







作者:Kamna Sinha翻译:陈超校对:赵茹萱
本文约5500字,建议阅读15分钟
本文为上篇,介绍了为数据分析而准备的数据清洗的10个Python案例及代码,下篇将继续介绍另外11个Python案例及代码。数据清洗是识别和纠正错误以及数据集不一致性的过程,以便于数据可以进行分析。在此过程中,数据专家可以更清楚地了解他们的业务中正在发生的事情,提供任何用户都可以利用的可靠分析,并帮助他们的组织运转更高效。
数据清洗的特征
不同数据特征和属性都用于衡量数据集的清洁度和整体质量,包括以下方面:
准确性
完整性
一致性
整体性
适时性
统一性
有效性
在本文当中,我们将覆盖数据清洗过程中4个宽泛主题,并通过示例展示如何使用Python进行清理。
1. 常见数据问题
a. 数据类型限制
b. 数据广度限制
c. 特异性限制
2. 文本和分类数据问题
a. 资格限制
b. 分类变量
c. 清洗文本数据
3. 高级数据问题
a. 统一性
b. 跨领域验证
c. 完整性
4. 记录链接
a. 字符串比较
b. 生成配对
c. 链接数据框

https://www.welldatalabs.com/2019/10/garbage-in-garbage-out/
1. 常见数据问题
我们将看一下分析者在处理原始数据和做进一步分析时遇到的最常见的问题。
a. 数据类型限制
当给定数据框的特定列是特定数据类型并且需要被矫正/转换成另一种便于计算和分析的数据类型或者进行统计处理时,这个过程通常很费时。
在一个典型的数据科学工作流程当中,我们通常获取我们的原始数据,探索并加工它,使用可视化或者预测模型来获得更深的洞察,并最终使用报表来进行展示。
由于重复值、拼写错误、数据类型解析错误和遗留系统等原因,也会出现不干净的数据。
如果不能确保数据已经在探索和处理过程中进行了合适的清理,肯定会对我们产生的见解和报告质量产生影响。
例1
例如:我们查看一个虚假销售数据,一个本应该是整型变量的数值数据被保存成字符串(使用dtype方法返回Revenue列对象)
# Import CSV file and output header
sales = pd.read_csv('sales.csv')
sales.head(2)
# Get data types of columns
sales.dtypes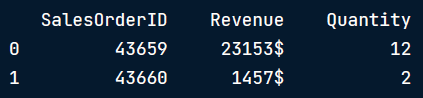
销售数据前两列
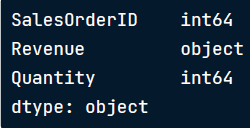
Revenue被视为对象型数据类型
现在,如果我们想要查看总收入并应用sum方法,结果将是一个连接字符串,而不是所有行中所有收入值的数值总和:
sales['Revenue'].sum()
作为一种解决方案,我们首先删除$符号,然后在执行求和操作之前将数据类型更改为' int ':
sales['Revenue'] = sales['Revenue'].str.strip('$')
sales['Revenue'] = sales['Revenue'].astype('int')例2
我们的下一个例子是,当一个分类变量被表征为一个数字并错误地变成一个int变量时,我们可能会得到该变量/数据列的非预期的统计摘要。
示例:我们将marriage_status值保存为数字,表示:
0 = Never married 1 = Married 2 = Separated 3 = Divorced
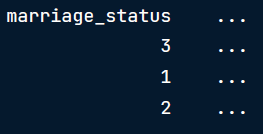
然后我们试着看看本列的统计总结:
df['marriage_status'].describe()
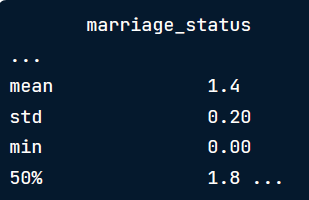
这对于理解我们所关心的变量在数据集中的分布毫无用处,因此我们首先需要将其转换为int类型的变量。
df["marriage_status"] = df["marriage_status"].astype('category')
df.describe()
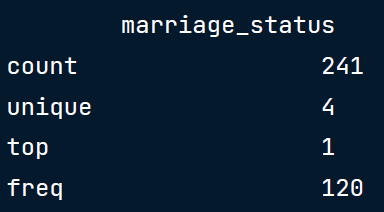
b.数据范围约束
应该落在一个范围内的数据。例如,电影评级数据只能保存1-5或1-10之间的值,或者订阅日期列不能有未来日期的值。
例3
第一个例子是我们的电影评分数据:


查看超出预期范围的损坏数据的一种有效方法是可视化该列:
import matplotlib.pyplot as plt
plt.hist(movies['avg_rating'])
plt.title('Average rating of movies (1-5)')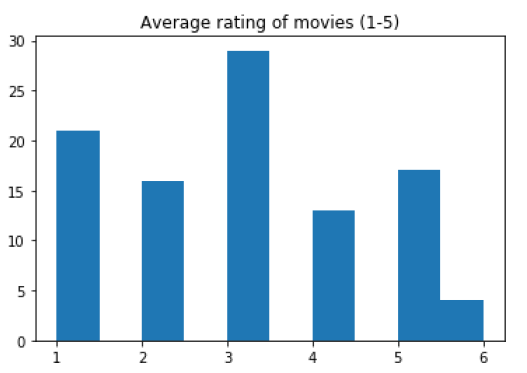
我们在这里看到几个值在超出范围的6处下降。有许多方法可以处理这些超出范围的值,如输入行,将它们设置为值5;或设置为平均评级值等,这取决于业务案例和我们试图通过此特定分析解决的问题。
我们使用下面的代码过滤掉错误的值:
import pandas as pd
# Output Movies with rating > 5
movies[movies['avg_rating'] > 5]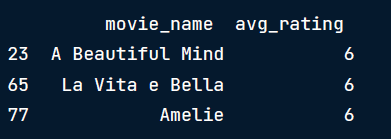
接下来,我们使用过滤来删除值:
movies = movies[movies['avg_rating'] <= 5]
# Drop values using .drop()
movies.drop(movies[movies['avg_rating'] > 5].index, inplace = True)另一种方法是将这些值替换为最大值,即5
# Convert avg_rating > 5 to 5
movies.loc[movies['avg_rating'] > 5, 'avg_rating'] = 5例4
在我们第二个例子当中,我们可以看到数据范围超出预期值:
为了过滤给定数据框中错误/将来的日期值,我们运行以下代码:
import datetime as dt
today_date = dt.date.today()
user_signups[user_signups['subscription_date'] > dt.date.today()]
# this is an old code and 'today's date' was 1/1/2020 , result has been filtered accordingly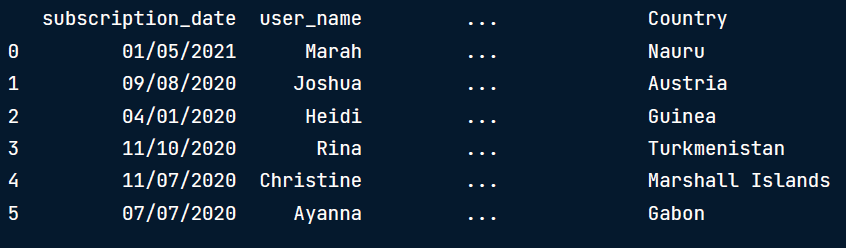
假定今天日期是2020/01/02,subscription_date列里所有过滤值都是未来时间
为了解决这一问题我们首先检查一下该列的数据类型:
import datetime as dt
import pandas as pd
# Output data types
user_signups.dtypes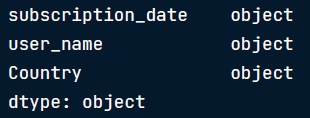
我们看到subscription_date列有对象数据类型,显示可能有字符串类型的值,所以首先我们需要将它们转换为日期类型:
# Convert to date
user_signups['subscription_date'] =
pd.to_datetime(user_signups['subscription_date']).dt.date接下来,我们使用loc函数将本列中显示未来日期的值进行替换:
today_date = dt.date.today()
# Drop values using filtering
user_signups = user_signups[user_signups['subscription_date'] < today_date]
# Drop values using .drop()
user_signups.drop(user_signups[user_signups['subscription_date'] > today_date].index, inplace = True)
# Drop values using filtering
user_signups.loc[user_signups['subscription_date'] > today_date, 'subscription_date'] = today_date
# Assert its true
assert user_signups.subscription_date.max().date() <= today_datec.特异性限制
当我们有相同的明确信息在一些或所有列当中出现跨行重复时,可以被诊断为重复值。
例如,以下个人信息:

要么是所有列都重复或者大部分列值重复。
原因:
a. 数据输入错误
b. 连接或合并错误
c. 漏洞或设计错误
如何发现重复值?
第一步,检查数据框:
例5
例如,接下来我们将处理用户信息数据的重复值:
height_weight.head()

使用duplicated()方法:
我们可以使用duplicated()方法来处理数据框中的重复值。返回一系列布尔值,True表示有重复,False表示非重复值。
接下来我们可以看到哪些行受到了影响。
duplicates = height_weight.duplicated()
print(duplicates)样例输出如下:

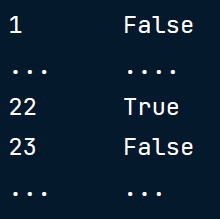
然而,使用duplicated()但不使用参数的方法可能会导致错误的结果,默认情况下所有列都要求有重复值,除了第一次出现外,所有重复的值都被标记为True。这限制了我们诊断重复类型以及如何有效处理的能力。
在这个例子中,我们可以看到所有行都会受到[]的影响:
duplicates = height_weight.duplicated()
height_weight[duplicates]
为了正确校准查找重复项的方式,我们将使用duplicate()方法中的2个参数。
a. 子集参数允许我们设置一个列名列表来检查重复。例如,它只允许我们查找姓和名列的重复项。
b. keep参数让我们通过将重复值的第一次出现设置为字符串的第一个,将重复值的最后一次出现设置为字符串的最后一个,或将所有重复值的出现设置为False来保留。
在本例中,我们检查名字、姓氏和地址变量之间的重复项,并选择保留所有重复项。
column_names = ['first_name','last_name','address']
duplicates = height_weight.duplicated(subset = column_names, keep = False)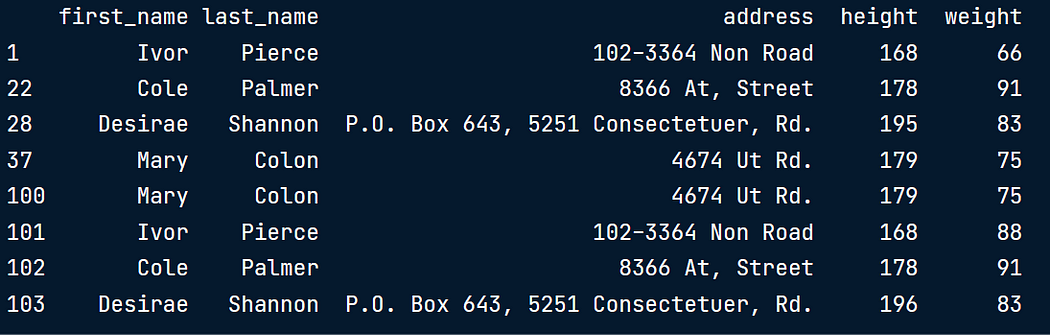
现在,为了获得更好地了解重复值,我们使用排序方法:
height_weight[duplicates].sort_values(by = 'first_name')
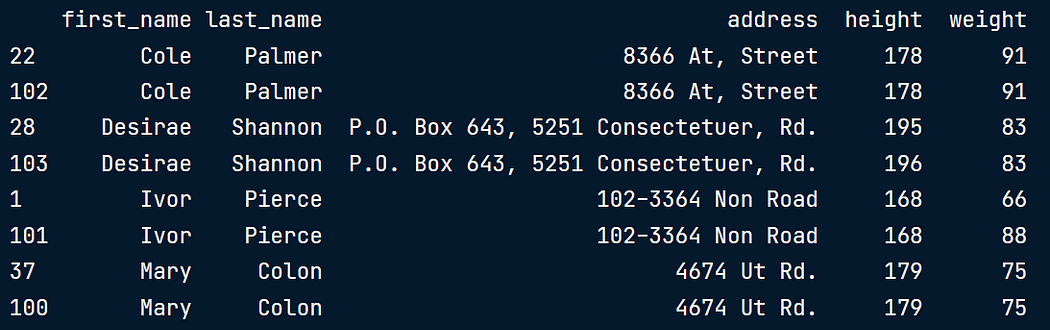
我们发现有四个重复行的集,前两行在所有列上都重复(1,2,7,8行)
另外两个不完全重复(3,4,5,行)
处理重复值:
完全重复的比较容易处理。所需要做的就是保留其中一个,去掉其他的。
drop_duplicates方法——与duplicates法参数相同——子集和原位
height_weight.drop_duplicates(inplace = True)这给我们留下了另外两组重复项,它们对于first_name、last_name和address是相同的,但是包含高度和重量的差异。除了删除差异很小的行之外,我们还可以使用统计度量来组合每组重复的值。
例如,我们可以通过计算它们之间的平均值,或最大值,或其他统计方法,将这两行合并为一行,这高度依赖于对数据的常识理解,以及我们拥有的数据类型。
我们可以使用groupby方法轻松地做到这一点,当它与agg方法链接在一起时,可以按一组公共列进行分组,并在执行聚合时返回特定列的统计值。

