







来源:Deephub Imba
本文共5800字,建议阅读10+分钟本文将通过直观的解释和基础代码实现,深入剖析流匹配在图像生成中的应用,并提供一个简单的一维模型训练实例。扩散模型(Diffusion Models)和流匹配(Flow Matching)是用于生成高质量、连贯性强的高分辨率数据(如图像和机器人轨迹)的先进技术。在图像生成领域,扩散模型的代表性应用是Stable Diffusion,该技术已成功迁移至机器人学领域,形成了所谓的"扩散策略"(Diffusion Policy)。值得注意的是,扩散实际上是流匹配的特例,流匹配作为一种更具普适性的方法,已被Physical Intelligence团队应用于机器人轨迹生成,并在图像生成方面展现出同等的潜力。相较于扩散模型,流匹配通常能够以更少的训练资源更快地生成数据。本文将通过直观的解释和基础代码实现,深入剖析流匹配在图像生成中的应用,并提供一个简单的一维模型训练实例。
图像作为随机变量
流匹配和扩散方法的核心理念是将数据(如图像)视为随机变量的实现。例如,下图中的8×8像素图像中每个像素都具有(0..255)范围内的RGB值。通过向其添加服从高斯分布的随机值,我们可以将其转化为随机图像。这里,我们用函数q()表示添加噪声的过程。通过追踪中间状态的图像,我们能够学习逆函数pθ(),其中θ对应神经网络的参数。该神经网络预测需要移除的噪声量,以将噪声转换回原始图像。这基本概括了扩散方法的工作原理。
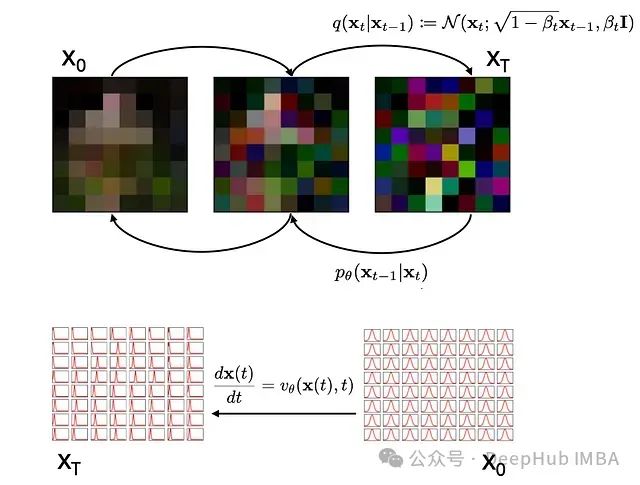
扩散方法(上)通过预测添加到原始图像x0的高斯噪声来生成图像。流匹配(下)则将每个像素明确表示为通过速度场v()变换的高斯分布。扩散训练卷积神经网络以预测需要移除的噪声,而流匹配则学习时间依赖的速度场,将正态分布转换为表征图像的分布。
但是这里还存在一种更整体的视角来审视此问题。由于每个像素本质上是遵循高斯分布的随机变量,随机图像(右上)实际上就是一个均值为128且方差相对较大的高斯分布(右下),而包含有意义内容的图像(左上)则是均值等于实际像素值且方差相对较小的高斯分布(左下)。
虽然此处展示了64个独立分布,但也可将其视为一个64维的高斯分布。我们可以构想一个速度场 vθ(),使随机粒子从x0分布移动到xT上的对应位置,而非通过添加噪声从左向右移动,并在从右向左移动时预测噪声。在整个分布范围内对随机粒子执行此操作,相当于将所有64个均值为0(方差为1)的正态分布x0转换为64个均值对应像素值的分布xT。这些概念在代码实现中将变得更加清晰。
利用速度场变换概率密度函数
让我们仅考虑图像中的单个像素,其值为2(为简化起见,我们假设分布以0为中心,而非255除以2)。我们可以从实际图像中采样1000次,获得下图所示的以x=2为中心的绿色概率密度分布。出于演示目的,我们选择了一个不太小的标准差。具有如此大方差的图像实现将类似于上述插图中的中间图像。我们还可以生成1000个像素值围绕0分布且方差为1的完全随机图像,这将产生橙色直方图。
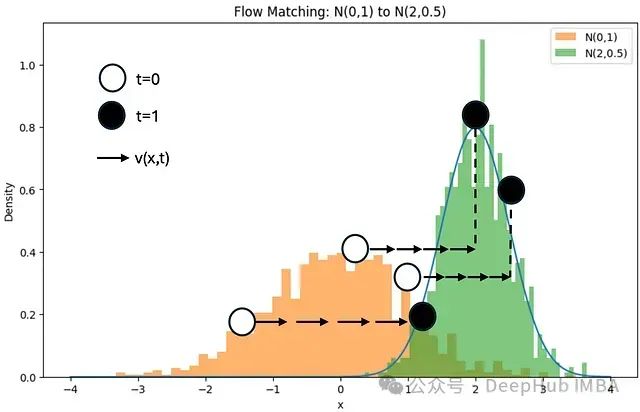
N(0,1)分布的样本及其在N(2,0.5)分布上的对应位置。速度场(箭头)将每个样本从源分布移动到目标分布上的对应位置,从而将N(0,1)转换为N(2,0.5)。
我们现在可以构想一个速度场v(x,t),该速度场将每个样本从一个分布移动到目标分布上的对应位置。这种速度依赖于x位置,在此例中表现为向右移动点。假设移动耗时为单位时间(例如一秒),速度也随时间变化。学习此速度场是流匹配的核心内容。如果对每个像素执行此操作,每个像素都有其特定的目标分布,则可以从噪声中生成图像。已知v(x,t)后,我们可以表述:
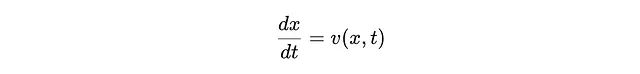
即速度场决定了分布x随时间的变化率(dx/dt)。我们可以通过对时间积分v(x,t)来计算最终分布:
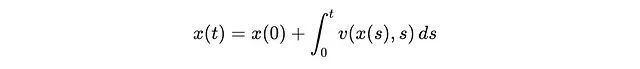
您可能会疑惑,在不了解源分布与目标分布样本间对应关系的情况下,如何学习v(x,t)。
