







来源:Deephub Imba
本文共17000字,建议阅读20分钟本文系统讲解从基本强化学习方法到高级技术(如PPO、A3C、PlaNet等)的实现原理与编码过程,旨在通过理论结合代码的方式,构建对强化学习算法的全面理解。为确保内容易于理解和实践,全部代码均在Jupyter Notebook环境中实现,仅依赖基础库进行算法构建。
代码库组织结构如下:
├── 1_simple_rl.ipynb ├── 2_q_learning.ipynb ├── 3_sarsa.ipynb ... ├── 9_a3c.ipynb ├── 10_ddpg.ipynb ├── 11_sac.ipynb ├── 12_trpo.ipynb ... ├── 17_mcts.ipynb └── 18_planet.ipynb
说明:github地址见文章最后,文章很长所以可以根据需求查看感兴趣的强化学习方法介绍和对应notebook。
搭建环境
首先,需要克隆仓库并安装相关依赖项:
# 克隆并导航到目录
git clone https://github.com/fareedkhan-dev/all-rl-algorithms.git
cd all-rl-algorithms
# 安装所需的依赖项
pip install -r requirements.txt
接下来,导入核心库:
# --- 核心Python库 ---
import random
import math
from collections import defaultdict, deque, namedtuple
from typing import List, Tuple, Dict, Optional, Any, DefaultDict # 用于代码中的类型提示
# --- 数值计算 ---
import numpy as np
# --- 机器学习框架(PyTorch - 从REINFORCE开始广泛使用) ---
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical, Normal # 用于策略梯度、SAC、PlaNet等
# --- 环境 ---
# 用于加载标准环境,如Pendulum
import gymnasium as gym
# 注意:SimpleGridWorld类定义需要直接包含在代码中
# 因为它是博客文章中定义的自定义环境。
# --- 可视化(由博客中显示的图表暗示) ---
import matplotlib.pyplot as plt
import seaborn as sns # 经常用于热力图
# --- 可能用于异步方法(A3C) ---
# 尽管在代码片段中没有明确展示,但A3C实现通常使用这些
# import torch.multiprocessing as mp # 或标准的'multiprocessing'/'threading'
# --- PyTorch设置(可选但是好习惯) ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# --- 禁用警告(可选) ---
import warnings
warnings.filterwarnings('ignore') # 抑制潜在的废弃警告等强化学习环境设置
虽然OpenAI Gym库提供了常见的强化学习环境,但为了深入理解算法核心原理,我们将自行实现大部分环境。仅在少数需要特殊环境配置的算法中,才会使用Gym模块。
本文主要关注两个环境:
自定义网格世界(从头实现)
钟摆问题(使用OpenAI Gymnasium)
# -------------------------------------
# 1. 简单自定义网格世界
# -------------------------------------
class SimpleGridWorld:
""" 一个基本的网格世界环境。 """
def __init__(self, size=5):
self.size = size
self.start_state = (0, 0)
self.goal_state = (size - 1, size - 1)
self.state = self.start_state
# 动作: 0:上, 1:下, 2:左, 3:右
self.action_map = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
self.action_space_size = 4
def reset(self) -> Tuple[int, int]:
""" 重置到初始状态。 """
self.state = self.start_state
return self.state
def step(self, action: int) -> Tuple[Tuple[int, int], float, bool]:
""" 执行一个动作,返回next_state, reward, done。 """
if self.state == self.goal_state:
return self.state, 0.0, True # 在目标处停留
# 计算潜在的下一个状态
dr, dc = self.action_map[action]
r, c = self.state
next_r, next_c = r + dr, c + dc
# 应用边界(如果碰到墙壁则原地不动)
if not (0 <= next_r < self.size and 0 <= next_c < self.size):
next_r, next_c = r, c # 保持在当前状态
reward = -1.0 # 墙壁惩罚
else:
reward = -0.1 # 步骤成本
# 更新状态
self.state = (next_r, next_c)
# 检查是否达到目标
done = (self.state == self.goal_state)
if done:
reward = 10.0 # 目标奖励
return self.state, reward, doneSimpleGridWorld环境是一个基础的二维网格强化学习环境,智能体需要从起始位置(0,0)导航至目标位置(size-1, size-1)。智能体可以执行四个基本方向的移动动作(上、下、左、右),在每一步会接收一个小的步骤惩罚(-0.1),碰撞墙壁则会获得更大的惩罚(-1.0),而到达目标则给予较大的奖励(10.0)。
# ------------------------------------- # 2. 加载Gymnasium钟摆 # ------------------------------------- pendulum_env = gym.make('Pendulum-v1') print("Pendulum-v1 environment loaded.") # 重置环境 observation, info = pendulum_env.reset(seed=42) print(f"Initial Observation: {observation}") print(f"Observation Space: {pendulum_env.observation_space}") print(f"Action Space: {pendulum_env.action_space}") # 执行随机步骤 random_action = pendulum_env.action_space.sample() observation, reward, terminated, truncated, info = pendulum_env.step(random_action) done = terminated or truncated print(f"Step with action {random_action}:") print(f" Next Obs: {observation}\n Reward: {reward}\n Done: {done}") # 关闭环境(如果使用了渲染则很重要) pendulum_env.close()
对于钟摆问题,我们使用Gymnasium库中的Pendulum-v1环境,这是一个基于物理的连续控制任务。上述代码初始化环境并展示了基本交互过程,包括获取初始观察、显示观察空间和动作空间的结构,以及执行一个随机动作并处理反馈。
让我们可视化这两个环境:

网格世界和钟摆
从上图可以看出,在网格世界环境中,智能体的目标是找到从起点到目标的最短路径;而在钟摆环境中,目标是将摆杆从任意初始位置控制到竖直向上的平衡点。
1、最简单的强化学习算法
首先从强化学习的基础概念出发,即智能体与环境交互的循环过程。即使是最基本的方法也遵循这一交互模式。
以下图示展示了强化学习智能体的基本工作原理:
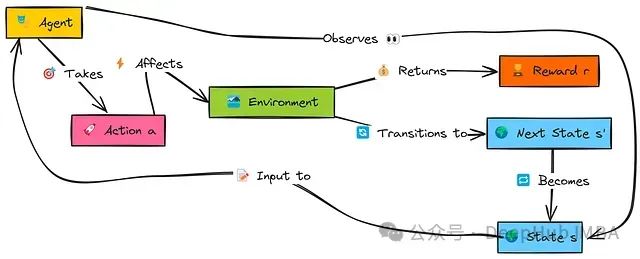
在这个交互流程中,智能体首先观察环境的当前状态s。基于该状态,智能体依据其当前策略决定执行一个动作a。该动作会影响环境,使环境转移到一个新状态s',并向智能体提供一个数值奖励r,指示动作的即时效果。智能体利用这一反馈信息(s, a, r, s')学习或调整其策略,然后从新状态s'继续交互循环。
我们将实现的第一个智能体与后续算法不同,它不会进行真正的"学习",而是通过记录在特定状态下执行特定动作所获得的即时奖励来做决策。其目标很简单:在给定状态时,选择过去在该状态中平均即时奖励最高的动作。该方法没有考虑长期后果的概念。
