








SpringMVC_day02
今日内容
完成SSM的整合开发
能够理解并实现统一结果封装与统一异常处理
能够完成前后台功能整合开发
掌握拦截器的编写
1,SSM整合
前面我们已经把Mybatis、Spring和SpringMVC三个框架进行了学习,今天主要的内容就是把这三个框架整合在一起完成我们的业务功能开发,具体如何来整合,我们一步步来学习。
1.1 流程分析
(1) 创建工程
-
创建一个Maven的web工程
-
pom.xml添加SSM需要的依赖jar包
-
编写Web项目的入口配置类,实现
AbstractAnnotationConfigDispatcherServletInitializer重写以下方法-
getRootConfigClasses() :返回Spring的配置类->需要==SpringConfig==配置类
-
getServletConfigClasses() :返回SpringMVC的配置类->需要==SpringMvcConfig==配置类
-
getServletMappings() : 设置SpringMVC请求拦截路径规则
-
getServletFilters() :设置过滤器,解决POST请求中文乱码问题
-
🧠 理论理解
搭建项目工程是任何开发的第一步。采用 Maven 管理 Web 项目,可以带来模块化依赖、版本控制、可移植性和更强的构建工具支持,适用于团队协作开发与 CI/CD 自动化。
🏢 大厂实战理解
-
阿里巴巴:大规模工程采用 Maven + Gradle 混合构建,结合自研 POM 模板和依赖仓库,实现多项目多团队协作。
-
字节跳动:字节内部工程使用统一的骨架脚手架,快速生成 Maven 项目结构,并自动接入代码扫描与 CI。
-
Google:Google 内部使用 Bazel 替代 Maven,但项目创建仍强调模块化依赖,确保构建的高效与可扩展。
(2)SSM整合[==重点是各个配置的编写==]
-
SpringConfig
-
标识该类为配置类 @Configuration
-
扫描Service所在的包 @ComponentScan
-
在Service层要管理事务 @EnableTransactionManagement
-
读取外部的properties配置文件 @PropertySource
-
整合Mybatis需要引入Mybatis相关配置类 @Import
-
第三方数据源配置类 JdbcConfig
-
构建DataSource数据源,DruidDataSouroce,需要注入数据库连接四要素, @Bean @Value
-
构建平台事务管理器,DataSourceTransactionManager,@Bean
-
-
Mybatis配置类 MybatisConfig
-
构建SqlSessionFactoryBean并设置别名扫描与数据源,@Bean
-
构建MapperScannerConfigurer并设置DAO层的包扫描
-
-
-
-
SpringMvcConfig
-
标识该类为配置类 @Configuration
-
扫描Controller所在的包 @ComponentScan
-
开启SpringMVC注解支持 @EnableWebMvc
-
🧠 理论理解
Spring、SpringMVC 和 MyBatis 三者功能不同,整合时需合理划分配置层:Spring 管理业务与事务、SpringMVC 管理 Web 层、MyBatis 管理数据持久化。这要求清晰分离配置,防止相互干扰,提高可维护性和灵活性。
🏢 大厂实战理解
-
腾讯:为大促等高并发场景,将 SSM 结构整合为微服务,结合 Spring Cloud,配置拆分为多级(微服务级、模块级、基础设施级)。
-
字节跳动:在大流量场景下,通过定制 Spring + MyBatis 配置,采用多数据源、动态切换等高级特性。
-
