







来源:专知
本文约1000字,建议阅读5分钟本文提出了一种新颖的方法——偏好优化(Preference Optimization),通过统计比较建模将传统的定量奖励信号转化为定性的偏好信号,强调在采样解之间的相对优劣。
强化学习(Reinforcement Learning, RL)已成为神经组合优化领域的一项强大工具,使模型能够在无需专家知识的前提下学习启发式策略以求解复杂问题。尽管取得了显著进展,现有的强化学习方法仍面临诸多挑战,如奖励信号逐渐减弱、在庞大的组合动作空间中探索效率低下,最终导致整体性能受限。
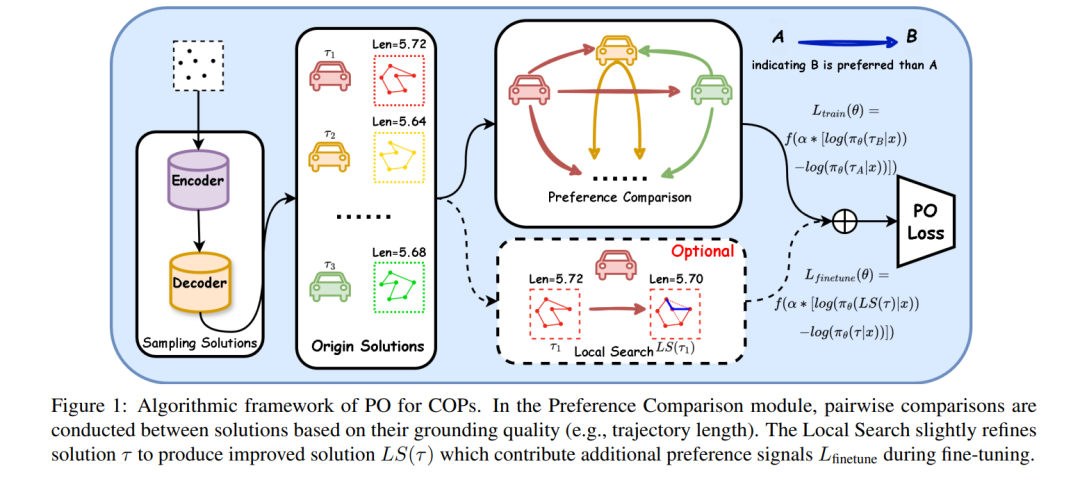
为此,本文提出了一种新颖的方法——偏好优化(Preference Optimization),通过统计比较建模将传统的定量奖励信号转化为定性的偏好信号,强调在采样解之间的相对优劣。具体而言,我们通过将奖励函数重参数化为策略形式,并引入偏好建模,构建了一个熵正则化的强化学习目标函数,该目标可使策略直接对齐于偏好,同时规避了难以处理的计算过程。
此外,我们将局部搜索技术集成到策略微调过程中,而非作为后处理步骤,用于生成高质量的偏好对,从而帮助策略跳出局部最优解。
在多个经典基准任务上(如旅行商问题 TSP、有容量限制的车辆路径问题 CVRP,以及柔性流水车间调度问题 FFSP)进行的实证研究表明,所提出的方法在收敛效率和解质量方面均显著优于现有的强化学习算法。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 7193
7193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









