







 本文详细探讨了常量传播在编译器优化中的作用,包括其数据流值结构、无界数据流、非分配性和单调性分析,以及如何处理UNDEF值。通过理解这些概念,可以优化程序执行效率并确保正确性。
本文详细探讨了常量传播在编译器优化中的作用,包括其数据流值结构、无界数据流、非分配性和单调性分析,以及如何处理UNDEF值。通过理解这些概念,可以优化程序执行效率并确保正确性。


常量传播:深入理解编译器优化的关键
常量传播作为编译器优化中的一项高级技术,对提升程序执行效率和减少不必要的计算具有重要作用。它通过在编译时期识别并利用程序中的常量信息,有效地简化程序逻辑。本节将详细探讨常量传播框架及其数据流值的结构,揭示其在优化过程中的关键角色。
常量传播框架的特殊性质
常量传播框架在数据流分析领域中独树一帜,主要体现在以下两个方面:
- 无界数据流值集合:不同于其他数据流分析问题,常量传播面对的是一个无界的数据流值集合,即对于特定的流图,可能存在无限多种常量值情况。
- 缺乏分配性:常量传播框架并不满足分配性质,这一点使得分析过程相比于有分配性的框架更加复杂,但也更加精确。
这两个特性使得常量传播问题在理论和实践上都是编译器优化中的一个挑战,但同时也是一个机遇。
数据流值的组成
在常量传播框架中,数据流值的设定是其核心,它决定了分析的精度和效率。数据流值主要包括以下三部分:
1. 可能的常量值
数据流值包括了程序中变量可能取到的所有常量值,这为编译器优化提供了基础信息。
2. 特殊值NAC
"NAC"(Not A Constant)表示变量的值不能保证为一个确定的常量。这种情况可能出现在变量依赖于非常量的变量,或者在不同的执行路径上被赋予不同的常量值。
3. 特殊值UNDEF
"UNDEF"(Undefined)表示变量在某个程序点没有定义。这种情况通常发生在变量在该程序点之前没有任何赋值操作。
NAC与UNDEF的区别
NAC和UNDEF虽然都表明变量值的不确定性,但它们代表了不同的语义:NAC意味着变量虽然有赋值,但赋值的结果不是一个固定的常量;而UNDEF则表示变量在该点之前没有任何赋值,即变量值完全未知。
整型变量的半格示例
