







来源:DrugAI
本文约3500字,建议阅读7分钟
本文为大家介绍的是来自Hoifung Poon团队的一篇论文。今天为大家介绍的是来自Hoifung Poon团队的一篇论文。数字病理学面临着独特的计算挑战,因为标准的千兆像素载玻片可能包含数万个图像切片。现有模型通常会对每张载玻片的部分图像切片进行子采样,因此错过了重要的切片级上下文信息。作者在此介绍Prov-GigaPath,一个在13亿个256×256病理图像切片上预训练的全载玻片病理基础模型。其中,这些切片来自Providence,它是包含28个癌症中心的大型美国健康网络中的171,189张完整载玻片。这些切片来源于超过30,000名患者,涵盖了31种主要组织类型。为了预训练Prov-GigaPath,作者提出了GigaPath,这是一种用于预训练千兆像素病理载玻片的新型视觉Transformer架构。为了使GigaPath能够处理包含数万个图像切片的切片级学习,GigaPath采用了最新开发的LongNet方法。为了评估Prov-GigaPath,作者构建了一个数字病理学基准,使用了Providence和TCGA的数据,它包含9个癌症亚型任务和17个病理任务。通过大规模预训练和超大上下文建模,Prov-GigaPath在26个任务中的25个任务上达到了最先进的性能,并且在18个任务上显著优于次优方法。作者通过整合病理报告进一步展示了Prov-GigaPath在病理学视觉-语言预训练中的潜力。在总结中,Prov-GigaPath是一个开放权重的基础模型,在各种数字病理学任务上达到了最先进的性能,展示了真实世界数据和全片建模的重要性。

计算病理学有潜力通过支持多种临床应用来改变癌症诊断,包括癌症分型、癌症分期、诊断预测和预后预测。尽管现有的计算方法表现令人鼓舞,但这些方法通常是为特定应用开发的,需要大量的标注数据进行监督学习。数据标注既昂贵又耗时,已经成为计算病理学的重要瓶颈。最近,自监督学习在利用未标记数据预训练基础模型方面显示了有前途的结果,可以大大减少对任务特定标注的需求。由于其强大的泛化能力,基础模型已经在标注数据稀缺但未标记数据丰富的生物医学领域得到开发,这种情况恰好描述了计算病理学。