代码说明:
例如,在这里,我们创建了一个名为summary的字典,它指示groupby返回高度列的最大重复行数,以及权重列的平均重复行数。然后,我们根据前面定义的列名对highight_weight进行分组,并将其与agg方法链接起来,该方法使用我们创建的摘要字典。我们用dot-reset_index()方法链接整行,这样我们就可以在最终输出中拥有编号的索引。我们可以通过再次运行duplicate方法来验证没有重复的值,并使用brackets来输出重复行。
2. 文本和分类数据问题
接下来,在进行分析之前,我们将研究可能面临的另外两种类型的数据清理范围。
分类变量是一种可以取有限的(通常是固定的)可能值中的一个的变量。因此,分类数据可以表示预定义有限类别集的变量。这方面的例子包括婚姻状况、家庭收入类别、贷款状况等。为了在分类数据上运行机器学习模型,它们通常被编码为数字。由于分类数据表示一组预定义的类别,因此它们不能具有超出这些预定义类别的值。
a. 关系限制
由于各种原因,我们的分类数据可能不一致。这可能是由于自由文本与下拉字段的数据输入问题,数据解析错误和其他类型的错误。
不同类型的矛盾需要不同的解决方案。
例6
下面是一个名为study_data的数据框,其中包含名字、出生日期和血型的列表。此外,还创建了一个名为categories的数据框,其中包含血型列可能的正确类别。
study_data = pd.read_csv('study.csv')
study_data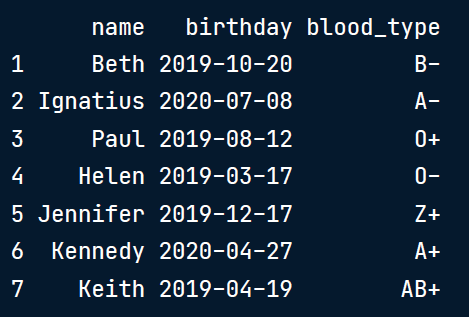
Study_data
# Correct possible blood types
categories

所以我们可以在这里看到,研究数据的第五行有一个血型Z+,这不是从类别数据。类别数据框架将帮助我们系统地发现所有这些不一致的行。
保存分类数据的所有可能值的日志始终是一个很好的做法,因为它将使处理这些类型的不一致更容易。
如何使用连接来修复数据中的分类不一致:
我们在这里关心的两种主要连接类型是反连接和内连接。
我们在它们之间的公共列上连接数据框。反连接,合并两个数据框 A和B,并返回一个数据框中不包含在另一个数据框中的数据。
在这个例子中,我们正在执行A和B的左反连接,并且返回数据框 A和B的列,这些列的值只能在连接它们之间的公共列的A中找到。
内部连接,只返回两个数据框中包含的数据。例如,A和B的内部连接将从两个数据框返回仅在A和B中找到的值的列,它们之间的公共列被连接在一起。