以整型变量为例,其半格结构包括所有整数常量、NAC和UNDEF。其中,UNDEF作为顶元表示最大不确定性,而NAC作为底元表示最大确定性(确定不是常量)。半格的汇合运算则用来处理变量值在不同路径上的合并情况。
常量传播的数据流值映射
在常量传播框架中,整个程序的数据流值被建模为各变量到其对应值半格元素的映射集合。这种映射方式为编译器在优化过程中提供了强大的分析和决策能力。
结论
常量传播框架及其数据流值的精细结构为编译器优化提供了一种强有力的工具,使得编译器能够在编译期间有效地识别和利用常量信息,从而提升程序的执行效率。通过深入理解常量传播的数据流值,我们能够更好地把握编译器优化技术的精髓和应用。

常量传播框架中的迁移函数详解
常量传播是编译器优化过程中的一项关键技术,旨在分析和传递程序中的常量值,以减少运行时的计算量。本节将深入探讨常量传播框架中迁移函数的构成和工作机制,这些函数是实现常量传播分析的核心。
迁移函数的基本构成
在常量传播框架中,迁移函数集合F是分析的基础,负责将变量到值的映射转换为新的映射。这些函数按照程序中基本块的语句进行定义,具体包括:
- 恒等函数:对于非赋值语句,迁移函数仅仅是一个恒等函数,不对变量到值的映射做任何修改。
- 迁移常函数:用于程序入口(ENTRY结点),将所有变量的值初始化为UNDEF,表示在程序开始执行之前,所有变量都未被定义。
赋值语句的迁移函数
对于赋值语句,迁移函数的行为更为复杂,取决于赋值的右侧表达式:
- 常量赋值:如果赋值的右部是常量c,则目标变量x的新值就是c。
- 表达式赋值:如果右部是一个表达式(如y+z),则根据y和z的值来决定x的新值:
- 如果y和z都是常量,则x的新值为这两个常量的运算结果。
- 如果y或z中任意一个为NAC或UNDEF,则x的新值为NAC,表示不是一个确定的常量。
迁移函数的逻辑
迁移函数的设计体现了常量传播分析的精髓:通过编译时的分析,尽可能地确定变量的常量值,以便优化程序的执行。对于每个基本块中的语句,迁移函数精确地模拟了它对程序状态的影响,从而为后续的优化决策提供依据。
示例解析
考虑以下简单的代码段:
int x = 5;
