







计算机网络五层模型分别负责什么?
注:这道题考的太多了,很多人估计都是直接背的模型,我觉得这样是无法加分的,你也不需要说的特别全,简单说一下+举例子就行了,举例子就是最好的证明:
物理层:负责把两台计算机连起来,然后在计算机之间通过高低电频来传送0,1这样的电信号,比如通过一些电缆线传输比特流。
链路层:链路层涉及到的协议比较多,比如 Mac 地址啊,ARP 等,这一层主要就是负责数据的通信,使各节点之间可以通信,比如通过 MAC 地址唯一识别不同的节点,通过以太网协议定义数据包等。
网络层:网络层负责把一个数据从一个网络传递到另外一个网络,最大的功能就是进行路由决策,比如通过 IP,子网等概念,使数据更好着在不同的局域网中传递。
传输层:传输层的功能就是建立端口到端口的通信,刚才说的网络层的功能则是建立主机到主机的通信,比如通过网络层我们可以把信息从 A 主机传递到 B 主机,但是 B 主机有多个程序,我们具体要发给哪个程序,则是靠传输层的协议来识别,常见协议有 UDP 和 TCP。
应用层:虽然我们收到了传输层传来的数据,可是这些传过来的数据五花八门,有html格式的,有mp4格式的,各种各样,我们用户也看不懂,
因此我们需要指定这些数据的格式规则,收到后才好解读渲染。例如我们最常见的 Http 数据包中,就会指定该数据包是 什么格式的文件了。
当然,你可以说的更详细,只是想我这样差不多了,之后就等着面试官是否要继续提问吧。
IP 地址和 Mac 地址有啥区别?
本系列第一篇文章其实已经讲了 IP 和 MAC 的区别的,简洁来说的话,就是:IP处于网络层,主要用来寻址,如同我们的快递地址,有个地址方便寻找大致的地点,而MAC地址,则用来唯一确认身份,就像我们的身份证。
总的来说,你回答了这个就差不多了,因为 这个代表你真正理解了,但是嘛,如果你还记住的话,再补充下面一些回答也是可以的。
下面是相对详细的一个回答,:
-
IP地址是逻辑地址,而MAC地址是物理地址。
-
IP地址是在网络层使用的地址,用于标识网络上的主机或路由器,MAC地址则是在数据链路层使用的地址,用于标识网络上的网卡或其他物理设备。
-
IP地址是可变的,可以在网络上动态分配或更改,而MAC地址是固定的,通常是出厂时设定的。
-
IP地址是全球唯一的,由互联网号码分配机构(IANA)管理分配,而MAC地址是由设备厂商分配,通常在设备生产时就已经固定。
总之,IP地址和MAC地址都是用来标识设备的地址,但其用途和管理方式不同。在实际应用中,IP地址通常用于网络间通信,而MAC地址用于局域网内部通信
说一说三次握手
**PS:**这个问的太多了,大家要先理解 =》背诵,防止突然忘了也能说个大概。这道题在问的时候,可深可浅,看面试官自己的掌握力度。
当面试官问你为什么需要有三次握手、三次握手的作用、讲讲三次三次握手的时候,我想很多人会这样回答:
首先很多人会先讲下握手的过程:
1、第一次握手:客户端给服务器发送一个 SYN 报文。
2、第二次握手:服务器收到 SYN 报文之后,会应答一个 SYN+ACK 报文。
3、第三次握手:客户端收到 SYN+ACK 报文之后,会回应一个 ACK 报文。
4、服务器收到 ACK 报文之后,三次握手建立完成。
作用是为了确认双方的接收与发送能力是否正常。
这里我顺便解释一下为啥只有三次握手才能确认双方的接受与发送能力是否正常,而两次却不可以:
第一次握手:客户端发送网络包,服务端收到了。这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。第二次握手:服务端发包,客户端收到了。这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。不过此时服务器并不能确认客户端的接收能力是否正常。
