






 本文提出BOMGraph,一种统一的图神经网络方法,针对电子商务搜索中的多场景问题,通过场景内/间元路径、解耦表示和样本增强等策略提升召回效果,实验证明其在离线和在线实验中表现优秀。
本文提出BOMGraph,一种统一的图神经网络方法,针对电子商务搜索中的多场景问题,通过场景内/间元路径、解耦表示和样本增强等策略提升召回效果,实验证明其在离线和在线实验中表现优秀。

本文约4700字,建议阅读5分钟
本文提出了一种统一的基于图神经网络的召回方法,BOMGraph包含几个组件来解决上述多场景建模存在的挑战。1. 摘要
手机淘宝支持用户以多种形式来进行搜索,除了常用的文本搜索,还支持拍照搜索、相似商品搜索。不同场景之间在数据分布上存在许多共性和差异性。能否利用场景之间的共性来缓解单场景样本稀疏性问题,提升召回效果,同时避免统一建模对于各场景差异化建模的影响。因此,本文提出了一种统一的基于图神经网络的召回方法(BOosting Multiscenario E-commerce Search with a unified Graph neural network,BOMGraph),BOMGraph包含几个组件来解决上述多场景建模存在的挑战。首先是在节点图卷积的时候通过场景内和场景间的metapath来传播跨场景之间的异构信息。其次,我们提出了一个解耦网络来为商品提取场景公共和独有的表示,显式的建模不同场景之间的共性和差异性。最后,通过基于跨场景的样本增强和对比学习,来解决商品在单个场景由于长尾和样本稀疏导致学习不充分的问题。离线评估和在线A/B测试均证明了BOMGraph的有效性,目前该方案已在搜索广告在线业务中投入使用。
论文:
【CIKM 2023】BOMGraph: Boosting Multi-scenario E-commerce Search with a Unified Graph Neural Network
作者:
Shuai Fan, Jinping Gou, Yang Li, Jiaxing Bai, Chen Lin, Wanxian Guan, Xubin Li, Hongbo Deng, Jian Xu, Bo Zheng
下载:
https://dl.acm.org/doi/10.1145/3583780.3614794
2. 背景
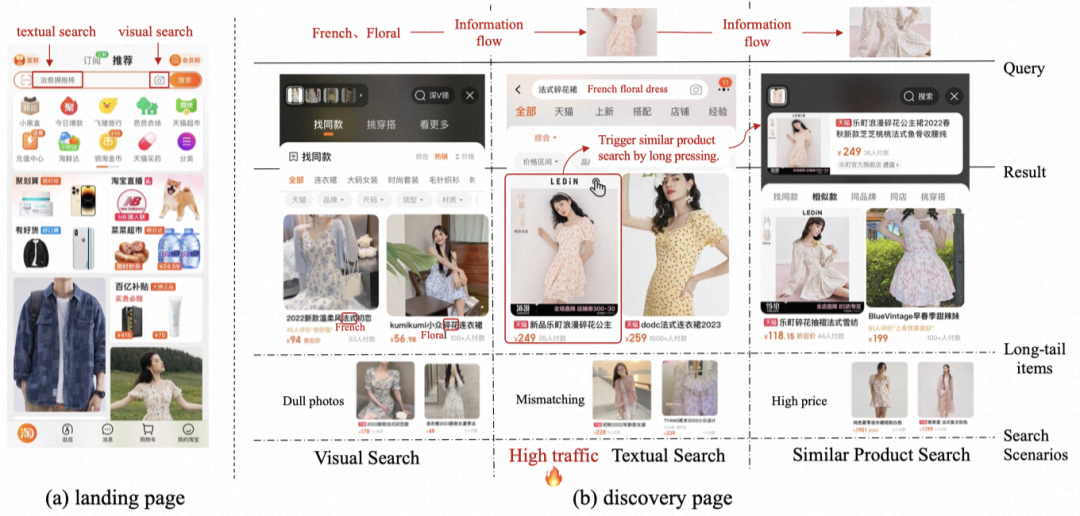
如图1所示,用户可以在首页进行文本搜索和拍照搜索,也可以在搜索结果页长按商品触发相似商品搜索。不同搜索方式从不同的入口发起,并且接受不同模态的查询输入,包括文本、图片和商品。
此外,用户还会交替使用不同的搜索方式。例如图1(b)中,用户想要购买一件连衣裙,从拍照搜索切换到文本搜索和相似商品搜索。由于每个搜索场景会侧重不同的模态信息,因此在交替搜索的过程中,能够更全面的表达用户的偏好(即“粉色、法式碎花、吊带裙、奢华面料”)。
这种多个搜索场景之间的关联性为多场景建模提供了机会。最新研究也表明,利用多场景数据联合建模可以提高单个场景的性能,缓解单场景的样本稀疏问题。本文核心目标是为手淘搜索的多个场景设计一套统一的图神经网络召回方法,其中主要面临以下3个挑战:1)如何捕捉不同场景的异构信息传递;2)如何学习场景鲁棒的商品表示;3)如何缓解单场景长尾商品样本稀疏问题。
3. 方法
