




来源:NewBeeNLP
本文约8400字,建议阅读15分钟
本文为你分享小红书在去中心化分发方面的一些工作和对未来的展望。小红书作为在国内因种草而声名大噪的社区,伴随用户规模的扩大,已逐渐发展成为多元化的线上社区。众多用户通过笔记来记录和分享自己的生活方式,当前每日可分发的内容多达数十亿,每日新增发布的内容有数百万之多,涵盖图文与视频等形式,这些我们称之为笔记。目前小红书每日可产生数百亿次的曝光量,每日超过一半的用户在小红书内产生互动行为,每日搜索查询量达到亿级。就产品形态而言,小红书现分为双列信息流和视频沉浸流两种。

今日分享提纲:去中心化分发问题的定义、分析和相应的解决办法;从强化 sideinfo 使用、多模信号全链路融合、兴趣探索及链路保护三个方面,分享小红书在去中心化分发方面的一些工作;对未来的展望。
主要内容包括以下几个部分:
1. 业务背景介绍
2. 强化 Sideinfo 使用
3. 多模信号全链路融合
4. 兴趣探索及链路保护
5. 未来展望
01、业务背景介绍
1. UGC 社区
小红书 UGC 社区与其他社区类似,主要由三个重要组成部分构成,分别是内容、消费用户和创作者。这三者紧密相连,其中内容是作者与用户之间的桥梁,若具备足够丰富多样的内容,我们就拥有广阔的精细化分发空间。
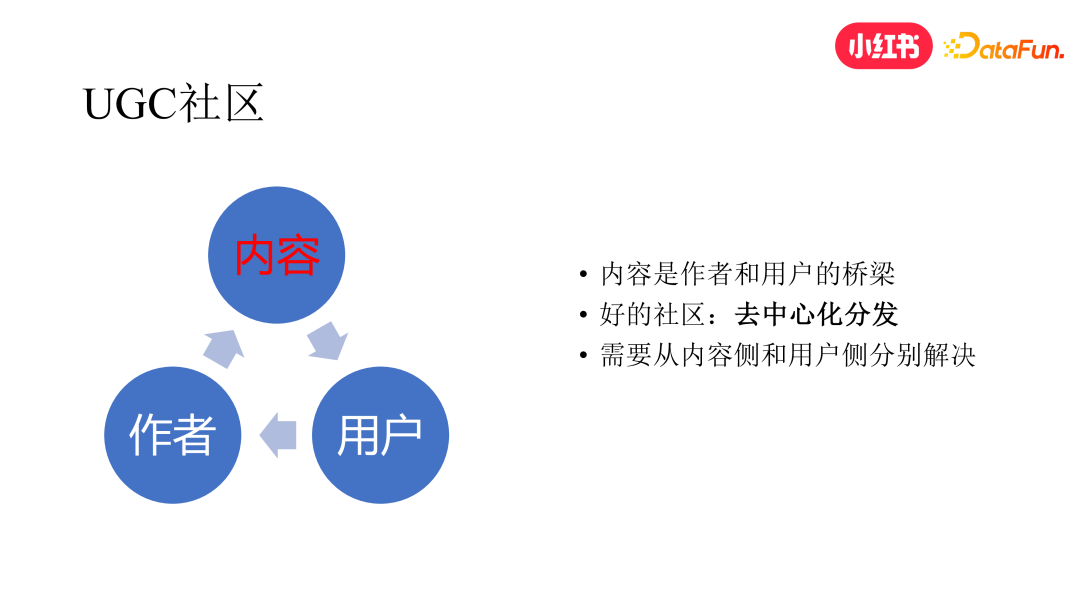
中心化分发问题的本质在于曝光越多、活跃度越高的内容,往往能获得更多的分发,致使普通创作者的内容分发效果相对较差。此外,用户可能也会频繁看到热门兴趣,导致自身中长尾兴趣的内容所见相对较少。若要构建生态良好的社区,去中心化分发问题是需要解决的核心问题。
结合上述两点,去中心化分发应从内容侧与用户侧分别解决。对于内容侧而言,应设法通过多种方式识别和引入笔记本身的更多信号,而非仅依赖用户对笔记的行为进行分发。对于用户侧来说,应设法对用户的兴趣进行更优的挖掘,并在挖掘后予以一定的保护,鼓励用户中长尾和小众兴趣的内容分发,使用户的兴趣得到更全面的满足。
2. 核心问题
去中心化分发本质上就是要解决两个问题,一方面是让我们的系统学的更快,一方面是让我们的系统学的更好。
学得快:整个系统链路学得更快,才能更快地捕捉到中长尾内容的信号和用户中长尾的兴趣。这对于内容冷启动和用户冷启动也非常重要,如果一个新笔记在冷启动阶段就没有得到很好的分发,那它就很难走到下一个阶段。同样的,如果一个用户刚刚表现出一个新的兴趣或者小众的兴趣,没有被立刻捕捉到,这个用户可能就会因为没有看到自己想看的东西而流失。中长尾内容同理,也会导致作者的发布欲望下降。
学得好:光是学的快其实还不够,因为中长尾兴趣和内容的分发最终能不能满足用户和作者的要求,还要取决于系统学的好不好。想要做到这一点,必须要保证系统链路的每个环节对这些兴趣和内容都能做有效的透出。如下图所示,整个推荐系统包括召回、初排、精排、后排这几个阶段,推荐系统的目标是希望拟合用户真实的兴趣分布。在这方面,去中心化其实是个特殊的问题。过去推荐系统的核心动作是通过排序模型优化来将用户的消费指标不断做高,但用户消费指标提高不一定意味着整个系统的去中心化分发变得更好了。下游的供给是来自上游的,如果上游给的内容就不好的话那下游怎么排也是排不好的,所以对去中心化
分发这个问题,反而越是上游链路越重要。

