









Elasticsearch Completion Suggester(补全建议)
官方文档
补全建议器提供了根据输入自动补全/搜索的功能。这是一个导航功能,引导用户在输入时找到相关结果,提高搜索精度。
理想情况下,自动补全功能应该和用户输入一样快,以便为用户提供与已输入内容相关的即时反馈。因此,completion建议器针对速度进行了优化。建议器使用的数据结构支持快速查找,但构建成本很高,并且存储在内存中。
拼音分词插件elasticsearch-analysis-pinyin安装
源码地址:https://gitcode.com/medcl/elasticsearch-analysis-pinyin/overview
-
idea通过git(https://gitcode.com/medcl/elasticsearch-analysis-pinyin.git)导入项目
-
切换到分支7.x
-
修改pom.xml,elasticsearch.version 版本号为7.15.0
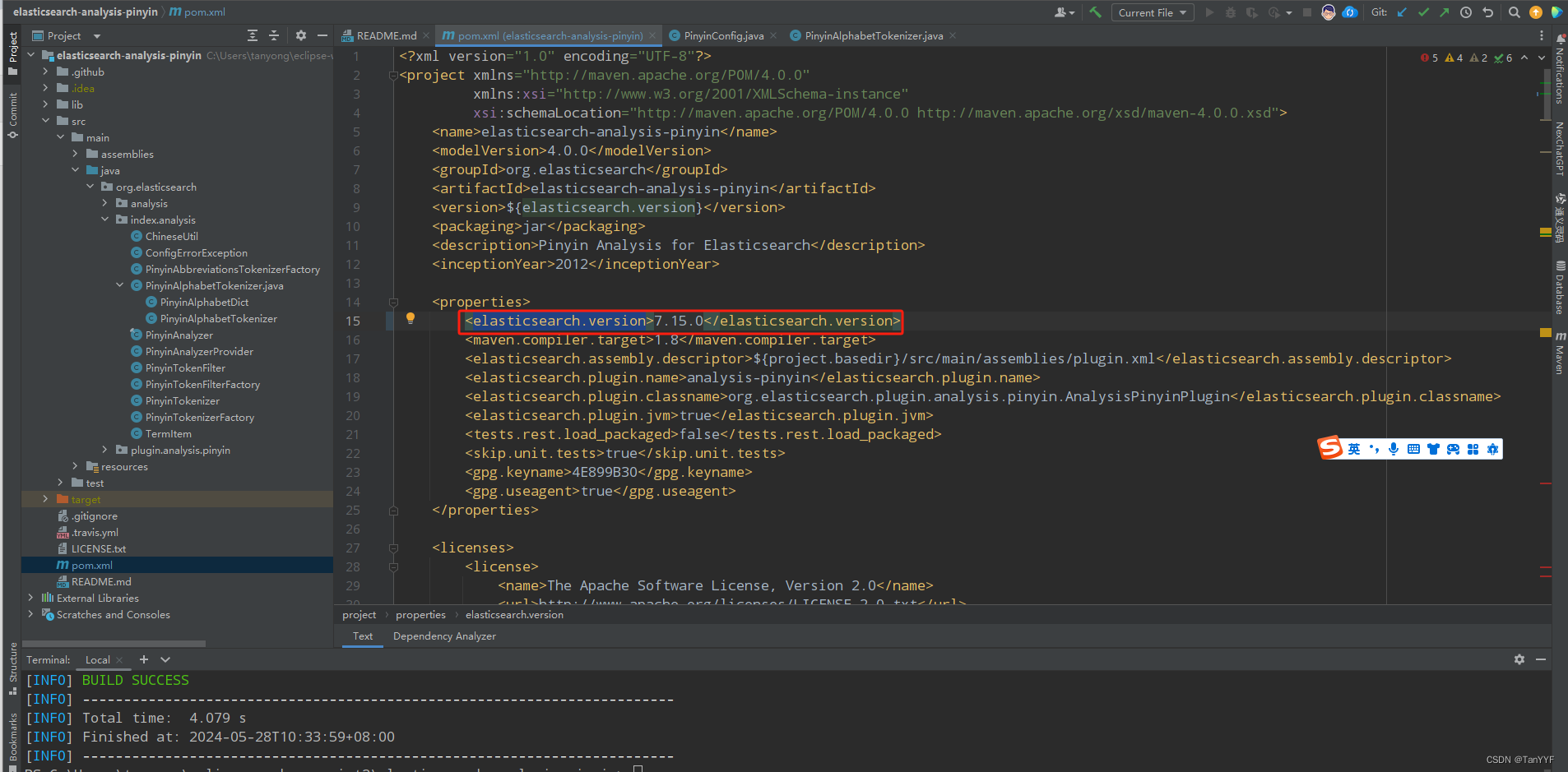
-
执行maven打包命令
mvn clean package "-Dmaven.test.skip=true"执行命令以后生成的插件:
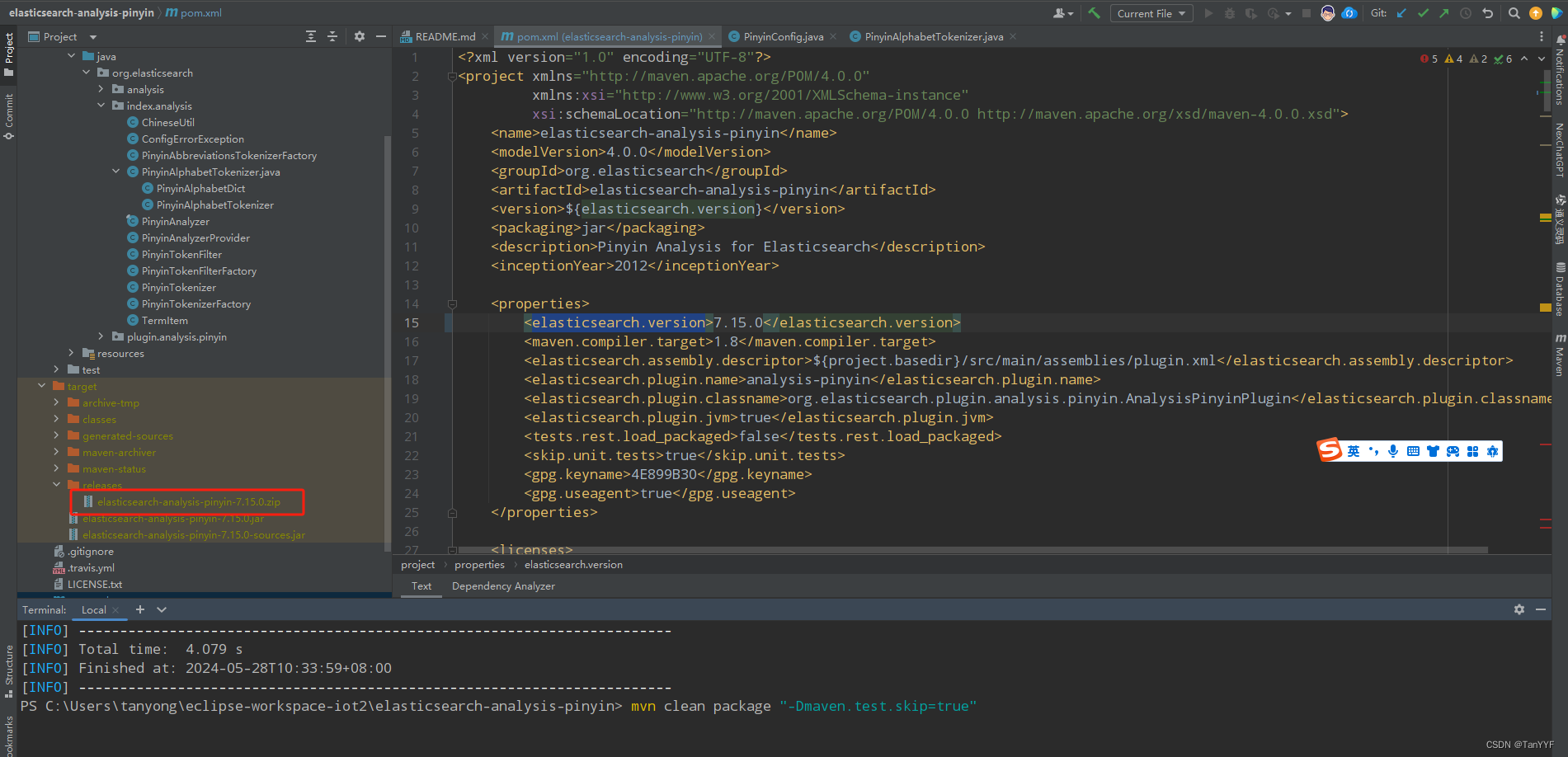
-
将elasticsearch-analysis-pinyin-7.15.0.zip上传到服务器elasticsearch安装目录,修改文件权限为elasticsearch用户权限,笔者的用户是hadoop.
chown hadoop:hadoop elasticsearch-analysis-pinyin-7.15.0.zip -
进入elasticsearch安装目录执行命令安装插件
sh ./bin/elasticsearch-plugin install file:elasticsearch-analysis-pinyin-7.15.0.zip
-
重新启动elasticsearch
# 停止 kill -9 进程id #启动 sh ./bin/elasticsearch -d -
查询插件是否安装成功