OpenAI:对接 GPT 模型时,虽然用的是 Python/Go,但同样注重后端配置分层,保障扩展性和快速更新。
(3)功能模块[与具体的业务模块有关]
-
创建数据库表
-
根据数据库表创建对应的模型类
-
通过Dao层完成数据库表的增删改查(接口+自动代理)
-
编写Service层[Service接口+实现类]
-
@Service
-
@Transactional
-
整合Junit对业务层进行单元测试
-
@RunWith
-
@ContextConfiguration
-
@Test
-
-
-
编写Controller层
-
接收请求 @RequestMapping @GetMapping @PostMapping @PutMapping @DeleteMapping
-
接收数据 简单、POJO、嵌套POJO、集合、数组、JSON数据类型
-
@RequestParam
-
@PathVariable
-
@RequestBody
-
-
转发业务层
-
@Autowired
-
-
响应结果
-
@ResponseBody
-
-
🧠 理论理解
模块化设计保证业务独立、职责单一,有利于团队分工、并行开发。功能模块如用户模块、订单模块、商品模块要严格依赖接口,遵循松耦合、高内聚设计。
🏢 大厂实战理解
-
阿里:模块化划分非常清晰,结合 DDD(领域驱动设计)与中台化思想,形成可复用的业务中台。
-
NVIDIA:在云平台(如 GPU 云租赁服务)中,模块化拆分为租赁、账单、监控、权限,确保高可靠可扩展。
-
Google:其大规模软件架构中,每个功能模块都在独立仓库或独立模块管理,防止跨模块依赖混乱。
面试题1:
阿里巴巴面试官问:
在企业级项目中,Maven 构建工具相比 Gradle 有哪些优势和劣势?为什么很多国内大厂依然选择 Maven?
答:
Maven 的优势主要体现在:
-
社区成熟,生态完善,有大量成熟插件(如 shade、surefire、jacoco);
-
企业内部大量现成 POM 模板和最佳实践;
-
对传统 Java 项目(如 Spring、MyBatis、SpringMVC)支持良好,团队成员上手门槛低;
-
与 Jenkins、GitLab CI 等 CI 工具无缝集成。
劣势是:
-
配置灵活性不足(不如 Gradle 的 Groovy/Kotlin 脚本化);
-
构建性能相对较慢,尤其是复杂多模块工程;
-
不支持细粒度的增量构建。
很多国内大厂(如阿里、腾讯、字节)依然偏好 Maven,是因为:
-
大量历史工程积累在 Maven 上,迁移成本高;
-
团队有统一的依赖仓库和私有插件,生态基于 Maven;
-
招聘和培训中,开发者普遍对 Maven 更熟悉。
不过,也有公司(比如字节在部分新项目)开始引入 Gradle,用于 Android 项目和部分复杂微服务工程。
1️⃣ 场景题:阿里巴巴 - 天猫大促商品系统的 SSM 整合挑战
🛒 背景:
阿里巴巴天猫团队要为双十一开发一个商品管理系统,需要支持千万级商品的查询、上下架、修改、删除,要求系统必须高可用、高并发,后台采用 SSM 框架。
🧩 挑战点:
-
商品列表查询量巨大,分页查询接口承压严重。
-
MyBatis 查询的 SQL 存在 N+1 查询和慢查询风险。
-
Spring 事务注解 @Transactional 使用不当,导致数据库死锁。
-
SpringMVC Controller 层缺乏限流、幂等性控制,出现重复提交问题。
🔧 问题:
你作为程序猿,需要回答:
1️⃣ 如何设计 Controller、Service、Dao 三层,确保代码层级职责清晰、事务安全?
2️⃣ 如何优化 MyBatis 查询性能,尤其是防止 N+1 查询?
3️⃣ 面对高并发请求,SpringMVC 层如何配合限流和幂等性设计,减少数据库压力?
4️⃣ 如何借助缓存(如 Redis)或中间件,提高系统整体响应速度?