第三次握手:客户端发包,服务端收到了。这样服务端就能得出结论:客户端的接收、发送能力正常,服务器自己的发送、接收能力也正常。
因此,需要三次握手才能确认双方的接收与发送能力是否正常。
这样回答其实也是可以的,但我觉得,这个过程的我们应该要描述的更详细一点,因为三次握手的过程中,双方是由很多状态的改变的,而这些状态,也是面试官可能会问的点。所以我觉得在回答三次握手的时候,我们应该要描述的详细一点,而且描述的详细一点意味着可以扯久一点。加分的描述我觉得应该是这样:
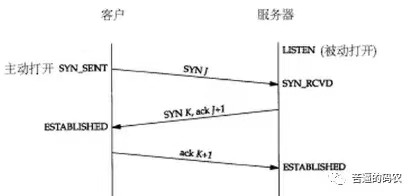
刚开始客户端处于 closed 的状态,服务端处于 listen 状态。然后
1、第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN©。此时客户端处于 SYN_Send 状态。
2、第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s),同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。
3、第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 establised 状态。
4、服务器收到 ACK 报文之后,也处于 establised 状态,此时,双方以建立起了链接
三次握手的作用
三次握手的作用也是有好多的,多记住几个,保证不亏。例如:
1、确认双方的接受能力、发送能力是否正常。
2、指定自己的初始化序列号,为后面的可靠传送做准备。
1、(ISN)是固定的吗
三次握手的一个重要功能是客户端和服务端交换ISN(Initial Sequence Number), 以便让对方知道接下来接收数据的时候如何按序列号组装数据。
如果ISN是固定的,攻击者很容易猜出后续的确认号,因此 ISN 是动态生成的。
2、什么是半连接队列
服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
这里在补充一点关于SYN-ACK 重传次数的问题: 服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传,如果重传次数超 过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s, 2s, 4s, 8s,
三次握手过程中可以携带数据吗
很多人可能会认为三次握手都不能携带数据,其实第三次握手的时候,是可以携带数据的。也就是说,第一次、第二次握手不可以携带数据,而第三次握手是可以携带数据的。
为什么这样呢?大家可以想一个问题,假如第一次握手可以携带数据的话,如果有人要恶意攻击服务器,那他每次都在第一次握手中的 SYN 报文中放入大量的数据,因为攻击者根本就不理服务器的接收、发送能力是否正常,然后疯狂着重复发 SYN 报文的话,这会让服务器花费很多时间、内存空间来接收这些报文。也就是说,第一次握手可以放数据的话,其中一个简单的原因就是会让服务器更加容易受到攻击了。
而对于第三次的话,此时客户端已经处于 established 状态,也就是说,对于客户端来说,他已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据页没啥毛病。
