







1.1进程模型
进程就是一个正在运行的程序,它由程序计数器、寄存器、当前变量的值组成。在单CPU环境下,操作系统利用了多道程序设计,来使得进程在一个时间片内快速的进行切换,进而达到了并行的效果,这只是一种模拟的“并发”,因而称之为并行。
问题1:物理寄存器只有固定的几个,程序计数器也是每个CPU人手一个,根本没法做到每个进程人手一个程序计数器,一套寄存器。因而给出的解决方案是:把一套寄存器,一个程序计数器搞进进程控制块里面,等到调度到该进程时候,把对应的寄存器,程序计数器之类的东西复制进硬件上,等到要切换出去时候,再把它复制进进程控制块。
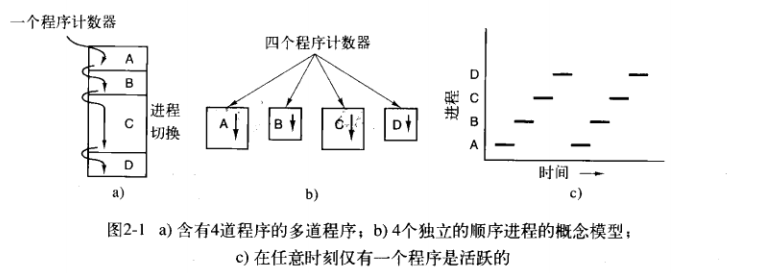
如上图所示,一个程序计数器对应多个程序计数器。。。。
1.2进程的创建
什么时候会创建进程??
A.系统初始化,比如windows系统初始化过程会启动大量的设置了启动项的程序,在cmd下打开msconfig就能看到对应的开机启动项。而Linux则开机时候会启动大量的守护进程,比如邮件守护进程之类.这些守护进程往往调度优先级比较低,却十分重要,默默方便着用户
B.执行相应的系统调用,比如fork..
C.用户请求创建一个新进程,比如打开一个新的窗口
D.一个批处理作业的初始化
创建进程的API?
windows下创建进程的API为CreateProcess,大概为10个参数左右,而linux下创建进程的API为fork.参数却是只能有1个,原因是windows把fork+exec集成成一个系统调用,认为windows创建的进程是相互独立的,不具有父子关系。
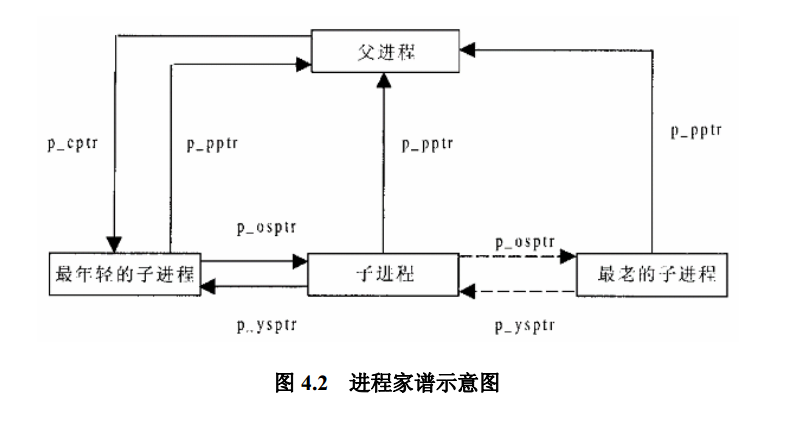
进程之间的关系由p_osptr、p_cptr、p_ysptr、p_pptr、p_osptr,p_opptr五个部分组成,p_opptr、p_ysptr分别指向兄、弟进程,p_cptr指向最年轻的刚刚产生的子进程,p_opptr、p_pptr指向父进程。
而windows下的创建进程创建出来则是没有这种结构,windows只是CreateProcess完成之后返回一个句柄。呃,,,,其实最准确说法是windows也有进程树,只是windows的各种细节一般不会暴露给用户,因为他们假定windows用户都是小白,他们不需要了解这些玩意
1.3进程的终止
进程的终止犹如一个人的死亡一样,无非以下两种死亡方式
A.自愿/正常死亡(正常退出、出错退出==》老死,病死)
B.非自愿/非正常死亡(严重错误、被其他进程杀死==》进监狱枪毙,直接被人打死)
这里要举例具体说说出错退出和严重错误的区别:
前者举例:打开一个文件发现打开失败,然后程序员通过一个if语句判断出来,调动exit函数自愿退出。
后者举例:除以一个为0的数字,*NULL之类的操作被执行,有的系统就会给进程发送相应的信号,如果这个进程不设置自行的信号处理函数,则会直接终止进程。。。
1.4进程的层次结构关系
往上看吧,少年。前面已经讲了层次结构的概念了。如今我们来分析一下它有什么用吧。
1.5进程的状态
经典的操作系统书上几乎都有下面的三种状态,以及他们之间的转换。
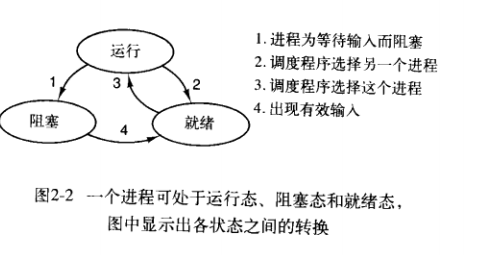
那么我们为什么要提出这个进程模型???因为为了方便程序员的理解,我们能够能够得到类似下面的图,不难看出,操作系统最重要的就是调度程序,所有的进程的启动、终止,中断处理都是隐藏着进程调度程序中。。
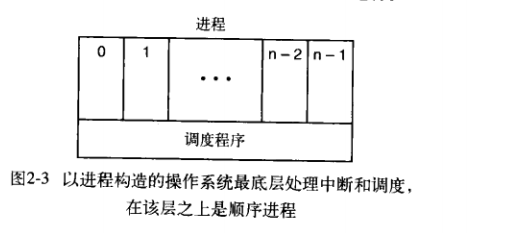
1.6 进程的实现
这时候我们想到了进程模型,想到了之前讲的多道程序切换,却一个CPU只有一套寄存器和一个进程计数器我们的进程偷偷的实现了逻辑逻辑器,偷偷实现了逻辑程序计数器,想到了进程的控制块,我们还想到了操作系统书上上的一句话:进程控制块是进程存在的唯一标识。我们好奇着为什么这样说?因而我们必须了解进程的实现。
