







欢迎来到@一夜看尽长安花 博客,您的点赞和收藏是我持续发文的动力
对于文章中出现的任何错误请大家批评指出,一定及时修改。有任何想要讨论的问题可联系我:3329759426@qq.com 。发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。

专栏:
文章概述:对mysql的 SQL函数种类的详细介绍和对应的习题&常见问题的解答以及注意点
关键词:Mysql SQL函数
本文目录:
-
SQL函数
1. 单行函数
单行函数仅对单个行进行运算,并且每行返回一个结果。
常见的函数类型:
字符
数字
日期
转换
通用

2. 多行函数
多行函数能够操纵成组的行,每个行组给出一个结果,这些函数也被称为组函数。
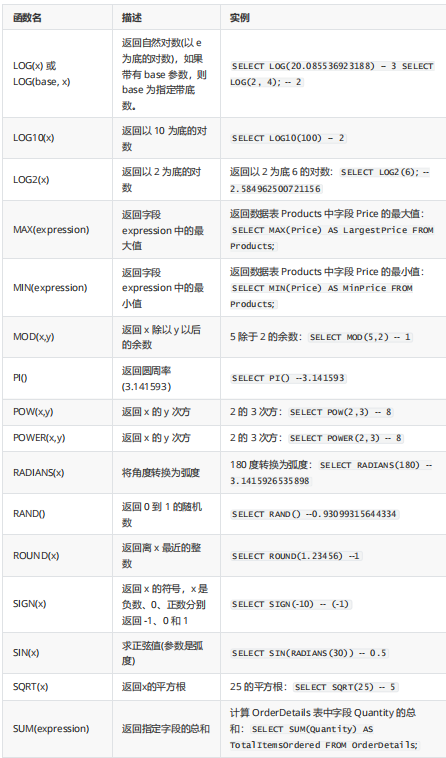
3.字符函数
1.大小写处理函数
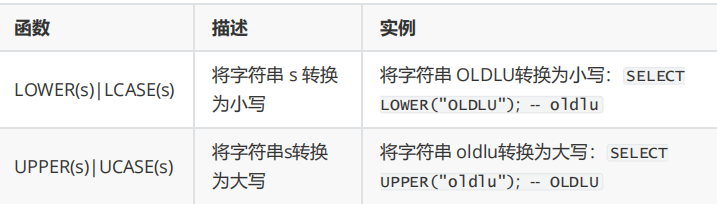
在mysql中用 select 调用函数 在oracle中不一样
#显示雇员Davies的雇员号、姓名和部门号,将姓名转换为大写。
select employee_id,UPPER(last_name),department_id from employees where last_name
='davies';2.字符处理函数
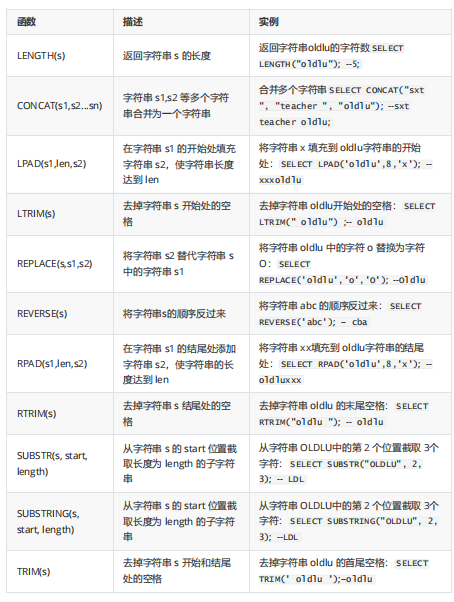
1.length
select length ("oldlu") ;2.concat
select concat ("a" , "b" ,"c" ); select concat (last_name ,first_name ) from employees;3.lpad | rpad
#左填填后长度为8
select lpad ("oldlu" , 8,"*");#右填填后长度为8
select rpad ("oldlu" , 8,"*");4.ltrim | rtrim |trim
5.replace ('oldlu','o','O');
6.reverse
7.substr
#从第二个字符( 注意不同于数组索引)开始,取3个 )
SELECT SUBSTR("OLDLU", 2, 3);8.substring
#显示所有工作岗位名称从第4个字符位置开始(截),包含字符串REP的雇员的ID信息,将雇员的姓和名连接显示在一起,还显示雇员名的的长度,以及名字中字母a的位置(是否有a)。
SELECT employee_id , CONCAT(last_name,first_name) NAME,
job_id, LENGTH(last_name), INSTR(last_name,'a') "Contains 'a'?" FROM employees
WHERE SUBSTR(job_id,4)='REP'; 4.数字函数
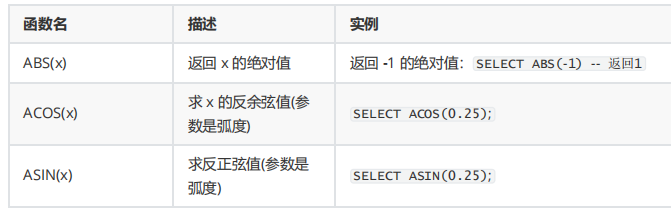
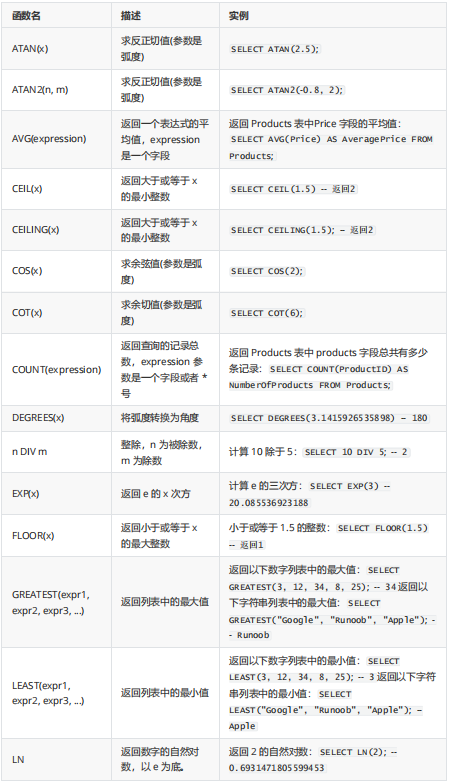

1.ROUND(column|expression, n) 函数
ROUND 函数四舍五入列、表达式或者 n 位小数的值。如果第二个参数是 0 或者缺少,值被四舍五入为整数。如果第二个参数是 2值被四舍五入为两位小数。如果第二个参数是–2,值被四舍五入到小数点左边两位。
SELECT ROUND(45.923,2), ROUND(45.923,0),ROUND(45.923,-1);2.TRUNCATE(column|expression,n) 函数