BOMGraph使用多个场景数据来构建查询、触发商品和商品的大规模异构图,并定义元路径来更新图中节点的信息,异构图通过多场景图编码器进行编码,该编码器通过元路径引导的信息传播来获得节点嵌入,捕捉不同场景之间的异构信息传递。然后将经过图编码的商品节点嵌入通过解耦表示模块进行解耦,学习场景鲁棒的商品表示。最后,通过在训练过程中加入跨场景数据扩充和对比学习损失缓解单场景长尾商品点击不足学习不充分的问题。接下来介绍统一图神经网络召回框架的细节。
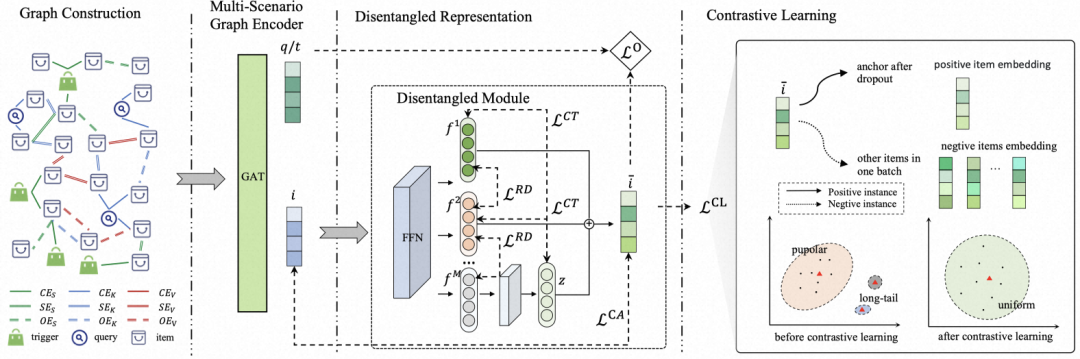
3.1 异构图构建
我们首先构造了一个异构图 . 是节点集合,每个节点都用一个D维的向量表示. 中有三种类型的节点,表示触发商品节点,表示查询节点,表示商品节点。
我们在3个场景中分别建模了点击和共现两种关系,其中表示相似商品搜索,表示文本搜索,表示拍照搜索,总共有七种类型的边。其中是点击边,连接触发商品/查询和商品。,,,是共现边,表示同一个场景的同一次搜索会话下两个被同时点击的商品。,{,,}是相似边,表示同一个场景下两个展现商品图文内容相似。
3.2 基于场景的元路径(meta-path)
然后我们分别定义了场景内元路径以及场景间元路径去对当前节点游走产生子图,通过在子图上使用图编码器来得到融合不同场景信息的表示。
场景内元路径是在每个搜索场景中定义的,动机是沿着场景内元路径收集特定场景的协作反馈,并允许信息传输到相关查询和商品。例如在相似商品搜索场景和文本搜索场景中,我们定义了连接查询(例如触发商品和文本查询)和商品(即)的元路径,沿着点击边构建的场景内元路径:
()
与现有的基于异构网络的检索模型不同,除了场景内元路径外,我们还定义了场景间元路径来捕获跨场景的信息。动机是通过相似性边将不同场景中内容相似的商品连接起来,这样信息就可以跨场景流动,并利用场景间的共性。具体的,我们在三个场景中以不同的顺序定义了三个元路径:
()
3.3 异构图编码器
对于每个节点,其中可以是触发商品/查询/商品节点,我们沿着每个场景的场景内元路径进行采样,该路径从开始形成场景内子图{,,}。我们还形成了场景间子图{,,},方法是沿着从场景开始的每个场景间元路径选择节点。具体来说,我们分别对一跳邻居中的三个节点和二跳邻居中三个节点进行随机采样。为了防止误采样产生偏差,如果采样的邻居在小批量中构成一对正对,我们将其丢弃并重新采样,直到达到样本大小。
然后我们使用异构图编码器依据采样的子图对查询节点和商品节点进行编码,先前的工作指出,(图注意力网络)的聚合效果优于,因此我们使用作为图编码器的主网络。我们定义 为节点通过在子图上的嵌入,其中是初始化的嵌入向量。
为了初始化节点嵌入和触发节点嵌入,我们将节点ID特征的One-Hot嵌入、图像特征嵌入和标题文本的特征嵌入连接起来,并通过全连接层传递它们。初始查询节点嵌入是通过连接ID嵌入和文本特征嵌入获得的。
对于查询或触发节点,由于它们的表示仅用于特定场景(即用于文本搜索和用于相似商品搜索),我们应该关注场景内信息。因此,它们的嵌入是以特定场景的方式在场景内元路径引导的子图上获得的,如下所示:
()
由于三个场景共享相同的商品,在获取商品表示时,我们考虑了场景内和场景间的信息。我们首先获取每个场景下的商品表示。我们使用三个GAT编码器,来组合来自场景内、场景间和场景共享信息。
()