为了实现进程模型,操作系统搞了一个叫做进程表的玩意,里面存放在所有进程多个进程控制块。。。
←_←如果你们有人知道linux2.4版本的进程是如何存储的,就会知道一个叫做GDT的表,一个叫LDT的表,这个表有8196个格子,一个进程控制块占用2个格子,所有我们能得出结论,2.4版本linux内核最多同时运行4096个进程,记住前提2.4版本!
进程控制块里存放什么呢?一般来说包含以下这些。。。

呃,应该给你们看看Linux3.0.6版本的task_struct结构体,也就是传说中的PCB。。。
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack; //stack should points to a threadinfo struct
atomic_t usage; //有几个进程正在使用该结构
unsigned int flags; /* per process flags, defined below *///反应进程状态的信息,但不是运行状态
unsigned int ptrace;
#ifdef CONFIG_SMP
struct task_struct *wake_entry;
int on_cpu; //在哪个CPU上运行
#endif
int on_rq; //on_rq denotes whether the entity is currently scheduled on a run queue or not.
int prio, static_prio, normal_prio; //静态优先级,动态优先级
/*
the task structure employs three elements to denote the priority of a process: prio
and normal_prio indicate the dynamic priorities, static_prio the static priority of a process.
The static priority is the priority assigned to the process when it was started. It can be modified
with the nice and sched_setscheduler system calls, but remains otherwise constant during the
process’ run time.
normal_priority denotes a priority that is computed based on the static priority and the
scheduling policy of the process. Identical static priorities will therefore result in different
normal priorities depending on whether a process is a regular or a real-time process. When a
process forks, the child process will inherit the normal priority.
However, the priority considered by the scheduler is kept in prio. A third element is required
because situations can arise in which the kernel needs to temporarily boost the priority of a pro-
cess. Since these changes are not permanent, the static and normal priorities are unaffected by
this.