int y = x + 3;
在这个例子中,对x的赋值导致迁移函数将x映射到常量5,而对y的赋值,则通过迁移函数将y映射到8,因为x的值为一个已知的常量,且加法操作的另一个操作数3也是一个常量。
结论
常量传播框架的迁移函数是实现编译时常量分析的关键,它们精确地模拟了程序中各种赋值和计算对变量值的影响。通过这些函数,编译器能够在编译期间识别出常量值,进而进行相应的优化处理,以提高程序运行的效率和性能。
常量传播框架的单调性分析
常量传播是一种关键的编译器优化技术,通过分析和传播程序中的常量信息,以减少运行时的计算量。常量传播框架的单调性是理解其工作原理和效果的重要方面。本节将解释常量传播框架的单调性,并通过一个具体的例子进行说明。
单调性定义
在数据流分析中,一个框架被认为是单调的,如果其迁移函数保持数据流值的偏序关系。也就是说,如果对于任意两个数据流值m和m',当m ≤ m'时,应用迁移函数f后仍然保持f(m) ≤ f(m')。单调性保证了数据流分析的正确性和稳定性。
常量传播框架的单调性证明
非复合表达式情况
对于大部分情况,即当赋值语句的右部不是形如y+z的表达式时,迁移函数f要么不改变映射m(x)的值,要么将其改变为一个确定的常量。在这些情况下,显然f是单调的,因为它不会破坏已有的偏序关系。
复合表达式情况
当赋值语句的右部是形如y+z的表达式时,迁移函数f的行为稍微复杂。表9.3展示了这种情况下f对变量x的影响,其中考虑了y和z的所有可能值及其对x的结果。
从表9.3中可以观察到,无论y和z的值如何变化,x的值都遵循从最大到最小的顺序。特别是,如果y或z之一为NAC(不是常量)或UNDEF(未定义),则x的结果为NAC或保持UNDEF,反映了对x值的保守估计。
单调性的直观理解
通过上述分析,我们可以看出,常量传播框架中的迁移函数f保持了数据流值之间的偏序关系,因此是单调的。这意味着,即使在面对复合表达式时,框架也能够保持对变量值的稳妥估计,从而确保了优化的正确性和稳定性。
结论
常量传播框架的单调性是其设计和实现的关键属性,保证了分析的准确性和稳定性。通过对赋值语句的细致分析,我们证明了框架在处理各种情况下都保持了单调性,这为编译器优化提供了坚实的理论基础。