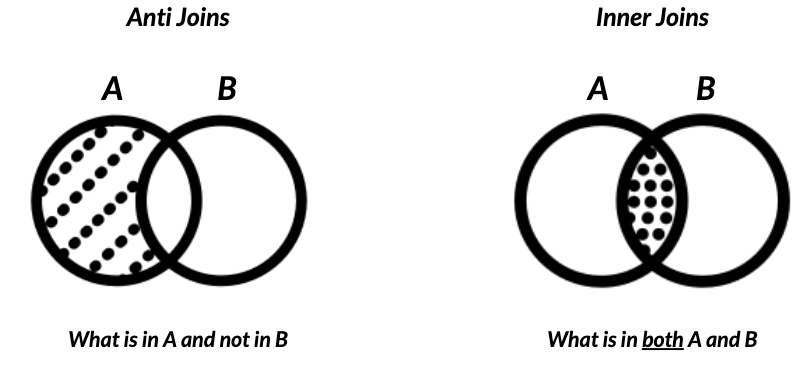
如何使用连接来清除数据中的分类不一致
在我们的示例中,左反连接实质上返回所有血型不一致的研究数据中的数据:

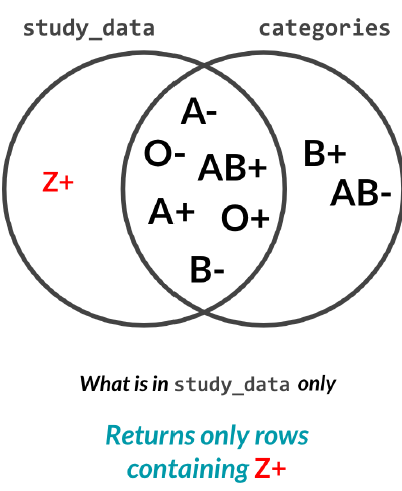
在Python中:
首先我们要找到给定数据中不一致的分类:
inconsistent_categories =
set(study_data['blood_type']).difference(categories['blood_type'])
print(inconsistent_categories)
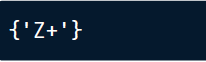
接下来,我们找到具有这个不一致值的行:
# Get and print rows with inconsistent categories
inconsistent_rows =
study_data['blood_type'].isin(inconsistent_categories)
study_data[inconsistent_rows]
删除不一致的行,只保留一致的行。我们只是在子集时使用波浪符号,它返回除了不一致行的所有内容。
inconsistent_categories =
set(study_data['blood_type']).difference(categories['blood_type'])
inconsistent_rows =
study_data['blood_type'].isin(inconsistent_categories)
inconsistent_data = study_data[inconsistent_rows]
# Drop inconsistent categories and get consistent data only
consistent_data = study_data[~inconsistent_rows]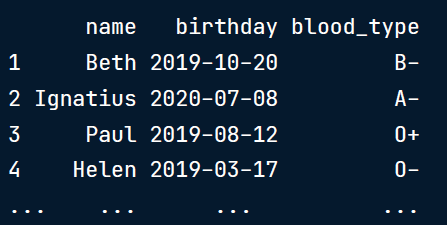
b.分类变量
在清理分类数据时,我们可能遇到的一些问题包括值不一致,存在太多可以合并为一个的类别,以及确保数据具有正确的类型。
例7
为此,我们将以人口统计数据为例,其中一个列是“marriage_status”:
首先,我们从计算这一列中的唯一值开始,以查看这一类别中的所有可能值:(检查一致性)。
注意,dot-value_counts()方法只适用于Series。
# Get marriage status column
marriage_status = demographics['marriage_status']
marriage_status.value_counts()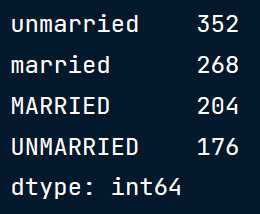
不一致的大写
为了解决这个问题,我们可以将marriage_status列大写或小写。这可以分别使用str-dot-upper()或dot-lower()函数来完成。
选择1:
# Capitalize
marriage_status['marriage_status'] =
marriage_status['marriage_status'].str.upper()
marriage_status['marriage_status'].valu_e_counts()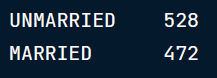
选择2:
# Lowercase
marriage_status['marriage_status'] = marriage_status['marriage_status'].str.lower()
marriage_status['marriage_status'].value_counts()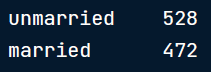
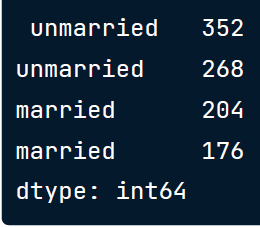
我们在这个例子中看到的另一个问题是:前导或尾随空格:'已婚','已婚','未婚','未婚' ..
# Get marriage status column
marriage_status = demographics['marriage_status']
marriage_status.value_counts()
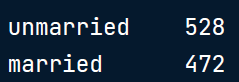
要删除前导空格,我们可以使用str-dot-strip()方法,当没有输入时,该方法会删除所有前导和后导空格。
# Strip all spaces
demographics = demographics['marriage_status'].str.strip()
demographics['marriage_status'].value_counts()
继续…
在某些情况下,我们可能希望将列中的值折叠到类别或箱中。
有时也可能存在类别数量非常高的情况,我们可能需要通过将少数类别映射到更广泛的类别中来将它们折叠成更小的组。
例8
对于我们的第一个例子,让我们从人口统计数据中提取收入群体:
(代表income_group列)
为了节省空间,我们就不讲太多细节了,我们只看这部分代码:
使用cut()方法:让我们使用bins参数定义类别截断。
范围。它接受每个类别的截断点列表,最后一个是无穷大,用np-dot-inf()表示。
# Using cut() - create category ranges and names
ranges = [0,200000,500000,np.inf]
group_names = ['0-200K', '200K-500K', '500K+']
# Create income group column
demographics['income_group'] = pd.cut(demographics['household_income'], bins=ranges,
labels=group_names)
demographics[['income_group', 'household_income']]