举例来说,曾经我在搞围棋 AI 的时候遇到过一个问题,当时我们学习了一个 RL Policy,但这个模型经常到了 200 步之后就下的非常差。我们对这个模型本身做了很多的调整,但最后都没有什么用处。后来我们发现问题出在 SL Policy 模型上,这个模型是通过人类棋手的监督数据学习而来的,但是对于人类的九段棋手来说,有很多高手在中盘就知道自己输了,所以经常不会下到 200 步以后,导致这样的数据很少,且噪音比较大,那基座就学不好这个信息,基于这个基座学习的下游模型效果也不会好,所以这是一个蛮重要的问题。
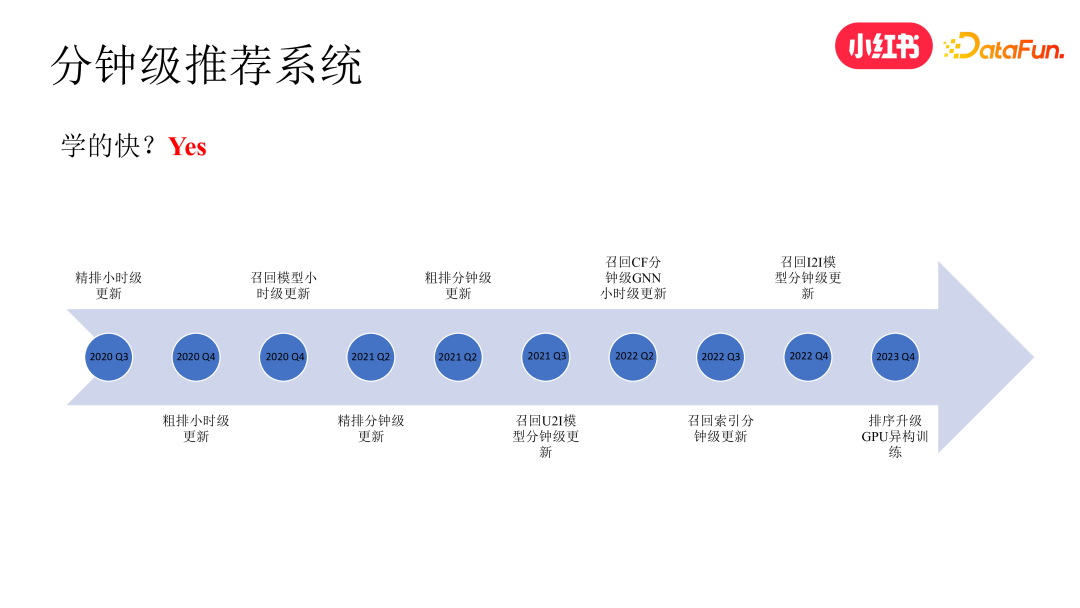
3. 高时效推荐系统 for“学的快”
小红书在 2020 年 Q2 之前,推荐系统的主要模块都保持在天级更新的状态。为此我们经过两年的持续迭代,通过数据流、训练框架、索引框架的改造以及实时计算技术,先后把精排、粗排、召回模块都做到了分钟级更新的状态。后来我们还进一步将初精排模型的训练也升级到了 gpu 异构训练的状态,就是 cpu worker 和 gpu worker 也是分开的,这个可以进一步提高模型的更新速度。
4. 链路分析 for“学的好”
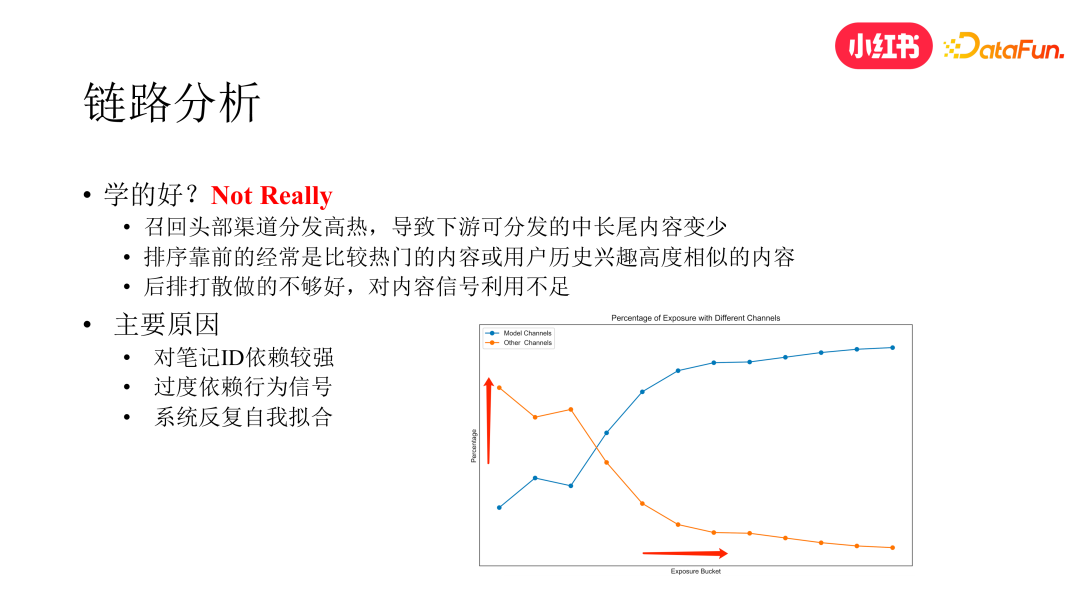
经过对整个系统链路的分析,我们发现在“学的好”这个方面,很多模块都是有优化空间的。
召回方面:我们对核心召回渠道做了一个曝光维度的分析,如下图。横轴是笔记按照曝光数的分桶,纵轴是不同召回渠道在不同曝光分桶上的分发占比。我们在召回方面上线了多目标、一致性、高精度等多路召回,时效性也都到了分钟级,虽然整个大盘的消费指标是变好的,但数据分析显示主要是在曝光比较高的区段变好的更多,在曝光比较低的区段表现仍是不好的,反而是其他的非头部渠道在曝光比较低的分段区间表现的更好,而这些渠道多为纯 CB 的召回渠道。
排序方面:我们发现如果我们不做任何干预,自然排名靠前的大多是比较热门的或者是与用户历史兴趣高度相似的内容,且新笔记排名并不高。
后排方面:高活用户的历史兴趣存在扎堆的现象,即使通过笔记类目进行打散,也未获得理想的效果,还会折损消费指标。
(1)原因分析
在当前模型的特征体系中,对笔记 id 本身的依赖过强
过度依赖用户行为信号,虽然也用了一些内容信号,但对内容信号的学习和利用并不充分,未能有效发挥内容信号的作用
系统反复自我拟合,导致信息茧房问题
(2)解决思路:从内容侧和用户侧分别来解决,双向奔赴
特征侧,除对笔记 id 特征的学习外,强化对 sideinfo 的利用
内容侧,尝试进行全链路的多模内容信号的引入
用户侧,系统性地加强用户的兴趣探索与保护
02、强化 Sideinfo 使用
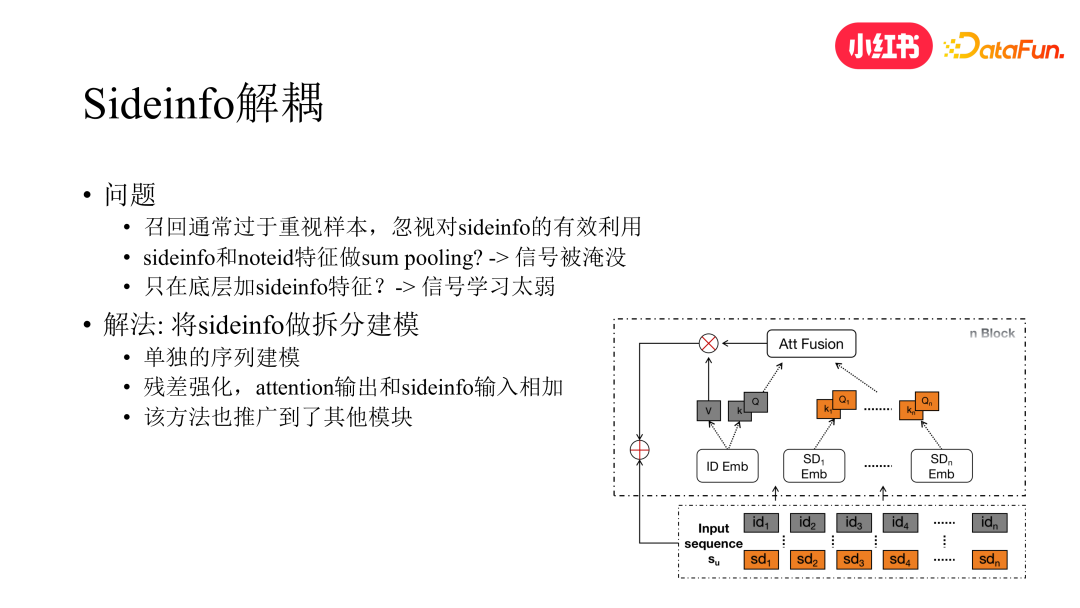
1. Sideinfo 解耦
考虑到召回是最上游的链路,对去中心化问题比较重要,我们首先从召回的角度尝试优化了 sideinfo 的建模方式。在召回模型中,对 sideinfo 的使用通常比较简单,一方面是直接作为模型最底层的特征输入,但这样会导致信号学习比较弱,另一方面是 sideinfo 的 embedding 通常会和笔记 id 的 embedding 做 pooling 融合,这样会导致 sideinfo 信号被淹没,不同的 sideinfo 之间区分不清晰。
