







🌌 新所得库 - 深度学习中的词嵌入:word2vec 理论与实战全解析
15.1. 词嵌入(word2vec)
自然语言是人类交流中最复杂的系统之一,而词语则是表达意义的最基本单位。将每个词转化为向量,使其能被神经网络等模型处理,是自然语言处理的关键任务之一。
**词嵌入(word embedding)**的目标是:将词语映射为稠密的、可学习的实数向量,捕捉它们之间的语义相似性。
理论理解:
词嵌入是将离散的词语映射为连续的实数向量的技术,是深度学习中对语言建模的基础操作。相比 One-Hot,词嵌入能表达语义信息。
实战理解:
-
Google:在 Google Translate 中,词嵌入用于建构词级语义空间,使翻译模型能够理解不同语言词汇的内在关联。
-
字节跳动:在推荐系统(如抖音短视频推荐)中将用户行为序列中的“点击词”与内容关键词嵌入统一语义空间,用于语义召回。
-
OpenAI:GPT 采用 embedding + positional encoding 作为输入的第一层,词嵌入质量直接决定语义理解上限。
15.1.1. 独热向量是一个糟糕的选择
在早期(如 9.5 节),我们使用 One-Hot 向量表示词语:每个词用一个长度为词典大小的向量表示,其中仅一个维度为 1,其余为 0。这种方式虽然简单,但存在重大缺陷:
-
所有词之间的余弦相似度均为 0;
-
无法度量语义相似性;
-
稀疏高维,计算成本高。
这意味着 One-Hot 编码不能反映“king” 和 “queen” 或 “apple” 和 “banana” 之间的关联。
💡 在实际工程中(如字节推荐系统),这会造成模型对“相关词”理解能力薄弱,影响召回质量。
理论理解:
One-Hot 向量不具备词与词之间的语义关系。它导致的一个重要缺陷是:所有词之间的余弦相似度恒为 0,无法建模词义接近性。
实战理解:
-
百度:在搜索排序系统中,一旦关键词相似性无法捕捉,会导致召回系统精度骤降。百度搜索很早就使用了基于词嵌入的向量检索。
-
Amazon/AWS:基于词向量的搜索系统允许模糊匹配(如“cheap phone” 召回 “budget smartphone”),提升转化率。
15.1.2. 自监督 word2vec
为了解决上述问题,Google 提出了 word2vec 工具,它通过无监督方式训练词向量,使得语义相近的词在向量空间中彼此靠近。
word2vec 提供两种模型:
-
Skip-Gram:用中心词预测上下文词;
-
CBOW(Continuous Bag of Words):用上下文词预测中心词。
其核心思想是:上下文共现关系中蕴含语义关联。例如,“the man loves his son” 中,“loves” 与 “his” 更可能出现在一起,而非“banana”。
🏭 字节/阿里在构建语义推荐系统时,也使用 word2vec 训练上亿规模语料中的关键词表示,以实现推荐内容理解。
理论理解:
Word2Vec 是一种自监督学习方法,通过预测上下文词(或中心词)来学习词表示。训练数据来自于大规模语料的自然共现关系,不依赖人工标签。
实战理解:
-
字节跳动:训练超大规模语料的词嵌入模型(例如百万视频标题),用于语义聚类和热词发现。
-
Google:其词向量模型是 Google News 上训练的,影响了整个 NLP 社区十年。
-
NVIDIA:在构建文本图谱、对话系统等任务中,将 Word2Vec 与实体链接共同使用,构建结构化语义图谱。
15.1.3. Skip-Gram 模型
Skip-Gram 假设中心词可以生成上下文。例如:
输入句子:“the man loves his son”,中心词设为“loves”,窗口大小为 2,预测上下文为:“the”、“man”、“his”、“son”。
模型目标是最大化给定中心词生成上下文词的概率:
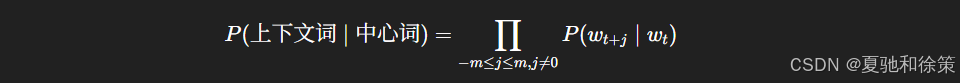
每个词在词表中拥有两个向量表示:一个作为中心词(输入向量),一个作为上下文词(输出向量)。条件概率通过 softmax 计算:
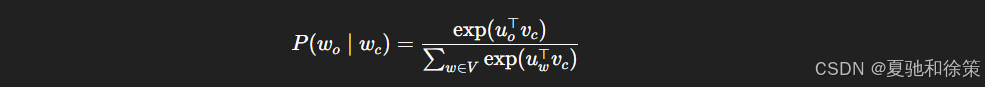
理论理解:
Skip-Gram 的目标是“中心词 ➡️ 上下文词”。核心思想是,语义接近的词将具有相似的上下文,因此训练模型预测上下文能内化这种语义信息。
其损失函数形式是所有上下文词条件概率的负对数求和,常用 softmax 或 negative sampling 优化。
实战理解:
-
腾讯 QQ 浏览器推荐系统:使用 Skip-Gram 对新闻词语建模,构建词向量热力图,用于实时推荐。
-
Facebook AI Research(FAIR):将 Skip-Gram 用于用户行为路径建模,构建“兴趣向量”,用于广告推荐。
-
