







来源:专知
本文约1000字,建议阅读5分钟在本教程中,我们全面回顾了现有的关于检索增强大型语言模型(RA-LLMs)的研究工作。
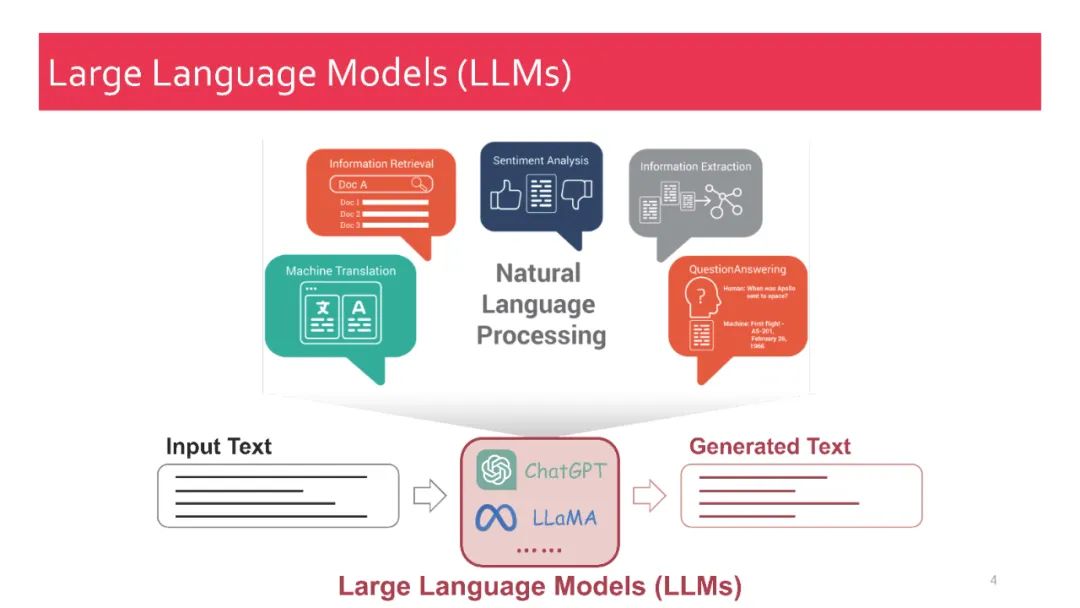
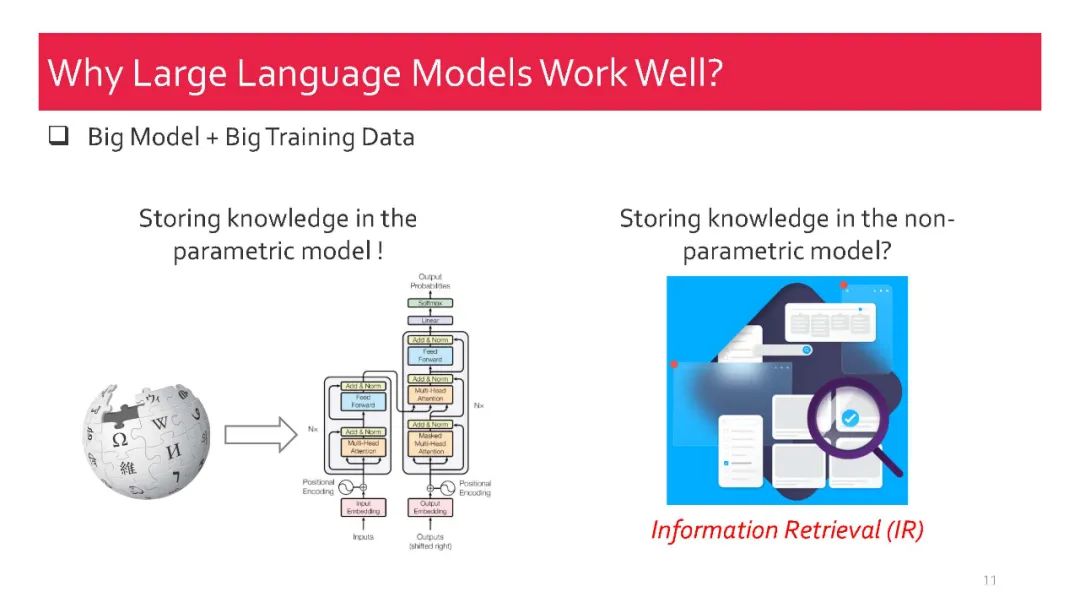
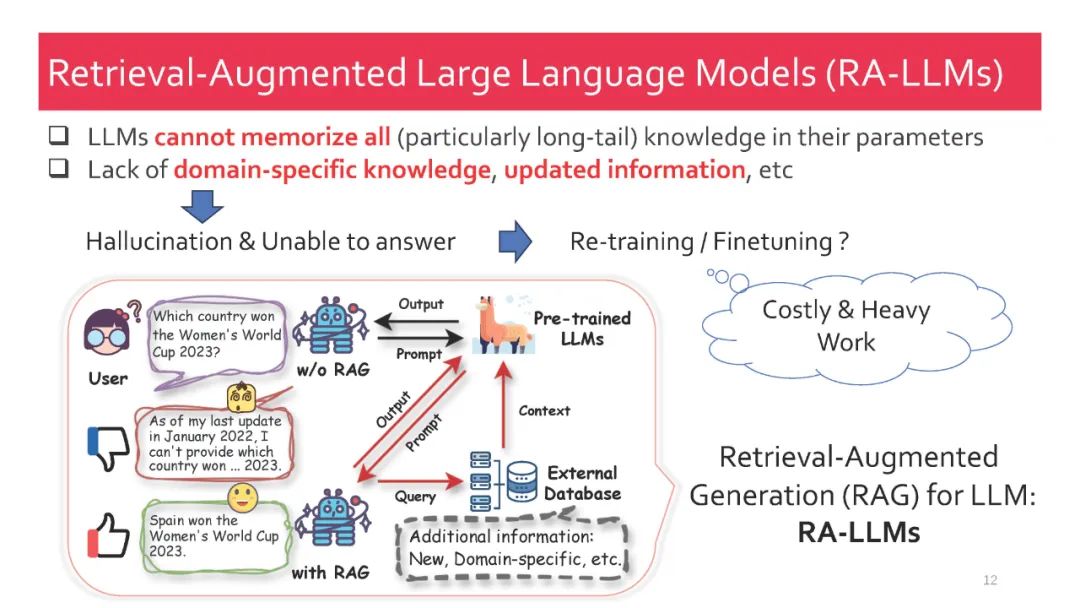
作为人工智能领域最先进的技术之一,检索增强生成(RAG) 技术能够提供可靠且最新的外部知识,为众多任务带来了巨大的便利。特别是在AI生成内容(AIGC)时代,RAG强大的检索能力可以提供额外的知识,帮助现有的生成式AI生成高质量的输出。