这样我们就把所有的收入都分组了。
例9
将类别映射到更少的类别:
假设我们有一个操作系统列,其中的值如下:
operating_system列为:' Microsoft ', ' MacOS ', ' IOS ', ' Android ', ' Linux '
operating_system列应该变成:' DesktopOS ', ' MobileOS '
# Create mapping dictionary and replace
mapping = {'Microsoft':'DesktopOS', 'MacOS':'DesktopOS', 'Linux':'DesktopOS',
'IOS':'MobileOS', 'Android':'MobileOS'}
devices['operating_system'] = devices['operating_system'].replace(mapping)
devices['operating_system'].unique() # to check result就这么简单!


c.清理文本数据
文本数据是最常见的数据类型。它的例子包括姓名、电话号码、地址、电子邮件等等。常见的文本数据问题包括处理不一致、确保文本数据具有一定长度、拼写错误等。
例10
在本节中,我们将选择一个示例' phone.csv ',其中包含有数据错误的电话号码列:
phones = pd.read_csv('phones.csv')
print(phones)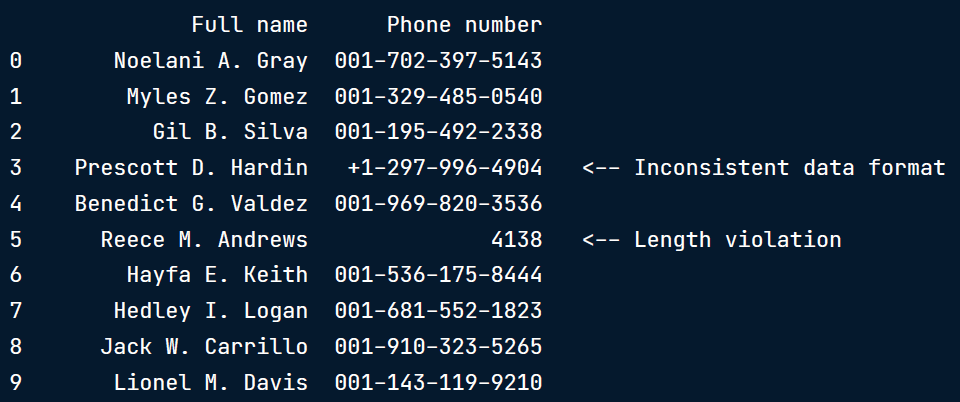
[虚拟数据]都是字符串列
如果我们想要将这些电话号码输入到自动呼叫系统中,或者创建一个按区号讨论用户分布的报告,那么如果没有统一的电话号码,我们就无法真正做到这一点。
我们期望:
1. 电话号码以00开始排列
2. 低于10位数值的任何数字都将被NaN替换以表示缺失的值,并且
3. 所有的破折号都被去掉了
我们将一步一步地进行:
# Replace "+" with "00"
phones["Phone number"] = phones["Phone number"].str.replace("+","00")
phones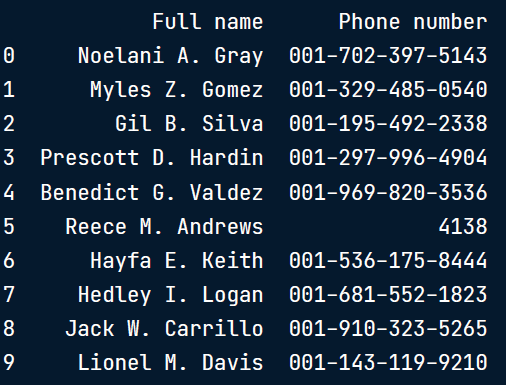
# Replace "-" with nothing
phones["Phone number"] = phones["Phone number"].str.replace("-","")