为解决这个问题,最直接的方式就是将 sideinfo 进行单独的拆分建模。拆分之后,除原本对用户 lastn 的序列建模外,还会对 sideinfo 做单独的序列建模。具体如下图所示,我们先基于 Q 和 K 分别算出 id 和 sideinfo 维度的 attention score 后再与 V 相乘。此外,为进一步强化 sideinfo 信号的学习,我们引入残差的做法,将 sideinfo 与 attention 的输出结果相加,进一步提升 sideinfo 在整个模型中的影响力。此方法也推广到了排序模块。
2. 图模型融合 sideinfo
提到用户兴趣泛化与长尾内容泛化,就不得不提到图模型,图模型相较传统算法主要优势就在于其泛化能力和可扩展性,故引入图模型来强化 sideinfo 的使用是一个很自然的做法。不过如果直接将 sideinfo 作为图中的节点加入学习,难以直接取得理想效果。首先,若为纯 content-based 的做法,在推荐系统被行为信号主导的情况下,下游的透出率无法保证。虽然我们可采取一些手段进行干预,例如通过中间链路进行保量强制其透出,但做法较为生硬,效果也比较有限。其次,若对图上的数据不做任何干预直接进行学习,图中会存在诸多的 bias,致使图模型学习产生偏差。为此,我们从以下两个方面进行优化。
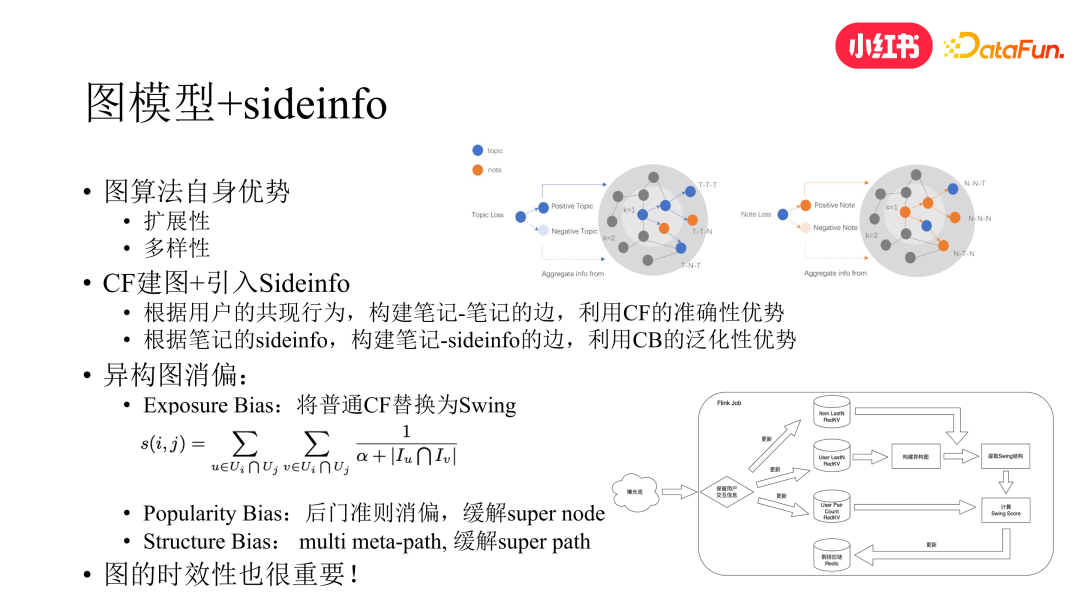
首先,我们还是要想办法将用户的行为数据与纯 CB 的数据进行融合。比较直接的做法就是从图中的边入手,我们可以采取 CF 的方法来构建图中笔记到笔记的边,同时根据笔记的 sideinfo 构建笔记到 sideinfo 的边,这样图中就同时兼具了 CB 与 CF 两种信号。
然后,在引入了基于 CF 的边之后,需要面对的一个问题是 CF 本身存在 exposure bias 的问题,即标准 CF 通常比较偏向于出高热的内容,这对中长尾内容其实是不友好的。因此我们将标准 CF 算法升级为 swing 算法。在 swing 算法中,如果一个中长尾内容被两个用户同时看过,而两个用户看过的笔记又比较少,即其兴趣本身也较为长尾,那么根据 swing 公式的计算原理,不需要经过太多次的曝光,这两个笔记的相似分数就会比较高,从而以更高的概率被召回。
此外,由于不同的 topic 关联的笔记数量各异,就会导致少部分的 topic 连接着大部分的笔记,这又会引入 Popularity Bias。为此我们引入因果推断中的后门准则做法,将 topic 视为 treatment,通过后门准则的消偏概率公式,对 topic 到笔记的边权进行调整,缓解了所谓的 super node 的问题。而图中除了 super node,还存在 super path,即在图游走的过程中部分 path 会更频繁的出现,这些 path 都放在一起学习也会导致频率出现较低 path 的信号被湮灭。为此我们又引入了 multiple meta path 的做法,针对不同的 meta path(如t-> t->t、t->n->t、t->n->n、t->t->n等)通过不同的 mlp 网络进行学习而非共享 mlp。不同的 meta path 对应的 mlp 的输出 concat 之后再作为后续网络的输入,从而缓解了这个问题。