说一说四次挥手
**PS:**这个问的太多了,大家要先理解 =》背诵,防止突然忘了也能说个大概。这道题在问的时候,可深可浅,看面试官自己的掌握力度。
四次挥手也一样,千万不要对方一个 FIN 报文,我方一个 ACK 报文,再我方一个 FIN 报文,我方一个 ACK 报文。然后结束,最好是说的详细一点,例如想下面这样就差不多了,要把每个阶段的状态记好,我上次面试就被问了几个了,呵呵。我答错了,还以为自己答对了,当时还解释的头头是道,呵呵。
刚开始双方都处于 establised 状态,假如是客户端先发起关闭请求,则:
1、第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态。(大白话:相当于客户端告诉服务端,我想断开链接了)
2、第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 + 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态。(大白话:相当于,服务端告诉客户端,好的,我收到你的断开请求了)
3、第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
4、第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 + 1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态
5、服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
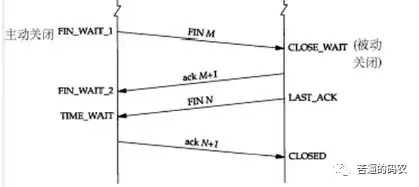
这里特别需要主要的就是TIME_WAIT这个状态了,这个是面试的高频考点,就是要理解,为什么客户端发送 ACK 之后不直接关闭,而是要等一阵子才关闭。这其中的原因就是,要确保服务器是否已经收到了我们的 ACK 报文,如果没有收到的话,服务器会重新发 FIN 报文给客户端,客户端再次收到 FIN 报文之后,就知道之前的 ACK 报文丢失了,然后再次发送 ACK 报文。
至于 TIME_WAIT 持续的时间至少是一个报文的来回时间。一般会设置一个计时,如果过了这个计时没有再次收到 FIN 报文,则代表对方成功就是 ACK 报文,此时处于 CLOSED 状态。(下面的面试题会给出更加具体的答复)
这里我给出每个状态所包含的含义,有兴趣的可以看看。
- LISTEN - 侦听来自远方TCP端口的连接请求;
- SYN-SENT -在发送连接请求后等待匹配的连接请求;
- SYN-RECEIVED - 在收到和发送一个连接请求后等待对连接请求的确认;
- ESTABLISHED- 代表一个打开的连接,数据可以传送给用户;
- FIN-WAIT-1 - 等待远程TCP的连接中断请求,或先前的连接中断请求的确认;
- FIN-WAIT-2 - 从远程TCP等待连接中断请求;
- CLOSE-WAIT - 等待从本地用户发来的连接中断请求;
- CLOSING -等待远程TCP对连接中断的确认;
- LAST-ACK - 等待原来发向远程TCP的连接中断请求的确认;
- TIME-WAIT -等待足够的时间以确保远程TCP接收到连接中断请求的确认;
- CLOSED - 没有任何连接状态;
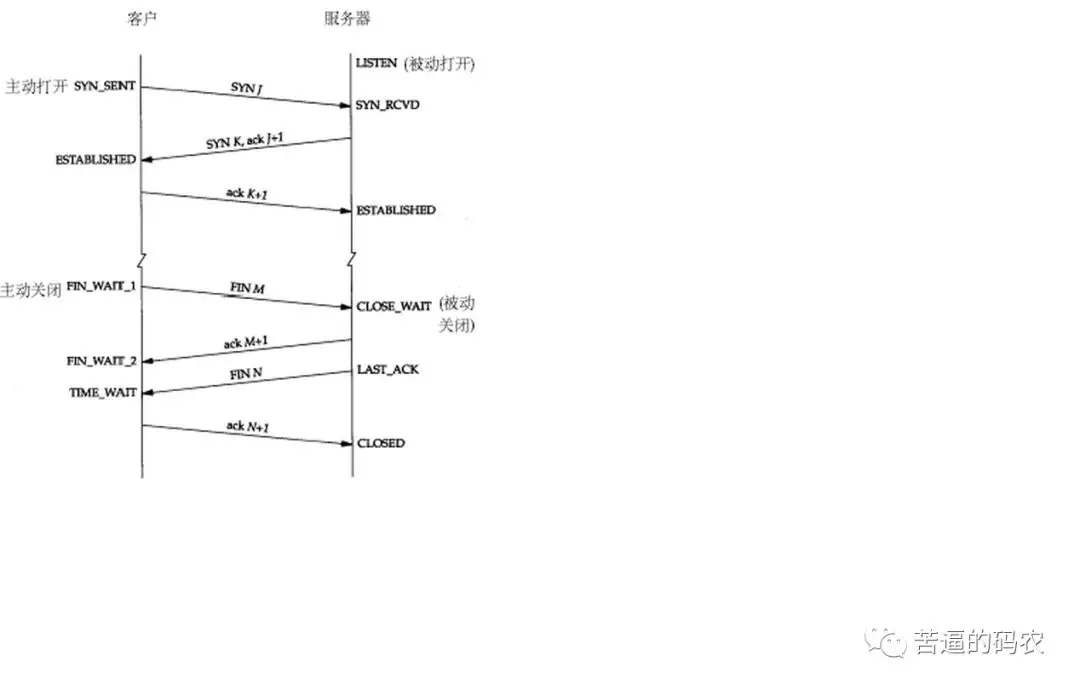
下面是三次握手和四次挥手的图片
为什么 TIME-WAIT 状态必须等待 2MSL 的时间呢?