GET _cat/plugins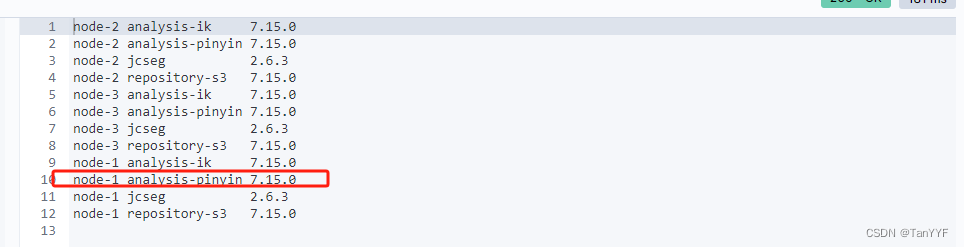
-
拼音插件参数说明
The plugin includes analyzer: pinyin , tokenizer: pinyin and token-filter: pinyin.- keep_first_letter 当启用此选项时, eg: 刘德华>ldh, default: true
- **keep_separate_first_letter ** 当此选项启用时,将单独保留首字母, eg: 刘德华>l,d,h, default: false, NOTE: 由于查询词的频率过高,查询结果可能会过于模糊
- limit_first_letter_length set max length of the first_letter result, default: 16
- keep_full_pinyin when this option enabled, eg: 刘德华> [liu,de,hua], default: true
- keep_joined_full_pinyin when this option enabled, eg: 刘德华> [liudehua], default: false
- keep_none_chinese 结果中保留非中文字母或数字, default: true
- keep_none_chinese_together keep non chinese letter together, default: true, eg: DJ音乐家 -> DJ,yin,yue,jia, when set to false, eg: DJ音乐家 -> D,J,yin,yue,jia, NOTE: keep_none_chinese should be enabled first
- keep_none_chinese_in_first_letter keep non Chinese letters in first letter, eg: 刘德华AT2016->ldhat2016, default: true
- keep_none_chinese_in_joined_full_pinyin keep non Chinese letters in joined full pinyin, eg: 刘德华2016->liudehua2016, default: false
- none_chinese_pinyin_tokenize 如果非汉语字母是拼音,则将其拆分成单独的拼音术语, default: true, eg: liudehuaalibaba13zhuanghan -> liu,de,hua,a,li,ba,ba,13,zhuang,han, NOTE: keep_none_chinese and keep_none_chinese_together should be enabled first
- keep_original 将非中文字母分成单独的拼音词,如果它们是拼音时,此选项启用,将保持原始输入, default: false
- lowercase lowercase non Chinese letters, default: true
- trim_whitespace default: true
- remove_duplicated_term when this option enabled, duplicated term will be removed to save index, eg: de的>de, default: false, NOTE: position related query maybe influenced
- ignore_pinyin_offset after 6.0, offset is strictly constrained, overlapped tokens are not allowed, with this parameter, overlapped token will allowed by ignore offset, please note, all position related query or highlight will become incorrect, you should use multi fields and specify different settings for different query purpose. if you need offset, please set it to false. default: true.