TRUNCATE函数的作用类似于 ROUND 函数。如果第二个参数是 0 或者缺少,值被截断为整数。如果第二个参数是 2,值被截断为两位小数。如果第二个参数是–2,值被截断到小数点左边两位。与 ROUND最大的区别是不会进行四舍五入。
SELECT TRUNCATE(45.923,2);3.使用MOD(m,n) 函数
MOD 函数找出m 除以n的余数。
#所有job_id是SA_REP的雇员的名字,薪水以及薪水被5000除后的余数。
SELECT last_name, salary,MOD(salary,5000) FROM employees WHERE job_id='SA_REP'; 5.日期函数
在MySQL中允许直接使用字符串表示日期,但是要求字符串的日期格式必须为:‘YYYY-MM-DD HH:MI:SS’ 或者‘YYYY/MM/DD HH:MI:SS’;


#向employees表中添加一条数据,雇员ID:300,名字:kevin,email:kevin@sxt.cn,入职时间:2049-5-1 8:30:30,工作部门:‘IT_PROG’。
insert into employees(EMPLOYEE_ID,last_name,email,HIRE_DATE,JOB_ID)
values(300,'kevin','kevin@sxt.cn','2049-5-1 8:30:30','IT_PROG'); 受影响的行: 1 (说明已经执行了)
时间: 0.012s
问题:
[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'information_schema.PROFILING.SEQ' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
解析:
这算是一个警告吧,讲的是分组的一个问题,但是不影响的
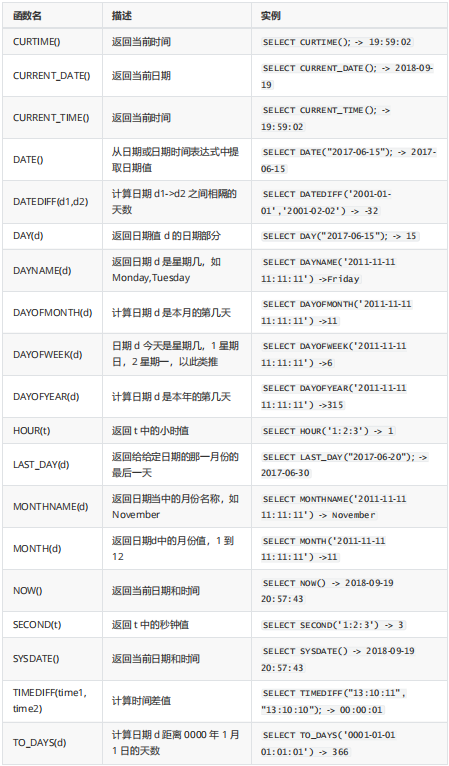
6.转换函数
1.隐式数据类型转换
隐式数据类型转换是指MySQL服务器能够自动地进行类型转换。如:可以将标准格式的字串日期自动转换为日期类型。
MySQL字符串日期格式为:‘YYYY-MM-DD HH:MI:SS’或‘YYYY/MM/DD HH:MI:SS’;
2.显示数据类型转换
显示数据类型转换是指需要依赖转换函数来完成相关类型的转换。
DATE_FORMAT(date,format) 将日期转换成字符串;
STR_TO_DATE(str,format) 将字符串转换成日期;
#向employees表中添加一条数据,雇员ID:400,名字:oldlu,email:oldlu@sxt.cn,入职时间:2049年5月5日,工作部门:‘IT_PROG’。
insert into employees(EMPLOYEE_ID,last_name,email,HIRE_DATE,JOB_ID)
values(400,'oldlu','oldlu@sxt.cn', STR_TO_DATE('2049年5月5日','%Y年%m月%d
日'),'IT_PROG'); insert into employees(EMPLOYEE_ID,last_name,email,HIRE_DATE,JOB_ID)
values(400,'oldlu','oldlu@sxt.cn', STR_TO_DATE('08时24分30秒','%H 时%i分%s
秒'),'IT_PROG');问题:
IErr) 1055 Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated columninformation schema.PROFILING.SEQ' which is not functionally dependent on columns in GROUP BY clause: this isincompatible with sgl mode=only full group by
版本差异化导致的,修改了一些mysql内置的内容
问题解决:
#先输入
SET @@SESSION.sql_mode='ALLOW_INVALID_DATES';#再重输入即可
insert into employees(EMPLOYEE_ID,last_name,email,HIRE_DATE,JOB_ID)
values(400,'oldlu','oldlu@sxt.cn', STR_TO_DATE('08时24分30秒','%H 时%i分%s
秒'),'IT_PROG'); #查询employees表中雇员名字为King的雇员的入职日期,要求显示格式为yyyy年MM月dd日。
select DATE_FORMAT(hire_date,'%Y年%m月%d日') from employees where last_name=
'King';7.通用函数
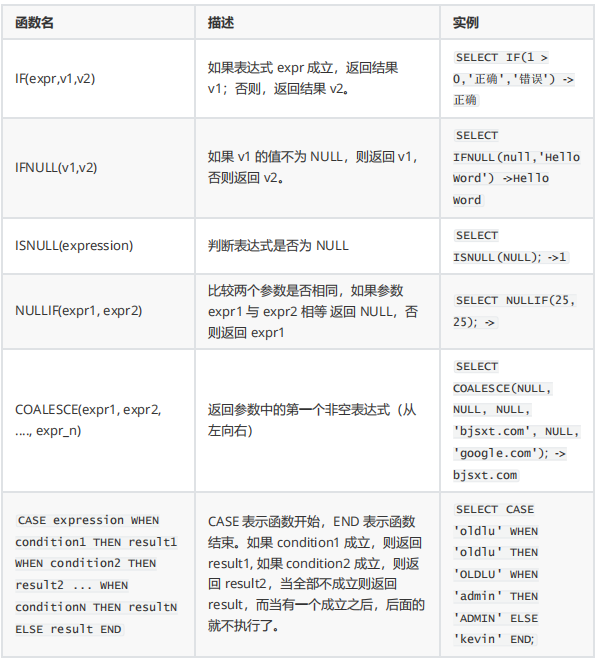
练习:
1、
#查询部门编号是50或者80的员工信息,包含他们的名字、薪水、佣金。在income列中,如果有佣金则显示‘SAL+COMM’,无佣金则显示'SAL'。
SELECT last_name, salary, commission_pct,if(ISNULL(commission_pct),
'SAL','SAL+COMM') income
FROM employees
WHERE department_id IN(50,80); 2、
#计算雇员的年报酬,你需要用12乘以月薪,再加上它的佣金(等于年薪乘以佣金百分比)
SELECT last_name, salary, IFNULL (commission_pct,0),(salary*12)+
(salary*12* IFNULL(commission_pct,0))AN_SAL
FROM employees; 3、
# 查询员工表,显示他们的名字、名字的长度该列名为expr1,姓氏、姓氏的长度该列名为expr2。在
SELECT first_name, LENGTH(first_name)"expr1",
last_name, LENGTH(last_name)"expr2", NULLIF(LENGTH(first_name),
LENGTH(last_name))result
FROM employees; result列中,如果名字与姓氏的长度相同则显示空,如果不相同则显示名字长度。
4、
#查询员工表,显示他们的名字,如果COMMISSION_PCT值是非空,显示它。如COMMISSION_PCT 值是空,则显示SALARY。如果COMMISSION_PCT和SALARY值都是空,那么显示10。在结果中对佣金列升序排序。
SELECT last_name,
COALESCE(commission_pct, salary,10)comm
FROM employees
ORDER BY commission_pct; 5、
#查询员工表,如果JOB_ID是IT_PROG,薪水增加10%;如果JOB_ID是ST_CLERK,薪水增加15%;如果JOB_ID是SA_REP,薪水增加20%。对于所有其他的工作角色,不增加薪水。
SELECT last_name, job_id, salary,
CASE job_id WHEN'IT_PROG' THEN1.10*salary