最后,我们发现图的时效性也很重要,对算法效果能否有效地发挥也有很大的影响。而图想要做到快速的更新是有挑战的,业界很多公司也在做这方面的工作。就我们这个图来说,图中包括 CB 和 CF 两种边,CB 边可迅速更新,但 CF 边是通过 swing 计算得到的,而在小红书的数据体量下,swing 全量计算是需要天级才能完成的。为解决这个问题,我们将 swing 算法从 batch 计算升级为 flink 流式计算,从而解决了这个问题。
3. sideinfo 在排序中的应用
在排序中,sideinfo 主要是在各种 attention 中发挥作用,attention 分为 hard attention、target attention 和 self attention 几种。
hard attention 方面:通过 target item 的类目或属性等 sideinfo 作为 hit 条件,将命中的 lastn 的表征进行融合,同时将 hit 作为统计值特征,与原始的 embedding layer 进行 concat 作为模型特征输入的一部分。
target attention 方面:将 sideinfo 作为 target attention 模块中的基础信息来计算不同 lastn 的权重,然后根据该权重对 lastn 的表征进行加权融合,同时对 sideinfo 做 early Fusion,即将 target item 的 sideinfo 在 attention 之前就与用户 lastn 的 sideinfo 进行融合,使其学习更加充分。
self attention 方面:基于 sideinfo 在用户侧内部做 self attention,同时以 sideinfo 构建 gate 网络,来学习各自 lastn 的兴趣强度。
最后,以上方法相互之间做融合,可取得更好的效果。而对 sideinfo 最极致的使用莫过于最近 meta 发表的 rankGPT 排序模型。在 rankGPT 中,user 侧除 userid、基础属性特征以及 lastn 外,仅保留 sideinfo,其余的统计特征一概不用。在大数据 + 大模型的方案下,模型的效果最终超越了 meta 的基线模型,并验证了 scaling law。其实关于这一点我本人也是比较看好的,在当年围棋AI 的调研过程中我们就发现 20+ 特征的版本效果甚至优于 50+ 特征的版本。在那之后 AlphaZero 横空出世,其特征仅寥寥数个,纯靠自身进行 selfplay 学习,不知rankgpt是否受此启发。所以在 sideinfo 这个维度上,我相信类 rankGPT 的方案最终是可以走通的。业界常说排序模型是特征的艺术,这个说法在未来的某一天可能会被彻底颠覆。

03、多模信号全链路融合
前面讨论了 sideinfo 如何建模的问题,接下来我们从 sideinfo 本身的质量出发来强化中长尾内容和兴趣的分发。相比类目、keyword、topic 等 sideinfo,多模表征也是 sideinfo 很重要的一种,且蕴含的内容信号更为丰富。在这个章节中我们介绍如何通过多模信号来强化 sideinfo 的表达能力,以及如何通过多种方式将其应用于我们的推荐系统。