病理学基础模型在现实世界临床应用中的发展和使用面临三大挑战。首先,公开可用的病理数据相对稀缺且质量不一,限制了在这些数据上预训练的基础模型的性能。例如,现有的病理基础模型主要在来自癌症基因组图谱(TCGA)的全片图像(WSI)上进行预训练,这是一个专家策划的数据集,包括约30,000张载玻片和2.08亿个图像切片。尽管这些数据资源非常宝贵,但TCGA数据可能不足以充分应对临床实践中现实世界数字病理学的挑战,如异质性和噪声伪影,导致使用基于TCGA的预测模型和生物标志物在分布外样本上表现显著下降。其次,设计一个能够有效捕捉单个切片中的局部模式和整个载玻片的全局模式的模型架构仍然具有挑战性。现有模型通常将每个图像切片视为独立样本,并将图片级建模形式化为多实例学习,因此限制了它们对千兆像素全载玻片中复杂全局模式的建模能力。一个显著的例外是分层图像金字塔转换器(HIPT),它探索了切片上的分层自注意力。第三,在极少数情况下,在大规模现实世界患者数据上进行预训练,所得的基础模型通常对公众不可访问,从而限制了其在临床研究和应用中的更广泛适用性。
Prov-GigaPath概述
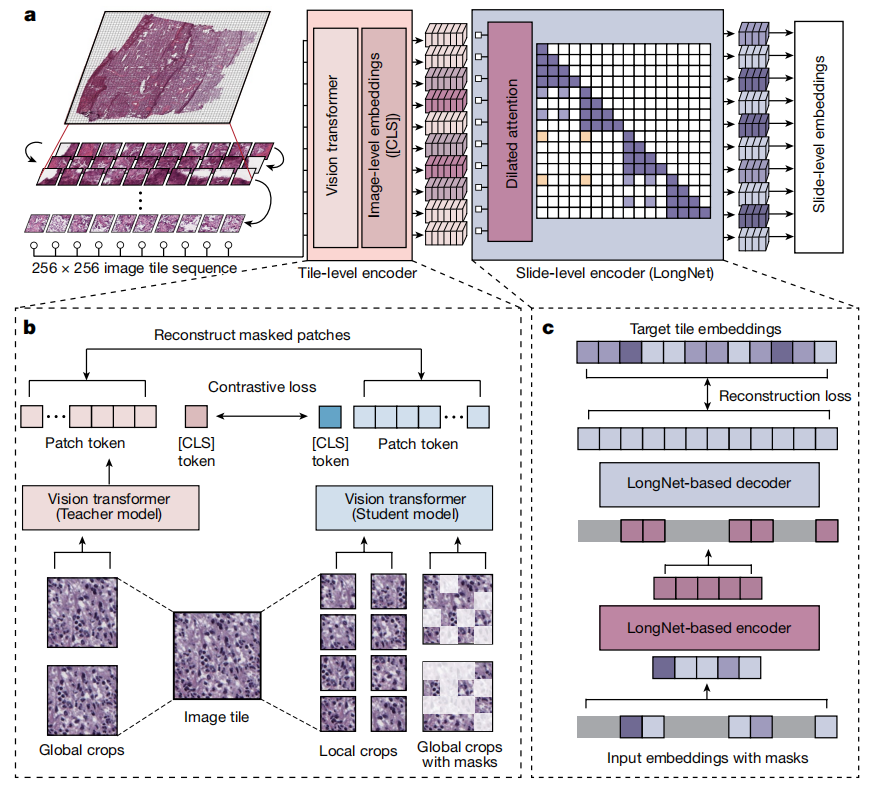
图1:Prov-GigaPath框架图
Prov-GigaPath以病理载玻片中的图像切片作为输入,并输出可用于多种临床应用的载玻片级嵌入(图1a)。Prov-GigaPath在千兆像素病理载玻片的长上下文建模方面表现出色,通过提取不同的局部病理结构并整合整个载玻片的全局特征。
Prov-GigaPath由一个捕捉局部特征的切片编码器和一个捕捉全局特征的载玻片编码器组成。切片编码器将所有切片单独投影到紧凑的嵌入空间中。然后,载玻片编码器输入切片嵌入序列,使用Transformer生成考虑整个序列的上下文化嵌入。切片编码器使用DINOv2(最先进的图像自监督学习框架)进行预训练。载玻片编码器结合了掩码自动编码器预训练和作者最近开发的超长序列建模方法LongNet。在下游任务中,载玻片编码器的输出使用简单的softmax注意力层进行聚合。
Prov-GigaPath是一种用于高分辨率成像数据的通用预训练方法,可能扩展到其他生物医学问题,包括大规模二维和三维图像及视频的分析。作者在Prov-Path的大型多样化的真实世界数据上预训练了Prov-GigaPath。对于给定的下游任务,预训练的Prov-GigaPath使用任务特定的训练数据进行微调,这是基础模型使用的标准方式。