WHEN 'ST_CLERK' THEN1.15*salary
WHEN 'SA_REP' THEN1.20*salary
ELSE salaryEND"REVISED_SALARY"
FROM employees; - 单行函数练习
1、
#.显示受雇日期在1998年2月20日 和2005年5月1日 之间的雇员的名字、岗位
和受雇日期。按受雇日期顺序排序查询结果。
SELECT
LAST_NAME,JOB_ID,HIRE_DATE
FROM employees
WHERE HIRE_DATE BETWEEN'1998-2-20'AND'2005-5-1'
order by HIRE_DATE; 2、
#显示每一个在2002年受雇的雇员的名字和受雇日期。
select
LAST_NAME,HIRE_DATE
FROM employees
where HIRE_DATE like'2002%' 3、
# 对每一个雇员,显示employee number、last_name、salary和salary增加15%,
并且表示成整数,列标签显示为New Salary。
SELECT
EMPLOYEE_ID,LAST_NAME,SALARY,
ROUND (SALARY*1.15,0)
FROM employees 4、
#写一个查询,显示名字的长度,对所有名字开始字母是J、A或M的雇员。用雇员的last
name排序结果。
SELECT
LAST_NAME,
LENGTH(LAST_NAME)
FROM employees
WHERE LAST_NAMELIKE'J%'
OR
LAST_NAMELIKE'A%'
OR
LAST_NAMELIKE'M%'
ORDER BY LAST_NAME; 5、
#创建一个查询显示所有雇员的last name和salary。将薪水格式化为15个字符长度,用$左填充
SELECT
LAST_NAME,LPAD(SALARY,15,'$')
FROM employees; 6、
#创建一个查询显示雇员的last names和commission (佣金)比率。如果雇员没有佣金,显示“No
Commission”,列标签COMM。
SELECT
LAST_NAME,IFNULL(COMMISSION_PCT,'No Commission')COMM
FROM employees 7、
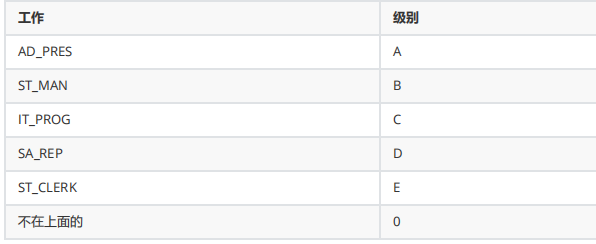
#.写一个查询,按照下面的数据显示所有雇员的基于JOB_ID列值的级别。
SELECTJOB_ID,
CASE JOB_IDWHEN'AD_PRES'THEN'A'
WHEN'ST_MAN'THEN'B'
WHEN'IT_PROG'THEN'C'
WHEN'SA_REP'THEN'D'
WHEN'ST_CLERK'THEN'E'
ELSE0END
FROM employees; 8.聚合连接
聚合函数
聚合函数也称之为多行函数,组函数或分组函数。聚合函数不象单行函数,聚合函数对行的分组进行操作,对每组给出一个结果。如果在查询中没有指定分组,那么聚合函数则将查询到的结果集视为一组。
聚合函数对行的进行分组操作,并给出一个结果值
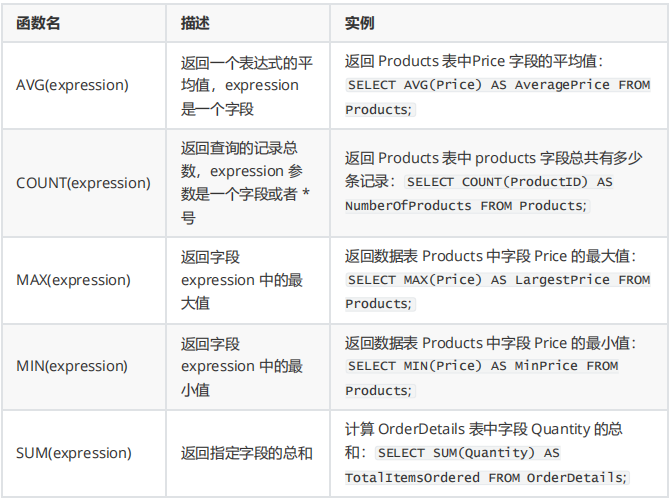
使用聚合函数的原则:
DISTINCT 使得函数只考虑不重复的值;
所有聚合函数忽略空值。为了用一个值代替空值,用 IFNULL 或 COALESCE 函数。
-
AVG函数和SUM函数
arg 函数
对分组数据做平均值运算
arg:参数类型只能是数字类型。 (不是数字类型的结果都是0)
#计算员工表中工作编号含有REP的工作岗位的平均薪水与薪水总和。