在异构图编码模块中,我们首先通过场景内和场景间的元路径聚合邻居信息,得到查询节点和商品节点的融合多个场景的粗粒度表示,之后再通过解耦表示学习模块来学习更加鲁棒的表示。
3.4 解耦表示学习
我们保持异构图编码器输出的查询嵌入和触发商品嵌入不变,并将所得到的商品嵌入送到解耦表示模块,该模块由三部分组成。
我们认为,更鲁棒的商品表示必须反映场景之间的共性和细微差异,而不是简单地将信息融合到各个场景中。
因此,我们通过将图学习得到的的商品表示解耦为个独立的对应项来微调它。这些对应项可以对应于不同场景所关注的特定特征,解耦表示如下:
()
然后,我们使用对应项来推导场景之间的共性。这可以通过转换一个对应物并对其进行调整以反映共同知识来实现。在不失一般性的情况下,我们可以将变换应用于最后一个正交特征空间。也就是说,我们向前馈层输入,如下所示:
()
由于反映了不同场景之间的共同信息,因此它应该在中捕获共同信息。受域对齐损失的启发,我们调节来捕获其他对应项的元素方差:
()
我们通过合并解耦的对应表示和公共信息来微调商品嵌入:
()
为了获得更稳定的性能,我们可以鼓励细化的商品嵌入的质心与原始商品嵌入的质心对齐,避免偏离到遥远的区域:
()
最终解耦阶段的loss组成为解耦损失以及CT损失还有CA损失。
3.5 对比学习
不同场景下的长尾商品不同,当前场景的长尾商品可能在另一场景下行为充分,因此可以联合其他场景的数据来补充行为数据。因此,我们在数据级别实现了跨场景扩充,使用场景之间相似度高的商品来补充当前场景的训练样本。在当前场景中,如果查询商品对,连接到点击次数少于三次的商品,则我们使用相似性边来查找与其他场景中的高度相似的商品。我们根据它们的相似性选择前五个商品。这前5项被构造为新的查询项对,。
我们优化了成对监督损失。对于查询或触发商品,在查询下单击的商品(或通过如上所述的跨场景数据扩充构建的商品)被视为正样本。我们随机抽取同类目下个其他商品作为负样本。监督学习中的InfoNCE损失定义如下:
()
GNN在表示一致性方面的性能较差,并且由于更加流行的商品可能聚集在一起,因此很难检索长尾商品。受此启发,我们还利用对比学习来解决长尾问题。对比学习的动机是缩短锚样本和正样本之间的距离,同时增加锚样本与负样本之间的间距。通过使用对比学习,样本在特征空间中的分布更加均匀。形式上,我们定义对比损失:
()
4. 实验分析
我们通过计算后一天点击商品的(NDCG)@100/200, (HR)@100/200, 和(MRR)@100/200来评估在多个场景的实际召回效果。
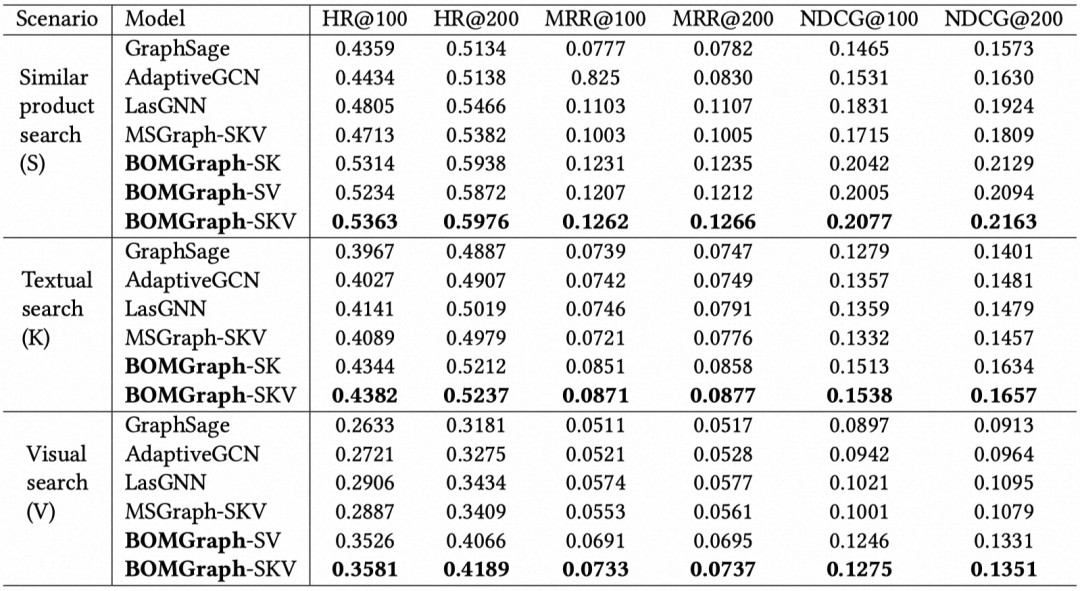
离线主实验部分,我们分别在三个场景对比相应的baseline模型:
BOMGraph-SKV在所有搜索场景中始终取得最佳结果,这证明了多场景搜索联合建模的优越性。
我们观察到结合更多的搜索场景可以提高BOMGraph的性能。例如,组合了三个场景的BOMGraph-SKV优于在每个数据集上组合两个场景的模型。然而,即使两个场景数据,BOMGraph也明显优于最佳竞争对手LasGNN。这一观察结果验证了我们的假设,即在统一的框架中多场景联合学习可以提高每个场景的性能。
此外,我们观察到,单一场景的LasGNN优于结合三种场景的MSGraph-SKV。这表明仅仅融合多个场景是不够的,也不一定比单一场景学习产生更好的结果。同时,LasGNN的性能优于GraphSage,根本原因是基于元路径采样的子图比随机采样的子图更有效地聚合节点信息。