首先提到一点,小红书的多模态技术已经经过数轮迭代,从基于 CB2CF 的对比学习方案逐渐演变为基于大模型的方案,在 post-pretrain 阶段,会引入下游的监督信号进行训练,使多模态表征融合了行为信号,而非纯内容信号本身。目前小红书笔记的多模态表征已广泛应用于小红书的多个场景。
1. 多模对比学习
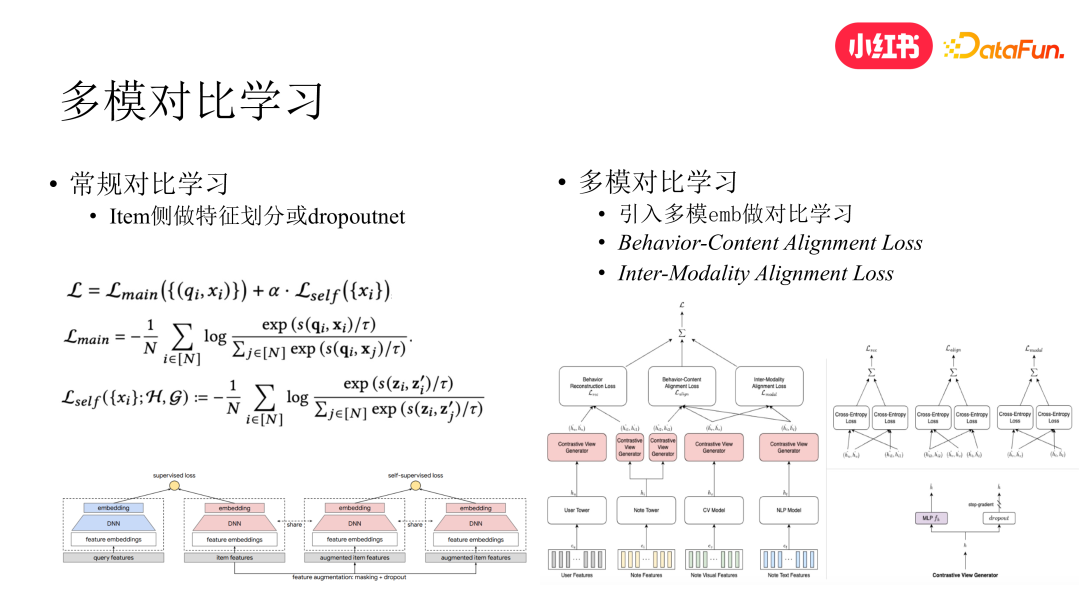
首先,使用多模信号不一定非要通过加特征的方式,我们试过直接在模型底层加特征,发现效果比较一般,这个和上面 sideinfo 解耦部分提到的问题类似,因此我们尝试了对比学习的方案来进行多模信号融合。
常规的对比学习,通常是对 item 的特征进行划分或 dropout,对同一个 item 的两个表征进行对比学习,以强化中长尾笔记的分发,但该方案并未引入额外的内容信号,因此主要还是在依赖行为信号进行学习。我们在此基础上引入多模信号,并将对比学习的方案进行升级。我们直接将多模 embedding 与常规双塔召回中的 item embedding 进行 alignment。整个方案分为域内 alignment 和跨域 alignment 两部分,域内是指笔记的 text 和 image 的 embedding 进行内部 alignment,跨域是指将笔记 text 和 image 的 embedding 与 item 塔输出的 item embedding 进行 alignment。加上原本 u2i 模型中 user embedding 与 item embedding 的 alignment,三个 loss 进行联合训练,取得了比单纯在模型底层添加多模表征更好的效果。此方案参考了 NIPS 2020 deepmind 的一篇工作。
2. AlignRec 框架
受此上面工作的启发,我们进一步提出 AlignRec 框架,此框架在上述方案基础上更进一步,提出一个更通用的多模态推荐框架。该方案在多个开源数据集上达到了 SOTA 效果,目前已被 CIKM 2024 Full Research Paper Track 接收。整个框架分为以下几个阶段,具体见下图:
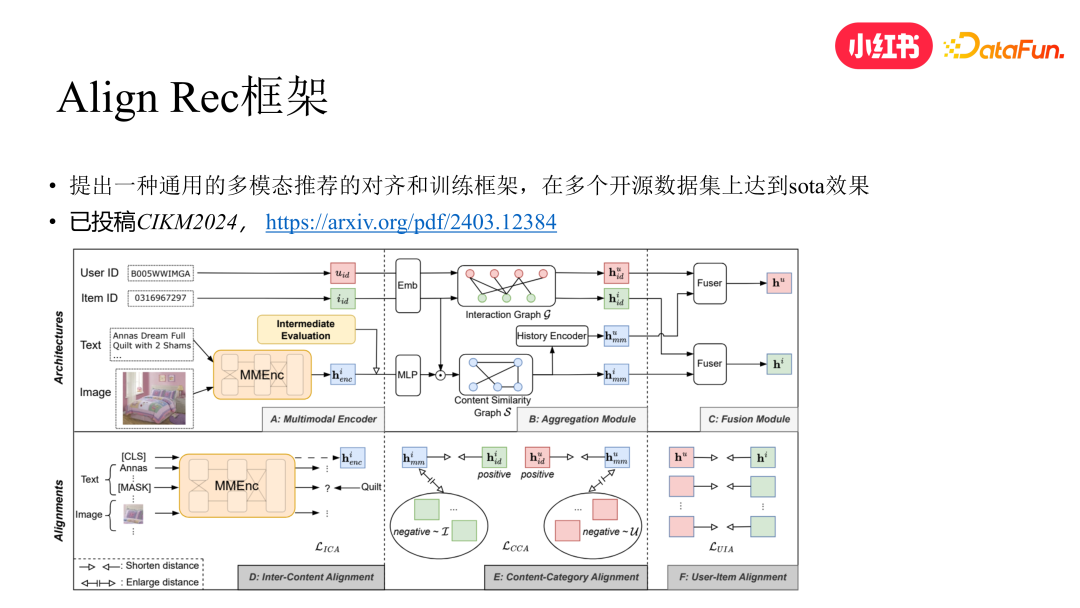
(1)通过 MMEnc 模块将 text 和 image 的 embedding 内部进行对齐与融合,得到 item 在内容侧的表征
(2)对 user 和 item 的行为侧原始表征基于 user 与 item 的行为图做融合
(3)内容侧的 item 表征会先和行为侧的 item 表征做 Fusion,然后基于内容侧 item 表征的相似度构建图来对 fusion 后的 item embedding 做 aggregation 得到 item 的内容聚合表征,然后 user 侧会根据 user 和 item 的行为图做聚合,得到 user 在内容维度的聚合表征
(4)user 和 item 的行为聚合表征分别和内容融合表征做 alignment 作为辅助 loss
(5)user 和 item 的行为表征和内容表征各自相加,得到 user 和 item 的跨域融合表征并做最终的 alignment
3. 多模特征交叉
由于多模表征作为特征直接加在模型底层效果微弱,因此我们对多模在底层的使用方式进行了探索,包括召回和排序模块。
(1)召回方面
