国家获得诺贝尔奖的数量也越多。
结论:要想获得诺贝尔奖就应多吃巧克力/吃巧克力有助于获得诺贝尔奖?
场景二:研究发现缅因州的离婚率和缅因州人均黄油的消耗量相关性极高。
结论:要想降低离婚率应该少吃一些黄油?
思考:以上这两个场景的结论是否可信?
相关性主要产生于:
(1)因果(causation)
T 能导致 Y,则 T 和 Y 构成直接的因果关系。
(2)混淆(confounding)
X 变量可能会同时对 T 和 Y 造成一些影响,这样就会造成 T 和 Y 之间的相关性,X 就是一个混淆变量。
(3)样本选择偏差(selection bias)
T 和 Y 可能本身并没有什么关系,但是 T 和 Y 都会影响 S,因此造成了 T 和 Y 的伪相关性。
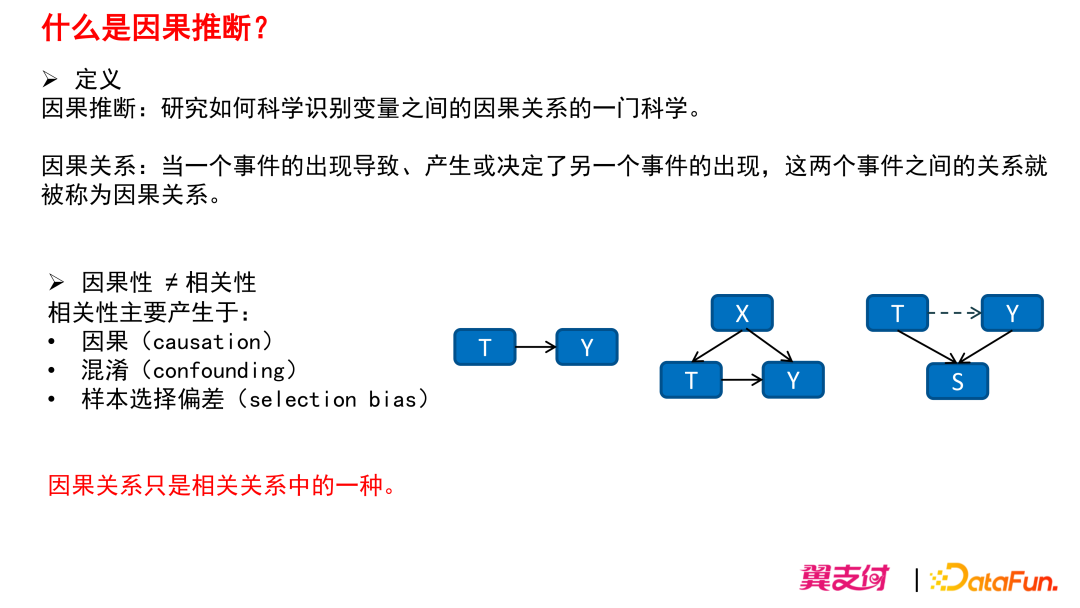
因果关系只是相关关系中的一种。因果推断的本质就是要尽可能的去掉这些混淆和样本偏差,从而发现真实的因果关系。以上举例的两个场景则显然非因果性。
3. 混淆和样本选择偏差
混淆(confounding)和样本选择偏差(selection bias)是两个主要的影响因果推断分析的因子,整个因果推断分析的过程就是不断识别和去除这两个影响因子的过程,因此这里延伸介绍一下什么是混淆和样本选择偏差。
混淆的一个经典场景就是“辛普森悖论”- 在基于某些条件下进行分组讨论时会得出某种结论(例如:X 比 Y 好),但是将分组合并后进行讨论则会得出相反的结论(例如:Y 比 X 好)。产生此现象的原因就是“混淆变量”。

比如在临床诊治中,有两种治疗手段,分别为治疗手段一和治疗手段二。当整体统计各治疗手段的治愈率时,我们发现治疗手段一的治愈率较高。但是当我们分轻重症来分别统计各治疗手段的治愈率时,发现无论是轻症还是重症,治疗手段二都会比治疗手段一要好。这里是否是重症(轻症)其实就是“混淆变量”,它会直接影响到最终的数据结论。因此我们在平时的数据分析中不但要从整体看数据结论,还需要下钻到各个分组下查看可能得到的结论。如果这两个角度的结论是一致的,那说明此数据结论是比较可靠的。如果不做数据上的分组分析,那我们得到的整体数据结论很可能只是一个数字游戏。
“样本选择偏差”是指样本的选择不随机,而是与其他的变量有关系。我们假设受教育程度越高可能收入也越高,也假设年纪越大可能收入也越高。此时如果只采样收入较高的这一部分样本,就很容易得到教育程度和年龄大小具有正相关的关系,而这种“相关性”就是由于样本选择偏差所导致的。