首先,我们需要一个数据结构来存储智能体的记忆,采用一个将(状态,动作)对映射到接收奖励列表的嵌套字典:
# 记忆结构:memory[(state_tuple)][action_index] -> [list_of_rewards] agent_memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]] = \ defaultdict(lambda: defaultdict(list)) # 示例:存储在状态(0,0)中采取动作1的奖励 # agent_memory[(0,0)][1].append(-0.1)
这个简单的字典结构能够存储每个状态-动作对的所有即时奖励记录。
接下来,智能体需要一个策略来选择其下一个动作。我们将基于记忆中存储的平均即时奖励,实现一个ε-贪心方法:
def choose_simple_action(state: Tuple[int, int], memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]], epsilon: float, n_actions: int) -> int: """ 基于平均即时奖励使用epsilon-greedy选择动作。 """ if random.random() < epsilon: return random.randrange(n_actions) # 探索 else: # 利用:找到具有最佳平均即时奖励的动作 state_action_memory = memory[state] best_avg_reward = -float('inf') best_actions = [] for action_idx in range(n_actions): rewards = state_action_memory[action_idx] # 如果从这个状态从未尝试过这个动作,将其平均奖励视为0或非常低 avg_reward = np.mean(rewards) if rewards else 0.0 if avg_reward > best_avg_reward: best_avg_reward = avg_reward best_actions = [action_idx] elif avg_reward == best_avg_reward: best_actions.append(action_idx) # 如果没有动作有积极奖励或状态未访问,随机选择 if not best_actions: return random.randrange(n_actions) # 随机打破平局 return random.choice(best_actions)
该函数使智能体可以在随机探索(以概率ε)和利用已知信息之间进行平衡。当选择利用时,智能体会选择在历史记录中平均即时奖励最高的动作。
最后,"学习"步骤仅仅是在执行动作后更新记忆:
def update_simple_memory(memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]], state: Tuple[int, int], action: int, reward: float) -> None: """ 为状态-动作对添加接收到的奖励到记忆中。 """ memory[state][action].append(reward)
这个简单的智能体仅记录即时结果,没有考虑长期回报或累积奖励,这是我们将通过后续算法解决的主要局限性。
下面通过可视化来分析该智能体的学习过程及表现:
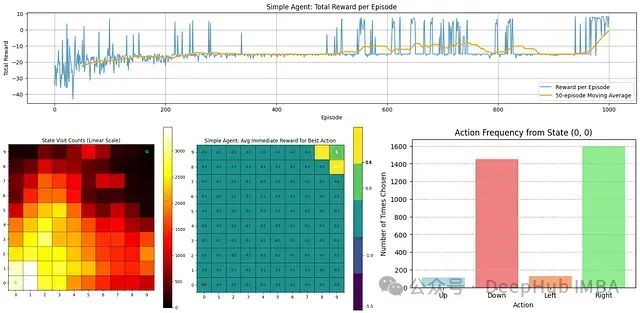
从上图可以观察到几个关键点:
奖励趋势:顶部图表显示了每个回合的总奖励。在早期阶段,智能体表现不佳(获得负奖励),但随着时间推移,其性能逐渐改善,这从移动平均线(橙色)的上升趋势可以明确看出。
状态访问频率:左下角热力图显示了智能体访问各个状态的频率。靠近起点的区域颜色较亮,表明探索集中在这些区域,而目标状态(G)的访问频率相对较低。
最佳动作奖励估计:中间热力图表示智能体对每个状态中最佳动作的即时奖励估计。大部分值较低,除了给予高奖励的目标状态附近区域。
动作选择分布:右下角条形图显示了智能体从起始状态(0,0)最常选择的动作。数据表明智能体倾向于向右和向下移动,这与通向目标的最优路径方向一致。
通过增加训练回合数,可以进一步提高智能体的寻路能力和性能。接下来,我们将介绍更为先进的Q学习算法。
2、Q学习
简单的记忆型智能体受限于只考虑即时奖励。Q学习则向前迈进了重要一步,它学习的是在一个状态中执行特定动作的"质量"或Q值,不仅考虑即时奖励,还考虑期望获得的总折扣未来奖励。
Q学习的目标是学习最优动作值函数 Q*(s,a)。
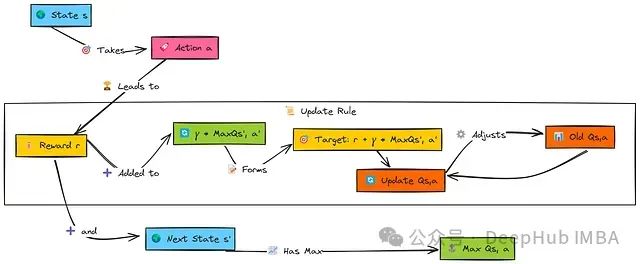
当智能体在状态s中执行动作a后,收到奖励r并转换到状态s'。为了更新原始(s,a)对的值,Q学习考虑了下一状态s'中所有可能动作a'的最佳Q值,表示为max Q(s', a')。
这个最大未来值经过因子γ(gamma)折扣后,与即时奖励r相加构成目标值。然后,原始(s,a)对的Q值通过学习率α(alpha)向这个目标值小幅调整。
学习通过以下更新规则进行:
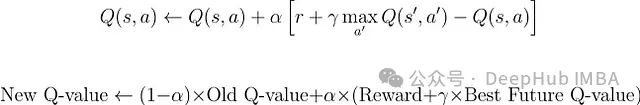
这意味着:
我们计算一个新的值估计:当前奖励 + 折扣因子 * 最佳未来值
计算这个新估计与当前Q值之间的差异(称为时序差分误差)
按照学习率确定的比例更新当前Q值
首先,我们初始化Q表,使用defaultdict可以简化实现,将未知的Q值默认初始化为0:
# Q表:q_table[(state_tuple)][action_index] -> q_value q_table: DefaultDict[Tuple[int, int], Dict[int, float]] = \ defaultdict(lambda: defaultdict(float)) # 示例:访问Q((0,0), 0=Up)将初始返回0.0 # print(q_table[(0,0)][0])
这个结构存储了每个状态内每个动作的估计Q值。
动作选择仍然使用epsilon-greedy,但现在它基于学习到的Q值来利用,而不仅仅是即时奖励。
# 基于Q值的Epsilon-Greedy动作选择 def choose_q_learning_action(state: Tuple[int, int], q_table: DefaultDict[Tuple[int, int], Dict[int, float]], epsilon: float, n_actions: int) -> int: """ 基于Q表值使用epsilon-greedy选择动作。 """ if random.random() < epsilon: return random.randrange(n_actions) # 探索 else: # 利用:选择该状态下Q值最高的动作 q_values_for_state = q_table[state] if not q_values_for_state: # 如果状态未被访问/更新 return random.randrange(n_actions) max_q = -float('inf') best_actions = [] # 遍历可用动作(0到n_actions-1) for action_idx in range(n_actions): q_val = q_values_for_state[action_idx] # defaultdict如果键缺失则返回0 if q_val > max_q: max_q = q_val best_actions = [action_idx] elif q_val == max_q: best_actions.append(action_idx) return random.choice(best_actions) # 随机打破平局
智能体会以概率epsilon进行随机探索,否则选择当前状态下估计长期回报最高的动作。
Q学习的核心更新函数实现了贝尔曼方程更新:
# Q学习更新规则 def update_q_value(q_table: DefaultDict[Tuple[int, int], Dict[int, float]], state: Tuple[int, int], action: int, reward: float, next_state: Tuple[int, int], alpha: float, # 学习率 gamma: float, # 折扣因子 n_actions: int, is_done: bool) -> None: """ 执行单个Q学习更新步骤。 """ # 获取当前Q值估计 current_q = q_table[state][action] # 找到下一个状态的最大Q值(Q学习特有) # 这代表了从下一个状态可达到的最佳可能值。 max_next_q = -float('inf') if not is_done and q_table[next_state]: # 检查next_state是否有条目 max_next_q = max(q_table[next_state].values()) elif is_done: max_next_q = 0.0 # 如果回合结束,则无未来奖励 else: max_next_q = 0.0 # 如果next_state还没有条目 # 计算TD目标:R + gamma * max(Q(s', a')) td_target = reward + gamma * max_next_q # 计算TD误差:TD目标 - Q(s, a) td_error = td_target - current_q # 更新Q值:Q(s, a) <- Q(s, a) + alpha * TD_Error q_table[state][action] = current_q + alpha * td_error
该函数根据即时奖励和下一状态的最大Q值(这是Q学习的脱策略特性)计算目标值,然后更新实际执行的状态-动作对的Q值。