创建索引
PUT hot_word
{
"settings": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"max_result_window": "10000",
"number_of_replicas": "1",
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "my_pinyin"
}
},
"tokenizer": {
"my_pinyin": {
"type": "pinyin",
"keep_separate_first_letter": true,
"keep_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"lowercase": true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"suggest": {
"type": "completion",
"analyzer": "pinyin_analyzer",
"preserve_separators": true,
"preserve_position_increments": true,
"max_input_length": 50
}
}
}
}
类型completion 参数:
| 参数 | 说明 |
|---|---|
| analyzer | 要使用的索引分析器默认为simple。 |
| search_analyzer | 要使用的搜索分析器,默认值为analyzer。 |
| preserve_separators | 保留分隔符,默认为true。如果禁用,你可以找到一个以Foo Fighters开头的字段,如果你建议使用foof。 |
| preserve_position_increments | 启用位置增量,默认为true如果禁用并使用停用词分析器,你可以得到一个以The Beatles开头的字段,如果你建议使用b。注意:你也可以通过索引两个输入,Beatles和The Beatles来实现这一点,如果你能够丰富数据,则无需更改简单的分析器。 |
| max_input_length | 限制单个输入的长度,默认为50个UTF-16代码点。这个限制只在索引时用于减少每个输入字符串的字符总数,以防止大量输入使底层数据结构膨胀。大多数用例都不受默认值的影响,因为前缀补全的长度很少超过几个字符。 |
添加数据
PUT hot_word/_doc/1?refresh
{
"name":"压克力盒",
"suggest":{
"input":["压克力盒"],
"weight":10
}
}
PUT hot_word/_doc/2?refresh
{
"name":"亚克力盒",
"suggest":{
"input":["亚克力盒"],
"weight":10
}
}
PUT hot_word/_doc/3?refresh
{
"name":"刻磨機",
"suggest":{
"input":["刻磨機"],
"weight":10
}
}
PUT hot_word/_doc/4?refresh
{
"name":"刻模机",
"suggest":{
"input":["刻模机"],
"weight":10
}
}
suggest参数说明:
| 参数 | 说明 | 备注 |
|---|---|---|
| input | 要存储的输入,可以是一个字符串数组,也可以只是一个字符串。该字段是必填字段。 | 此值不能包含以下UTF-16控制字符:\u0000 (null),\u001f (information separator one),\u001f (information separator one) |
| weight | 一个正整数或包含一个正整数的字符串,它定义了权重,允许你对建议进行排序。该字段是可选的。 |
查询
GET hot_word/_search?pretty
{
"_source": ["suggest"],
"suggest": {
"song-suggest": {
"prefix": "关键词",
"completion": {
"field": "suggest",
"size": 10,
"skip_duplicates": true
}
}
}
}
参数说明:
- suggest: suggest类型
- song-suggest: suggest名称,自定义命名
- prefix:搜索建议时使用的前缀
- completion: 建议类型
- field:搜索建议的字段名称
- size:返回的建议条数,默认5
- skip_duplicates:是否应该过滤重复的建议(默认为false)。
测试:
-
测试中文输入关键词:亚,亚克、亚克力、亚克力盒,正常返回补全结果:
{ "took" : 6, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "suggest" : { "song-suggest" : [ { "text" : "亚克力", "offset" : 0, "length" : 3, "options" : [ { "text" : "亚克力盒", "_index" : "hot_word", "_type" : "_doc", "_id" : "2", "_score" : 10.0, "_source" : { "suggest" : { "input" : [ "亚克力盒" ], "weight" : 10 } } }, { "text" : "压克力盒", "_index" : "hot_word", "_type" : "_doc", "_id" : "1", "_score" : 10.0, "_source" : { "suggest" : { "input" : [ "压克力盒" ], "weight" : 10 } } } ] } ] } } -