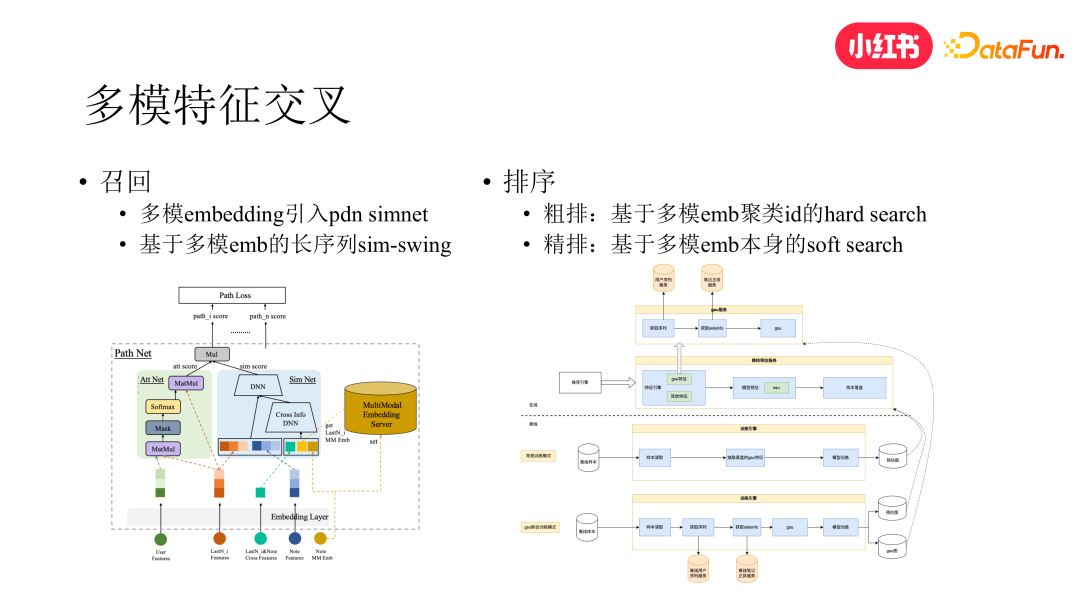
在过去我们上线了 pdn 召回,该路召回的亮点是做了 u2i 和 i2i 的联合建模,但分析发现它的内容分发仍然偏向于头部内容。因此,我们对 pdn 召回做了升级。我们将 trigger net 部分改成了 attention 结构,同时在 simnet 部分引入了笔记的多模信息,即通过查表的方式得到用户 lastn 和 target item 的多模表征,作为 simnet cross dnn 的输入,通过特征交叉的方式在 simnet 的学习过程中引入多模信息。升级后的 pdn 对于中长尾内容和兴趣的分发效果提升显著,并带动了大盘的消费指标。
此外,我们还做了基于多模表征的长序列 swing 算法。前面提到,我们把 swing 升级到流式计算后,由于不能全量计算,只能保留用户近期的 lastn,导致算法对用户长期信号的捕捉变弱。为缓解这个问题,同时考虑到性能,我们做了类似排序 sim 的做法,首先基于多模 embedding 从用户长期行为序列中检索出跟 target item 比较相似的 lastn,然后将得到的结果和原始的 online swing 放在一起同时做训练,对用户中长尾兴趣和长期兴趣的捕捉取得了不错的补充效果。
(2)排序方面
初排方面,考虑到初排的线上性能压力,直接通过多模表征做相似检索的性能是难以接受的,所以在初排我们是通过多模 embedding 聚类得到的聚类 id 对 user lastn 做 hard search 来进行多模特征交叉
精排方面,直接用多模 embedding 来做 soft search。我们设计了 GSU+ESU 的架构,在离线训练时用户 lastn 通过本地静态表的方式接入笔记的多模 embedding 进行训练,模型导出时会导出成 GSU 和 ESU 两张子图在线上分别做部署。GSU 子图放到线上后,特征引擎通过 RPC 的方式调用 GSU 服务,GSU 在图内基于 target item 的多模 embedding 对用户 lastn 的多模 embeddings 做检索,得到最相似的 topk lastn,然后再将 topk lastn 及其相关特征送入通过 ESU 子图做 attention 建模。
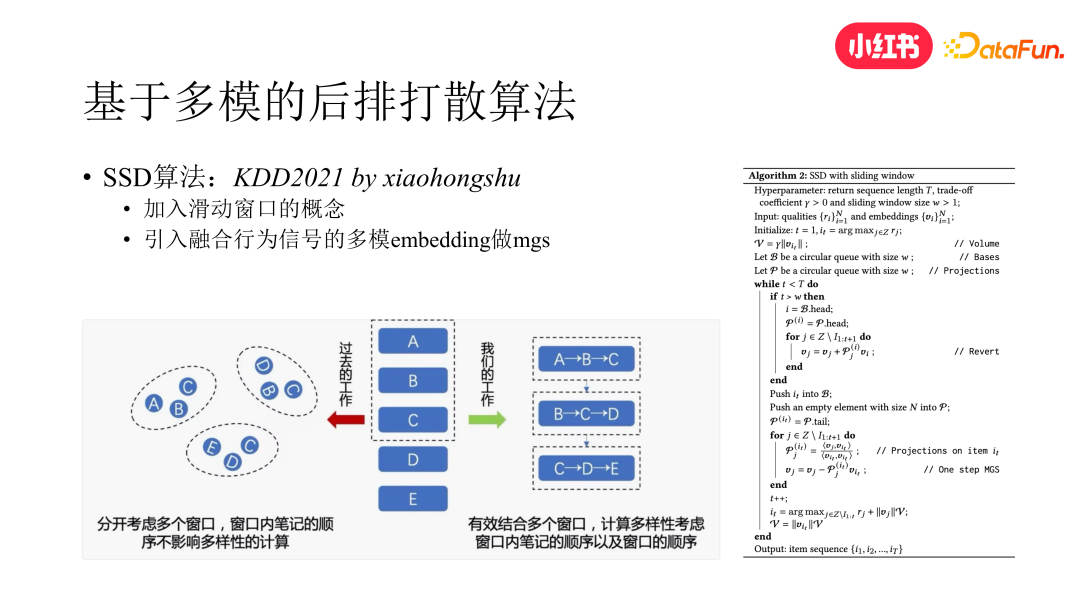
4. 基于多模的后排打散
在业界通常会有个认知,后排打散通常会带来消费指标的损失,但我们验证下来之后发现,多样性的提高和消费指标的提升其实是不冲突的,如果出现跷跷板效应,那还是因为打散没有做到个性化的多样性。
我们在 KDD 2021 上提出了一种解法。该做法包括两方面,一是加入滑动窗口的概念,二是引入融合行为信号的多模 embedding。滑动窗口有效地结合了多个窗口,我们把窗口之外的笔记先通过逆 MGS 的方式做向量还原,然后对窗口内部笔记的 embedding 重新做 MGS 分解,得到当前位置的候选笔记的 embedding,再根据该 embedding 计算与前面内容的相似度,并结合当前内容的相关性分数最终确定当前位置选择哪个笔记。可以看出,笔记 embedding 的质量对这个算法是非常重要的。如果我们基于纯 CB 的 embedding,由于 embedding 中没有行为的信号,直接做打散就会对消费指标带来负向的影响。因此我们通过对比学习的方式,提前得到了融合行为信号的多模 embedding。后来我们对该算法使用的多模 embedding 再次做了升级,又带来了多样性和消费指标的双提升。