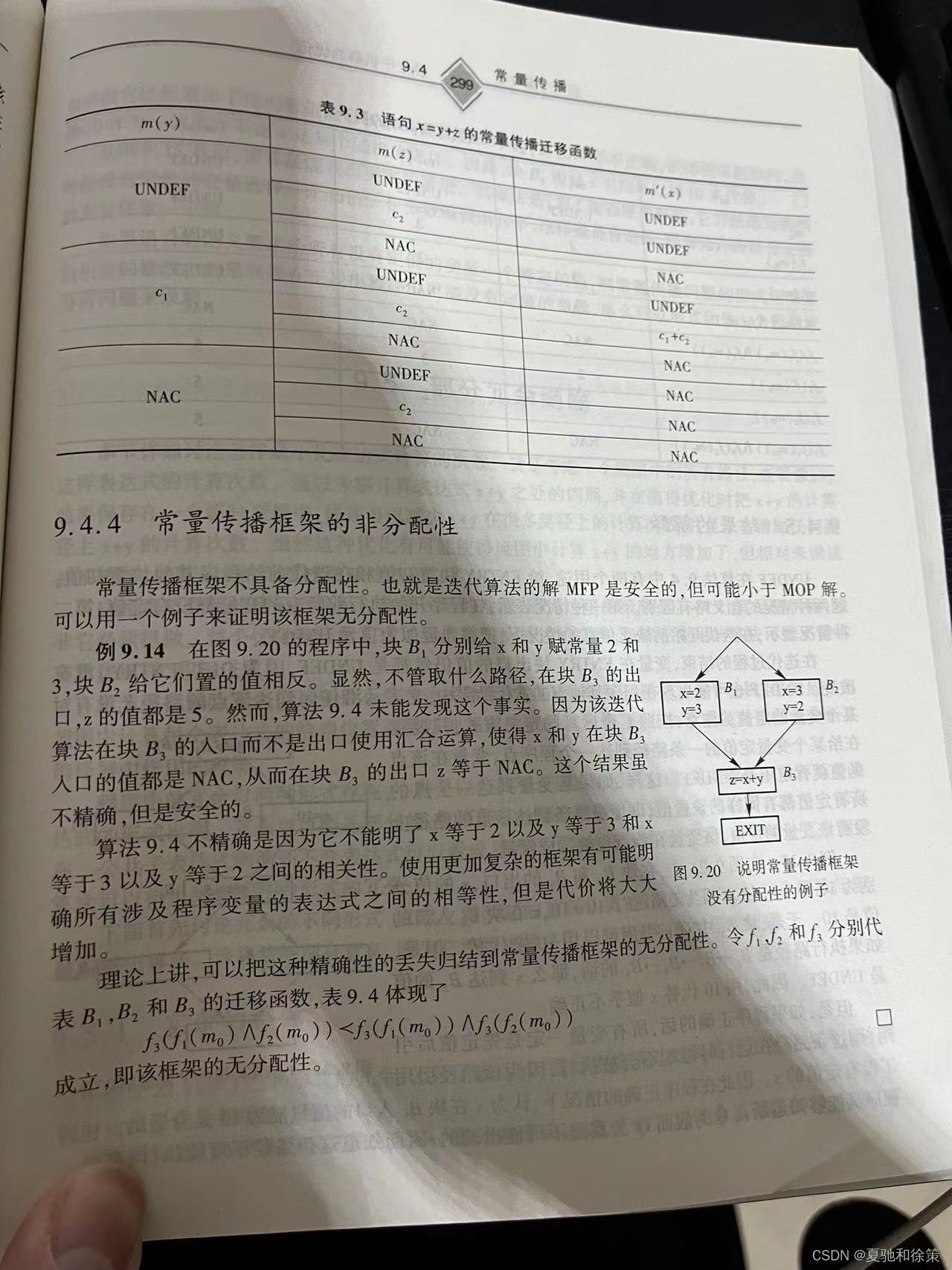
常量传播框架的非分配性分析
常量传播是编译器优化中一种重要的技术,用于在编译时期确定程序中变量的常量值。这项技术可以显著提高程序执行的效率,通过减少运行时的计算量。然而,常量传播框架的一个关键特性是其非分配性,这可能导致算法在某些情况下无法达到最优的精确性,尽管保持了结果的安全性。
非分配性的定义
在数据流分析中,分配性是指当一个迁移函数应用于两个或多个汇合运算的结果时,与分别对每个结果应用迁移函数再进行汇合运算的结果相同。即,迁移函数与汇合运算之间存在一种分配律。当一个数据流分析框架不满足这一性质时,我们称其为非分配性的。
常量传播框架的非分配性
常量传播框架的非分配性意味着,在处理分支结构时,即使所有路径最终导致相同的结果,迭代算法也可能无法识别这一点,从而导致过于保守的估计。
非分配性的示例
考虑图9.20中的例子,其中有两个基本块B1和B2,分别给变量x和y赋予了常量值2和3,以及相反的值3和2。在块B3中,无论哪条路径被执行,z的值都应该是5。然而,由于常量传播框架的非分配性,迭代算法无法识别这一点,在块B3入口将x和y的值都评估为NAC,因此在B3的出口z也被评估为NAC。
非分配性的影响
这个例子清楚地展示了非分配性如何影响常量传播框架的精确性。尽管算法的结果是安全的,即它不会导致错误的优化,但它未能利用所有可用的信息来达到最优的优化效果。这种情况下的保守估计阻止了对z=x+y的优化。
应对非分配性的挑战
为了提高常量传播的精度,可以考虑使用更复杂的分析框架,这些框架能够识别并利用程序变量之间的复杂关系。然而,这种方法的代价是显著增加的计算复杂度。因此,在设计编译器优化策略时,需要在计算效率和优化精度之间进行权衡。
结论
常量传播框架的非分配性是一种重要的特性,它限制了算法在处理分支和合并路径时的精确性。通过理解这一特性,编译器设计者可以更好地评估常量传播策略的适用性和限制,从而设计出既高效又准确的优化策略。

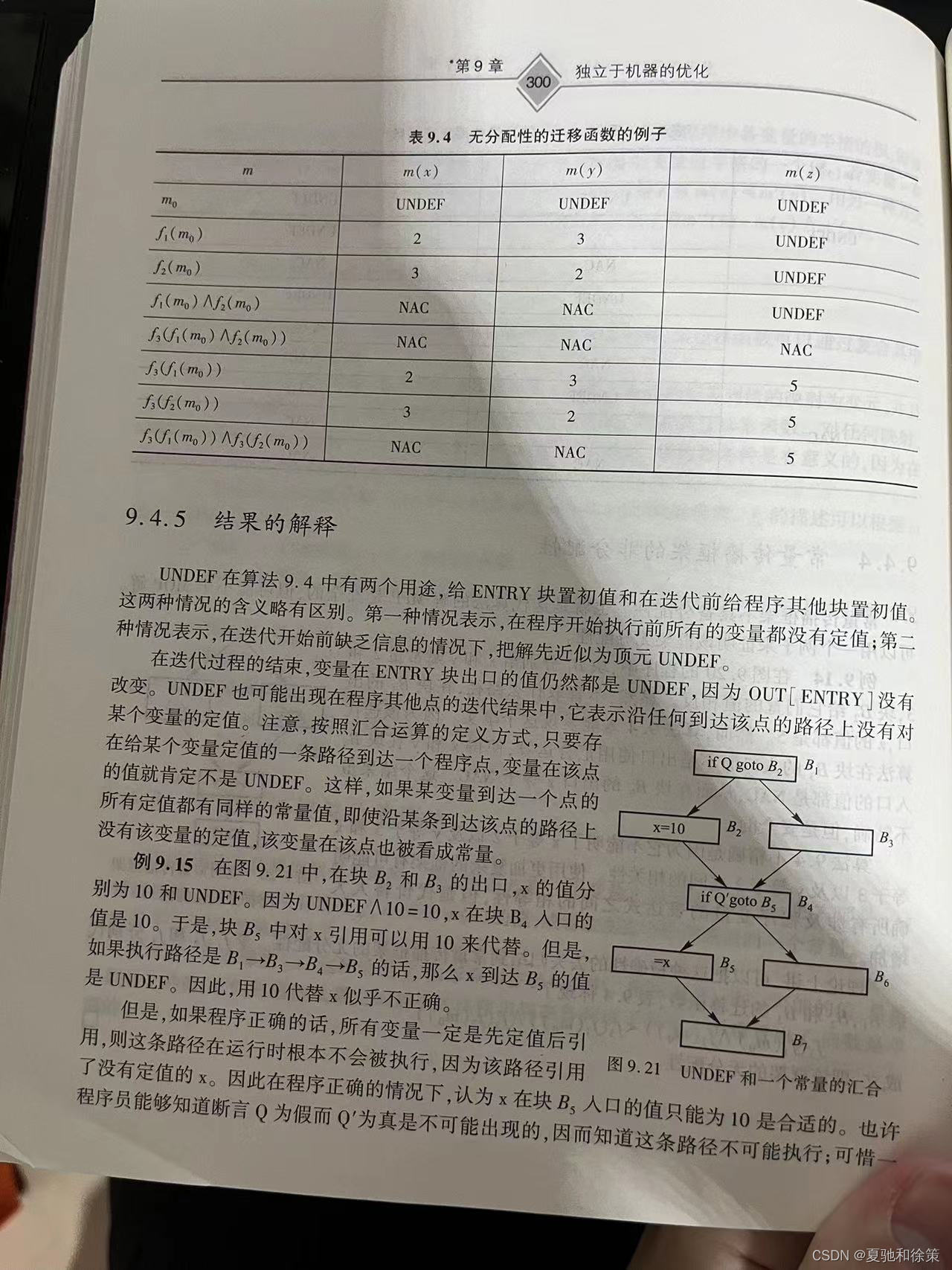
