







📘 动手学深度学习 - 计算机视觉14.2:微调(Fine-tuning)
✍️ 本节笔记基于《动手学深度学习》第14章“计算机视觉”的 14.2 小节,内容聚焦于如何使用迁移学习进行模型微调(Fine-tuning),并通过“热狗识别”实战案例来加深理解。
1️⃣ 背景介绍
在实际应用中,我们往往面对的是 中小规模数据集,介于如 Fashion-MNIST(仅6万张图像)和 ImageNet(千万级大规模数据)之间。如果直接从头训练深度模型,极易出现过拟合,效果也难以令人满意。
例如:我们想构建一个识别不同椅子种类的模型,手动收集100种椅子、拍摄1000张图片,显然不现实。
💡 解决思路:
-
方案一:扩大数据集,但成本高昂。
-
✅ 方案二:迁移学习 + 微调技术,将大规模数据集上预训练的模型“迁移”到新任务中。
2️⃣ 微调的四个步骤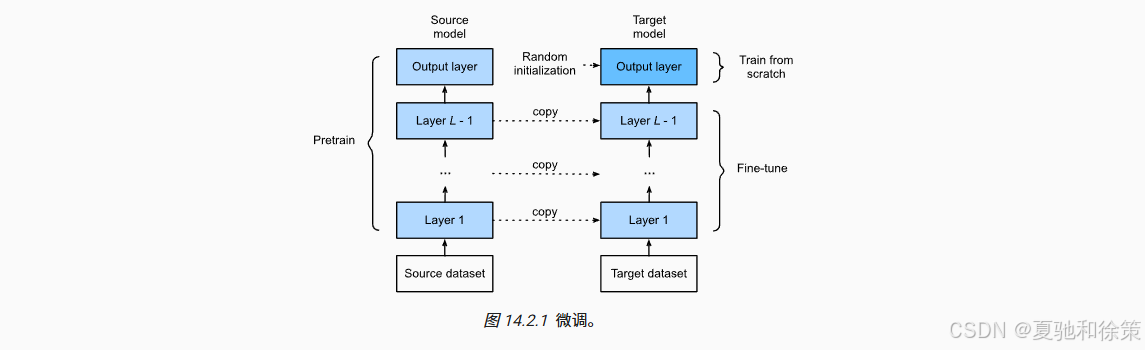
如下图所示(图 14.2.1),微调一般遵循四个关键步骤:
📌 Step 1:选择源模型
如使用在 ImageNet 上训练好的 ResNet18、VGG 等经典模型。
📌 Step 2:复制模型结构
保留所有原模型层(除了最后一层),即 feature extractor,它学到的是“通用视觉特征”。
📌 Step 3:替换输出层
将原有输出层替换为适用于新任务的类别数(如热狗 vs 非热狗 → 2类),并随机初始化。
📌 Step 4:训练新任务
-
只对新任务的输出层进行大学习率训练;
-
其他层则以较小的学习率进行微调,保留其在源数据集上的知识。
3️⃣ 热狗识别实战案例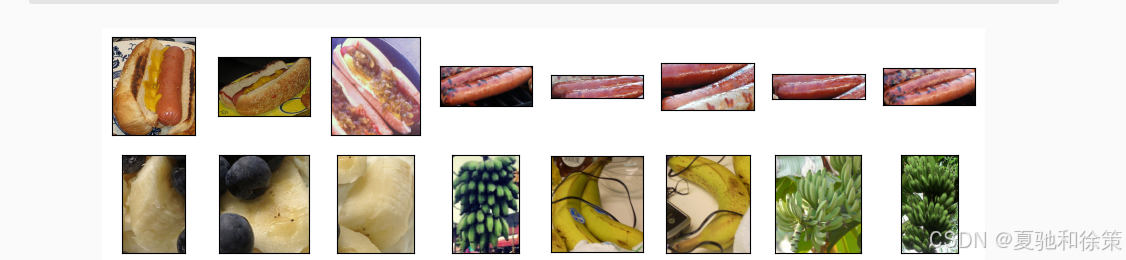
为了验证微调的效果,书中使用了一个趣味案例:识别热狗 vs 非热狗图像
🔧 数据准备
-
共2800张图片(正类1400热狗 / 负类1400非热狗),1000用于训练,400用于测试。
-
使用
torchvision.datasets.ImageFolder载入。 -
数据增强:
-
训练集:
RandomResizedCrop、HorizontalFlip、标准化 -
测试集:
Resize → CenterCrop、标准化