实际上,只需从两个分布中随机选择配对样本x0 ~ p0和x1 ~ p1,并用直线连接它们即可。使用足够多的样本后,平均速度场将自然呈现。如下图所示,在时间t=0时,样本主要分布在-2和2之间,而在t=1时,样本围绕2集中,并表现出更高的密度(因为N(2,0.5)的方差小于原始方差)。
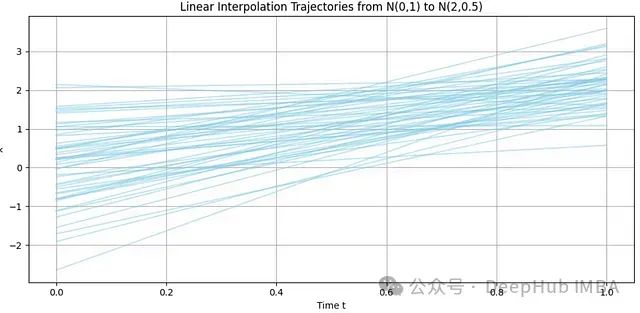
N(0,1)和N(2,0.5)的随机配对。通过足够多的样本,可以清晰地展现如何平均移动样本以将一个分布转换为另一个分布。
我们还可以观察速度场随时间的变化。下图展示了速度作为x的函数。初始阶段(t=0,亮色),左侧区域的速度较高——将样本向右移动。在流动后期(较大t值,暗色),当粒子接近目标位置时,运动减缓。同时需注意,初始阶段在x>2处的速度为负值,将那里的粒子向左移动。
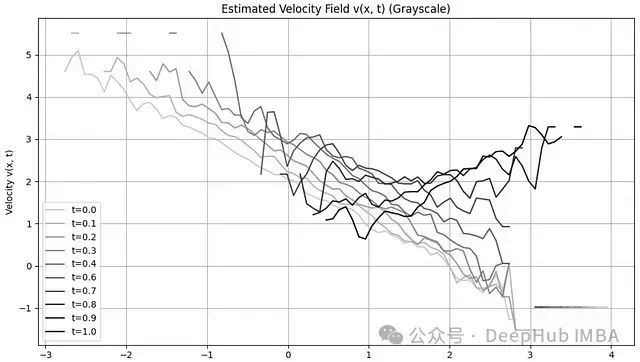
生成上述两图的代码可在文末附录中找到。
速度场的学习过程
为了学习速度场,我们需要两组粒子样本:一组从源分布采样,另一组从目标分布采样:
import torch import matplotlib.pyplot as plt import numpy as np # 目标分布:N(2, 0.5) # 源分布:标准正态分布 N(0,1) def source_distribution(n_samples): return torch.randn(n_samples, 1) plt.figure(figsize=(10, 6)) #plt.plot(x_range.numpy(), target_pdf.numpy(), '-') plt.hist(source_distribution(1000).numpy(), bins=50, density=True, alpha=0.6, label='N(0,1)') plt.hist(torch.normal(2.0, 0.5, (1000, 1)).numpy(),bins=50, density=True, alpha=0.6, label='N(2,0.5)') plt.legend() plt.title('Source N(0,1) and target distribution N(2,0.5)') plt.xlabel('x') plt.ylabel('Density') plt.show()
这将生成前文展示的直方图。那么速度场应该具有怎样的形式呢?让我们看看上述积分在Python中的实现方式:
# 前向模拟 for t in time_steps[:-1]: t_tensor = t * torch.ones(n_samples, 1) v = model(x, t_tensor.to(device)) x = x + v * dt
这里,time_steps是一个从0到1以dt为增量的数组。例如,当dt=1ms时,我们将计算1000步。向量x包含从源分布(在我们的例子中为N(0,1))中抽取的n_samples个随机值。在每个时间步,我们将速度场v添加到x,目标是使生成的x分布近似于从目标分布N(2,0.5)中抽样得到的分布。速度场由一个神经网络模型表示,该模型以当前分布和时间步为输入。需要注意的是,这实际上是求解常微分方程(ODE),上述实现是其中最简单的方法之一,即欧拉方法。在此提及这一点是因为还存在许多更高效的求解方法。
针对该问题的模型可以设计如下:
import torch import torch.nn as nn import numpy as np # 设置随机种子以确保结果可复现 torch.manual_seed(42) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 为速度场定义一个简单的神经网络 class VelocityField(nn.Module): def __init__(self, input_dim=1, hidden_dim=128): super(VelocityField, self).__init__() self.input_layer = nn.Linear(input_dim + 1, hidden_dim) self.norm1 = nn.LayerNorm(hidden_dim) self.hidden1 = nn.Linear(hidden_dim, hidden_dim) self.norm2 = nn.LayerNorm(hidden_dim) self.hidden2 = nn.Linear(hidden_dim, hidden_dim) self.norm3 = nn.LayerNorm(hidden_dim) self.output_layer = nn.Linear(hidden_dim, input_dim) self.relu = nn.ReLU() def forward(self, t, x): t_tensor = t * torch.ones(x.shape[0], 1, device=x.device) xt = torch.cat([x, t_tensor], dim=-1) h = self.relu(self.norm1(self.input_layer(xt))) h = h + self.relu(self.norm2(self.hidden1(h))) h = h + self.relu(self.norm3(self.hidden2(h))) return self.output_layer(h) model = VelocityField(hidden_dim=128) model.to(device)
该模型由输入层(接收(x,t)对并投影到hidden_dim=128维潜在空间)、两个隐藏层以及输出x的输出层组成。我们添加了层归一化和ReLU(修正线性单元)激活函数。注意,输出层后没有ReLU激活,因为x值可以为负。网络还包含残差连接,这有助于梯度更有效地传播,并提高训练稳定性。
现在我们可以使用源分布和目标分布之间的均方误差来训练该模型:
n_steps = 100 n_samples = 1000 epochs = 30 optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) time_steps = torch.linspace(0, 1, n_steps) dt = time_steps[1] - time_steps[0] for epoch in range(epochs+1): # 从源分布采样 x0 = source_distribution(n_samples).to(device) x = x0.clone().to(device) # 前向模拟 for t in time_steps[:-1]: t_tensor = t * torch.ones(n_samples, 1) v = model(x, t_tensor.to(device)) x = x + v * dt target_samples = torch.normal(2.0, 0.5, (n_samples, 1)).to(device) loss = torch.mean((x - target_samples)**2) # 优化 optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 10 == 0: print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
训练结果如下:
Epoch 0, Loss: 4.4413 Epoch 10, Loss: 2.0921 Epoch 20, Loss: 0.8110 Epoch 30, Loss: 0.6001
现在我们可以利用训练好的模型将标准正态分布N(0,1)的任意样本转换为目标分布:
def generate_samples(model, n_samples=1000, n_steps=50): x = source_distribution(n_samples).to(device) time_steps = torch.linspace(0, 1, n_steps).to(device) dt = time_steps[1] - time_steps[0] with torch.no_grad(): for t in time_steps[:-1]: t_tensor = t * torch.ones(n_samples, 1).to(device) v = model(x, t_tensor) x = x + v * dt return x
还可以可视化源分布和目标分布:
import matplotlib.pyplot as plt # 生成样本 generated_samples = generate_samples(model).to('cpu') # 绘制结果 # 计算理论目标分布PDF用于参考 x_range = torch.linspace(-4, 4, 1000).unsqueeze(1) mean, std = 2, 0.5 target_pdf = torch.exp(-((x_range - mean)**2) / (2 * std**2)) / (std * np.sqrt(2 * np.pi)) plt.figure(figsize=(10, 6)) plt.hist(generated_samples.numpy(), bins=50, density=True, alpha=0.6, label='Generated') plt.plot(x_range.numpy(), target_pdf.numpy(), 'r-', label='Target') plt.hist(source_distribution(1000).numpy(), bins=50, density=True, alpha=0.6, label='Source N(0,1)') plt.legend() plt.title('Flow Matching: N(0,1) to N(2,0.5)') plt.xlabel('x') plt.ylabel('Density') plt.show()
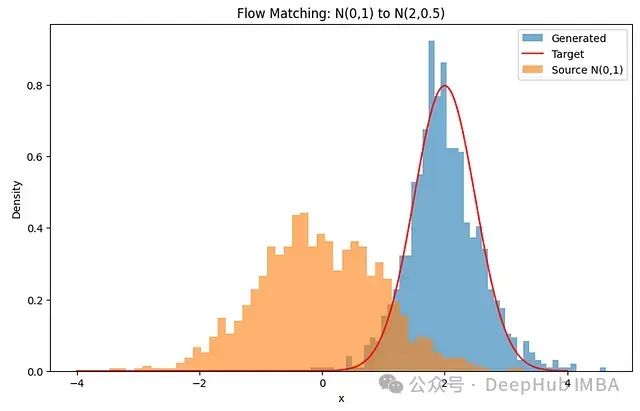
通过速度场变换源分布后生成的分布。
这个案例比较简单,并且我们略施技巧,恰好在适当时机停止训练。如果继续训练,损失值会降至0.25并停滞不前。此时生成的分布会越来越窄,最终在x=2处形成单一峰值。这是由于我们简化的损失函数(计算随机配对间的均方误差)导致的。虽然当目标方差较低时(例如生成真实图像或轨迹时)这种方法有效,但我们可以通过更直接地比较两个分布来改进模型。
最大均值差异(MMD)的计算
使用Kullback-Leibler散度轻松比较参数化分布,但在这里我们面临的挑战是仅基于样本比较两个分布。给定两个概率分布P和Q,MMD定义为:
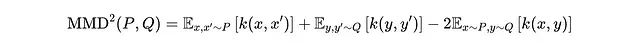
其中x和x'是来自分布P的样本,y和y'是来自分布Q的样本,k(x,y)是核函数,例如高斯核,用于测量x和y之间的相似度:
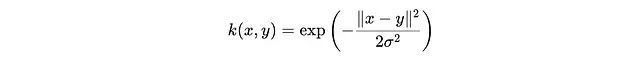
我们可以通过计算样本平均值重写期望值:
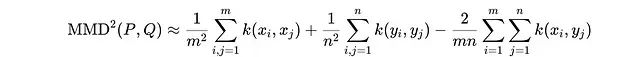
其中分布P包含m个样本,分布Q包含n个样本。当两个分布相同时,第三项抵消前两项,MMD值为0。
def compute_mmd(x, y, sigma=1.0): """ 使用高斯核计算两组样本间的最大均值差异(MMD)。 