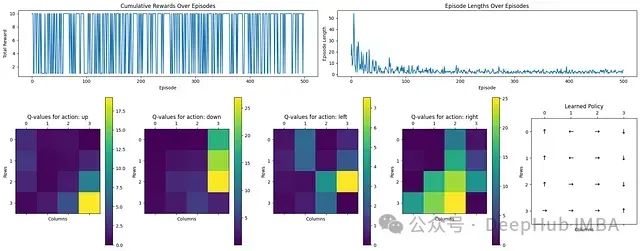
从上图可以看出Q学习的效果:
奖励和回合长度:顶部图表显示了随时间变化的累积奖励和回合长度。初始阶段,回合较长,表明智能体在探索低效路径。随着学习进行,回合长度明显减少,表明学习进程有效。
动作Q值分布:四个热力图展示了向上、下、左、右四个动作方向的Q值。黄色区域(高值)表示靠近目标状态的优先动作,而深色区域(低值)表示较不优化的选择。
学习策略可视化:最右侧的图表直观展示了最终学习到的策略,箭头指示各状态的最优动作方向,清晰地显示了通向目标的路径。
总体而言,通过Q学习,智能体成功学习了一条通向目标的最优路径。
3、Sarsa
SARSA(State-Action-Reward-State-Action,状态-动作-奖励-状态-动作)是另一种基于值的算法,与Q学习相似,但有一个关键区别:它是在策略的算法。
这意味着SARSA学习的是它当前正在遵循的策略的价值,包括任何探索性动作;而Q学习是脱策略的,它学习的是最优策略,不论当前采用何种探索策略。
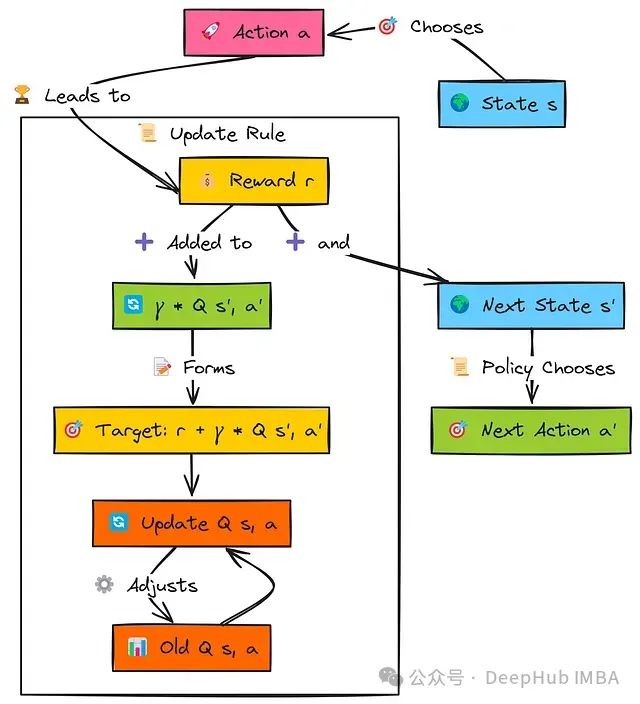
智能体从状态s开始,使用其策略选择动作a,获得奖励r并转换到状态s'。关键在于,在更新原始(s,a)对的值之前,智能体确定它将使用相同策略在状态s'中采取的下一个动作a'。
这个特定下一状态-动作对的Q值Q(s', a')经过因子γ折扣后与即时奖励r相加,构成SARSA目标。然后,原始的Q(s, a)按照学习率α的影响向这个目标值更新。这个过程遵循完整的五元组(s, a, r, s', a'),这也是算法名称的由来。
SARSA使用与Q学习相同的Q表结构存储状态-动作值,将状态-动作对映射到估计值。
动作选择通常也采用epsilon-greedy策略,与Q学习相同,以平衡探索和利用:
# Epsilon-Greedy动作选择(与Q学习相同的函数) def choose_sarsa_action(state: Tuple[int, int], q_table: DefaultDict[Tuple[int, int], Dict[int, float]], epsilon: float, n_actions: int) -> int: """ 基于Q表值使用epsilon-greedy选择动作。 """ if random.random() < epsilon: return random.randrange(n_actions) # 探索 else: # 利用:选择Q值最高的动作 q_values_for_state = q_table[state] if not q_values_for_state: return random.randrange(n_actions) max_q = -float('inf') best_actions = [] for action_idx in range(n_actions): q_val = q_values_for_state[action_idx] # 默认为0.0 if q_val > max_q: max_q = q_val best_actions = [action_idx] elif q_val == max_q: best_actions.append(action_idx) return random.choice(best_actions) if best_actions else random.randrange(n_actions)
SARSA与Q学习的关键区别在于更新规则,它使用实际选择的下一个动作(a')的Q值,而非下一状态中可能的最大Q值:
# SARSA更新规则 def update_sarsa_value(q_table: DefaultDict[Tuple[int, int], Dict[int, float]], state: Tuple[int, int], action: int, reward: float, next_state: Tuple[int, int], next_action: int, # 为下一步实际选择的动作 alpha: float, gamma: float, is_done: bool) -> None: """ 执行单个SARSA更新步骤。 """ # 获取当前Q值估计 current_q = q_table[state][action] # 获取*下一个状态和策略选择的下一个动作*的Q值 # 这是与Q学习的核心区别 q_next_state_action = 0.0 if not is_done: q_next_state_action = q_table[next_state][next_action] # 使用Q(s', a') # 计算TD目标:R + gamma * Q(s', a') td_target = reward + gamma * q_next_state_action # 计算TD误差:TD目标 - Q(s, a) td_error = td_target - current_q # 更新Q值:Q(s, a) <- Q(s, a) + alpha * TD_Error q_table[state][action] = current_q + alpha * td_error
由于SARSA在更新中使用Q(s',a')(下一个实际选择的动作的值,可能是探索性动作),相比Q学习,它倾向于学习更为保守的策略,特别是在存在潜在风险的环境中(如悬崖问题)。SARSA评估的是智能体当前积极遵循的策略。
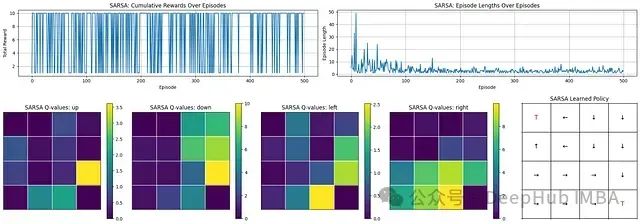
从SARSA的学习过程和结果可以观察到:
学习进展:回合长度显著减少,表明智能体学会了更高效地到达目标。
奖励表现:奖励总体较高但存在波动,反映了一个有效但不完全稳定的策略,这可能是由于持续的探索所致。
学习策略:Q值分布和最终策略图表显示智能体成功学习了指向目标状态('T')的动作序列。
综上所述,SARSA成功地学习了如何在环境中有效导航,提高了运行效率并频繁获得高奖励。最终的策略能够有效地引导智能体朝向目标,尽管性能上仍存在一定的变异性。
4、期望Sarsa
期望SARSA是在SARSA算法基础上的直接扩展,保持其在策略(on-policy)学习的核心特性,即基于当前策略所采取的动作进行价值函数的更新。
与标准SARSA依赖单一下一个动作(a')进行更新不同,期望SARSA通过考虑后继状态中所有可能动作并按照当前策略π(a'∣s')的概率分布对其Q值进行加权平均,从而计算下一个状态的期望值。
这种期望计算机制有效降低了更新过程中的方差,相较于标准SARSA仅依赖可能包含探索噪声的单一动作样本。降低方差通常带来更平稳的价值估计收敛过程,并可能加速学习效率。
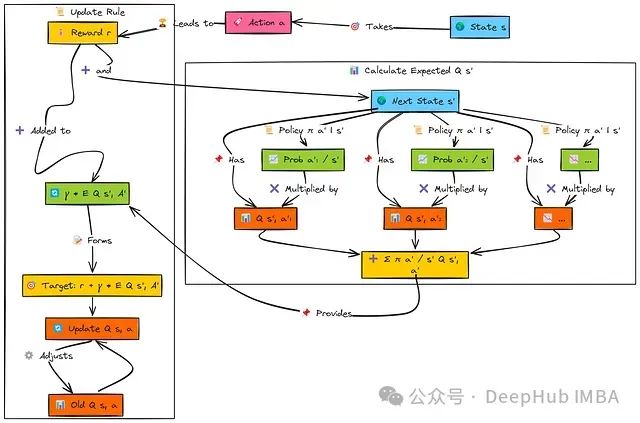
期望SARSA的基本过程与SARSA相似:智能体在状态's'中执行动作'a',获取奖励'r',并转移至后继状态's''。
然而在计算目标值时,期望SARSA考虑从's''可能执行的所有动作('a'₁, 'a'₂, ...)。算法从当前策略中提取选择每个动作的概率(π(a'∣s'))以及相应的Q值Q(s',a')。
随后,算法通过将每个动作的选择概率与其对应Q值的乘积求和,计算状态's''的期望Q值:
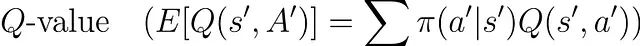
该期望值经折扣因子(γ)调整后与奖励'r'相加构成目标值。最后,根据学习率(α)将当前Q(s,a)向这个期望目标值方向更新。
Q表初始化函数和动作选择机制沿用了与SARSA部分相同的基于epsilon-greedy策略的实现。
期望SARSA的主要区别在于其更新规则,现在基于epsilon-greedy策略概率分布计算后继动作的期望值。
