







来源:专知
本文约1000字,建议阅读5分钟
HgVT在图像分类与检索任务中均表现出色,展示了其作为高效语义视觉任务框架的潜力。
近年来,计算机视觉领域的发展凸显了视觉Transformer(ViT)在多种任务中的可扩展性,然而在适应性、计算效率以及建模高阶关系的能力之间,仍存在权衡挑战。视觉图神经网络(ViG)作为一种替代方案,通过图结构方法进行建模,但其在边生成过程中依赖的聚类算法带来了计算瓶颈。
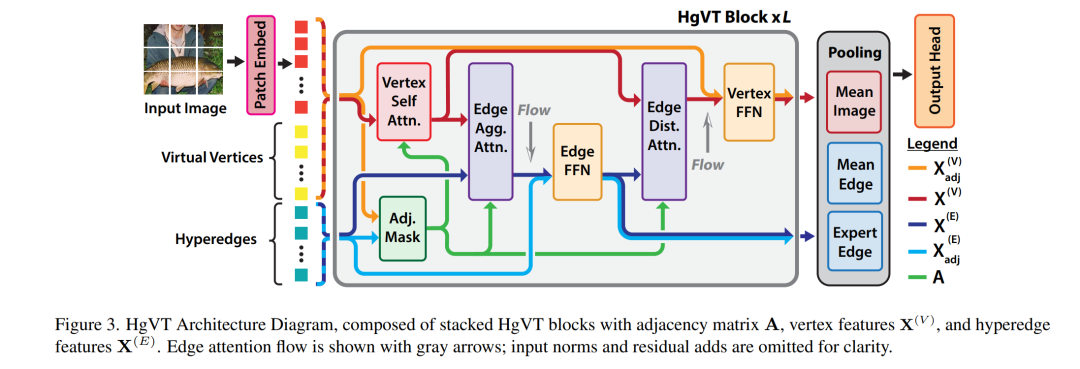
为了解决上述问题,我们提出了一种超图视觉Transformer(Hypergraph Vision Transformer, HgVT),该方法将层次化的二分超图结构引入视觉Transformer框架中,从而在保持计算效率的同时捕捉高阶语义关系。HgVT利用种群与多样性正则化动态构建超图,无需依赖聚类操作,并引入专家边池化机制以增强语义信息提取能力,并促进基于图的图像检索。
实验结果表明,HgVT在图像分类与检索任务中均表现出色,展示了其作为高效语义视觉任务框架的潜力。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