*/
unsigned int rt_priority; //实时任务的优先级
const struct sched_class *sched_class; //与调度相关的函数
struct sched_entity se; //调度实体
struct sched_rt_entity rt; //实时任务调度实体
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers; //与抢占有关的
#endif
/*
* fpu_counter contains the number of consecutive context switches
* that the FPU is used. If this is over a threshold, the lazy fpu
* saving becomes unlazy to save the trap. This is an unsigned char
* so that after 256 times the counter wraps and the behavior turns
* lazy again; this to deal with bursty apps that only use FPU for
* a short time
*/
unsigned char fpu_counter;
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy; //调度策略
cpumask_t cpus_allowed;//多核体系结构中管理CPU的位图:Cpumasks provide a bitmap suitable
//for representing the set of CPU's in a system, one bit position per CPU number.
// In general, only nr_cpu_ids (<= NR_CPUS) bits are valid.
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting; //RCU是一种新型的锁机制可以参考博文:http://blog.csdn.net/sunnybeike/article/details/6866473。
char rcu_read_unlock_special;
#if defined(CONFIG_RCU_BOOST) && defined(CONFIG_TREE_PREEMPT_RCU)
int rcu_boosted;
#endif /* #if defined(CONFIG_RCU_BOOST) && defined(CONFIG_TREE_PREEMPT_RCU) */
struct list_head rcu_node_entry;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TREE_PREEMPT_RCU
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex;
#endif /* #ifdef CONFIG_RCU_BOOST */
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info; //调度相关的信息,如在CPU上运行的时间/在队列中等待的时间等。
#endif
struct list_head tasks; //任务队列
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
#endif
struct mm_struct *mm, *active_mm; //mm是进程的内存管理信息
/*关于mm和active_mm
lazy TLB应该是指在切换进程过程中如果下一个执行进程不会访问用户空间,就没有必要flush TLB;
kernel thread运行在内核空间,它的mm_struct指针mm是0,它不会访问用户空间。 if (unlikely(!mm))是判断切换到的新进程是否是kernel thread,
如果是,那么由于内核要求所有进程都需要一个mm_struct结构,所以需要把被切换出去的进程(oldmm)的mm_struct借过来存储在
active_mm( next->active_mm = oldmm;),这样就产生了一个anomymous user, atomic_inc(&oldmm->mm_count)就用于增加被切换进程的mm_count,
然后就利用 enter_lazy_tlb标志进入lazeTLB模式(MP),对于UP来说就这个函数不需要任何动作;
if (unlikely(!prev->mm))这句话是判断被切换出去的进程是不是kernel thread,如果是的话就要释放它前面借来的mm_struct。
而且如果切换到的进程与被切换的kernel thread的page table相同,那么就要flush与这些page table 相关的entry了。
注意这里的连个if都是针对mm_struct结构的mm指针进行判断,而设置要切换到的mm_struct用的是active_mm;
对于MP来说,假如某个CPU#1发出需要flushTLB的要求,对于其它的CPU来说如果该CPU执行kernel thread,那么由CPU设置其进入lazyTLB模式,
不需要flush TLB,当从lazyTLB模式退出的时候,如果切换到的下个进程需要不同的PageTable,那此时再flush TLB;如果该CPU运行的是普通的进程和#1相同,
它就要立即flush TLB了
大多数情况下mm和active_mm中的内容是一样的;但是在这种情况下是不一致的,就是创建的进程是内核线程的时候,active_mm = oldmm(之前进程的mm), mm = NULL,
(具体的请参考深入Linux内核的78页。)
参考文章:http://www.linuxsir.org/bbs/thread166288.html
*/
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat; //RSS is the total memory actually held in RAM for a process.
//请参考博文:http://blog.csdn.net/sunnybeike/article/details/6867112
#endif
/* task state */
int exit_state; //进程退出时的状态
int exit_code, exit_signal; //进程退出时发出的信号
int pdeath_signal; /* The signal sent when the parent dies */
unsigned int group_stop; /* GROUP_STOP_*, siglock protected */
/* ??? */
unsigned int personality; //由于Unix有许多不同的版本和变种,应用程序也有了适用范围。
//所以根据执行程序的不同,每个进程都有其个性,在personality.h文件中有相应的宏定义
unsigned did_exec:1; //根据POSIX程序设计的标准,did_exec是用来表示当前进程是在执行原来的代码还是在执行由execve调度的新的代码。
unsigned in_execve:1; /* Tell the LSMs that the process is doing an
* execve */
unsigned in_iowait:1;
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
pid_t pid; //进程ID
pid_t tgid; //线程组ID
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/*
* ptraced is the list of tasks this task is using ptrace on.