# 期望SARSA更新规则 def update_expected_sarsa_value( q_table: DefaultDict[Tuple[int, int], Dict[str, float]], state: Tuple[int, int], action: int, # 现在使用整数动作索引 reward: float, next_state: Tuple[int, int], alpha: float, gamma: float, epsilon: float, # 计算期望值需要当前epsilon n_actions: int, is_done: bool ) -> None: """ 执行单个期望SARSA更新步骤。 """ # 获取当前Q值估计 current_q = q_table[state][action] # 计算下一个状态的期望Q值 expected_q_next = 0.0 if not is_done and q_table[next_state]: # 检查next_state是否存在且有条目 q_values_next_state = q_table[next_state] if q_values_next_state: # 检查字典是否非空 max_q_next = max(q_values_next_state.values()) # 找到所有最佳动作(处理平局) best_actions = [a for a, q in q_values_next_state.items() if q == max_q_next] # 在epsilon-greedy下计算概率 prob_greedy = (1.0 - epsilon) / len(best_actions) # 将贪婪概率分配给最佳动作 prob_explore = epsilon / n_actions # 计算期望值 E[Q(s', A')] = sum[ pi(a'|s') * Q(s', a') ] for a_prime in range(n_actions): prob_a_prime = 0.0 if a_prime in best_actions: prob_a_prime += prob_greedy # 添加贪婪概率 prob_a_prime += prob_explore # 添加探索概率(适用于所有动作) expected_q_next += prob_a_prime * q_values_next_state.get(a_prime, 0.0) # 如果动作未见则默认为0 # TD目标: R + gamma * E[Q(s', A')] td_target = reward + gamma * expected_q_next # TD误差: TD目标 - Q(s, a) td_error = td_target - current_q # 更新Q值 q_table[state][action] = current_q + alpha * td_error
此更新函数考虑了epsilon-greedy策略的概率分布特性,在计算未来状态价值时,使更新过程对下一步可能选择的单一(可能随机)动作的敏感度降低,从而相比标准SARSA提供更稳定的学习过程。
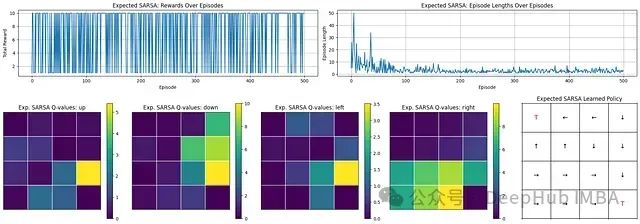
期望Sarsa
学习进展分析:回合长度迅速降低,表明智能体快速掌握了到达目标的高效路径。
奖励性能评估:初始学习阶段后,智能体能够频繁且稳定地获得接近10的高奖励值,证明其策略有效性。
学习策略分析:Q值矩阵清晰地识别出了首选动作,最终策略网格展示了智能体形成的合理路径,能够可靠地引导至终端状态('T')。
期望SARSA展现了强大且高效的学习能力,能够快速收敛至稳定策略。智能体获得持续高奖励的能力表明其学习到的策略具有稳定性和有效性。
5、Dyna Q
之前介绍的算法均为无模型方法,即仅从与环境的直接交互中学习。
Dyna-Q引入了一种简洁的基于模型强化学习框架,通过同时学习环境模型并利用该模型进行额外的"规划"步骤(模拟经验),有效加速学习过程。
核心理念在于更高效地利用每次真实交互经验:将其用于直接Q学习更新、内部模型更新,以及利用模型生成多次模拟未来场景并执行额外Q学习更新。
这种方法通常能显著提高样本效率,即从更少的真实环境交互中获取更快的学习速度。
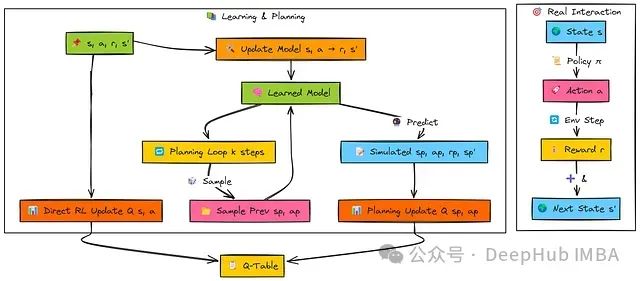
当智能体在状态s执行动作a并观测到奖励r与后继状态s'后,Dyna-Q算法并行执行三项任务:
直接强化学习(RL):利用真实经验(s, a, r, s')更新Q值Q(s, a),与标准Q学习算法相同。
模型学习:更新内部环境模型,记录状态s执行动作a导致奖励r和后继状态s'的转移关系。
规划:执行k次额外更新,每次随机选择先前经历过的状态-动作对(s_p, a_p),查询学习到的模型获取预测奖励r_p和预测后继状态s_p',然后使用这些模拟经验(s_p, a_p, r_p, s_p')执行Q学习更新。
Q表:维护Q(s,a)估计值。在最基本的表格形式中,这是一个字典结构,存储先前访问过的状态-动作对的观察结果(奖励和后继状态):Model(s,a)→(r,s′)。
实现Dyna-Q需要定义Q表和模型的数据结构,以及一种追踪已访问状态-动作对用于规划的机制:
# Q表:q_table[(state_tuple)][action_index] -> q_value(与之前相同) q_table_dynaq: DefaultDict[Tuple[int, int], Dict[int, float]] = \ defaultdict(lambda: defaultdict(float)) # 模型:model[(state_tuple, action_index)] -> (reward, next_state_tuple) model_dynaq: Dict[Tuple[Tuple[int, int], int], Tuple[float, Tuple[int, int]]] = {} # 跟踪已观察到的状态-动作对,用于规划期间的采样 observed_state_actions: List[Tuple[Tuple[int, int], int]] = []
动作选择仍然基于当前Q表使用epsilon-greedy策略。直接RL更新采用标准Q学习更新规则(在Q学习部分中详细介绍)。
算法的创新部分在于模型更新和规划步骤的实现。
首先,我们需要一个基于真实经验更新环境模型的函数:
# 模型更新函数 def update_model(model: Dict[Tuple[Tuple[int, int], int], Tuple[float, Tuple[int, int]]], observed_pairs: List[Tuple[Tuple[int, int], int]], state: Tuple[int, int], action: int, reward: float, next_state: Tuple[int, int]) -> None: """ 更新确定性表格模型和已观察对列表。 """ state_action = (state, action) model[state_action] = (reward, next_state) # 存储结果 # 如果这个对之前未见过,则添加到列表中 if state_action not in observed_pairs: observed_pairs.append(state_action)
此函数简单记录状态-动作对及其结果转移信息。
规划步骤函数实现了从模型采样并应用Q学习更新的核心机制:
# 规划步骤函数 def planning_steps(k: int, # 规划步骤数 q_table: DefaultDict[Tuple[int, int], Dict[int, float]], model: Dict[Tuple[Tuple[int, int], int], Tuple[float, Tuple[int, int]]], observed_pairs: List[Tuple[Tuple[int, int], int]], alpha: float, gamma: float, n_actions: int) -> None: """ 使用模型执行'k'次模拟Q学习更新。 """ if not observed_pairs: # 没有观察就无法规划 return for _ in range(k): # 1. 采样随机先前观察到的状态-动作对 state_p, action_p = random.choice(observed_pairs) # 2. 查询模型获取模拟结果 reward_p, next_state_p = model[(state_p, action_p)] # 3. 使用模拟经验应用Q学习更新 # (假设模拟步骤不会结束回合,除非模型表示如此) # 这里需要Q学习部分的update_q_value函数。 update_q_value(q_table, state_p, action_p, reward_p, next_state_p, alpha, gamma, n_actions, is_done=False) # 在模拟中假设未结束 # (更复杂的模型可以预测'done')
此规划函数利用从智能体学习的环境模型中采样的转移数据执行k次Q学习更新,实现了价值信息的更快传播。
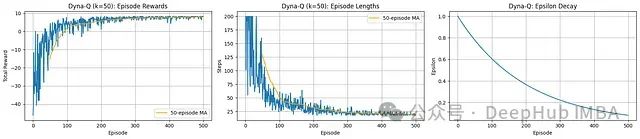
学习进展分析:观察到极为快速的收敛过程。回合长度迅速下降,表明智能体能够非常高效地学习到最优路径。
奖励性能分析:总奖励从初始负值陡峭上升至持续稳定的高正值,展示了快速有效的策略学习过程。
效率评估(Dyna-Q特性):步数和奖励的快速改善明显体现了Dyna-Q规划机制(k=50)的优势,通过利用学习模型显著加速学习过程。
Dyna-Q算法展现了卓越的样本效率,使智能体能够迅速学习网格环境中的有效策略。规划组件促进了快速收敛至高奖励和短回合长度的优化目标。
6、Reinforce
我们现在将讨论从基于值的方法(Q学习,SARSA)转向基于策略的方法的重要转变。