百度百科:用于术语之间的关系分析,训练“词向量地图”,发现实体之间的近似概念。
15.1.3.1. 训练
模型训练的目标是最大化似然函数,对应损失函数为负对数似然:
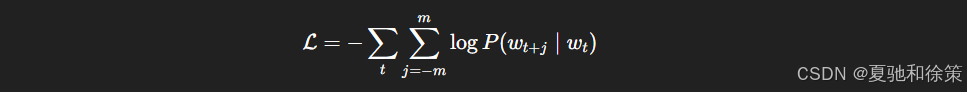
由于 softmax 的分母计算开销极大(词表往往上百万),采用以下优化:
-
负采样(Negative Sampling):每次仅计算少量负样本的点积;
-
层次 Softmax:用二叉树代替词表遍历。
更新时,计算该损失对中心词向量 vcv_c 和上下文词向量 uou_o 的梯度:
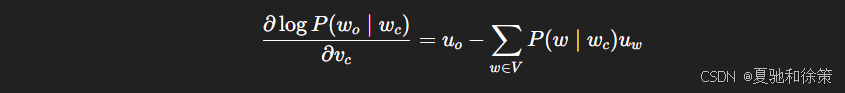
⚙️ 工程实践(如 NVIDIA NeMo)中,用 C++ 实现梯度累积和优化,加速千万级语料训练。
理论理解:
使用最大似然估计来训练模型,即最大化上下文词的出现概率。为了加速 softmax 计算,引入负采样方法降低计算复杂度。
实战理解:
-
Google:使用 hierarchical softmax 在大词表上训练,替代全词表计算。
-
字节跳动:采用异步多机分布式训练策略,将大规模语料切片并行训练,显著提升收敛速度。
-
NVIDIA NeMo:在 NLP 框架中提供了高度优化的 Word2Vec GPU 训练模块,支持万亿词级别建模。
15.1.4. 连续词袋模型(CBOW)
CBOW 与 Skip-Gram 相反:它假设中心词是由上下文词生成的。
仍以上文为例,用“the”、“man”、“his”、“son” 预测中心词 “loves”,其条件概率形式为:
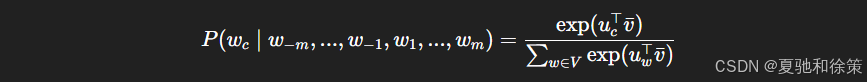
其中 vˉ\bar{v} 为上下文词向量的平均。
理论理解:
CBOW 与 Skip-Gram 相反,“上下文词 ➡️ 中心词”。将多个上下文词的向量平均作为输入,用来预测中心词。
虽然损失一点精度,但训练更快,特别适合大规模语料。
实战理解:
-
美团:用于商品查询推荐系统,CBOW 对商品词训练嵌入,提升搜索语义召回能力。
-
Google BERT Pretraining:BERT 的 Masked Language Model 本质上是改良版的 CBOW,预测被掩码的词。
-
OpenAI:训练 GPT 初期也曾评估过 CBOW 作为初始化嵌入方式,但由于上下文建模能力弱,最终放弃。
15.1.4.1. 训练
与 Skip-Gram 类似,CBOW 训练目标为最大化中心词的条件概率,对应损失函数为:
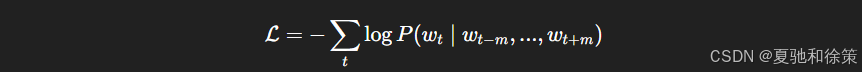
梯度更新时的偏导数如下:
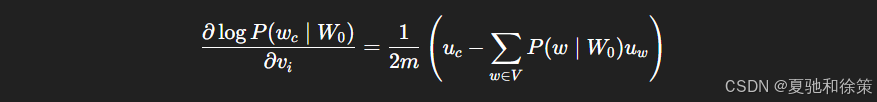
🧠 实战中,CBOW 常用于大规模语料(如阿里商品标题建模),因其训练速度更快、收敛更稳。
理论理解:
同样使用最大似然训练,但 CBOW 的输入是多个上下文词向量的平均,输出是一个中心词。优化方式基本一致,也支持负采样。
实战理解:
-
京东:商品描述标签训练 CBOW 向量,用于类目归一化和推荐系统冷启动。
-
微软必应搜索:用 CBOW 模型构建 query vector,用于向量召回候选集合,优化语义检索体验。
15.1.5. 小结
-
词嵌入是自然语言处理的关键技术;
-
Word2Vec 提供 Skip-Gram 和 CBOW 两种建模方式;
-
Skip-Gram 适合小数据+精度需求高场景;
-
CBOW 更适合大语料+训练效率要求场景;
-
两者均为无监督建模,捕捉上下文语义关系。
理论理解:
-
Word2Vec 是词向量学习的基础方法;
-
Skip-Gram 保留语义更好,适合精度需求高场景;
-
CBOW 训练更快,适合大规模工程应用;
-
都属于自监督范式,无需人工标注。
实战理解:
-
BAT & Google:都将词嵌入作为推荐系统、语义理解、搜索召回的基础模块;
-
OpenAI:BERT、GPT 等模型的输入层本质是“嵌入层”,它继承了 Word2Vec 的思想但做了更深建模;
-
阿里巴巴:大规模商品图谱构建中,用词向量构建商品关联网络。
15.1.6. 练习与思考
-
Softmax 的时间复杂度是多少?为什么负采样能加速?
-
“New York” 如何训练成整体向量?是否可以将短语作为 Token 预处理?
-
Skip-Gram 中的点积和余弦相似度之间的关系是什么?为什么语义相似的词点积更高?
是否继续撰写下一节:15.2 GloVe 全局词向量模型解析?还是你想结合当前 word2vec 写一篇企业级工程实战经验(比如推荐系统中的嵌入工程实践)?




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