1、为了保证 A 发送的最后一个 ACK 报文段能够到达 B。
A 发送的 ACK 报文段有可能丢失,因而使处在 LAST-ACK 状态的 B 收不到对方已发送的 FIN + ACK 报文段的确认。这时 B 会超时重传这个 FIN+ACK 报文段,而 A 就能在 2MSL 时间内(超时 + 1MSL 传输)收到这个重传的 FIN+ACK 报文段。接着 A 重传一次 ACK 报文确认,并且重新启动 2MSL 计时器。
最后,A 和 B 都正常进入到 CLOSED 状态。如果 A 在 TIME-WAIT 状态不等待一段时间,而是在发送完 ACK 报文段后立即释放连接,那么就无法收到 B 重传的 FIN + ACK 报文段,因而也不会再发送一次确认报文段,这样,B 就无法按照正常步骤进入 CLOSED 状态。
2、 防止已失效的连接请求报文段出现在本连接中。
A 在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个连接中不会出现这种旧的连接请求报文段。
说一说TCP与UDP的区别
说明:这个问题问的很多,两种之前的区别也非常多,个人觉得大家只需要说几个本质的区别就好了,不用说太多,因为有些区别是它的一些本质区别导致的,所以大家流畅说几个区别,然后等着面试官继续提问就好了,如果有面试官有继续提问道话。
回答模式:先说TCP和UDP各自特点=》讲解他们的区别=〉讲解他们的应用场景
TCP协议的主要特点
(1)TCP是面向连接的传输层协议,所谓面向连接就是双方传输数据之前,必须先建立一条通道,例如三次握手就是建议通道的一个过程,而四次挥手则是结束销毁通道的一个其中过程;而 UDP 则是无连接的传输协议。
(2)TCP 可以提供可靠的传输,比如数据丢失,超时,TCP 都会重传,并且数据包也能够按序到达,而 UDP 是不可靠的,数据丢失了也不会重传等等。
所以呢,从效率的角度讲,UDP 的效率更快,因为 UDP 不需要做诸如三次握手/四次挥手/重传等额外的消耗。
那从应用场景角度讲的话,对信息的正确率要求比较高的可以采用 TCP 协议,比如我们平时常见的文字聊天;而允许出现小部分数据丢失的,则可以采用 UDP,比如视频聊天等。
像HTTP、HTTPS、FTP、TELNET、SMTP(简单邮件传输协议)协议基于可靠的TCP协议。TFTP、DNS、DHCP、TFTP、SNMP(简单网络管理协议)、RIP基于不可靠的UDP协议。
PS:之后面试官想继续问就等着他问吧。
TCP 和 UDP 分别对应的常见应用层协议有哪些?
PS:这个问题和上一个问题其实具有包含关系,大家可以把这个作为一个补充,因为这里相对详细说明了常见的协议。
1. TCP 对应的应用层协议
FTP:定义了文件传输协议,使用 21 端口。常说某某计算机开了 FTP 服务便是启动了文件传输服务。下载文件,上传主页,都要用到 FTP 服务。
Telnet:它是一种用于远程登陆的端口,用户可以以自己的身份远程连接到计算机上,通过这种端口可以提供一种基于 DOS 模式下的通信服务。如以前的 BBS 是-纯字符界面的,支持 BBS 的服务器将 23 端口打开,对外提供服务。
SMTP:定义了简单邮件传送协议,现在很多邮件服务器都用的是这个协议,用于发送邮件。如常见的免费邮件服务中用的就是这个邮件服务端口,所以在电子邮件设置-中常看到有这么 SMTP 端口设置这个栏,服务器开放的是 25 号端口。
POP3:它是和 SMTP 对应,POP3 用于接收邮件。通常情况下,POP3 协议所用的是 110 端口。也是说,只要你有相应的使用 POP3 协议的程序(例如 Fo-xmail 或 Outlook),就可以不以 Web 方式登陆进邮箱界面,直接用邮件程序就可以收到邮件(如是163 邮箱就没有必要先进入网易网站,再进入自己的邮-箱来收信)。
HTTP:从 Web 服务器传输超文本到本地浏览器的传送协议。
2. UDP 对应的应用层协议
DNS:用于域名解析服务,将域名地址转换为 IP 地址。DNS 用的是 53 号端口。
SNMP:简单网络管理协议,使用 161 号端口,是用来管理网络设备的。由于网络设备很多,无连接的服务就体现出其优势。
TFTP(Trival File Transfer Protocal):简单文件传输协议,该协议在熟知端口 69 上使用 UDP 服务。
浏览器对同一 Host 建立 TCP 连接到的数量有没有限制?