然后可以在给定任务的测试数据上评估所得的任务特定模型。与先前的最先进公共病理基础模型相比,Prov-GigaPath在17个病理学任务和9个分型任务上取得了显著改进。预训练数据集Prov-Path由171,189张H&E染色和免疫组化病理载玻片中的1,384,860,229个256×256图像切片组成,这些载玻片来自于超过30,000名患者的31种主要组织类型的活检和切除样本。
Prov-GigaPath改进了突变预测
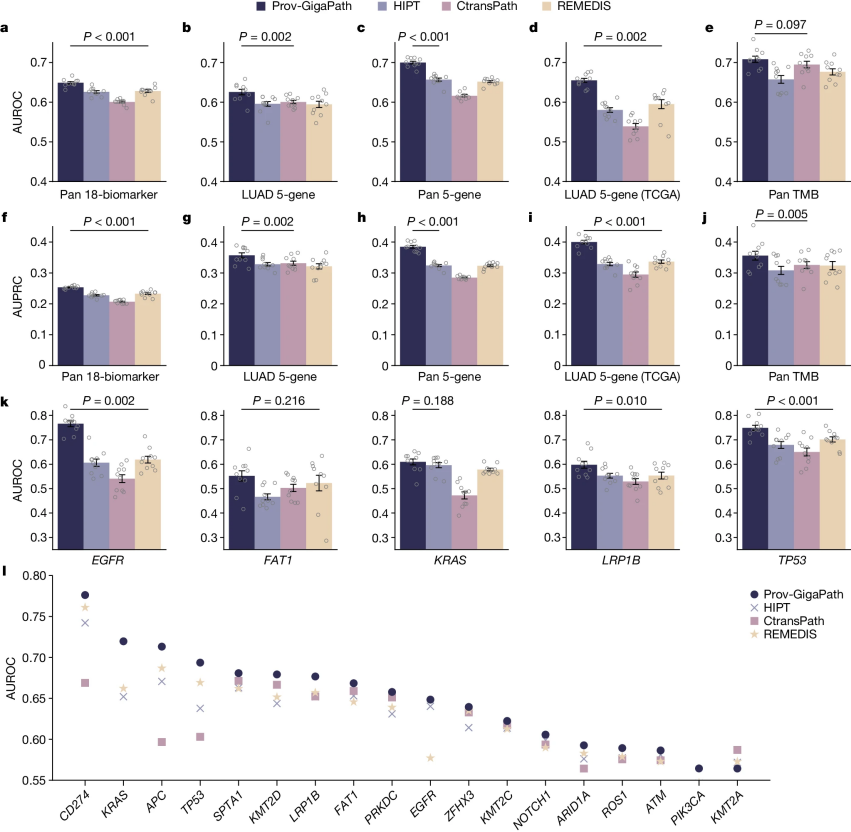
图2:基因突变预测
各种功能改变的体细胞基因突变是癌症进展和发展的基础,因此在癌症诊断和预后中具有重要作用。尽管测序成本已大幅下降,但全球范围内在肿瘤测序的可及性方面仍存在关键的医疗差距。因此,从病理图像中预测肿瘤突变可能有助于治疗选择并增加个性化医学的应用。作者将Prov-GigaPath与竞争方法在五基因突变预测基准上进行了比较(图2),将此任务形式化为图像分类任务。
首先,作者检查了全癌症背景下最常见的18个生物标志物的预测(图2a, f, l)。与最佳竞争方法相比,Prov-GigaPath在这18个生物标志物上的宏观受试者工作特征曲线下面积(AUROC)提高了3.3%,宏观精确度-召回曲线下面积(AUPRC)提高了8.9%。鉴于特定肿瘤突变与总体肿瘤组成和形态之间的已知关联,作者将此改进归因于LongNet在有效捕捉全局图像模式方面的能力。
接下来,作者关注肺腺癌(LUAD),这是图像基突变预测中研究最广泛的癌症类型之一(图2b, g)。作者重点研究了文献中与LUAD诊断和治疗密切相关的五个基因(EGFR、FAT1、KRAS、TP53和LRP1B)。Prov-GigaPath通过实现0.626的平均宏观AUROC,超过了所有竞争方法,表现最佳(P值<0.01)。在全癌症分析中,Prov-GigaPath在这五个基因上的表现也优于最佳竞争方法,宏观AUROC提高了6.5%,AUPRC提高了18.7%(图2c, h)。
作者还在TCGA数据上进行了各方法的正面对比,以检查Prov-GigaPath的泛化能力。作者再次使用LUAD特定的五基因突变预测作为关键评估任务(图2d, i)。作者观察到Prov-GigaPath相对于竞争方法的类似优势。最后,作者检查了整体肿瘤突变负担(TMB)的预测,这是一种在实体瘤中与免疫治疗特别相关的预测生物标志物。Prov-GigaPath取得了最佳表现,平均AUROC为0.708,显著优于次优的方法(图2e, j)。