常量传播结果的解释与应用
常量传播算法是编译器优化技术中的一个重要组成部分,旨在编译时期识别和利用常量值,以优化程序执行。通过分析程序的控制流图和变量的赋值行为,该算法可以预测在程序的特定点变量是否可能拥有常量值。然而,对于算法产生的UNDEF结果,正确的理解和解释至关重要,以确保优化的正确性和效率。
UNDEF的双重含义
在常量传播算法中,UNDEF值扮演了两个关键角色:
- 程序开始前的状态:表明程序的起始状态下,所有变量都未被初始化,即没有任何定值。
- 迭代过程的初值:在算法迭代开始之前,由于缺乏足够信息,所有变量的值被近似设为
UNDEF,代表顶元。
UNDEF的处理
在迭代过程结束时,UNDEF的出现指示了两种情况:
- 变量在到达某个程序点的所有路径上都未被定义:此时,该变量在该点的值为
UNDEF。 - 变量在到达某个程序点的某些路径上被定义为同一常量值:即使存在未定义该变量的路径,该变量在该点也被视为该常量。
实例分析
考虑如下控制流图示例,在其中变量x在不同的基本块中被赋予不同的值或状态(如10和UNDEF)。算法识别出,尽管存在一条路径在该路径上x未被定义,但如果所有变量都按照“先定义后使用”的原则被正确使用,则在运行时不会执行到引用未定义变量x的路径。因此,将x在特定点视为常量10是合理的,即使存在未初始化x值的路径。
结论与应用
此分析揭示了常量传播算法在处理UNDEF时的灵活性和保守性。它能够在不牺牲程序正确性的前提下,通过假设变量在某些情况下为常量,优化程序执行。这种策略尤其适用于大多数编程语言,其中对未初始化变量的处理相对宽松。
然而,如果编程语言对未初始化变量有严格的要求,则可能需要调整常量传播算法,以适应语言的具体语义。此外,识别可能未初始化的变量也是另一个数据流分析问题,需要单独考虑和解决。
通过这种优化,编译器能够提高程序的执行效率,减少不必要的计算,同时保持优化结果的安全性和稳健性。

















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