4. 因果推断的主要应用和手段
因果推断主要解决两类问题:
(1)因果关系挖掘(Causal Discovery):因果发现旨在挖掘出变量之间的因果关系,其本质是构建变量间的因果关系图。
(2)因果效应估计(Causal Effect Estimation):因果效应估计是为了量化原因对结果的影响程度,其本质是建立因果模型来量化增量。因果效应估计又主要分为以下三种:
① ITE(Individual treatment Effect):同一个体在干预与不干预(互斥情况下)不同 outcome 的差异: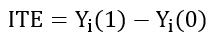
② ATE(Average treatment Effect):一个群体在干预与不干预(互斥情况下)不同 outcome 的差异: 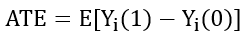
③ CATE(Conditional Average treatment Effect):介于个体与群体之间的,也就是一个 subpopulation 的 ATE。预估某一个状态人群的 ATE就是CATE: 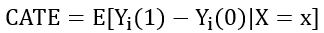
常见的因果效应估计的手段包括:匹配法、双重差分法、合成控制、Uplift Modeling 等。
主流的因果推断框架分为两大类:
(1)Potential Outcome Framework,Rubin 提出,目前主流的用于因果效应评估的框架。
(2)Structural Causal Model(SCM),主要用于构建因果推断关系图。

02 因果推断在智能决策中的探索
接下来介绍因果推断在智能决策中的几个应用场景。应用目标都是通过因果推断来进行因果效应估计。
场景一:评估一个新上线功能的效果价值。
比如在首页弹窗等热门资源位上,如何判断某弹窗是否对金融产品的转化提升有帮助? 提升程度又如何量化?

首先,在条件允许的情况下,一般优先采用 A/B Test 的方式去评估,因为随机对照实验 A/B Test 得到的就是一个 Groud Truth 的结果。但是在一些热门的资源位上,频繁的 A/B Test 成本可能会过高,需要借助因果推断的方式来计算 ATE。比如在上面举例的场景下,一个热门资源位的弹窗展示可能是由多个产品或者多个部门去竞争的结果,频繁采用 A/B Test 去效果评估的成本代价就相对较大。因此在这种情况下就适合用因果推断方式来进行效果估计。