* This includes both natural children and PTRACE_ATTACH targets.
* p->ptrace_entry is p's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* for vfork() */
/*
If the vfork mechanism was used (the kernel recognizes this by the fact that the CLONE_VFORK
flag is set), the completions mechanism of the child process must be enabled. The vfork_done
element of the child process task structure is used for this purpose.
*/
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */c
putime_t utime, stime, utimescaled, stimescaled; // utime是进程用户态耗费的时间,stime是用户内核态耗费的时间。
//而后边的两个值应该是不同单位的时间cputime_t gtime; //??
#ifndef CONFIG_VIRT_CPU_ACCOUNTING
cputime_t prev_utime, prev_stime;
#endif
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires; //进程到期的时间?
struct list_head cpu_timers[3]; //???/* process credentials */ //请参考cred结构定义文件的注释说明
const struct cred __rcu *real_cred; /* objective and real subjective task * credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task * credentials (COW) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
char comm[TASK_COMM_LEN]; /* executable name excluding path - access with [gs]et_task_comm (which lock it with task_lock()) - initialized normally by setup_new_exec */
/* file system info */
int link_count, total_link_count; //硬连接的数量?
#ifdef CONFIG_SYSVIPC/* ipc stuff */ //进程间通信相关的东西
struct sysv_sem sysvsem; //
#endif
#ifdef CONFIG_DETECT_HUNG_TASK/* hung task detection */
unsigned long last_switch_count;
#endif/* CPU-specific state of this task */
struct thread_struct thread; /*因为task_stcut是与硬件体系结构无关的,因此用thread_struct这个结构来包容不同的体系结构*/
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespaces */ //关于命名空间深入讨论,参考深入Professional Linux® Kernel Architecture 2.3.2节
// 或者http://book.51cto.com/art/201005/200881.htm
struct nsproxy *nsproxy;/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending; //表示进程收到了信号但是尚未处理。
unsigned long sas_ss_sp;size_t sas_ss_size;
/*Although signal handling takes place in the kernel, the installed signal handlers run in usermode — otherwise,
it would be very easy to introduce malicious or faulty code into the kernel andundermine the system security mechanisms.
Generally, signal handlers use the user mode stack ofthe process in question.
However, POSIX mandates the option of running signal handlers on a stackset up specifically for this purpose (using the
sigaltstack system call). The address and size of this additional stack (which must be explicitly allocated by the
user application) are held in sas_ss_sp andsas_ss_size, respectively. (Professional Linux® Kernel Architecture Page384)*/
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
struct audit_context *audit_context; //请参看 Professional Linux® Kernel Architecture Page1100
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid;
unsigned int sessionid;
#endif
seccomp_t seccomp;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, * mempolicy */
spinlock_t alloc_lock;
#ifdef CONFIG_GENERIC_HARDIRQS/* IRQ handler threads */
struct irqaction *irqaction;#endif/* Protection of the PI data structures: */ //PI --> Priority Inheritanceraw_spinlock_t pi_lock;
#ifdef CONFIG_RT_MUTEXES //RT--> RealTime Task 实时任务/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES/* mutex deadlock detection */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
unsigned long hardirq_enable_ip;
unsigned long hardirq_disable_ip;
unsigned int hardirq_enable_event;
unsigned int hardirq_disable_event;
int hardirqs_enabled;
int hardirq_context;
unsigned long softirq_disable_ip;
unsigned long softirq_enable_ip;
unsigned int softirq_disable_event;
unsigned int softirq_enable_event;
int softirqs_enabled;
int softirq_context;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth; //锁的深度
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
gfp_t lockdep_reclaim_gfp;
#endif
/* journalling filesystem info */
void *journal_info; //文件系统日志信息
/* stacked block device info */
struct bio_list *bio_list; //块IO设备表
#ifdef CONFIG_BLOCK
/* stack plugging */
struct blk_plug *plug;
#endif
/* VM state */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message;
siginfo_t *last_siginfo;
/* For ptrace use. */
struct task_io_accounting ioac; //a structure which is used for recording a single task's IO statistics.