浏览器对同一Host建立的TCP连接数量是有限制的。这个限制情况主要依赖于浏览器的类型和版本,以及特定的浏览器配置。
以HTTP/1.1协议为例,根据其规范,对于同一个给定的域,大多数浏览器限制同时打开的TCP连接数量为6个到8个。这意味着,如果一个网页需要获取该域下的更多资源,可能需要等待前面的请求完成。
但是,在HTTP/2协议中,对于同一个域,所有的请求都可以在同一个持久连接中并行完成,从而减少了所需的连接数量。
需要注意的是,这个限制只针对同一个Host。如果一个网页的资源分布在不同的Host上,那么浏览器可以分别针对这些Host建立连接。因此,使用多个子域(比如:img1.example.com,img2.example.com)去托管网站的资源是一种常见的绕过浏览器连接限制的方式,以提高加载效率。
最后,虽然上述的规则一直是浏览器同步下载的主要限制,但现在的浏览器和网络环境可能会进行一些改动和优化来提高性能。
面试题:说一说HTTP1.0,1.1,2.0 的区别
这个面试题问的不多
HTTP/1.0
1996年5月,HTTP/1.0 版本发布,为了提高系统的效率,HTTP/1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
这种方式就好像我们打电话的时候,只能说一件事儿一样,说完之后就要挂断,想要说另外一件事儿的时候就要重新拨打电话。
HTTP/1.0中浏览器与服务器只保持短暂的连接,连接无法复用。也就是说每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
我们知道TCP连接的建立需要三次握手,是很耗费时间的一个过程。所以,HTTP/1.0版本的性能比较差。
HTTP1.0 其实也可以强制开启长链接,例如接受
Connection: keep-alive这个字段,但是,这不是标准字段,不同实现的行为可能不一致,因此不是根本的解决办法。
HTTP/1.1
为了解决HTTP/1.0存在的缺陷,HTTP/1.1于1999年诞生。相比较于HTTP/1.0来说,最主要的改进就是引入了持久连接。所谓的持久连接即TCP连接默认不关闭,可以被多个请求复用。
由于之前打一次电话只能说一件事儿,效率很低。后来人们提出一种想法,就是电话打完之后,先不直接挂断,而是持续一小段时间,这一小段时间内,如果还有事情沟通可以再次进行沟通。
客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。或者客户端在最后一个请求时,主动告诉服务端要关闭连接。
HTTP/1.1版还引入了管道机制(pipelining),即在同一个TCP连接里面,客户端可以同时发送多个请求。这样就进一步改进了HTTP协议的效率。
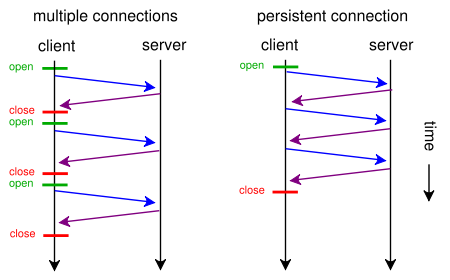
有了持久连接和管道,大大的提升了HTTP的效率。但是服务端还是顺序执行的,效率还有提升的空间。
HTTP/2
HTTP/2 是 HTTP 协议自 1999 年 HTTP 1.1 发布后的首个更新,主要基于 SPDY 协议。
HTTP/2 为了解决HTTP/1.1中仍然存在的效率问题,HTTP/2 采用了多路复用。即在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应。能这样做有一个前提,就是HTTP/2进行了二进制分帧,即 HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码。
也就是说,老板可以同时下达多个命令,员工也可以收到了A请求和B请求,于是先回应A请求,结果发现处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。A请求的两部分响应在组合到一起发给老板。

而这个负责拆分、组装请求和二进制帧的一层就叫做二进制分帧层。
除此之外,还有一些其他的优化,比如做Header压缩、服务端推送等。
Header压缩就是压缩老板和员工之间的对话。
服务端推送就是员工事先把一些老板可能询问的事情提现发送到老板的手机(缓存)上。这样老板想要知道的时候就可以直接读取短信(缓存)了。
目前,主流的HTTP协议还是HTTP/1.1 和 HTTP/2。并且各大网站的HTTP/2的使用率也在逐年增加。
什么是SQL 注入?举个例子?