线上AB实验部分,我们进行了在线A/B测试,将我们提出的模型BOMGraph与线上解决方案(单场景模型LasGNN)的性能进行比较。在为期七天的实验中,我们只修改了候选商品生成步骤,即在相似商品搜索场景中,使用不同的模型来召回每个触发商品查询的前200个商品,保持所有其他排序预估的步骤不变。我们比较了在线实际点击率(CTR)、转化率(CVR)和每千次点击扣费收入(RPM),以确定BOMGraph召回的商品是否更有可能被用户点击和购买。
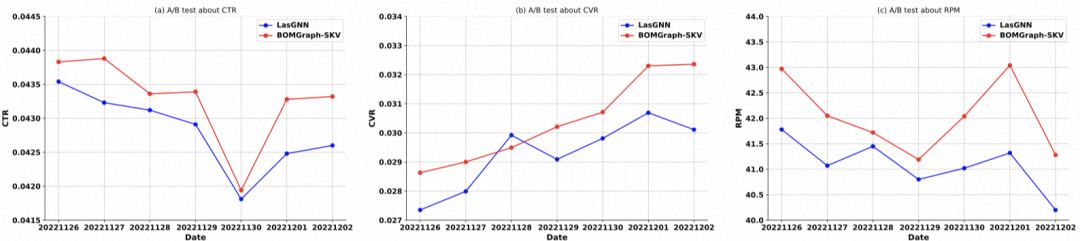
如图所示,在相似商品搜索场景中,我们提出的BOMGraph-SKV在CTR和RPM方面始终优于LasGNN。就CVR而言,它只落后于LasGNN一天。这可能是因为,虽然我们的模型能够每天提高点击率,但并不一定总是能提高转化率,总体而言,我们的CVR仍有提升效果。
在论文中我们还分别验证了不同模块的消融实验,以及相关超参数实验,具体细节可以参考我们的论文。
5. 总结
在本文中,我们提出一种基于电商搜索多场景联合建模的统一图神经网络召回框架,用于文本搜索、拍照搜索、相似商品搜索三个场景,利用来自多个场景的数据并联合优化整体性能,实验证明我们的方法在多个场景都能够取得效果上的提升。未来工作也将持续关注电商搜索场景下的多场景联合学习。
参考文献
Xinyu Zou, Zhi Hu, Yiming Zhao, Xuchu Ding, Zhongyi Liu, Chenliang Li, and Aixin Sun. 2022. Automatic Expert Selection for Multi-Scenario and Multi-Task Search. In SIGIR. 1535–1544.
Qijie Shen, Wanjie Tao, Jing Zhang, Hong Wen, Zulong Chen, and Quan Lu. 2021. SAR-Net: A Scenario-Aware Ranking Network for Personalized Fair Recommendation in Hundreds of Travel Scenarios. In CIKM. 4094–4103.
Yuting Chen, Yanshi Wang, Yabo Ni, Anxiang Zeng, and Lanfen Lin. 2020. Scenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce. In ICDM (Workshops). 127–135.
Shaohua Fan, Junxiong Zhu, Xiaotian Han, Chuan Shi, Linmei Hu, Biyu Ma, and Yongliang Li. 2019. Metapath-Guided Heterogeneous Graph Neural Network for Intent Recommendation. 2478–2486.