测试拼音输入:ya、yake,yakelihe,yakelihe,正常返回补全结果:
{ "took" : 7, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "suggest" : { "song-suggest" : [ { "text" : "yakelihe", "offset" : 0, "length" : 8, "options" : [ { "text" : "亚克力盒", "_index" : "hot_word", "_type" : "_doc", "_id" : "2", "_score" : 10.0, "_source" : { "suggest" : { "input" : [ "亚克力盒" ], "weight" : 10 } } }, { "text" : "压克力盒", "_index" : "hot_word", "_type" : "_doc", "_id" : "1", "_score" : 10.0, "_source" : { "suggest" : { "input" : [ "压克力盒" ], "weight" : 10 } } } ] } ] } } -
测试拼音首字母输入:y、yk、ykl、yklh,正常返回补全结果。支持首字母补全,pinyin需要设置keep_separate_first_letter为true。
-
测试同音字输入:鸭,鸭课,正常返回补全结果。
-
测试简繁体输入:刻模机,正常返回简繁体补全结果。
模糊查询
completion建议器还支持模糊查询——这意味着即使你在搜索中输入错误,仍然可以得到结果。
GET hot_word/_search?pretty
{
"_source": ["suggest"],
"suggest": {
"song-suggest": {
"prefix": "关键词",
"completion": {
"field": "suggest",
"size": 10,
"skip_duplicates": true,
"fuzzy": {
"fuzziness": 2,
"min_length":4,
"prefix_length":4,
"transpositions": false,
"unicode_aware":true
}
}
}
}
}
模糊查询fuzzy参数说明:
- fuzziness:作用:决定模糊匹配的程度。默认值为AUTO,意味着根据查询项的长度自动调整模糊匹配的严格程度。也可以手动设置为具体的值,如0(精确匹配)、1(允许一个编辑距离内的匹配)等,或者使用其他特定的字符串值(如"AUTO"、“1”、“2”)。
- transpositions:如果设置为true(默认值),则在计算编辑距离时把字符的交换视为一个变化而不是两个。这对于那些可能因快速打字而产生的常见转置错误(比如"thsi"到"this")非常有用。
- min_length:只有当查询字符串长度达到这个值时,才会返回模糊建议。默认为3,意味着较短的查询可能不会触发模糊匹配,以减少不相关的匹配结果。
- prefix_length:指定了查询字符串中从开始部分的多少个字符必须精确匹配,之后的字符才开始应用模糊匹配算法。默认为1,意味着除了最小长度要求外,所有字符都可能被模糊处理。增加这个值可以提高查询的精确度,尤其是在查询字符串较短时。
- unicode_aware:确定是否在进行模糊匹配计算时考虑Unicode编码。如果设为true,则编辑距离、转置等计算都会基于Unicode码点进行,这使得多语言文本的处理更为准确。但因为涉及到更复杂的计算,所以默认为false以追求更快的性能。
测试输入“亚可爱”,正常返回补全结果:
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"song-suggest" : [
{
"text" : "亚可爱",
"offset" : 0,
"length" : 3,
"options" : [
{
"text" : "亚克力盒",
"_index" : "hot_word",
"_type" : "_doc",
"_id" : "2",
"_score" : 40.0,
"_source" : {
"suggest" : {
"input" : [
"亚克力盒"
],
"weight" : 10
}
}
},
{
"text" : "压克力盒",
"_index" : "hot_word",
"_type" : "_doc",
"_id" : "1",
"_score" : 40.0,
"_source" : {
"suggest" : {
"input" : [
"压克力盒"
],
"weight" : 10
}
}
}
]
}
]
}
}
Java实现
easy-es实现:https://www.easy-es.cn/,这个框架建议索引设置为手动,自动索引还不是很稳定
- 添加maven依赖:
<!-- 引入easy-es最新版本的依赖-->
<dependency>