04、兴趣探索及链路保护
上面介绍了从内容侧来解决去中心化分发问题的一些工作,接下来我们介绍下在用户侧解决该问题的一些思路。从用户角度来说,看不到中长尾兴趣的内容,有很大的原因是因为系统总是在拟合用户的历史兴趣。想要打破这一点,就需要引入兴趣探索和兴趣保护的能力。
1. 显式多兴趣
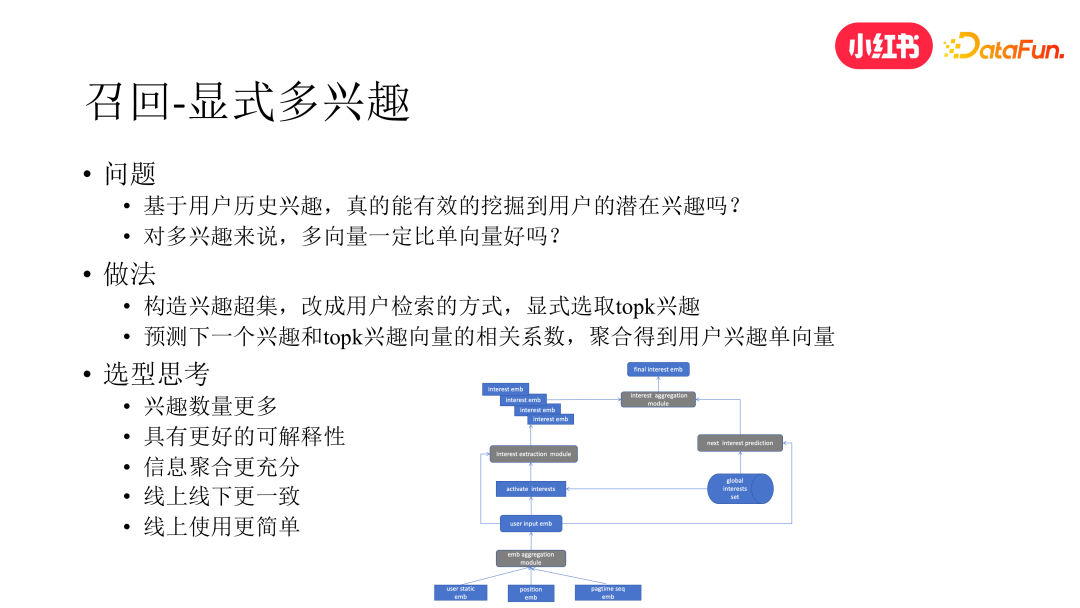
首先还是从召回模块入手,多兴趣模型是召回阶段做用户兴趣探索的常用手段之一。我们曾尝试了一些基于多向量的多兴趣做法,包括 mind、comirec 等,但在多样性和中长尾内容分发方面没有得到理想的效果。经过分析我们发现:其一,若直接基于用户的 lastn 做聚类,本质上还是在完全依赖用户的历史兴趣做建模,而用户的潜在兴趣在用户的历史行为中还比较弱势,不进行显式的挖掘很难直接获取。其二,多兴趣不等于多向量,多向量的效果也未必优于单向量,还会引发一些其他问题,例如会导致线上性能压力升高,限制探索兴趣的数量。其三,多向量的做法还是很难做到精准的个性化,同一用户的不同向量所代表的兴趣难以显式区分和解释,不同用户的多向量所代表的兴趣也难以做到全局概念上的对齐。
为此,我们反其道行之,相较于隐式挖掘多兴趣,我们改为显式挖掘的方式。具体来说,我们先构建一个客观存在的全局兴趣集合,这样兴趣集合中的每一个向量都代表着一个相对明确的兴趣。然后我们通过检索的方式,基于用户 lastn 从这个兴趣超集中显式选取 topk 的兴趣。接下来我们预测用户的下一个兴趣与当前所选择的 topk 兴趣向量的相关系数,然后聚合得到用户的兴趣向量,最终只将该单向量应用于线上。这种做法从性能和效果来说都取得了比较理想的效果,且具有更好的可解释性。
2. EE 兴趣探索
说到兴趣探索,就不得不提及 EE。目前工业界 EE 方面的工作大多都在更靠近用户的后链路展开,因 EE 如果做在前链路,受到下游链路的影响,最终对用户的实际影响会受到较大的削弱。然而,对去中心化分发问题来说只在后链路做 EE 是不够的,如果只是做在后链路,那一个很大的问题是若前链路下发的用户中长尾兴趣的内容本身就很少,那么探索的天花板就比较低,因此我们需要在前链路就设法通过 EE 将用户中长尾兴趣的内容挖掘出来。但仅在上游链路完成探索,下游链路若没有有效承接,还是会导致整个 EE 的效率比较低。
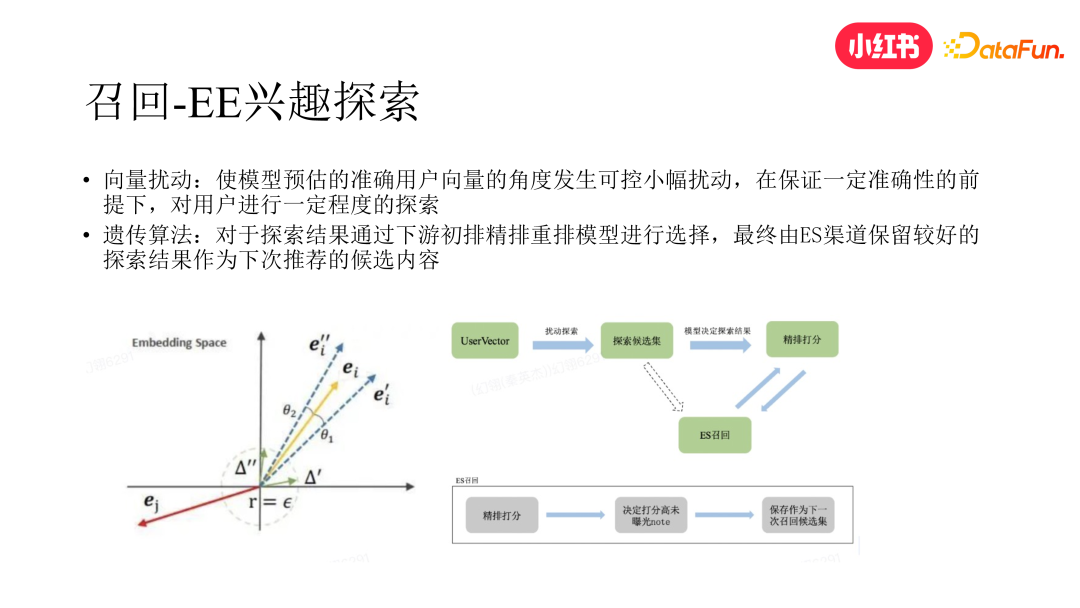
为兼顾以上两个问题,我们提出了一种新的 EE 做法。
首先,我们在召回阶段对用户的召回向量表征加一些高斯噪音扰动,获取一个新的召回向量,得到相应的召回结果。
然后,我们采用了基于 Evolution Strategy 的策略,将下发未曝光但在下发排名较高的当次探索内容进行保存,参与后续的召回。在这个过程中,我们将召回模块作为交叉再生算子,将初排和精排漏斗当作遗传选择算子。在下一次召回时,会从前n 代最后下发的头部笔记中选取未得到曝光的那些探索笔记,作为结果重新参与召回的再生。
我们发现这种系统性的 EE 做法,相较于单纯在召回阶段对向量扰动做 EE,对整个系统在中长尾兴趣的内容分发方面产生了更显著的影响。