SELECT AVG(salary),SUM(salary)
FROM employees
WHERE job_id LIKE'%REP%'; -
min 和 max 函数
arg:参数类型可以是字符(首字母的顺序,a最小)、数字、 日期。
#查询员工表中入职时间最短与最长的员工,并显示他们的入职时间。
SELECT MIN(hire_date),MAX(hire_date) FROM employees; -
count函数
返回分组中的总行数。
COUNT函数有三种格式:
- COUNT(*):返回表中满足SELECT语句的所有列的行数,包括重复行,包括有空值列(因为它是对一整条数据,不是具体一栏)
- 的行。
- COUNT(expr):返回在列中的由expr指定的非空值的数。
- COUNT(DISTINCT expr):返回在列中的由expr指定的唯一的非空值的数。
#显示员工表中部门编号是80中有佣金的雇员人数。
SELECT COUNT(commission_pct) FROM employees WHERE department_id=80; #显示员工表中的部门数
SELECT COUNT(DISTINCTdepartment_id) FROM employees;
-
组函数和 Null 值
在组函数中使用 IFNULL 函数
#有佣金的员工的平均值
SELECT AVG(commission_pct) FROM employees; #计算所有员工的平均值
SELECT AVG(IFNULL(commission_pct,0)) FROM employees;
-
数据分组
1.创建数据组
在没有进行数据分组之前,所有聚合函数是将结果集作为一个大的信息组进行处理。但是,有时,则需要将表的信息划分为较小的组,可以用GROUP BY子句实现。
#求每个部门平均薪水
SET @@SESSION.sql_mode='ALLOW_INVALID_DATES';
SELECT DEPARTMENT_ID ,AVG(IFNULL(salary,0)) FROM employees GROUP BY DEPARTMENT_ID; 版本问题
2.GROUP BY

- 使用WHERE子句,可以在划分行成组以前过滤行。
- 如果有WHERE子句,那么GROUP BY子句必须在WHERE的子句后面。
- 在GROUP BY子句中必须包含列。
#计算每个部门的不同工作岗位的员工总数。
SELECT e.DEPARTMENT_ID, e.JOB_ID,COUNT(*)
FROM employees e
GROUP BY e.DEPARTMENT_ID,e.JOB_ID; 注意:在mysql中不能对聚合函数做嵌套使用(即不能在count函数里套sum函数)
3.在多列上使用分组
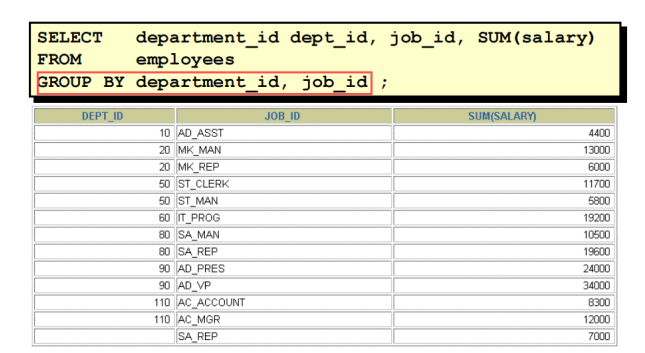
# 相当于求相同部门相同工作的人为一组
在组中分组,可以列出多个 GROUP BY 列返回组和子组的摘要结果。可以用 GROUP BY子句中的列的顺序确定结果的默认排序顺序。下面是图片中的 SELECT 语句中包含一个 GROUP BY 子句时的求值过程:
1.SELECT 子句指定被返回的列:
− 部门号在 EMPLOYEES 表中
− Job ID 在 EMPLOYEES 表中
− 在 GROUP BY 子句中指定的组中所有薪水的合计
2.FROM 子句指定数据库必须访问的表:EMPLOYEES 表。
3.GROUP BY 子句指定你怎样分组行:
− 首先,用部门号分组行。
− 第二,在部门号的分组中再用 job ID 分组行
#计算每个部门的不同工作岗位的员工总数。
