







来源:专知
本文约1000字,建议阅读5分钟
我们提出了Vevo,一个多功能的零-shot语音模仿框架,具备可控的音色与风格。
语音模仿,尤其是针对特定的语音属性,如音色和说话风格,对于语音生成至关重要。然而,现有的方法往往过度依赖标注数据,且难以有效地解耦音色与风格,这使得在零-shot场景下实现可控生成面临挑战。为解决这些问题,我们提出了Vevo,一个多功能的零-shot语音模仿框架,具备可控的音色与风格。Vevo的工作流程分为两个核心阶段:
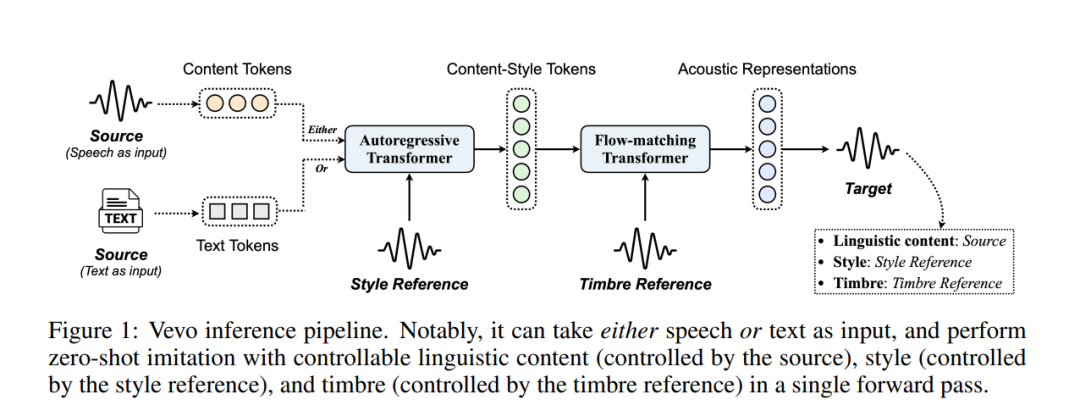
内容-风格建模:给定文本或语音的内容tokens作为输入,我们使用自回归Transformer生成内容-风格tokens,这一过程受到风格参考的提示;
声学建模:给定内容-风格tokens作为输入,我们采用流匹配Transformer生成声学表示,这一过程受到音色参考的提示。
为了获得语音的内容和内容-风格tokens,我们设计了一种完全自监督的方法,逐步解耦语音的音色、风格和语言内容。具体来说,我们采用VQ-VAE [1]作为HuBERT [2]连续隐藏特征的分词器,将VQ-VAE字典的词汇量视为信息瓶颈,并精心调整该瓶颈,以获得解耦后的语音表示。Vevo在没有针对风格特定语料库的微调下,单纯使用60K小时有声书语音数据进行自监督训练,在口音和情感转换任务中,能够与现有方法匹敌或超越。此外,Vevo在零-shot语音转换和文本到语音任务中的有效性,进一步证明了其强大的泛化能力和多功能性。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