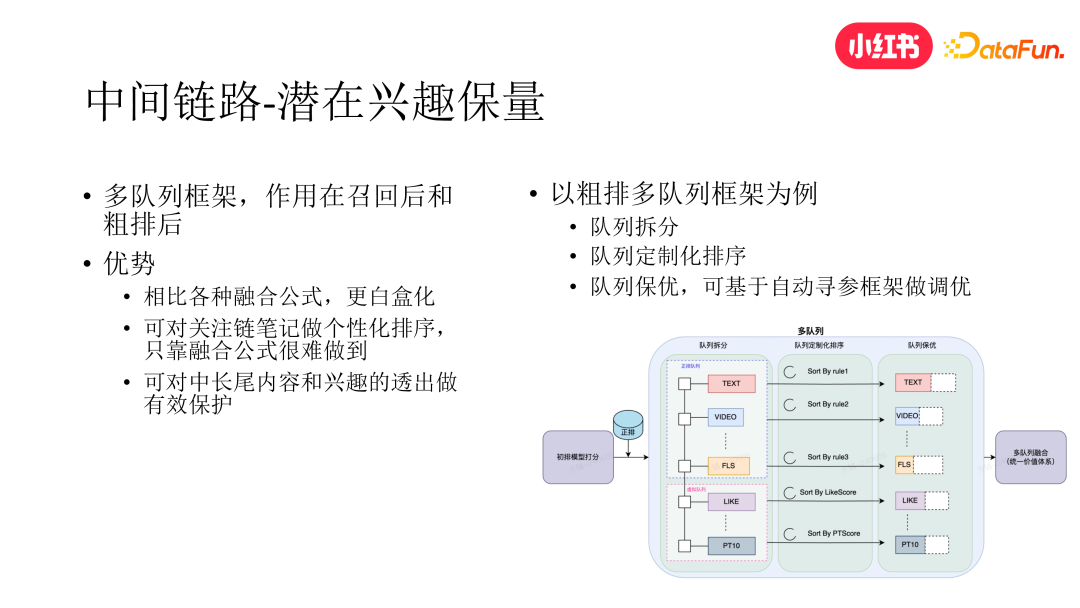
3. 中间链路兴趣保量
受到 EE 做法的启发,我们发现除了兴趣探索之外,中间链路的兴趣保量也很重要,只探索不保护会导致兴趣探索最终无疾而终。从召回阶段的兴趣挖掘,再到最终曝光给用户,推荐系统中间会经历召回进初排、初排进精排等多个阶段。在兴趣保护方面,已有的做法大多是通过调整初精排的融合公式来对那些希望最终能展现给用户的内容做一些提权,但这种做法有两个比较大的短板。首先这种做法比较黑盒,对系统全局的影响不得而知。其次,某些特殊需求无法通过融合公式的调整直接做到,比如关注渠道是对中长尾内容和兴趣有效分发的渠道之一,如果我们想要单独调整某次下发中关注链笔记集合的内部序,通过全局的融合公式很难做到。
为此,我们构建了白盒化的多队列保量框架,来和黑盒化的融合公式做互补。以初排进精排阶段的多队列为例(召回进初排我们也加入了多队列框架),我们从多个维度对初排进精排的笔记进行了队列拆分,每个队列内部可以进行定制化排序,这样就能解决前面所说的关注链笔记个性化排序无法实现的问题。再者,每个队列可进行独立的截断,目前我们已经实现了一套基于 Evolution Strategy 的自动寻参工具,可通过该工具对每个队列的截断值进行超参自动寻优。
4. 基于大模型的潜在兴趣挖掘与强化
最近一年大模型技术正在引领一场新的技术革命,大模型对于大多数问题的理解能力远远超过许多传统的模型,因此展现出在兴趣挖掘方面强大的潜力。鉴于大模型的性能要求很高,直接将其作为在线模块用于用户的兴趣探索目前并不现实。为此小红书采取了一种折中的办法,首先基于 COT 原则设计了专门的 prompt 构造用户画像,然后通过小红书自研的大模型基座 tomato-7B 离线预估用户的潜在兴趣,将得到的结果通过 SIMCSE 模型与已有的标签体系做映射,最终对命中标签的笔记在后排阶段给予助推,从而和前链路的兴趣探索和兴趣保量一起,形成用户兴趣挖掘的闭环。

05、未来展望
未来在去中心化问题上仍然存在许多工作可以开展,主要分为以下几个方面:
生成式推荐:相较于传统的判别式推荐,生成式推荐具有更强的多样性和泛化能力,目前生成式召回和排序的工作我们已在探索中,并取得了阶段性的结果。
交互式搜索:基于大模型技术,以多轮对话的方式更全面细致地捕捉用户意图和挖掘用户兴趣,返回令用户有惊喜感的内容。
多模态画像:将用户的个人信息和历史行为输入预训练的多模态大模型得到用户画像,通过 token 化技术提取图片中的笔记画像,将用户画像和笔记画像作为推荐各模块模型的输入。
多模态联合训练:传统多模态推荐通常采取预训练+finetune 两阶段的做法,可尝试直接做 end2end 的多模态和行为联合训练,这也是个值得探索的方向。
全域信号联合建模:通过搜广推全域预训练大模型或全域图模型,打通全域信号,捕捉用户在整个 app 上的行动轨迹,更全面地挖掘和学习用户全域兴趣。
编辑:于腾凯
校对:林本耀
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 8874
8874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









