







目录
一、Netty的基本介绍

- 主Reactor--Boss Threads:
- NioEventLoop 中的 selector 监听连接事件
- 创建 socket channel连接
- 然后从 worker group 中选择一个 NioEventLoop注册
- 从Reactor--Worker Threads:
- 将 socket channel 注册到选择的 NioEventLoop 的 selector
- 注册读事件(OP_READ)到 selector 上,通过Handler链处理IO事件
- ChannelPipeline的介绍:
- ChannelPipeline 的双向链表分别维护了 HeadContext 和 TailContext 的头尾节点。
- 我们自定义的 ChannelHandler 会插入到 DefaultChannelPipeline 的 Head 和 Tail 之间,这两个节点在 Netty 中已经默认实现了。
- HeadContext 既是 Inbound 处理器,也是 Outbound 处理器。它分别实现了 ChannelInboundHandler 和 ChannelOutboundHandler。网络数据写入操作的入口就是由 HeadContext 节点完成的。
- HeadContext 作为 Pipeline 的头结点负责读取数据并开始传递 InBound 事件,当数据处理完成后,数据会反方向经过 Outbound 处理器,最终传递到 HeadContext,所以 HeadContext 又是处理 Outbound 事件的最后一站。
- TailContext 只实现了 ChannelInboundHandler 接口。它会在 ChannelInboundHandler 调用链路的最后一步执行,主要用于终止 Inbound 事件传播,例如释放 Message 数据资源等。
- Inbound 事件的传播方向为 Head -> Tail,而 Outbound 事件传播方向是 Tail -> Head。
- 异常捕获:
- 如果用户没有对异常进行拦截处理,会向后传播,最后将由 Tail 节点统一处理。
- 虽然 Netty 中 TailContext 提供了兜底的异常处理逻辑,但是在很多场景下,并不能满足我们的需求。假如你需要拦截指定的异常类型,并做出相应的异常处理
- 异常处理的最佳实践
在 Netty 应用开发的过程中,良好的异常处理机制会让排查问题的过程事半功倍。所以推荐用户对异常进行统一拦截,然后根据实际业务场景实现更加完善的异常处理机制。在 ChannelPipeline 自定义处理器的末端添加统一的异常处理器 -
public class ExceptionHandler extends ChannelDuplexHandler { @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) { if (cause instanceof RuntimeException) { System.out.println("Handle Business Exception Success."); } } }
- WriteAndFlush方法:
- 最终是调用write 和 flush方法 ,这两个方法都是在 Head 节点 HeadContext 实现的。
- write 方法:将数据写入到 ChannelOutboundBuffer 缓存中
- 过滤msg:如果 msg 使用的不是 DirectByteBuf,那么它会将 msg 转换成 DirectByteBuf。
- 给buffer添加数据:
- ChannelOutboundBuffer 缓存是一个链表结构,每次传入的数据都会被封装成一个 Entry 对象添加到链表中。ChannelOutboundBuffer 包含三个非常重要的指针:第一个被写到缓冲区的节点 flushedEntry、第一个未被写到缓冲区的节点 unflushedEntry和最后一个节点 tailEntry
- tailEntry 指针会不断指向新加入的 msgN,unflushedEntry 依然保持不变,unflushedEntry 和 tailEntry 指针之间的数据都是未写入 Socket 缓冲区的。
- 但是我们不可能一直向缓存中写入数据,所以 addMessage 方法中每次写入数据后都会判断缓存的水位线 ,判断缓存大小是否超过所设置的高水位线 64KB,如果超过了高水位,那么 Channel 会被设置为不可写状态。直到缓存的数据大小低于低水位线 32KB 以后,Channel 才恢复成可写状态。
- flush 方法:调用channel的write方法将数据写入到 Socket 缓冲区
- 准备待发送数据:
- flushedEntry 指针指向的数据才会被真正发送到 Socket 缓冲区。decrementPendingOutboundBytes 主要作用是减去待发送的数据字节,如果缓存的大小已经小于低水位,那么 Channel 会恢复为可写状态。
- doWrite 方法:
- 当我们向 Socket 底层写数据的时候,如果每次要写入的数据量很大,是不可能一次将数据写完的,所以只能分批写入。
- Netty 在不断调用写入逻辑的时候,EventLoop 线程可能一直在等待,这样有可能会阻塞其他事件处理。所以需要控制一次写入数据的最大的循环执行次数,如果超过所设置的自旋锁次数,那么写操作将会被暂时中断。
- 删除缓存中的链表节点以及调用Socket底层 API 发送数据。
- 调用 incompleteWrite 方法确保数据能够全部发送出去:
- 因为自旋锁次数的限制,可能数据并没有写完,所以需要继续 OP_WRITE 事件;如果数据已经写完,清除 OP_WRITE 事件即可。
- 准备待发送数据:
- Netty启动的流程:
- 1.创建服务端 Channel:本质是创建 JDK 底层原生的 Channel,并初始化几个重要的属性,包括 id、unsafe、pipeline 等。
- 2.初始化服务端 Channel:设置 Socket 参数以及用户自定义属性,并给Boos Group添加特殊的处理器ServerBootstrapAcceptor(可以将channel注册到从Reacter)。
- 3.注册服务端 Channel:实际是调用 JDK 底层将 Channel 注册到 Selector 上并监听对应事件。
- 4.端口绑定:实际是调用 JDK 底层给 Channel 绑定端口,并触发 channelActive 事件。
- 注册和绑定:不会阻塞当前线程,实际是EventLoop执行,给Future添加回调,来实现。
- Netty处理客户端连接:
- 1.Netty 服务端启动后,BossEventLoopGroup 会负责监听客户端的相应事件。
- 2.当有客户端新连接接入时,BossEventLoopGroup 中的 NioEventLoop 进入到AbstractNioMessageChannel的read方法调用JDK的accept()方法 新建 Channel连接,
- 3.调用Pipeline触发事件传播,通过 ServerBootstrapAcceptor 的 channelRead() 方法将Channel 注册到 WorkerEventLoopGroup 中。
- 以上就完成了客户端连接,现在可以接收客户端的请求。
- 4.当客户端向服务端发送数据时,NioEventLoop 会监听到相应的事件,然后分配 ByteBuf 并读取数据,最后交给 Pipeline 进行处理。
- 一般来说,数据会从 ChannelPipeline 的第一个 ChannelHandler 开始传播,将加工处理后的消息传递给下一个 ChannelHandler,整个过程是串行化执行。
- 5.最终finally会执行taskQueue里的任务。