**注:**这个一般会结合项目来问你,一般不会突然单独问这个,问的时候,最好可以举例子哈,自己在项目中测试过是最好的说服力,下面会举一个简单的案例。
SQL 注入就是通过把 SQL 命令插入到 We b表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令的。
1). SQL注入攻击的总体思路
(1). 寻找到SQL注入的位置
(2). 判断服务器类型和后台数据库类型
(3). 针对不通的服务器和数据库特点进行SQL注入攻击
2). SQL注入攻击实例
比如,在一个登录界面,要求输入用户名和密码,但是我们可以通过**SQL注入来实现免帐号登录,比如我们可以这样输入:
用户名: ‘or 1 = 1 --
密 码:
用户一旦点击登录,如若没有做特殊处理,那么这个非法用户就很得意的登陆进去了。
这是为什么呢?
下面我们分析一下:从理论上说,后台认证程序中会通过如下的SQL语句来判断用户的账户密码是否正确:
String sql = “select * from user_table where username=’ “+userName+” ’ and password=’ “+password+” ‘”;
因此,当输入了上面的用户名和密码,上面的SQL语句变成:
SELECT * FROM user_table WHERE username=’’or 1 = 1 –- and password=’’
分析上述SQL语句我们知道,username='' or 1=1 这个语句一定会成功;然后后面加两个 -,这意味着注释,它会将后面的语句注释,让他们不起作用。这样,上述语句永远都能正确执行,用户轻易骗过系统,获取合法身份。
3). 应对方法
(1). 参数绑定
使用预编译手段,绑定参数是最好的防SQL注入的方法。目前许多的ORM框架及JDBC等都实现了SQL预编译和参数绑定功能,攻击者的恶意SQL会被当做SQL的参数而不是SQL命令被执行。在mybatis的mapper文件中,对于传递的参数我们一般是使用#和$来获取参数值。当使用#时,变量是占位符,就是一般我们使用javajdbc的PrepareStatement时的占位符,所有可以防止sql注入;当使用$时,变量就是直接追加在sql中,一般会有sql注入问题。
(2). 使用正则表达式过滤传入的参数
谈一谈 XSS 攻击,举个例子?
**注:**这个一般会结合项目来问你,一般不会突然单独问这个,问的时候,最好可以举例子哈,自己在项目中测试过是最好的说服力,下面会举一个简单的案例。
XSS是一种经常出现在web应用中的计算机安全漏洞,与SQL注入一起成为web中最主流的攻击方式。
XSS是指恶意攻击者利用网站没有对用户提交数据进行转义处理或者过滤不足的缺点,进而添加一些脚本代码嵌入到web页面中去,使别的用户访问都会执行相应的嵌入代码,从而盗取用户资料、利用用户身份进行某种动作或者对访问者进行病毒侵害的一种攻击方式。
1). XSS攻击的危害
盗取各类用户帐号,如机器登录帐号、用户网银帐号、各类管理员帐号
控制企业数据,包括读取、篡改、添加、删除企业敏感数据的能力
盗窃企业重要的具有商业价值的资料
非法转账
强制发送电子邮件
网站挂马
控制受害者机器向其它网站发起攻击
2). 原因解析
主要原因:过于信任客户端提交的数据!