Yichao Wang, Huifeng Guo, Bo Chen, Weiwen Liu, Zhirong Liu, Qi Zhang, Zhicheng He, Hongkun Zheng, Weiwei Yao, Muyu Zhang, Zhenhua Dong, and Ruiming Tang. 2022. CausalInt: Causal Inspired Intervention for Multi-Scenario Recommendation. In KDD. 4090–4099.
Jiangxia Cao, Xixun Lin, Xin Cong, Jing Ya, Tingwen Liu, and Bin Wang. 2022. DisenCDR: Learning Disentangled Representations for Cross-Domain Recommendation. In SIGIR. 267–277.
Menghan Wang, Yujie Lin, Guli Lin, Keping Yang, and Xiao-Ming Wu. 2020. M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems. In KDD. 2349–2358.
Xiang Wang, Hongye Jin, An Zhang, Xiangnan He, Tong Xu, and Tat-Seng Chua. Disentangled Graph Collaborative Filtering. In SIGIR. 1001–1010.
Jianxin Ma, Chang Zhou, Hongxia Yang, Peng Cui, Xin Wang, and Wenwu Zhu. 2020. Disentangled Self-Supervision in Sequential Recommenders. In KDD. 483–491.
Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, Jianxun Lian, and Xing Xie. 2021. Self-supervised Graph Learning for Recommendation. In SIGIR. 726–735.
Xiangnan He, Zhankui He, Xiaoyu Du, and Tat-Seng Chua. 2018. Adversarial Personalized Ranking for Recommendation. In SIGIR. 355–364.
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are Graph Augmentations Necessary?: Simple Graph Contrastive Learning for Recommendation. In SIGIR. 1294–1303.
Ruoyu Li, Sheng Wang, Feiyun Zhu, and Junzhou Huang. 2018. Adaptive Graph Convolutional Neural Networks. In AAAI. 3546–3553.
编辑:王菁



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









