







2024中国高校计算机大赛-大数据挑战赛初赛阶段周周星奖项评选环节火热进行中,通过对参赛选手在线提交相关模型文件的系统自动评测得分(以7月10日18:00榜单排名为准),第二周周周星在校生队伍和在职队伍排名榜单已出炉,恭喜获奖的三支队伍!
目前榜单前三名的队伍在参赛中有哪些实战的经验呢,让我们一起听听他们的分享吧!

剃刀鲸是鲸吗-获奖经验分享
数据处理
在数据处理方面,我将每个站点的最后10%的数据作为验证集,其余数据用于训练。在原始的iTransformer模型上,CV和LB之间的相关性较好,但在进行模型的魔改之后,CV和LB之间就没有什么关联了。目前还在找其他的CV的构造方案。
特征工程
在特征工程方面,目前是简单提取了一些较为常规的特征。比如说,对wind和temp进行diff和rolling,并对协变量的9个站点求均值等。
模型
模型部分依然是采用baseline的iTransformer,在改进模型的时候主要参考了上一周的周周星方案,对encoder,decoder进行了一些改进,例如加入LSTM层。感觉算是一个比较稳定的上分点。但是魔改了之后,模型会出现一定的过拟合,所以这里要控制好模型的层数。
trick
之前看到群里讨论的本地的CV和LB差别特别大的问题。其实这里不一定是过拟合,也有可能是因为特征提取的问题。因为给的数据是一整个序列,而测试的时候是采样的多个子序列,这种数据格式的差异就可能会导致提取的特征存在一定的问题,从而造成本地拟合的很好,而一到线上效果就会很差。所以在构造特征的时候,应该先对整个序列采样做成训练用的子序列,再做特征。
虎牙181469-获奖经验分享
大家好,我是虎牙181469的队长张嘉文,目前工作是在数据处理相关的,个人兴趣喜欢东学学西学学。今天给大家分享一下我做这个比赛的整体思路,重点是思路两个字。
看了第一名的分享,我和他的不同之处是,我没有做任何一个额外的特征,单纯是模型的搭建和数据的过滤。
MMoe整体建模分享:
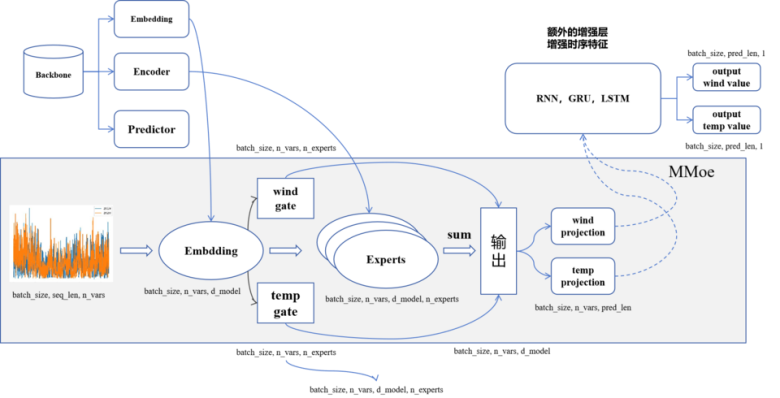
模型的上限有一部分取决于数据,数据分析很重要,我做了几乎半个多月的eda,试了各种剔除脏数据的策略,最终迭代到了现在手头上的一版,所以大家应该多花时间在数据研究上,尤其是这种偏数据挖掘的任务(第一次做这类型的任务,之前是搞NLP的,不太需要研究数据方面的东西)。
一些划分时序数据的方法,我从kaggle上搜到的,大家可以试试,对于多折融合应该有帮助
https://www.kaggle.com/code/konradb/ts-10-validation-methods-for-time-series#Combinatorial-purged-group-KFold
一些体验融合收益的实验:
之前单模单折iTransformer 1.00的版本,跑了个10折是0.99(提升不到);然后我用这个外加在此基础上改造的MMoe版本(2个专家),跑了10折,即得到了20个子模型,55平均融合的得分是98.00。
目前我的榜上最高分是单模全量数据(过滤后的)训练得到的MMoe版本的iTransformer模型,成绩为0.946,搞个10折融合估计有0.936左右。
一些后处理的方法,还没实现的,个人猜测线下构造测试集(未知站点,然后与验证集的同时段),用训练好的模型预测出温度、湿度曲线,计算该曲线与真实曲线之间的偏差,将偏差应用于预测结果。
一些通用的在NLP上的trick也是可以沿用到时序上来的:EMA、SWA、MODEL SOUP、rdropout 等等。
现在我感觉eda方面没有必要继续进行了(我已经搞的差不多了感觉),模型的架构也加的差不多了,后续我会继续模型的各个子层。
还有个未解决的问题,就是时间轴信息怎么用,因为比赛数据是2019.1到2020.12的,所以很好抽出来,但是测试集是未知的,这个时间轴信息就不好用了,有没大佬可以分享下怎么用?我用了像iTransformer里默认的方法,直接拼接在embedding之后的x_enc特征之后,但是效果不好。
以下是构造时间轴特征的代码,有兴趣的可以研究研究:




总的能分享的就这么多,我的整体路线:
做好EDA,得到高质量的数据;
建好基础模型架构,才能充分体现模型的能力;
模型的训练策略也很重要,它也决定了你模型是否能够更好的收敛、会不会过拟合严重等等;
做好融合策略,调研好差异性能力相当的模型,比如inverted和非inverted的;
研究好后处理,保持良好的心态,我第一次打这个,碰到很多困难,坚持下来就行了。
我的github主页:https://github.com/fuxuelinwudi ,
可以follow一波,比赛拿奖一般都会开源代码。
tips:还好这些比赛的数据量大,并且适用于nn,不然我这种不会数据挖掘的(不会做特征的渣渣)就可以直接放弃了。
MISX-获奖经验分享
hello各位,我是MISX,我是本科大一,我简单介绍下我们现在的提分过程。
采用的手段大部分是来自上一周周周星大佬的分享,我们所有的工作都是从baseline开始,1.09调了一下参数,itrans1.06更改了itrans模型的结构(主要改了解码器部分,原模型的解码器是线性层连出来的,可以稍微更改一下),itrans0.98最后就是进行数据的后处理(考虑上周分享的各种平滑办法),到了大概现在的分数。
最近我们在尝试融模:TST timemixer都有尝试,效果其实都很一般,我觉得可能是因为我们没调好参数的原因。
我们在大致思路上的分享肯定不如榜一榜二两位大佬,我接下来分享一些细节:
我们没有进行mmoe,而是分别预测wind和temp,但在dataloader里面我们加了一个通道(原37),加的就是另外一个因变量的数据,比如对于temp,我们加入了wind的168时间点数据,这其实某种角度我们也算是利用到了另外一个因变量相关的信息。
我们没有进行数据集划分,一直是使用全量数据训练。
原代码训练里面他每100个iter打印的loss取得是瞬时loss.item() ,这里可以换成avg(train_loss),能更好的看一下模型的训练过程。
我们尝试了将原先协变量单纯堆叠三次的方法更改为对每个通道进行线性插值,但是结果提升并不明显,后面考虑在其他模型里面去用这种办法。
有关算力的问题,我们一直是在算力平台上租赁服务器,我们的配置是4090,bs一般40960,有部分跑不了的情况就用20480。
有关模型融合,我们目前采用的模型融合的办法是直接加权,这个权值基本就是按照线上分去加。
我们在训练的过程中发现在相同轮数下temp一般很快就过拟合了,但是wind那边还可以接着训一训。
优化器可以考虑换成adamw,但是拟合的可能会更快。
我们队基本只做了这些事情,分享的内容相较榜一榜二大佬比较少,后面各位如果有什么想问的欢迎在评论区提问,分数是0.97左右,基本就是极限了,我们这个分数跟榜一榜二有断档的差距,后面我们也向榜一榜二提出的各种nb办法学习。

本次大赛组委会精心为每周的周周星获奖者们准备了琳琅满目、极具民族特色的奖品大礼包,让我们先一睹为快!



上下滑动浏览
特别介绍:大赛主办方之一、决赛比赛地点预告
——鄂尔多斯欢迎你!

鄂尔多斯,这座融合了古老文明与现代科技的活力之城,以它独有的“暖城”魅力,张开怀抱欢迎来自世界各地的参赛者。作为内蒙古经济发展的领航者,鄂尔多斯在新能源、新材料、现代煤化工以及羊绒产业等领域树立了世界级的标杆,这里不仅拥有国家煤炭保障基地的坚实后盾,还有清洁电力供应、油气战略储备、氢能应用示范及储能实证的前沿探索,是国家能源安全的坚实“压舱石”。
在这片充满无限可能的土地上,大数据挑战赛不仅仅是对参赛者的历练,更是鄂尔多斯展现其魅力与潜力的窗口。大赛期间,除了紧张激烈的比赛,选手们还将有机会漫步在鄂尔多斯的蓝天白云下,体验草原文化的民族特色,感受生态与人文的和谐共生,见证这座城市在创新驱动下的日新月异。


初赛已进入到白热化阶段,同学们参赛热情持续高涨!目前已有来自370多所高校和企事业单位参赛,报名总人数接近2500人。大赛报名系统将于7月12日12:00关闭,参赛选手可以继续从指定网站下载比赛的训练数据和测试数据,并在线提交相关模型文件。
每一次努力都值得被看见,每一份才华都值得被赞赏。让我们一起,用代码书写梦想,用数据描绘未来!

欢迎了解更多(数据派THU菜单栏-关于我们-大赛入口)
• 大赛官网:http://nercbds.tsinghua.edu.cn/bdc/
• 大赛小程序:可赛
• 大赛邮箱:data@tsinghua.edu.cn
• 大赛 QQ 群:762146461 / 901317172
点击阅读原文,观看大赛启动会直播回顾
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