phones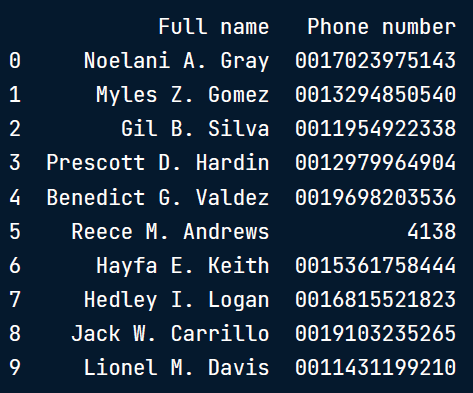
# Replace phone numbers with lower than 10 digits to NaN
digits = phones['Phone number'].str.len() phones.loc[digits <10,"Phone number"] = np.nan
phones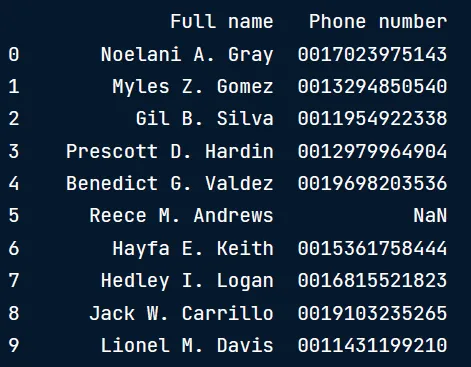
至此,我们完成了上篇文章中对数据清理的讨论。
如果你喜欢这个内容,请鼓掌/评论:)
参考:
1. 糟糕的数据如何导致糟糕的决策
https://www.welldatalabs.com/2019/10/garbage-in-garbage-out/
2. 数据清理
https://www.thoughtspot.com/data-trends/data-science/what-is-data-cleaning-and-how-to-keep-your-data-clean-in-7-steps
3. 数据科学中的数据清理:过程、收益和工具
https://www.knowledgehut.com/blog/data-science/data-cleaning
4. 数据清理
https://www.techtarget.com/searchdatamanagement/definition/data-scrubbing
原文标题:
Cleaning Data For Data Analysis — in Python with 21 examples and code.
原文链接:
https://medium.com/data-at-the-core/cleaning-data-for-data-analysis-in-python-with-21-examples-and-code-b7bf7bd528a9
编辑:于腾凯
校对:林赣敏
译者简介

陈超,北京大学应用心理硕士,数据分析爱好者。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。在学习过程中越来越发现数据分析的应用范围之广,希望通过所学输出一些有意义的工作,很开心加入数据派大家庭,保持谦逊,保持渴望。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