解决办法:不信任任何客户端提交的数据,只要是客户端提交的数据就应该先进行相应的过滤处理然后方可进行下一步的操作。
进一步分析细节:客户端提交的数据本来就是应用所需要的,但是恶意攻击者利用网站对客户端提交数据的信任,在数据中插入一些符号以及javascript代码,那么这些数据将会成为应用代码中的一部分了,那么攻击者就可以肆无忌惮地展开攻击啦,因此我们绝不可以信任任何客户端提交的数据!!!
3). XSS 攻击分类
(1). 反射性XSS攻击 (非持久性XSS攻击)
漏洞产生的原因是攻击者注入的数据反映在响应中。一个典型的非持久性XSS攻击包含一个带XSS攻击向量的链接(即每次攻击需要用户的点击),例如,正常发送消息:
http://www.test.com/message.php?send=Hello,World!
接收者将会接收信息并显示Hello,World;但是,非正常发送消息:
http://www.test.com/message.php?send=<script>alert(‘foolish!’)</script>!
接收者接收消息显示的时候将会弹出警告窗口!
(2). 持久性XSS攻击 (留言板场景)
XSS攻击向量(一般指XSS攻击代码)存储在网站数据库,当一个页面被用户打开的时候执行。也就是说,每当用户使用浏览器打开指定页面时,脚本便执行。
与非持久性XSS攻击相比,持久性XSS攻击危害性更大。从名字就可以了解到,持久性XSS攻击就是将攻击代码存入数据库中,然后客户端打开时就执行这些攻击代码。
例如,留言板表单中的表单域:
<input type="text" name="content" value="这里是用户填写的数据">
正常操作流程是:用户是提交相应留言信息 —— 将数据存储到数据库 —— 其他用户访问留言板,应用去数据并显示;而非正常操作流程是攻击者在value填写:
<script>alert(‘foolish!’);</script> <!--或者html其他标签(破坏样式。。。)、一段攻击型代码-->
并将数据提交、存储到数据库中;当其他用户取出数据显示的时候,将会执行这些攻击性代码。
4). 修复漏洞方针
漏洞产生的根本原因是 太相信用户提交的数据,对用户所提交的数据过滤不足所导致的,因此解决方案也应该从这个方面入手,具体方案包括:
将重要的cookie标记为http only, 这样的话Javascript 中的document.cookie语句就不能获取到cookie了(如果在cookie中设置了HttpOnly属性,那么通过js脚本将无法读取到cookie信息,这样能有效的防止XSS攻击);
表单数据规定值的类型,例如:年龄应为只能为int、name只能为字母数字组合。。。。
对数据进行Html Encode 处理
过滤或移除特殊的Html标签,例如:
<script>, <iframe> , < for <, > for>, " for
过滤JavaScript 事件的标签,例如 “οnclick=”, “onfocus” 等等。
需要注意的是,在有些应用中是允许html标签出现的,甚至是javascript代码出现。因此,我们在过滤数据的时候需要仔细分析哪些数据是有特殊要求(例如输出需要html代码、javascript代码拼接、或者此表单直接允许使用等等),然后区别处理!
什么是DDos攻击?