最近,大型语言模型(LLMs)在语言理解和生成方面展现了革命性的能力,但它们仍面临固有的局限性,如幻觉和过时的内部知识。鉴于RAG在提供最新且有用的辅助信息方面的强大能力,检索增强的大型语言模型(RA-LLMs) 应运而生,利用外部的权威知识库,而不是单纯依赖模型的内部知识,从而增强LLMs的生成质量。
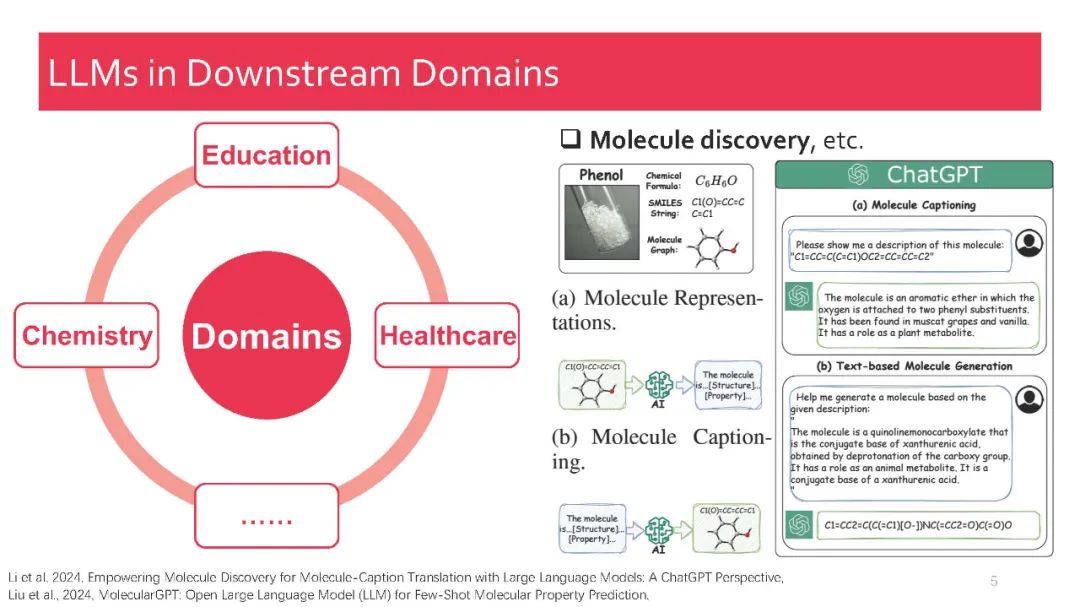
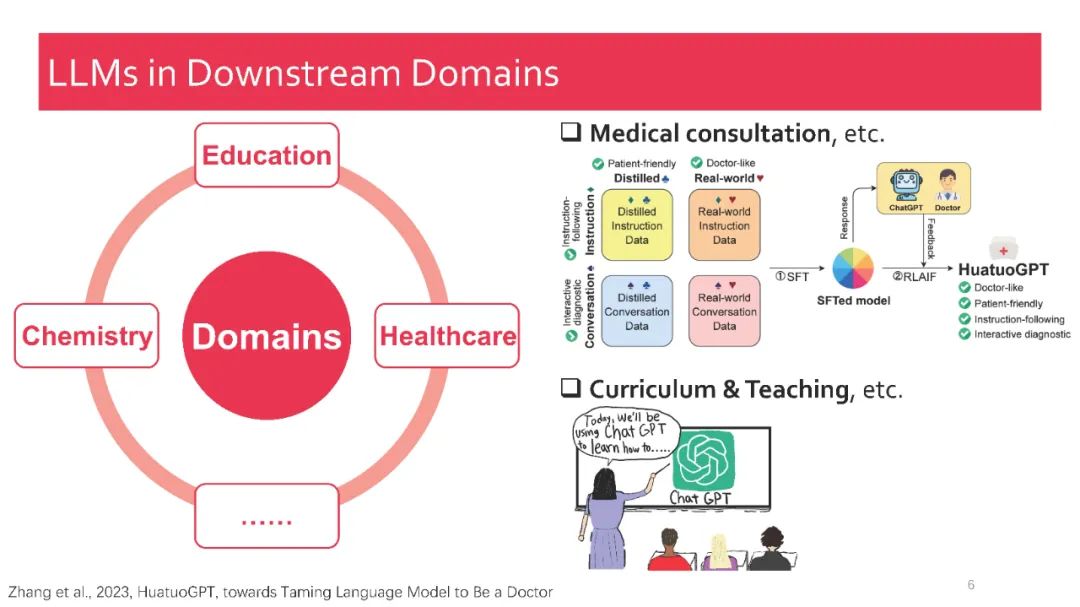
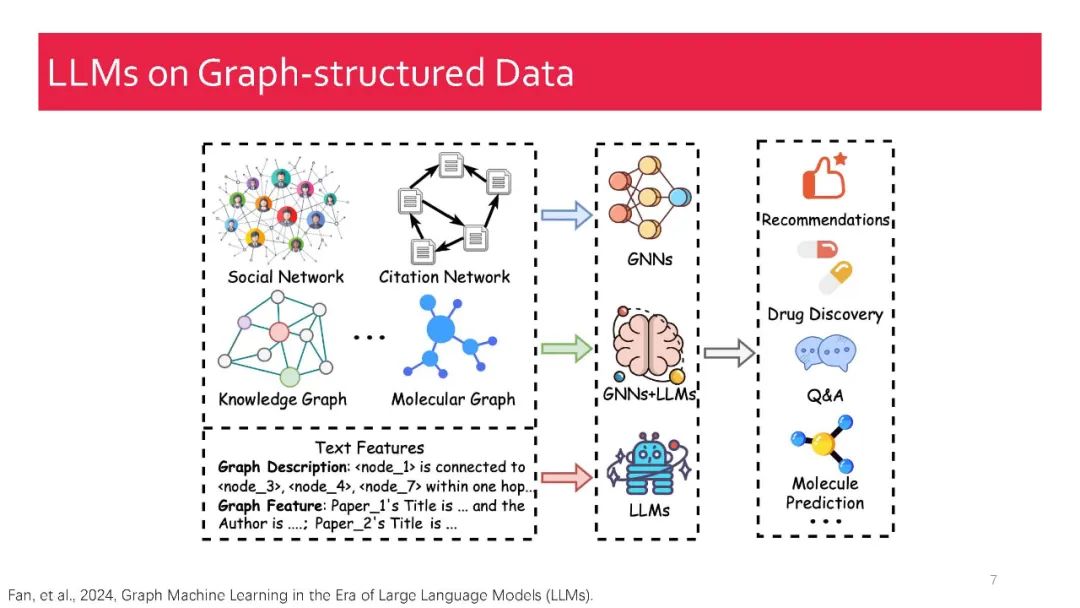
在本教程中,我们全面回顾了现有的关于检索增强大型语言模型(RA-LLMs)的研究工作,涵盖了三个主要技术视角:架构、训练策略和应用。作为基础知识,我们简要介绍了LLMs的基本原理及其最近的进展。接着,为了展示RAG对LLMs的实际意义,我们按应用领域对主流相关工作进行分类,详细说明了每个领域面临的挑战及RA-LLMs的对应能力。最后,为了提供更深刻的见解,我们讨论了当前的局限性以及未来研究的几个有前景的方向。
我们的综述论文:《RAG-Meets-LLMs: 迈向检索增强的大型语言模型》
https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/




关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