- Boss和WorkerEventLoopGroup都有相应的PipeLine和EventLoop,流程基本是相同的;
二、Netty的编解码拦截器;
- 执行逻辑:
- 执行ChannelPipeline,这种拦截器的设计模式,可以让数据的处理方式扩展性更好,比如:TCP协议的粘包拆包问题、HTTP协议的数据处理、数据的压缩和解压缩、数据的序列化和反序列化。

- 编/解码器:
- 编码器负责将“Java对象”转化为可传输的“byte字节类型-二进制”;
- 编码器是基于ChannelOutboundHandler的扩展;
- 解码器为逆过程;
- 基于TCP协议的粘包拆包通过编解码器的解决方式:
- 特定分隔符法:使用基于特殊分割符的方式;
- 由于在发送报文时尾部需要添加特定分隔符,所以对于分隔符的选择一定要避免和消息体中字符相同,以免冲突。否则可能出现错误的消息拆分。
- 比较推荐的做法是将消息进行编码,例如 base64 编码,然后可以选择 64 个编码字符之外的字符作为特定分隔符。特定分隔符法在消息协议足够简单的场景下比较高效,例如 Redis 在通信过程中采用的就是换行分隔符。
- 消息长度+消息内容:先写入一个数据长度,然后在写入消息即可,比如心跳信息就约定长度为-1;
- 消息长度 + 消息内容是项目开发中最常用的一种协议。消息头中存放消息的总长度,例如使用 4 字节的 int 值记录消息的长度,消息体实际的二进制的字节数据。
- 接收方在解析数据时,首先读取消息头的长度字段 Len,然后紧接着读取长度为 Len 的字节数据,该数据即判定为一个完整的数据报文。消息长度 + 消息内容的使用方式非常灵活,且不会存在消息定长法和特定分隔符法的明显缺陷。