REINFORCE算法不是学习动作值函数,而是直接学习和优化参数化策略π(a∣s;θ),该策略将状态直接映射至动作概率分布,由参数集θ决定。策略参数调整的目标是使高质量动作(即导致高累积奖励的动作)具有更高的发生概率。
REINFORCE采用蒙特卡洛方法框架,这意味着算法在更新策略参数前需要收集完整回合的奖励序列。
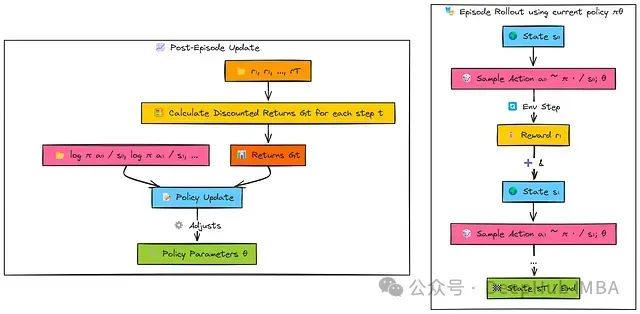
智能体使用当前策略网络(π_θ)生成一个完整回合的交互序列。在每个时间步骤,智能体:
基于当前状态s采样一个动作a。
存储该动作的对数概率(log π(a|s))。
记录获取的奖励r。
回合完成后,智能体回顾分析整个奖励序列。算法计算从每个时间步t开始的折扣累积回报(G_t)。
最终,策略参数(θ)通过梯度上升进行更新:
对于后续获得高回报(G_t)的动作,更新过程增加其对数概率(log π(a|s))。
对于后续获得低回报的动作,更新过程降低其对数概率。
首先,我们定义策略网络架构。该网络类似于Actor网络,通过Softmax层输出动作概率分布:
# 定义策略网络架构 class PolicyNetwork(nn.Module): def __init__(self, n_observations: int, n_actions: int): super(PolicyNetwork, self).__init__() self.layer1 = nn.Linear(n_observations, 128) self.layer2 = nn.Linear(128, 128) self.layer3 = nn.Linear(128, n_actions) # 输出logits def forward(self, x: torch.Tensor) -> Categorical: """ 前向传播,返回动作的Categorical分布。 """ if not isinstance(x, torch.Tensor): x = torch.tensor(x, dtype=torch.float32, device=device) # 假设'device'已定义 elif x.dtype != torch.float32: x = x.to(dtype=torch.float32) if x.dim() == 1: x = x.unsqueeze(0) x = F.relu(self.layer1(x)) x = F.relu(self.layer2(x)) action_logits = self.layer3(x) # 直接从logits创建Categorical分布 return Categorical(logits=action_logits)
该网络接收环境状态作为输入,并提供一种机制来采样动作并计算其对数概率。
接下来,动作选择函数利用策略网络采样动作并记录其对数概率:
# 通过采样选择动作 def select_action_reinforce(state: torch.Tensor, policy_net: PolicyNetwork) -> Tuple[int, torch.Tensor]: """ 通过从策略网络的输出分布采样选择动作。 """ action_dist = policy_net(state) action = action_dist.sample() # 采样动作 log_prob = action_dist.log_prob(action) # 获取所选动作的对数概率 return action.item(), log_prob
与epsilon-greedy策略不同,REINFORCE的探索机制是通过网络输出的概率分布采样过程自然引入的。
在回合结束后,需要计算每个时间步的折扣累积回报Gt:
# 计算折扣回报 def calculate_discounted_returns(rewards: List[float], gamma: float, standardize: bool = True) -> torch.Tensor: """ 计算每一步t的折扣回报G_t,可选择标准化。 """ n_steps = len(rewards) returns = torch.zeros(n_steps, dtype=torch.float32) # 保持在CPU上进行计算 discounted_return = 0.0 # 反向迭代 for t in reversed(range(n_steps)): discounted_return = rewards[t] + gamma * discounted_return returns[t] = discounted_return if standardize: mean_return = torch.mean(returns) std_return = torch.std(returns) + 1e-8 # 添加epsilon以保持稳定 returns = (returns - mean_return) / std_return return returns.to(device) # 最后移动到适当的设备
此函数计算回合中每个动作后的实际累积回报(Gt)。标准化处理能够提高训练稳定性。
最后,策略更新函数利用收集的对数概率和回报调整网络参数:
# 策略更新步骤 def optimize_policy(log_probs: List[torch.Tensor], returns: torch.Tensor, optimizer: optim.Optimizer) -> float: """ 执行一次REINFORCE策略梯度更新。 """ # 堆叠对数概率并确保回报具有正确的形状 log_probs_tensor = torch.stack(log_probs) returns = returns.detach() # 在此更新中将回报视为固定目标 # 计算损失:- Sum(G_t * log_pi(a_t|s_t)) # 我们最小化负目标 loss = -torch.sum(returns * log_probs_tensor) # 执行优化 optimizer.zero_grad() loss.backward() optimizer.step() return loss.item()
此函数计算REINFORCE算法的策略梯度损失,并使用优化器(如Adam)更新策略网络参数θ,使有利的动作序列在未来更可能出现。

学习进展分析:智能体展现有效学习能力,从回合步骤(长度)的急剧减少并在低值稳定可以明确观察到。
奖励性能评估:总奖励从负值大幅提升并收敛到稳定的高正值,表明智能体成功学习了高效策略。
损失和稳定性分析:损失值在整个训练过程中表现出显著波动,移动平均线也未展示明确的收敛趋势。这突显了基本REINFORCE算法固有的高方差特性。
REINFORCE算法成功训练了智能体解决网格导航任务,实现了高奖励和高效路径规划。然而,从损失曲线的波动性可以看出,训练过程存在高方差现象,这是该算法的典型特征。
7、PPO(近端策略优化)
像REINFORCE这样的标准策略梯度方法可能存在训练不稳定性,因为基于噪声回报的单次更新可能导致策略发生剧烈变化,进而导致性能严重下降。
信任区域策略优化(TRPO)通过复杂的约束优化机制解决了这一问题。而近端策略优化(PPO)则提供了一种更为简洁的替代方案,通过使用裁剪的替代目标函数实现类似的稳定性。
PPO是一种演员-评论家、在策略算法,设计理念是在更新过程中确保新策略与旧策略保持适当的相似性,防止破坏性的大幅策略变化,同时保持高效学习能力,通常在同一批数据上进行多次迭代更新(epochs)。
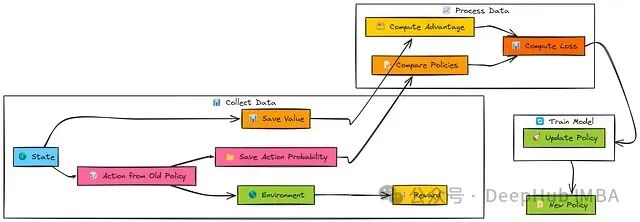
与REINFORCE和A2C类似,PPO首先使用当前的旧策略(π_old)收集一批经验数据(s, a, r, s')。算法同时存储每个动作在该策略下的对数概率。评论家网络(V_old)提供状态值估计。
在收集足够的经验数据后,计算优势估计(Â)—通常使用广义优势估计(GAE)方法。
PPO核心更新在这批收集的数据上进行多个epochs的迭代:
当前的新策略(π_new)对批次状态进行评估以获得新的动作对数概率。
计算新旧策略之间的概率比率r。
PPO应用裁剪目标(L_CLIP),基于裁剪参数(ϵ)限制r对更新的影响程度。
完整损失函数由以下组成部分构成:
裁剪的策略损失(L_CLIP),确保策略更新稳定性。
值函数损失(L_VF),优化评论家网络。
熵正则项(S),鼓励足够的探索行为。
演员(策略)和评论家(值函数)网络通过梯度下降基于此综合损失函数进行优化。
PPO使用与A2C和TRPO相同的Actor(策略网络)和Critic(值网络)架构。
算法通常采用相同的广义优势估计(GAE)函数计算优势值。PPO的独特之处在于其更新逻辑,特别是策略损失函数(L_CLIP)的计算方式。
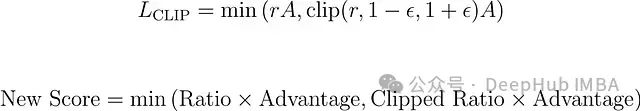
更新逻辑方程