<groupId>org.dromara.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<!--这里Latest Version是指最新版本的依赖,比如2.0.0,可以通过下面的图片获取-->
<version>v2.0.0</version>
</dependency>
<!-- 排除springboot中内置的es依赖,以防和easy-es中的依赖冲突-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.14.0</version>
</dependency>
- java实体关键代码:
/**
* 自动补齐字段
*/
@IndexField(fieldType = FieldType.NESTED, nestedClass = SearchHotWordV2IDX.HotSuggest.class)
private SearchHotWordV2IDX.HotSuggest suggest;
@Data
public static class HotSuggest {
@IndexField(fieldType = FieldType.INTEGER)
private Integer weight;
@IndexField(fieldType = FieldType.KEYWORD)
private List<String> input;
}
- 新增
使用mapper直接调用就可以 - 查询关键代码:
private static final String HOT_KEYWORD_SUGGEST_NAME = "hot-suggest";
public List<String> autoComplete(String keyword, Boolean fuzzy) {
LambdaEsQueryWrapper<SearchHotWordV2IDX> queryWrapper = new LambdaEsQueryWrapper<SearchHotWordV2IDX>();
queryWrapper.select(SearchHotWordV2IDX::getSuggest);
String newKeyword = Optional.ofNullable(keyword)
.map(a -> a.toLowerCase())
.map(b -> StrUtil.sub(b, 0, 10)).orElseThrow(RuntimeException::new);
// 定义建议构造器
SuggestBuilder suggestBuilder = new SuggestBuilder();
// 自动补全补齐构造器
CompletionSuggestionBuilder completionSuggestionBuilder = new CompletionSuggestionBuilder("suggest")
.size(20)
.skipDuplicates(true);
if (fuzzy) {
// 设置模糊查询
FuzzyOptions fuzzyOptions = FuzzyOptions.builder()
.setFuzziness(2)
.setFuzzyMinLength(4)
.setFuzzyPrefixLength(4).build();
completionSuggestionBuilder.prefix(newKeyword, fuzzyOptions);
} else {
completionSuggestionBuilder.prefix(newKeyword);
}
// 自动补全添加到建议构造器
suggestBuilder.addSuggestion(HOT_KEYWORD_SUGGEST_NAME, completionSuggestionBuilder);
SearchSourceBuilder searchSourceBuilder = searchHotWordV2EsMapper.getSearchSourceBuilder(queryWrapper);
// 建议器添加到searchSourceBuilder
searchSourceBuilder.suggest(suggestBuilder);
// queryWrapper设置searchSourceBuilder
queryWrapper.setSearchSourceBuilder(searchSourceBuilder);
// 查询
SearchResponse response = searchHotWordV2EsMapper.search(queryWrapper);
Suggest suggest = response.getSuggest();
// 获取自动补全结果
CompletionSuggestion completionSuggestion = suggest.getSuggestion(HOT_KEYWORD_SUGGEST_NAME);
return Optional.ofNullable(completionSuggestion.getOptions())
.map(a -> a.stream().map(b -> b.getText().string()).collect(Collectors.toList())).orElse(null);
}















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