Prov-GigaPath改进了癌症分型
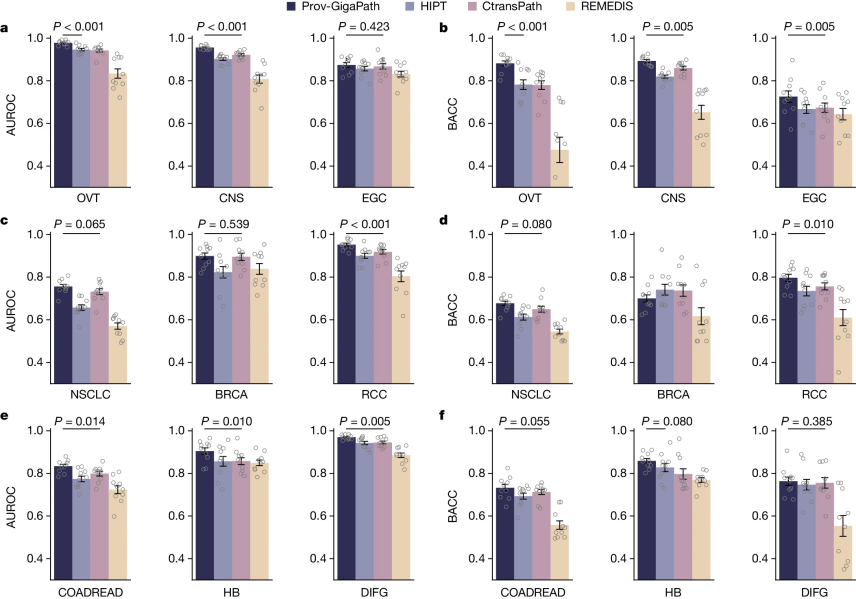
图3:癌症分型的比较
鉴于病理图像在确定肿瘤亚型中的整体实用性,作者接下来检查了Prov-GigaPath是否能准确预测图像中的癌症亚型,在Prov-Path中的九种主要癌症类型的分型上评估了该方法(图3)。Prov-GigaPath在所有九种癌症类型中都优于所有竞争方法,并在六种癌症类型中相比于次优方法取得了显著改进,这表明作者的切片编码器和载玻片编码器协同工作,有效提取了区分细微病理模式的有意义特征。HIPT和Prov-GigaPath之间的一个关键区别在于图像切片嵌入的聚合层。Prov-GigaPath相比于HIPT的显著改进展示了使用LongNet进行全片图像切片高效聚合的潜力。
载玻片级视觉-语言对齐
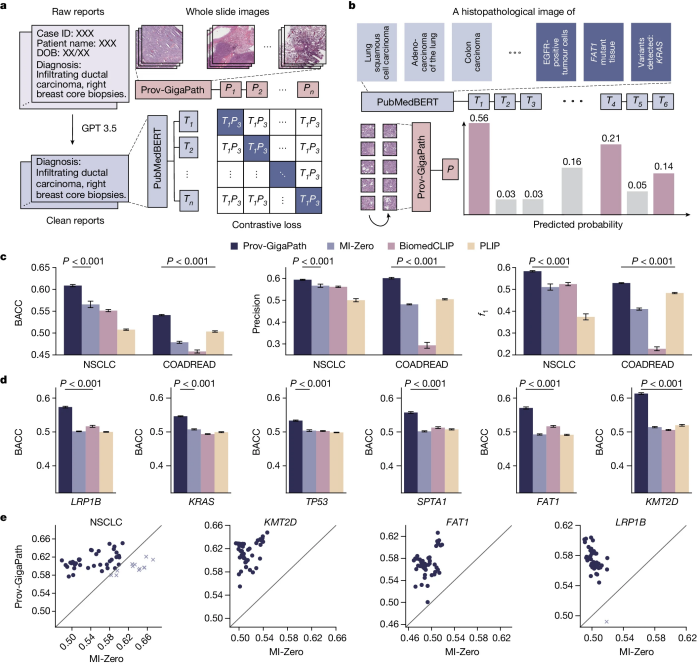
图4:视觉-语言对齐比较
Prov-GigaPath在病理图像上的出色表现进一步激励作者探索Prov-GigaPath在多模态视觉-语言处理中的应用。之前关于病理学视觉-语言建模的研究倾向于关注病理图像和文本的切片级对齐,因为它们的研究受限于图像-文本载玻片对的来源。相比之下,作者通过利用每张载玻片的相关报告,研究了病理图像和文本的载玻片级对齐(图4a)。这种自然存在的载玻片-文本对可能揭示更丰富的载玻片级信息,但由于缺乏单个图像切片和文本片段之间的精细对齐信息,建模难度相当大。作者在Prov-GigaPath的持续预训练中使用标准的跨模态对比损失,将其作为视觉编码器,并将最先进的生物医学语言模型PubMedBERT作为文本编码器(图4b)。
作者在NSCLC和COADREAD的零样本癌症分型中评估了所得的Prov-GigaPath,使用了与最先进的病理学视觉-语言模型MI-Zero相同的设置。在零样本设置中,不提供任何目标癌症亚型的训练图像。载玻片和相应的癌症亚型数据来自Prov-Path。