# PPO更新步骤(简化视图,假设数据已批处理) def update_ppo(actor: PolicyNetwork, critic: ValueNetwork, actor_optimizer: optim.Optimizer, critic_optimizer: optim.Optimizer, states: torch.Tensor, actions: torch.Tensor, log_probs_old: torch.Tensor, # 来自用于rollout的策略的对数概率 advantages: torch.Tensor, # 计算的GAE优势 returns_to_go: torch.Tensor, # 值函数的目标(Adv + V_old) ppo_epochs: int, # 每批次的更新次数 ppo_clip_epsilon: float, # 裁剪参数ε value_loss_coeff: float, # 评论家损失权重 entropy_coeff: float) -> Tuple[float, float, float]: # 平均损失 total_policy_loss = 0.0 total_value_loss = 0.0 total_entropy = 0.0 # 数据在进入循环前应该被分离 advantages = advantages.detach() log_probs_old = log_probs_old.detach() returns_to_go = returns_to_go.detach() # 在同一批次上执行多个epochs的更新 for _ in range(ppo_epochs): # --- Actor(策略)更新 --- policy_dist = actor(states) # 获取当前策略分布 log_probs_new = policy_dist.log_prob(actions) # 动作在*新*策略下的对数概率 entropy = policy_dist.entropy().mean() # 平均熵 # 计算比率r(θ) = π_new / π_old ratio = torch.exp(log_probs_new - log_probs_old) # 计算裁剪的替代目标部分 surr1 = ratio * advantages surr2 = torch.clamp(ratio, 1.0 - ppo_clip_epsilon, 1.0 + ppo_clip_epsilon) * advantages # 策略损失:-(min(surr1, surr2)) - entropy_bonus policy_loss = -torch.min(surr1, surr2).mean() - entropy_coeff * entropy # 优化actor actor_optimizer.zero_grad() policy_loss.backward() actor_optimizer.step() # --- Critic(值)更新 --- values_pred = critic(states).squeeze() # 使用当前critic预测V(s) value_loss = F.mse_loss(values_pred, returns_to_go) # 与计算的回报比较 # 优化critic critic_optimizer.zero_grad() (value_loss_coeff * value_loss).backward() # 在backward前缩放损失 critic_optimizer.step() # 累积统计 total_policy_loss += policy_loss.item() total_value_loss += value_loss.item() total_entropy += entropy.item() # 返回epochs上的平均损失 return total_policy_loss / ppo_epochs, total_value_loss / ppo_epochs, total_entropy / ppo_epochs
此更新函数在收集的数据批次上进行多次迭代(epochs)。
在每次迭代中,函数计算策略比率,应用裁剪机制限制策略变化幅度,计算值函数损失,并更新两个网络参数。这种组合机制实现了稳定且高效的学习过程。
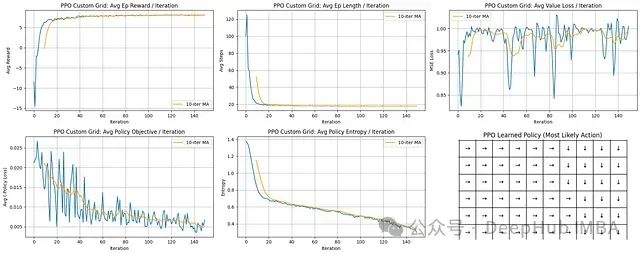
学习进展分析:PPO展示极为快速的学习能力;平均回合长度急剧下降并迅速稳定在较低水平。
奖励性能评估:平均奖励值呈陡峭上升趋势并稳定在接近最大可能值的水平,表明算法快速收敛到高效策略。
训练稳定性分析:策略目标(损失)和熵值均呈稳步下降趋势,表明策略持续改进并逐步减少探索。值函数损失虽有波动但整体保持在可控范围内。
学习策略评估:最终策略网格清晰展示了确定性且合理的导航路径,指向网格右下方的目标区域。
PPO算法表现卓越,特点是收敛速度快、学习过程稳定且能持续获得高奖励。智能体能够迅速学习形成高效且有效的网格环境导航策略。
8、A2C(同步优势演员-评论家)
同步优势演员-评论家(A2C)是演员-评论家算法族中的一个同步、简化变体。
与其他演员-评论家方法相似,A2C使用双网络架构:一个演员网络负责动作选择,一个评论家网络负责状态评估。A2C特别采用优势函数估计:
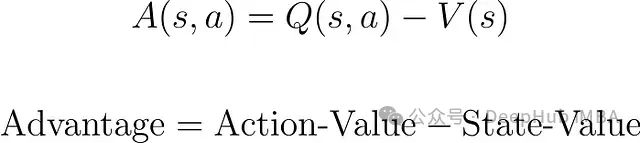
优势函数指导演员网络的更新过程,相比REINFORCE算法能够有效降低梯度估计的方差。
与其异步版本A3C不同,A2C执行同步参数更新。
算法通常在收集一批经验数据后(通常从并行环境收集,尽管本示例中按顺序模拟)才同时计算并应用梯度更新到演员和评论家网络参数。
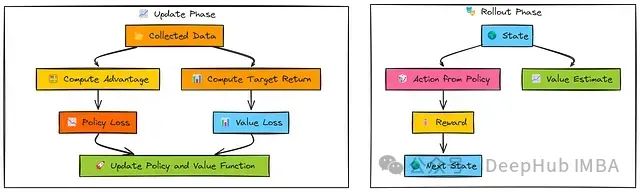
在交互采样阶段,演员网络(π_θ)根据当前状态(s)选择动作(a),而评论家网络(V_ϕ)估计该状态的价值(V(s))。
执行动作后获得奖励(r)和后继状态(s')。此过程重复N步,收集一批交互数据。
在参数更新阶段,收集的奖励序列和值估计用于计算目标回报(R_t)和优势估计(Â)。策略损失通过优势和动作对数概率计算,目标是增强具有正优势的动作概率。
值函数损失计算为预测值(V(s_t))与目标回报(R_t)之间的均方误差。
最后,两种损失函数的梯度被计算并用于同步更新演员(θ)和评论家(ϕ)网络参数。
演员网络:策略函数π(a∣s;θ),输出动作概率分布。
评论家网络:值函数V(s;ϕ),估计状态价值。
优势函数:计算为Â_t≈R_t−V(s_t),其中R_t通常是n步回报或通过GAE计算。它衡量动作相对于状态平均预期回报的相对优势。
同步更新机制:梯度在一批经验数据上计算并同时应用到演员和评论家网络。
A2C使用与PPO和TRPO相同的Actor(策略网络)和Critic(值网络)架构。
算法通常采用广义优势估计(GAE)计算优势值和评论家网络的目标回报。
A2C更新函数计算组合损失并同步应用梯度更新:
# A2C更新步骤 def update_a2c(actor: PolicyNetwork, critic: ValueNetwork, actor_optimizer: optim.Optimizer, critic_optimizer: optim.Optimizer, states: torch.Tensor, actions: torch.Tensor, advantages: torch.Tensor, # 计算的GAE优势 returns_to_go: torch.Tensor, # 值函数的目标(Adv + V_old) value_loss_coeff: float, # 评论家损失权重 entropy_coeff: float # 熵奖励权重 ) -> Tuple[float, float, float]: # 平均损失 # --- 评估当前网络 --- policy_dist = actor(states) log_probs = policy_dist.log_prob(actions) # 所采取动作的对数概率 entropy = policy_dist.entropy().mean() # 平均熵 values_pred = critic(states).squeeze() # 评论家的值预测 # --- 计算损失 --- # 策略损失(演员):- E[log_pi * A_detached] - entropy_bonus policy_loss = -(log_probs * advantages.detach()).mean() - entropy_coeff * entropy # 值损失(评论家):MSE(V_pred, Returns_detached) value_loss = F.mse_loss(values_pred, returns_to_go.detach()) # --- 优化演员 --- actor_optimizer.zero_grad() policy_loss.backward() # 计算演员梯度 actor_optimizer.step() # 更新演员权重 # --- 优化评论家 --- critic_optimizer.zero_grad() # 评论家损失的反向传播(缩放后) (value_loss_coeff * value_loss).backward() critic_optimizer.step() # 更新评论家权重 # 返回用于记录的损失(策略目标部分,值损失,熵) return policy_loss.item() + entropy_coeff * entropy.item(), value_loss.item(), entropy.item()
此函数接收一批交互数据,基于计算的优势估计和目标回报计算策略和值函数损失,然后对演员和评论家网络执行独立但同步的梯度更新。
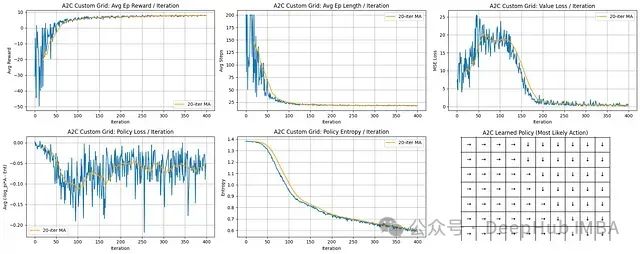