比较直观的评估方法有双重差分法:
第一次差分 D1:计算弹窗上线前,Treat 组和 Control 组的差值,得到 D1;
第二次差分 D2:计算弹窗上线后,Treat 组和 Control 组的差值,得到 D2;
而用 D2 减去 D1 则可以得到该场景的 ATE;
在这个过程中也有一些纠偏的方式,比如 Treat 组的弹窗可能是根据一些业务经验总结出来的策略所做的弹窗,那么 Control 组的范围相对就会过大,这时候我们就可以使用一些匹配方法(如 PSM)在 Control 组里找到和 Treat 组相接近的匹配人群,然后再使用双重差分法来进行效果评估。
得到该场景的 ATE 后就可以帮助业务运营人员做更好的决策规划:比如优化弹窗内容,或者决策是否继续弹窗等。
双重差分法的使用理论上要满足以下三个假设:
(1)平行趋势假设:比如在弹窗前,Treat 组和 Control 组的转化率差异水平平稳。
(2)个体处理稳定性假设:个体相对是稳定的,个体的 outcome 是取决于个体干预变量 treatment 的一个函数,且要满足一致性和互不干预性。
(3)线性关系假设:假设干预变量 treatment 和 outcome 是一个线性关系。
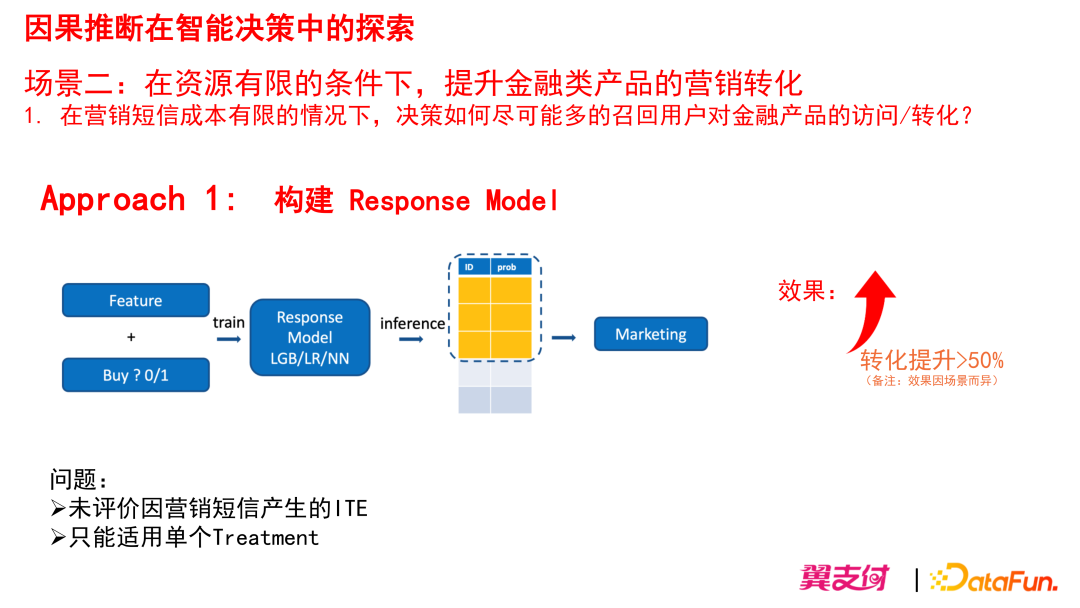
场景二:在资源有限的条件下,提升金融类产品的营销转化。
比如在营销短信成本有限的情况下,决策如何尽可能多的召回用户对金融产品的访问/转化?
(1)Approach 1: 构建 Response Model
最初我们构建的主要是 Response Model,就是常见的基于机器学习的二分类模型。我们根据预测的目标构建样本 Label,以及构建样本特征,然后进行模型选型、模型训练,然后再进行推断得到决策概率,对决策概率在一定阈值之上的用户进行 marketing。
效果:在我们的某个场景上构建 Response Model 得到转化提升 >50%(备注:此提升值不具有普遍意义,实际效果取决于模型准确程度和用户规模等,效果因场景而异)。
问题:未评价因为营销短信产生的 ITE,只适合单个的 treatment。
(2)Approach 2:Uplift Model
之后我们尝试构建了 Uplift Model。Uplift Model 是一个衡量增量的模型,用于预测/估计某一个干预对个人状态/行为的因果效用(ITE)。
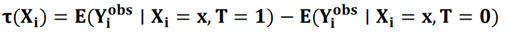