- 特定分隔符法:使用基于特殊分割符的方式;
三、Netty的ByteBuf;
- 索引指针更细粒度的划分:
- JDK原生的buffer底层使用了pos指针、limit指针、capacity指针来实现读写,在写模式下调用flip方法,那么limit就设置为了position当前的值(即当前写了多少数据),postion会被置为0,以表示读操作从缓存的头开始读。
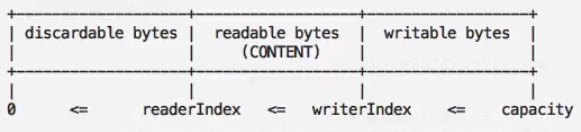
- Netty进行了改进,使用了readerIndex指针、writerIndex指针、capacity指针来进行了实现,不需要进行flip重置指针,更加高效。
- 分为三部分,第一部分为已经读取过的数据可以进行废弃,第二部分是还没有读取但是可以读取的数据,第三部分是还没有写但是可以写的区域。
- 动态扩容机制:
- 这是JDK的ByteBuffer对象中用于存储数据的对象声明,其字节数组是被声明为final的,也就是长度是固定不变的。一旦分配好后不能动态扩容,如果ByteBufer的空间不足,我们需要自己实现动态扩容,创建一个全新的ByteBuffer对象,然后再将之前的ByteBuffer中的数据复制过去。
- Netty存储字节的数组是动态的,其最大值默认是Integer.anx_VALB。这里的动态性是体现在write方法中的, write方法在执行时会判断butfer容量,如果不足则自动扩容。
- 默认门限阈值为4MB(这个阈值是一个经验值,不同场景,可能取值不同);
- 当需要的容量等于门限阈值,使用阈值作为新的缓存区容量 目标容量;
- 如果大于阈值,采用每次步进4MB的方式进行内存扩张((需要扩容值/4MB)*4MB),扩张后需要和最大内存(maxCapacity)进行比较,大于maxCapacity的话就用maxCapacity,否则使用扩容值 目标容量;
- 如果小于阈值,采用倍增的方式,以64(字节)作为基本数值,每次翻倍增长64-》128-》256,直到倍增后的结果大于或等于需要的容量值。
- ByteBuf大致分为两种Pooled和Unpooled:
- pooled(池化)类型的bytebuf是在已经申请好的内存块取一块内存,而Unpooled(未池化)是直接通过JDK底层代码申请。
- ByteBuf提供了heap buffer堆缓冲、direct buffer非堆缓冲、composite buffer复合缓冲(可以组装堆缓冲和非堆缓冲)这三种,
四、Netty的心跳检测
- 客户端和服务端都可以检测每隔一段时间是否有读写请求,如果没有就会触发回调,自己可以设定一些逻辑。
- Netty 中的心跳检测机制_rickiyang的博客-CSDN博客_netty心跳检测
五、Netty的Future和Promise
- Netty的ChannelFuture和Promise接口在JDK的Future接口上增加了监听器功能;
- 当setSucces置为完成状态的时候,就会调用ChannelFuture对应的Listener,在执行任务的线程异步执行。
- 当我们进行异步IO操作时,完成的时间是无法预测的,利用异步通知机制回调FutureListener,当前业务线程不需要一直阻塞,这样的实现非常优雅。
- Netty的实现类DefaultChannelPromise是以上接口的实现,是JDK的FutureTask的一个扩展;
扩展:HTTP和自定义RPC协议的区别;
- 两者其实都是建立在TCP协议的传输层之上的,都应该属于应用层的协议;
- RPC协议是属于RPC框架的;
- RPC框架:底层数据传输可以基于不同的协议实现
- 基于HTTP协议,不需要设计消息的结构,也不需要处理粘包拆包问题,按照顺序和换行分隔符解析出请求行、请求头、请求体即可,然后对数据进行解码。
- 基于TCP协议,需要设计消息的结构,需要处理粘包拆包问题,可以写入一个消息长度来解决,然后读出数据进行解码即可。
- +---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 消息 ID 8byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
- +---------------------------------------------------------------+

扩展:Netty高性能原因;
- epoll的实现红黑树O(logN), 平衡效率和内存占用, 在容量需求不能确定并可能量很大的情况下红黑树是最佳选择、size参数已经没什么意义, 早期epoll实现是hash表, 所以需要size参数 ,
- FastThreadLocal, 相比jdk的实现更快 线性探测的Hash表 —> index原子自增的裸数组存储, 从socket读写数据时(内存池, 零拷贝)等技术。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