学习进展与效率分析:智能体展现出强劲的学习能力。平均回合奖励从显著负值迅速上升,在约100-150次迭代后稳定收敛在接近最大可能值水平。同时,平均回合长度从最大步数限制急剧下降至低且稳定的值,表明智能体迅速掌握了高效路径规划能力。
值函数学习过程:值损失(MSE)在初始阶段呈上升趋势,这是因为评论家网络需要在快速变化的策略环境中学习准确的状态价值。损失在约75次迭代后达到峰值,随后随着策略稳定而稳步下降,表明评论家网络对状态价值的预测精度显著提高。
策略优化与稳定性:策略损失曲线呈现一定噪声,这是策略梯度方法的固有特性,反映了更新过程中的方差。然而,移动平均趋势显示整体损失呈下降趋势(尽管有波动),表明策略持续改进。
最终策略评估:策略网格展示了一个连贯且确定性的导航策略。方向箭头一致地指引智能体,形成通向位于网格右下区域目标位置的明确路径,证明算法成功收敛到特定的导航方案。
A2C算法成功优化了策略网络(演员)和值函数网络(评论家),实现了快速收敛到高平均奖励和高效导航路径的目标,最终形成了清晰合理的策略决策模式。
9、A3C (异步优势演员-评论家算法)
异步优势演员-评论家算法(A3C)是一项突破性的强化学习方法,其创新之处在于通过并行化机制实现演员-评论家学习的稳定性,而无需依赖DQN中使用的经验回放缓冲区。
该算法部署多个并行执行的"工作者"智能体,每个工作者与环境的独立副本进行交互。
A3C的核心原理是基于异步更新机制:各工作者根据其本地经验独立计算参数更新,并将这些更新异步应用于共享的全局网络,无需相互协调或等待。
这种来自不同工作者的持续、多样化的更新流有效降低了训练数据间的相关性,从而显著提高了学习稳定性。
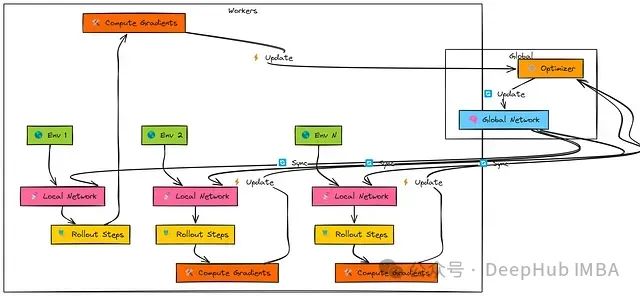
该算法架构中存在多个独立工作者。每个工作者首先从共享的"全局网络"复制参数。
随后,工作者使用其本地网络副本与专属环境实例交互,执行一系列步骤(即"n步展开")。
基于这段轨迹经验,工作者计算其本地网络中演员和评论家组件的梯度。
最后,工作者异步地将这些梯度传递给共享优化器,用于更新全局网络参数。
由于各工作者独立运行且在不同时间点进行更新,全局网络接收到的是具有多样性且相关性较低的更新流。
A3C的关键技术特点包括:
异步更新: 工作者之间无需相互等待,减少了计算资源的闲置时间,同时降低了更新之间的数据相关性。
全局与本地网络架构: 工作者定期与中央全局网络同步参数,但在本地进行梯度计算。
N步回报计算: 更新通常基于短序列(n步)内收集的奖励总和,再加上由评论家网络对n步后状态的价值估计。这种方法平衡了单步时序差分学习的偏差与完整蒙特卡洛回报的方差。
优势估计: 优势函数计算采用Â_t = R_t − V(s_t)公式,其中R_t表示n步回报。
A3C典型实现采用共享初层特征提取的组合演员-评论家网络架构:
# 共享的演员-评论家网络(与A2C结构相同) class ActorCriticNetwork(nn.Module): def __init__(self, n_observations: int, n_actions: int): super(ActorCriticNetwork, self).__init__() self.layer1 = nn.Linear(n_observations, 128) self.layer2 = nn.Linear(128, 128) self.actor_head = nn.Linear(128, n_actions) # 动作对数概率 self.critic_head = nn.Linear(128, 1) # 状态价值 def forward(self, x: torch.Tensor) -> Tuple[Categorical, torch.Tensor]: if not isinstance(x, torch.Tensor): x = torch.tensor(x, dtype=torch.float32, device=x.device) elif x.dtype != torch.float32: x = x.to(dtype=torch.float32) if x.dim() == 1: x = x.unsqueeze(0) x = F.relu(self.layer1(x)) shared_features = F.relu(self.layer2(x)) action_logits = self.actor_head(shared_features) state_value = self.critic_head(shared_features) # 确保在添加批次维度的情况下值被压缩 if x.shape[0] == 1 and state_value.dim() > 0: state_value = state_value.squeeze(0) return Categorical(logits=action_logits.to(x.device)), state_value
每个工作者收集n步经验并计算目标回报和优势值:
# 计算N步回报和优势(在每个工作者内使用) def compute_n_step_returns_advantages(rewards: List[float], values: List[torch.Tensor], # 网络预测的V(s_t) bootstrap_value: torch.Tensor, # V(s_{t+n})预测,已分离 dones: List[float], # 完成标志(0.0或1.0) gamma: float ) -> Tuple[torch.Tensor, torch.Tensor]: """ 计算n步回报(评论家目标)和优势(演员指导)。""" n_steps = len(rewards) returns = torch.zeros(n_steps, dtype=torch.float32) # 在CPU上存储结果 advantages = torch.zeros(n_steps, dtype=torch.float32) # 分离用于优势计算的值(作为基线的一部分) values_detached = torch.cat([v.detach() for v in values]).squeeze().cpu() R = bootstrap_value.detach().cpu() # 从自举值开始 for t in reversed(range(n_steps)): R = rewards[t] + gamma * R * (1.0 - dones[t]) # 计算n步回报 returns[t] = R # 确保values_detached具有正确的形状以进行优势计算 value_t = values_detached if values_detached.dim() == 0 else values_detached[t] advantages[t] = R - value_t # 优势 = N步回报 - V(s_t) # 可选:标准化优势 # advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8) return returns, advantages
工作者基于n步经验计算策略损失、价值损失和熵奖励,在本地计算梯度,并通过共享优化器异步更新全局网络参数:
# --- 工作者损失计算(概念性 - 由每个工作者执行) --- # 假设'log_probs_tensor'、'values_pred_tensor'、'entropies_tensor'包含 # n步展开的网络输出, # 而'returns_tensor'、'advantages_tensor'包含计算出的目标。 policy_loss = -(log_probs_tensor * advantages_tensor.detach()).mean() value_loss = F.mse_loss(values_pred_tensor, returns_tensor.detach()) entropy_loss = -entropies_tensor.mean() total_loss = policy_loss + value_loss_coeff * value_loss + entropy_coeff * entropy_loss # --- 梯度应用(概念性) --- global_optimizer.zero_grad() total_loss.backward() # 计算本地模型上的梯度 # 将梯度从local_model.parameters()传输到global_model.parameters() global_optimizer.step() # 将梯度应用于全局模型
这种异步更新机制使多个工作者能够并行贡献梯度更新,显著提高了多核系统上的训练时间效率。
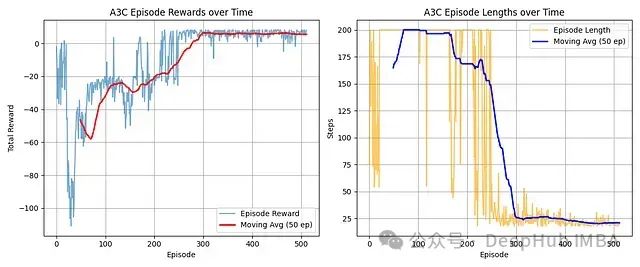
奖励进展: 智能体从初始负分状态显著改善,移动平均线表明在约300回合后收敛至稳定的高正奖励水平。
效率提升: 回合长度在250回合左右出现显著下降,从最大步数减少至稳定的较低平均值,表明任务完成效率大幅提高。
学习效果: 图表清晰展示了A3C的有效学习过程,从初始探索/低效阶段转变为稳定高效的策略,持续有效地解决任务。
A3C算法成功学习了目标任务,展现了从初始低效表现到稳定高奖励水平的显著进步。