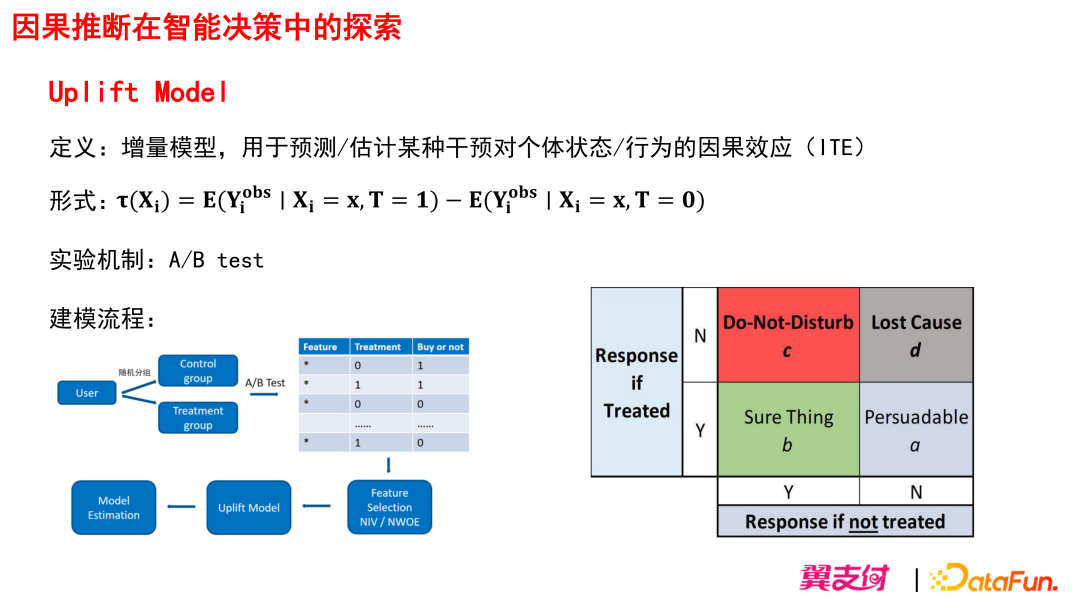
我们建模过程中采用的是随机分组的方式得到的 Control 组和 Treatment 组,对 Treatment 组进行营销短信触达,而对 Control 组不进行任何干预,这样即可得到构建 Uplift Model 所需的 Label 表现,之后再进行特征选择、模型构建、以及模型效果评估。Uplift Model 想要识别出的目标人群象限其实就是需要 Treat 才会 Response 的人群。
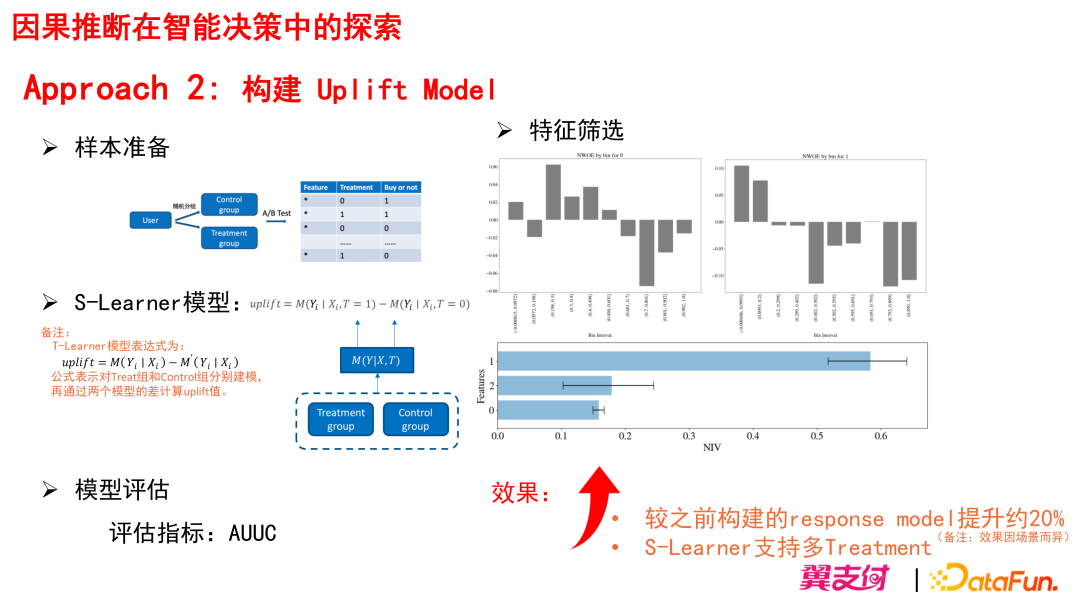
工业工程中用的比较多的一种 Uplift Model 是 meta-learner,这里我们采用了 meta-learner 方法簇里的 S-learner,S-learner 是单模型的,它将干预变量 treatment 作为一个特征入模,用传统有监督学习模型进行训练。而 Uplift 值等于干预变量 treatment 分别置为 1 和 0 时,使用模型进行预测的预测值之差。这种方式优点是可解释性强,灵活方便,但是当特征维度很多时,干预变量的影响可能会被稀释掉。S-learner 支持单模型多 treatment 进行建模,即用一个模型可以估算多个 treatment 其各自的 Uplift 值。
模型的评估指标是:AUUC(Area Under Uplift Curve)
特征筛选:计算得到每个特征的 NIV 值;NIV 值越高,说明该特征越有能力去区分“需要 Treat 才会 Response” 和“无需 Treat 也会 Response”,NIV 值越高则该特征就越会被挑选入模。
效果:在我们的某个场景上构建 Uplift Model,对比之前构建的 Response Model 转化提升约 20% (备注:此提升值不具有普遍意义,实际效果取决于模型准确程度和用户规模等,效果因场景而异)。采用 S-Learner 构建 Uplift Model 可支持单模型多个 Treatment。
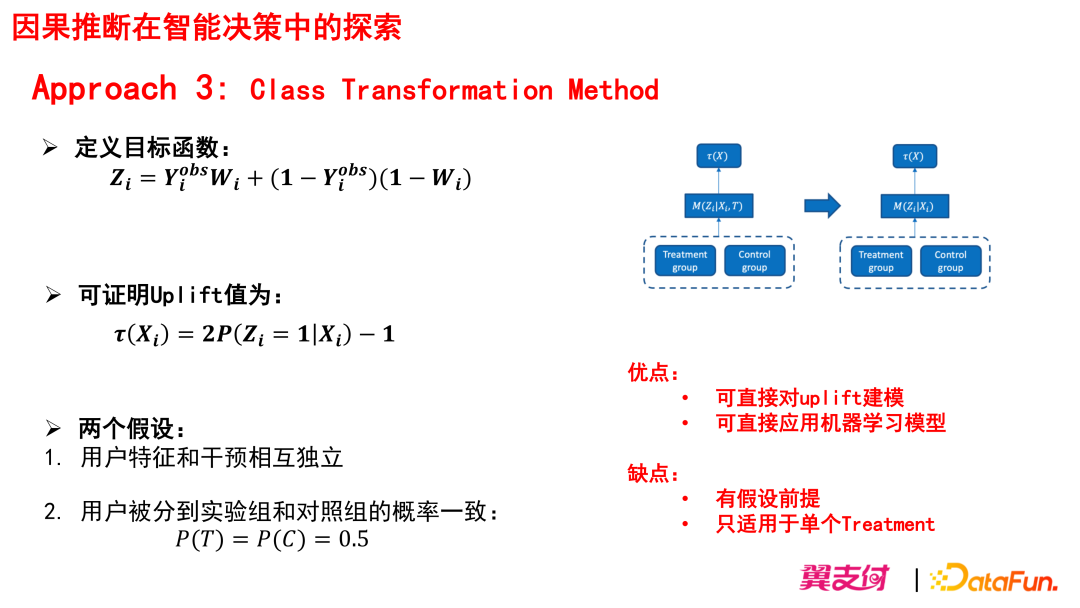
(3)Approach 3:Class Transformation Method
后续我们也有采用 Class Transformation Method,其原理是将 outcome 和干预变量 treatment 进行结合,变换得到新的 label,然后使用传统有监督学习模型拟合。该方法适用于 treatment 和 outcome 都是二类分类的情况。