x: 生成样本 (n_samples, dim) y: 目标样本 (n_samples, dim) sigma: 核带宽参数 """ n = x.shape[0] m = y.shape[0] # 计算成对平方距离 xx = torch.sum(x**2, dim=1, keepdim=True) - 2 * torch.mm(x, x.t()) + torch.sum(x**2, dim=1, keepdim=True).t() yy = torch.sum(y**2, dim=1, keepdim=True) - 2 * torch.mm(y, y.t()) + torch.sum(y**2, dim=1, keepdim=True).t() xy = torch.sum(x**2, dim=1, keepdim=True) - 2 * torch.mm(x, y.t()) + torch.sum(y**2, dim=1, keepdim=True).t() # 高斯核:k(x,y) = exp(-||x-y||^2 / (2 * sigma^2)) kernel_xx = torch.exp(-xx / (2 * sigma**2)) kernel_yy = torch.exp(-yy / (2 * sigma**2)) kernel_xy = torch.exp(-xy / (2 * sigma**2)) # MMD^2 = E[k(x,x')] + E[k(y,y')] - 2 E[k(x,y)] mmd = (kernel_xx.sum() / (n * n)) + (kernel_yy.sum() / (m * m)) - (2 * kernel_xy.sum() / (n * m)) return mmd
我们现在可以将损失计算替换为:
loss = compute_mmd(x,target_samples)这种训练方式效果显著:
Epoch 0, Loss: 1.1316 Epoch 10, Loss: 0.5481 Epoch 20, Loss: 0.0634 Epoch 30, Loss: 0.0372 Epoch 40, Loss: 0.0193 Epoch 50, Loss: 0.0014 Epoch 60, Loss: 0.0022 Epoch 70, Loss: 0.0004 Epoch 80, Loss: 0.0003 Epoch 90, Loss: 0.0004 Epoch 100, Loss: 0.0024
该方法实际上适用于任意概率分布,例如高斯混合模型。只需将target_samples替换为其他分布类型:
target_samples = torch.cat([ torch.normal(2.0, 0.5, (n_samples//2, 1)), torch.normal(-3.0, 0.5, (n_samples//2, 1)) ]).to(device)
这样会在x=-3和x=2处产生两个峰值,相同的训练循环将得到以下结果:
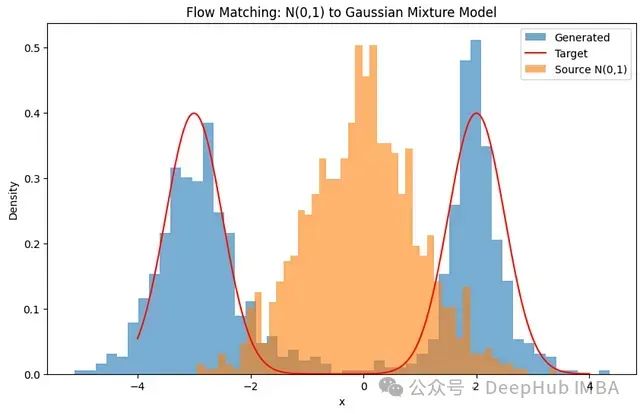
流匹配学习将正态分布转换为高斯混合模型的速度场。
总结
流匹配不需要像扩散方法中常用的复杂神经网络结构(如U-Net)就能从噪声中生成多模态/多维概率分布。与扩散类似,流匹配可以基于文本或图像嵌入进行条件约束,以生成特定类型的分布,且通常需要更少的数据和训练资源。
附录:速度场的可视化
展示两个概率分布的随机配对及估计速度场的图表是通过以下代码生成的:
import numpy as np import matplotlib.pyplot as plt # 设置随机种子以确保结果可复现 np.random.seed(42) # 从源分布和目标分布中采样1000个点 n_samples = 1000 x0_samples = np.random.normal(loc=0.0, scale=1.0, size=n_samples) # 源:N(0,1) x1_samples = np.random.normal(loc=2.0, scale=0.5, size=n_samples) # 目标:N(2, 0.5) # 为每对样本采样 t ~ Uniform(0,1) t_samples = np.random.uniform(low=0.0, high=1.0, size=n_samples) # 计算插值 x_t 和真实速度 v* x_t = (1 - t_samples) * x0_samples + t_samples * x1_samples v_star = x1_samples - x0_samples # 绘制一部分轨迹(50个) idx = np.random.choice(n_samples, size=50, replace=False) x0_vis = x0_samples[idx] x1_vis = x1_samples[idx] # 绘图 plt.figure(figsize=(10, 5)) for i in range(len(idx)): plt.plot([0, 1], [x0_vis[i], x1_vis[i]], color='skyblue', alpha=0.5) plt.title("Linear Interpolation Trajectories from N(0,1) to N(2,0.5)") plt.xlabel("Time t") plt.ylabel("x") plt.grid(True) plt.tight_layout() plt.show()
第二张图:
from scipy.stats import norm # 创建 x 和 t 的网格以评估速度场 x_grid = np.linspace(-3, 5, 100) t_grid = np.linspace(0, 1, 10) X, T = np.meshgrid(x_grid, t_grid) # 对于每个 (x, t),通过平均多对样本的 v* 来计算期望速度 # 我们将通过对 x_t 接近 (x,t) 的采样对进行平均来经验性地估计这一点 # 使用所有样本计算 x_t 和 v* x_t_all = (1 - t_samples[:, None]) * x0_samples[:, None] + t_samples[:, None] * x1_samples[:, None] v_star_all = (x1_samples - x0_samples)[:, None] # 在网格上估计速度场 V = np.zeros_like(X) for i in range(len(t_grid)): for j in range(len(x_grid)): t_val = t_grid[i] x_val = x_grid[j] # 计算此 t 的插值点 x_interp = (1 - t_val) * x0_samples + t_val * x1_samples v_interp = x1_samples - x0_samples # 找到 x_interp 接近当前 x_val 的样本 mask = np.abs(x_interp - x_val) < 0.1 if np.sum(mask) > 0: V[i, j] = np.mean(v_interp[mask]) else: V[i, j] = np.nan # 附近没有数据 grayscale_colors = [(i, i, i) for i in np.linspace(0.8, 0.0, len(t_grid))] plt.figure(figsize=(10, 6)) plt.clf() for i in range(len(t_grid)): plt.plot(x_grid, V[i], color=grayscale_colors[i], label=f't={t_grid[i]:.1f}') plt.title("Estimated Velocity Field v(x, t) (Grayscale)") plt.xlabel("x") plt.ylabel("Velocity v(x, t)") plt.grid(True) plt.legend() # 确保图例显示 plt.tight_layout() plt.show()
作者:Nikolaus Correll
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 2660
2660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