SELECT e.DEPARTMENT_ID, e.JOB_ID,COUNT(*) FROM employees e
GROUP BY e.DEPARTMENT_ID,e.JOB_ID; 4.约束分组结果(HAVING)
HAVING 子句
HAVING 子句是对查询出结果集分组后的结果进行过滤。
#用WHERE子句约束选择的行,用HAVING子句约束组。为了找到每个部门中的最高薪水,而且只显示最高薪水大于$10,000的那些部门,
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000; 1.用部门号分组,在每个部门中找最大薪水。
2.返回那些有最高薪水大于$10,000的雇员的部门

#显示那些合计薪水超过13,000的每个工作岗位的合计薪水。排除那些JOB_ID中含有REP的工作岗位,并且用合计月薪排序列表。
SELECT job_id,SUM(salary)PAYROLL
FROM employees
WHERE job_idNOT LIKE'%REP%'
GROUP BY job_id
HAVING SUM(salary)>13000
ORDER BY SUM(salary); -
聚合函数与数据分组练习
1、
#显示所有雇员的最高、最低、合计和平均薪水,列标签分别为:Max、Min、Sum和Avg。四舍五入结果为最近的整数。(聚合函数嵌套在单行函数是可以的)
SELECT ROUND(MAX(e.SALARY)) max,ROUND(MIN(e.SALARY)) min , ROUND(SUM(e.SALARY)) sum,
ROUND(AVG(e.SALARY)) avg
FROM employees e; 2、
# 写一个查询显示每一工作岗位的人数。
SELECT
e.JOB_ID, COUNT(*)
FROM employees e
GROUP BY e.JOB_ID; 3、
#.确定经理人数,不需要列出他们,列标签是Number of Managers。提示:用MANAGER_ID列决定经理号。
SELECT
COUNT(DISTINCTe.MANAGER_ID)
FROM employees e; 4、
#.写一个查询显示最高和最低薪水之间的差。
SELECT
MAX(e.SALARY)-MIN(e.SALARY)
FROM employees e; 5、
#显示经理号和经理(分组)付给雇员的最低薪水。(where )排除那些经理未知的人。(having)排除最低薪水小于等于$6,000的组。按薪水降序排序输出。(order)
SELECT e.MANAGER_ID,MIN(e.SALARY)
FROM employees e
WHERE e.MANAGER_ID is notnull(要的条件)
GROUP BY e.MANAGER_ID
HAVING min(e.SALARY)>6000 (要的条件)
ORDER BY min(e.SALARY) desc; 6、
#写一个查询显示每个部门的名字、地点、人数和部门中所有雇员的平均薪水。(多表连接)四舍五入薪水到两位小数
SELECT d.DEPARTMENT_NAME,d.LOCATION_ID, COUNT(*),ROUND(AVG(e.SALARY))
FROM employees e,departments d
where e.DEPARTMENT_ID=d.DEPARTMENT_ID
GROUP BY d.DEPARTMENT_NAME,d.LOCATION_ID;















 4037
4037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