优点:可直接对 Uplift 建模, 并且可利用较熟悉的机器学习模型进行建模。
缺点:只适合单个干预变量,且有假设前提:
用户特征和干预要相互独立;
用户被分到实验组和对照组的概率要一致 P(T)=P(C)=0.5。
03 关于因果推断的个人思考
最后分享一些对于因果推断的思考:
(1)在 A/B Test 条件允许的情况下,应该优先考虑采用 A/B Test 来规划评估
在经济学领域或者医学领域可能因为可行性问题或伦理问题而无法开展 A/B Test,但是在互联网场景下构建随机对照实验 A/B Test 的可行性还是较高的。并且随机对照实验 A/B Test 的结果也会更直观,可解释性更强。
(2)关于 Uplift Model Uplift Model 并不一定会比 Reponse Model 效果好,这取决于该场景可 Uplift 的空间有多大,同时也取决于模型的准确程度。
04 问答环节
Q1:Response Model 的阈值是怎么判断的?
A1:在模型线下验证环节,根据不同阈值下的准确率和召回率情况,结合业务目标去确定 inference 的阈值。
Q2:如果在用 S-learner 的时候,treatment 这个变量都没有入模的话怎么办?
A2:采用 S-learner 这样的方式,默认前提就是 treatment 这个变量是入模的。如果 treatment 这个变量不打算入模的话,可以考虑采用 T-learner 的方式来构建模型。
Q3:能不能详细讲解一下 Uplift Model 的通用评价指标?
A3:主要用到的指标是 AUUC,有时候也会查看 QINI 系数,但我觉得你只要选定一个常用的评价指标就行了,因为这个评价指标还是取决于建模人员对这个指标在这个场景上的熟悉程度。并没有说哪一个指标就一定是最好的,具体场景具体分析。
今天的分享就到这里,谢谢大家。
分享嘉宾
INTRODUCTION

傅剑文,中国电信翼支付算法总监,毕业于伊利诺伊大学芝加哥分校计算机科学系,目前在翼支付人工智能研究院负责 AI 算法研发工作,曾在携程、PayPal、SGI 从事模型算法及高性能计算相关工作,曾在创业团队担任 CTO。
编辑:王菁
校对:邱婷婷



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