DDoS(Distributed Denial of Service)攻击是指利用多个不同的计算机或网络设备,协同发起大规模的拒绝服务攻击。攻击者通过控制大量的僵尸计算机(也称为“肉鸡”或“僵尸网络”)或利用其他合法的网络设备,向目标服务器或网络发起大量的请求,使其无法正常响应合法用户的请求。
DDoS攻击的目标是使目标服务器或网络过载,耗尽其计算资源、网络带宽、处理能力等,导致正常用户无法访问目标服务。攻击方式多种多样,常见的类型包括:
-
ICMP Flood:发送大量的ICMP(Internet Control Message Protocol)数据包,消耗目标服务器的网络带宽和处理能力。
-
SYN Flood:发送大量的TCP连接请求的半连接(SYN),使服务器处于半连接打开状态,无法接受新的连接请求。
-
UDP Flood:发送大量的UDP(User Datagram Protocol)数据包,使服务器的目标端口过载,无法处理其他合法的请求。
-
HTTP Flood:发送大量的HTTP请求,以耗尽目标服务器的处理能力,例如发起大量的查询或下载请求。
-
DNS Amplification:利用存在放大效应的DNS协议,向开放式DNS服务器发送小型请求,从而获得大量响应数据,使目标服务器的网络带宽被占用。
DDoS攻击可以导致服务不可用、网络延迟、数据泄漏以及经济损失,对于网站、在线服务和网络基础设施造成严重影响。为了应对DDoS攻击,可以采取一系列的防御措施,如使用入侵检测和防火墙技术、流量过滤、负载均衡等,以提高网络的安全性和抗DDoS攻击能力。
GET请求中URL编码的意义
我们知道,在GET请求中会对URL中非西文字符进行编码,这样做的目的就是为了 避免歧义(特别是中文)。看下面的例子,
针对“name1=value1&name2=value2”的例子,我们来谈一下数据从客户端到服务端的解析过程。首先,上述字符串在计算机中用ASCII吗表示为:
6E616D6531 3D 76616C756531 26 6E616D6532 3D 76616C756532
6E616D6531:name1
3D:=
76616C756531:value1
26:&
6E616D6532:name2
3D:=
76616C756532:value2
服务端在接收到该数据后就可以遍历该字节流,一个字节一个字节的吃,当吃到3D这字节后,服务端就知道前面吃得字节表示一个key,再往后吃,如果遇到26,说明从刚才吃的3D到26子节之间的是上一个key的value,以此类推就可以解析出客户端传过来的参数。
现在考虑这样一个问题,如果我们的参数值中就包含 = 或 & 这种特殊字符的时候该怎么办?比如,“name1=value1”,其中value1的值是“va&lu=e1”字符串,那么实际在传输过程中就会变成这样“name1=va&lu=e1”。这样,我们的本意是只有一个键值对,但是服务端却会解析成两个键值对,这样就产生了歧义。
那么,如何解决上述问题带来的歧义呢?解决的办法就是对参数进行URL编码:例如,我们对上述会产生歧义的字符进行URL编码后结果:“name1=va%26lu%3D”,这样服务端会把紧跟在“%”后的字节当成普通的字节,就是不会把它当成各个参数或键值对的分隔符
HTTP 哪些常用的状态码及使用场景?
说:这种状态码好多,大家不需要把他们全部死记硬背哈,没意义,大家记住几个常用的,回答的时候,就回答几个常用的,并且给面试官举例场景就好了,无论面试官是否要去你举例使用场景,你都要举例。举例的场景,最好是你遇到过的。
比如想 404,501,503,2xx系列就经常会遇到,甚至做项目的时候也经常遇到,如果你在做项目遇到过,那举例就更好了。
下面是一些状态码总结,大家看一看,有个印象就行,然后记住几个常用的给面试官说就好了。
状态码分类
1xx:表示目前是协议的中间状态,还需要后续请求
2xx:表示请求成功
3xx:表示重定向状态,需要重新请求
4xx:表示请求报文错误
5xx:服务器端错误
常用状态码
101 切换请求协议,从 HTTP 切换到 WebSocket
200 请求成功,有响应体
301 永久重定向:会缓存
302 临时重定向:不会缓存
304 协商缓存命中
403 服务器禁止访问
404 资源未找到
400 请求错误
500 服务器端错误
503 服务器繁忙

















 5863
5863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