#if defined(CONFIG_TASK_XACCT)
u64 acct_rss_mem1;
/* accumulated rss usage */
u64 acct_vm_mem1;
/* accumulated virtual memory usage */
cputime_t acct_timexpd;
/* stime + utime since last update */
#endif
#ifdef CONFIG_CPUSETS
nodemask_t mems_allowed;
/* Protected by alloc_lock */
int mems_allowed_change_disable;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endifstruct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy;
/* Protected by alloc_lock */
short il_next;
short pref_node_fork;
#endifatomic_t fs_excl; /* holding fs exclusive resources *///是否允许进程独占文件系统。为0表示否。
struct rcu_head rcu;/* * cache last used pipe for splice */
struct pipe_inode_info *splice_pipe;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
#endif
struct prop_local_single dirties;
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/* * time slack values; these are used to round up poll() and * select() etc timeout values.
These are in nanoseconds. */
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
struct list_head *scm_work_list;
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack */
int curr_ret_stack;/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
/* * Number of functions that haven't been traced * because of depth overrun. */
atomic_t trace_overrun;
/* Pause for the tracing */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* state flags for use by tracers */
unsigned long trace;/* bitmask and counter of trace recursion */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
/* memcg uses this to do batch job */
struct memcg_batch_info {int do_batch; /* incremented when batch uncharge started */
struct mem_cgroup *memcg; /* target memcg of uncharge */
unsigned long nr_pages; /* uncharged usage */
unsigned long memsw_nr_pages; /* uncharged mem+swap usage */
} memcg_batch;
#endif
#ifdef CONFIG_HAVE_HW_BREAKPOINT
atomic_t ptrace_bp_refcnt;
#endif
};在了解到进程模型以后,我们可以在了解到进程模型以后,我们可以解释好多东西,比如计算机如何用一个CPU来模拟多个进程“同时”运行,比如当一个程序发生了I/O时候究竟发生了什么事情,再比如说一个系统调用究竟发生什么事情?其实他们最底层都是由一个叫做中断的技术来实现的。
比如说如何产生多个进程同时运行的错觉,这就是依赖于名字叫做时钟中断的一种中断技术来实现,再比如说I/O底层是如何搞的,这就依赖于一个名字叫做I/O中断的中断技术来实现的。再比如说系统调用底层就是80号中断技术来实现。看吧,都是中断。那么中断究竟做了什么呢?????好吧,我们以I/O中断为例说明吧。。。。

这就是中断发生的过程,呃,说的有点抽象,这样吧。我们还是假设在银行排队做业务吧,每个用户最多只能有5分钟的业务处理事件。用户=》进程,窗口=》CPU。现在一个正在窗口处理的业务的客户(进程)发生了一个意外,他忘了带银行卡来了(I/O中断),或者说属于他的五分钟处理事件到了(时钟中断)。。。。这时候,这个客人默默拿出一张纸,把当前处理到哪里记录下来(程序计数器),再把一些跟这次处理有关的申请书之类带走(寄存器)。然后默默告诉前台自己要干嘛去(中断向量),最后银行前台批准好了,这个客人就默默的离开了。然后辛苦的前台发挥了蛋疼的决定,帮刚刚的客人拿了数据回来(I/O),然后再调度一个调度程序,让下一个进程执行。呃,当然,下一个是不是刚才的客人的就不好说了。。。。
所以说I/O、系统调用不是光荣的,它把属于这个进程的时间片全部放弃了才能换来一次I/O,系统调用的机会,而且下次不一定轮到它执行,漫长的排队谁也不知道下次到他执行是什么时候。
1.7多道程序设计
如今我们从数学上分析银行排队模型,假设我们有n个人排队,其中每个人发生I/O的概率为p,那么我们这个模型的CPU的利用率就是
这个公式的好处就是告诉我们CPU利用率和I/O等待之间的关系,或者说我们可以根据I/O等待,分析要不要加大内存,然后提高CPU的利用率。最后看看CPU提高的吞吐量。考虑要不要加内存
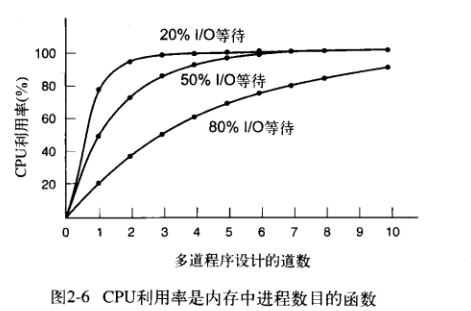
呃,给出一个例子吧。
好了,字数也有点多了,,总结一下吧。














 1833
1833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