-
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
4️⃣ 微调模型训练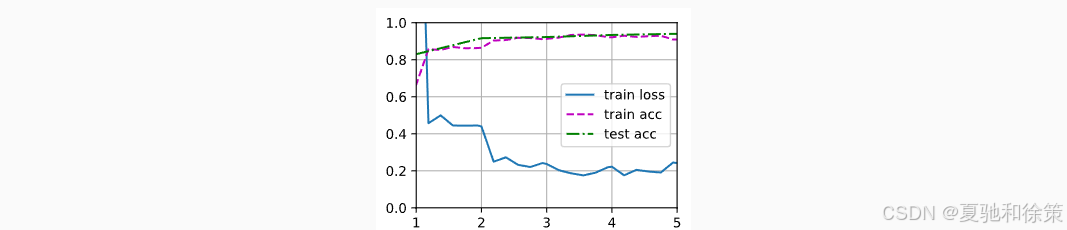
🧠 微调模型(finetune_net)
-
加载预训练的 ResNet18 模型(
pretrained=True) -
替换
fc层为二分类输出(2个神经元) -
对
fc使用较大学习率(×10),其余层使用较小学习率
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
🆚 从头训练模型(scratch_net)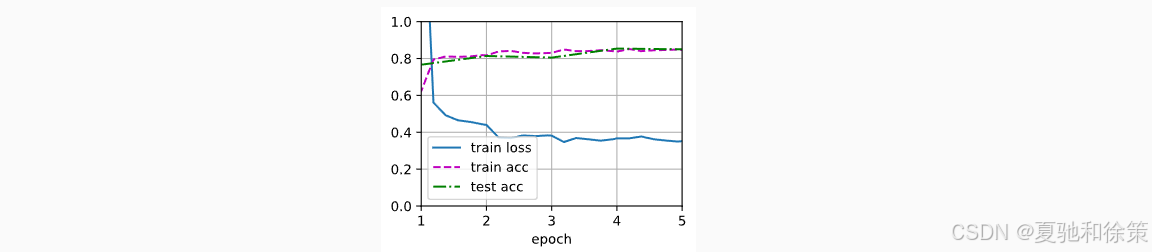
-
同样使用 ResNet18,但不加载预训练参数
-
全部参数都随机初始化,使用统一较大学习率
5️⃣ 实验结果对比
| 模型 | Loss | Train Acc | Test Acc |
|---|---|---|---|
微调模型 finetune_net | 0.242 | 90.9% | 94.0% |
随机初始化模型 scratch_net | 0.352 | 84.6% | 85.0% |
📊 结论:在相同训练轮数下,微调模型表现显著优于随机初始化的模型,迁移学习有效提升了泛化能力。
6️⃣ 小结与思考
-
微调是一种经典的迁移学习策略。
-
利用大规模数据集上预训练的模型作为“视觉特征提取器”。
-
在小数据集任务中,不仅节省训练时间,还显著提高精度。
-
输出层需要重新训练,其他层可微调或冻结,具体策略依据数据量和任务难度而定。
📌 延伸思考(练习题建议)
-
冻结除了输出层外的全部参数,模型性能是否变化?
-
微调学习率设置为统一值,是否影响训练速度与最终精度?
-
如何复用预训练模型中的某一类权重(例如 ImageNet 中 hotdog 类)来辅助目标任务?
如果你觉得这篇博客对你有帮助,欢迎点赞、评论交流!🚀
后续我们将进入《动手学深度学习》第14章更多实战任务,比如目标检测、迁移路径分析等,敬请期待!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