与三种最先进的病理学视觉-语言模型相比,Prov-GigaPath在这两种癌症类型的所有三项指标上都取得了最佳的零样本分类结果(图4c, e),这表明LongNet启用的载玻片级对齐确实具有优势。Prov-GigaPath在NSCLC上的改进大于在COADREAD上的改进,这可以归因于Prov-Path中肺组织的更广泛存在。Prov-GigaPath以相当大的优势优于PLIP,这可能反映了现实世界临床数据相对于Twitter数据的优越性。
接下来,作者在相同的零样本设置中,使用视觉-语言预训练的Prov-GigaPath,检查了基因突变预测的可能性(图4d, e)。作者采用了用于癌症分型的提示,通过将癌症类型名称替换为想预测的二进制突变状态的基因名称。Prov-GigaPath在检查的所有六种突变中显著优于最先进的病理学视觉-语言模型(P值<0.001)。作者的方法在突变预测上的改进大于在癌症分型上的改进,这可能部分归因于现实世界数据中的病理报告相比Twitter数据和科学论文中的文本评论包含更丰富的突变信息。据作者所知,这是首次在病理学视觉-语言建模中评估零样本基因突变预测。Prov-GigaPath在这一新任务上的出色表现预示着其在研究罕见癌症类型和新突变方面的潜在应用前景。
讨论
作者介绍了Prov-GigaPath,一个用于广泛数字病理应用的基础模型。该模型在来自Providence健康系统的真实数据集Prov-Path上预训练,数据集规模远大于TCGA,包括171,189张病理载玻片的1,384,860,229个图像切片。作者提出了GigaPath,采用LongNet进行超大上下文建模。综合评估显示,Prov-GigaPath在多种病理任务和癌症分型任务中表现出色,具有辅助临床诊断和决策支持的潜力。未来,作者计划通过引入其他模态和特征,优化预训练过程,并探索不同放大倍率和多模态学习框架,以进一步提升模型性能。
参考资料
Xu H, Usuyama N, Bagga J, et al. A whole-slide foundation model for digital pathology from real-world data[J]. Nature, 2024: 1-8.
编辑:于腾凯
较对:林亦霖
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