这一学习成效与效率的大幅提升紧密相关,从回合长度的快速下降可以明确观察到这一点。
智能体在大约300回合的训练后收敛到一个高质量且高效的策略。
10、DDPG (用于连续动作的演员-评论家算法)
深度确定性策略梯度(DDPG)是一种将演员-评论家方法扩展到连续动作空间环境的算法,适用于需要精确控制的任务(如施加特定扭矩、设定精确速度等)。
该算法巧妙地融合了DQN的核心技术(如经验回放缓冲区和目标网络)与确定性策略梯度方法。
DDPG的核心技术原理包括:
确定性演员网络: 与REINFORCE/A2C/PPO等输出动作概率分布的算法不同,DDPG的演员网络直接为给定状态输出一个确定性动作向量。
Q值评论家网络: 评论家网络学习状态-动作值函数Q(s, a),类似于Q学习,但针对连续动作空间进行了适配,评估在状态(s)中执行演员选择的连续动作(a)的价值。
离策略学习: 采用经验回放缓冲区存储交互经验并随机采样小批量数据进行学习,实现从历史数据中进行稳定学习,类似于DQN的机制。
目标网络机制: 为演员和评论家网络均设置独立的目标网络,用于计算评论家的目标值,显著提高学习稳定性。
探索策略: 由于算法采用确定性策略,需要手动添加探索机制,通常通过向演员网络输出动作添加噪声(如高斯噪声或奥恩斯坦-乌伦贝克过程噪声)实现。
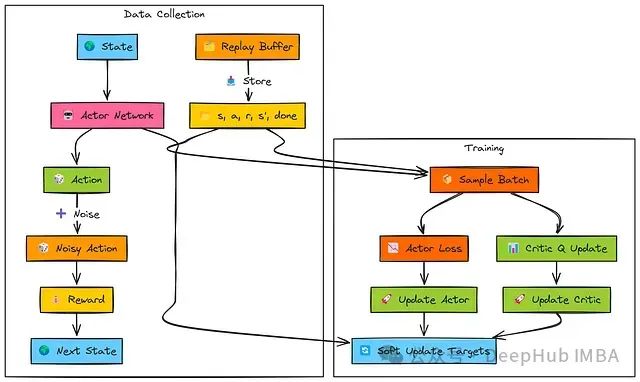
在环境交互阶段,演员网络基于当前状态(s)生成确定性动作。
为实现探索,在将动作传递给环境执行前,系统向该动作添加噪声。产生的转移经验(s, a, r, s', done)被存储到经验回放缓冲区中。
在训练阶段,系统从回放缓冲区中随机采样批量数据:
评论家网络更新: 目标Q值(TD目标y)通过结合即时奖励(r)、目标演员和目标评论家网络对下一状态(s')的评估计算得出。主评论家网络计算当前批次状态和动作的Q(s, a)值。系统使用目标(y)与Q(s, a)之间的均方误差(MSE损失)更新主评论家网络参数(ϕ)。
演员网络更新: 演员网络为批次状态(s)计算确定性动作。这些动作作为输入传递给主评论家网络以获取对应的Q值评估。演员网络通过最大化这些Q值(即最小化负Q值,L_θ = −Q)进行参数更新。
目标网络更新: 目标演员和目标评论家网络(θ', ϕ')通过软更新机制逐步向主网络参数靠近,以平滑学习过程并提高稳定性。
DDPG实现需要设计独立的演员和评论家网络架构。演员网络输出确定性连续动作,通常使用tanh激活函数进行归一化和缩放:
# 简化的DDPG演员网络(输出连续动作) class ActorNetworkDDPG(nn.Module): def __init__(self, state_dim: int, action_dim: int, max_action: float): super(ActorNetworkDDPG, self).__init__() self.layer1 = nn.Linear(state_dim, 256) self.layer2 = nn.Linear(256, 256) self.layer3 = nn.Linear(256, action_dim) self.max_action = max_action # 用于缩放输出 def forward(self, state: torch.Tensor) -> torch.Tensor: x = F.relu(self.layer1(state)) x = F.relu(self.layer2(x)) # 使用tanh输出-1到1之间的值,然后缩放 action = self.max_action * torch.tanh(self.layer3(x)) return action # 简化的DDPG评论家网络(接收状态和动作) class CriticNetworkDDPG(nn.Module): def __init__(self, state_dim: int, action_dim: int): super(CriticNetworkDDPG, self).__init__() # 分别或一起处理状态和动作 self.layer1 = nn.Linear(state_dim + action_dim, 256) self.layer2 = nn.Linear(256, 256) self.layer3 = nn.Linear(256, 1) # 输出单个Q值 def forward(self, state: torch.Tensor, action: torch.Tensor) -> torch.Tensor: # 连接状态和动作 x = torch.cat([state, action], dim=1) x = F.relu(self.layer1(x)) x = F.relu(self.layer2(x)) q_value = self.layer3(x) return q_value
上述网络定义了DDPG的核心组件。演员网络学习"选择什么动作",评论家网络学习"这些动作的价值评估"。
完整实现还需要经验回放缓冲区(类似DQN)和目标网络复制机制:
# 回放缓冲区(概念 - 使用deque或list) # 目标网络(概念 - 创建演员/评论家的副本) target_actor = ActorNetworkDDPG(...) target_critic = CriticNetworkDDPG(...) target_actor.load_state_dict(actor.state_dict()) # 初始化 target_critic.load_state_dict(critic.state_dict())
DDPG的核心更新逻辑涉及计算演员和评论家网络的损失函数,并对目标网络实施软更新:
# --- DDPG更新逻辑概述 --- # (假设优化器已定义: actor_optimizer, critic_optimizer) # (假设tau: 软更新率, gamma: 折扣因子已定义) # 1. 从replay_buffer采样批次: states, actions, rewards, next_states, dones # --- 评论家更新 --- # 从目标演员获取下一动作: next_actions = target_actor(next_states) # 从目标评论家获取目标Q值: target_q = target_critic(next_states, next_actions) # 计算TD目标: td_target = rewards + gamma * (1 - dones) * target_q # 获取当前Q值估计: current_q = critic(states, actions) # 计算评论家损失(MSE): critic_loss = F.mse_loss(current_q, td_target.detach()) # 更新评论家: critic_optimizer.zero_grad() critic_loss.backward() critic_optimizer.step() # --- 演员更新 --- # 从主演员获取当前状态的动作: actor_actions = actor(states) # 计算演员损失(主评论家的负Q值): actor_loss = -critic(states, actor_actions).mean() # 更新演员: actor_optimizer.zero_grad() actor_loss.backward() actor_optimizer.step() # --- 软更新目标网络 --- soft_update(target_critic, critic, tau) soft_update(target_actor, actor, tau)
这一实现框架展示了DDPG如何结合离策略学习、目标网络和双网络架构,实现连续动作空间中的有效强化学习。
实际应用中,智能体与环境交互时需要为演员网络输出动作添加适当噪声以促进探索。
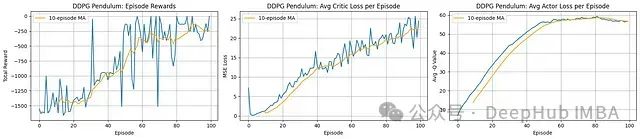
奖励进展: 智能体展现出明确的学习过程。每回合总奖励(左图)从极低水平(约-1500)开始稳步提升,移动平均线在约100回合处达到-250左右的水平。这表明在控制钟摆以最小化成本函数方面取得了显著进步。尽管性能曲线存在波动,但整体呈现明显的正向趋势。
评论家学习: 平均评论家损失(中图)在整个训练过程中呈现稳步增长趋势。这一现象在直觉上可能令人困惑,但在DDPG框架中,随着演员性能提升并探索到更高价值状态,目标Q值也相应增加。评论家网络不断适应这些演化的更高价值目标,因此损失增加实际上可能与学习成功同步发生,反映了价值函数适应过程中规模/复杂度的增加。
演员学习: 平均演员"损失"(右图,标记为Avg -Q Value,实际表示演员实现的平均Q值)呈现明显的上升趋势,与奖励进展高度相关。这表明演员成功学习选择评论家评估为高价值(低成本)的动作,推动整体性能提升。图表末端的平缓趋势暗示学习可能正在趋于收敛。
DDPG算法成功地学习了钟摆控制任务,在约100回合的训练过程中显著提高了累积奖励。演员网络(负责选择最优动作)和评论家网络(负责评估状态-动作价值)均展现出有效的学习特征,尽管评论家损失增加是这类算法中常见的现象,反映了价值函数适应过程的复杂性。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