回答:
1️⃣ 我们必须严格分层:
-
Controller 只负责接收请求、参数校验、响应封装,绝不能写业务逻辑。
-
Service 处理业务场景,@Transactional 也只加在 Service,不要加在 Controller。
-
Dao 层专注数据库操作,绝不能引入业务判断。
这样可以避免事务混乱、分层紊乱。
2️⃣ MyBatis 查询优化:我会优先用 mapper.xml 里定义的 association、collection 标签解决 N+1 问题,同时加上合理的 join 查询。对热点数据,我还会评估是否用缓存(Redis 缓存结果集)。
3️⃣ 高并发下,SpringMVC 层要加拦截器或注解限流(比如结合 Guava RateLimiter 或 Sentinel)。同时,像商品上下架这种幂等性接口,我会用防重令牌(提交时带唯一 token,消费一次即失效)。
4️⃣ 我们会用缓存做读写分离:商品详情、列表页等高频读请求,用 Redis;库存扣减、订单生成用异步队列,削峰填谷。通过缓存 + 队列组合,才能顶住双11的流量洪峰。
1.2 整合配置
掌握上述的知识点后,接下来,我们就可以按照上述的步骤一步步的来完成SSM的整合。
步骤1:创建Maven的web项目
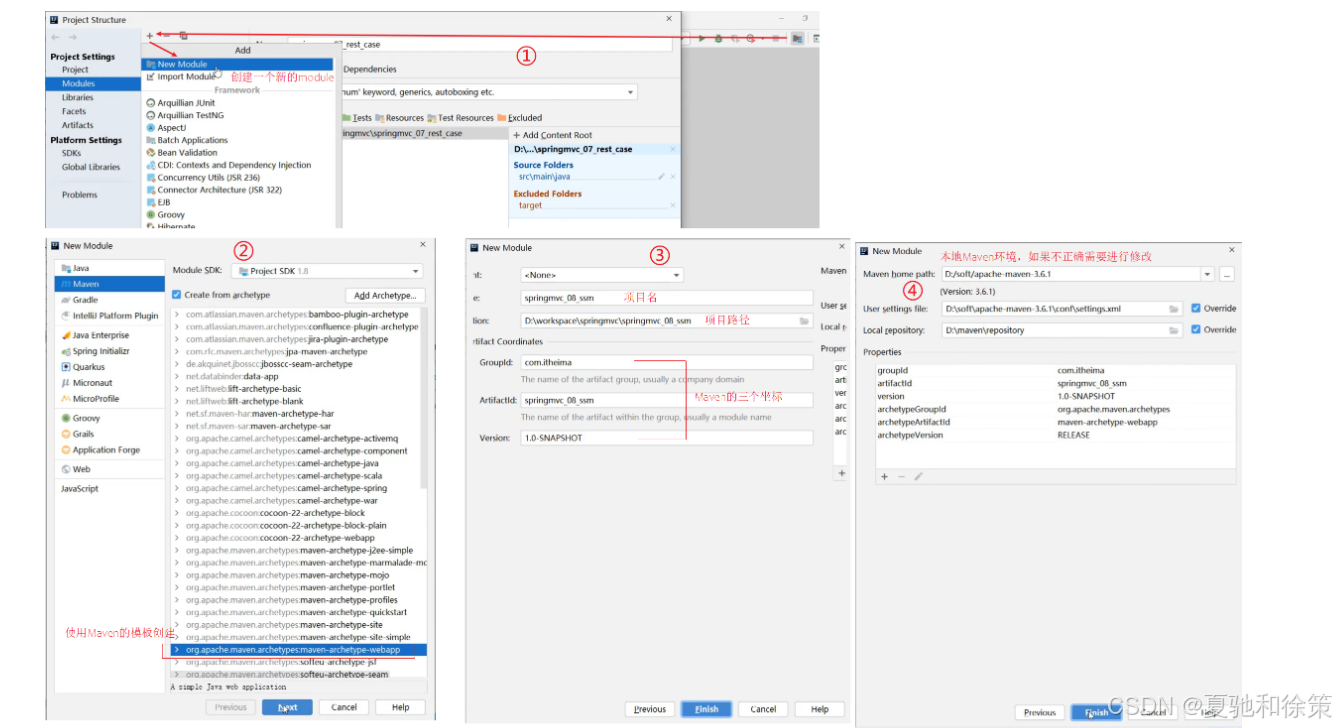
可以使用Maven的骨架创建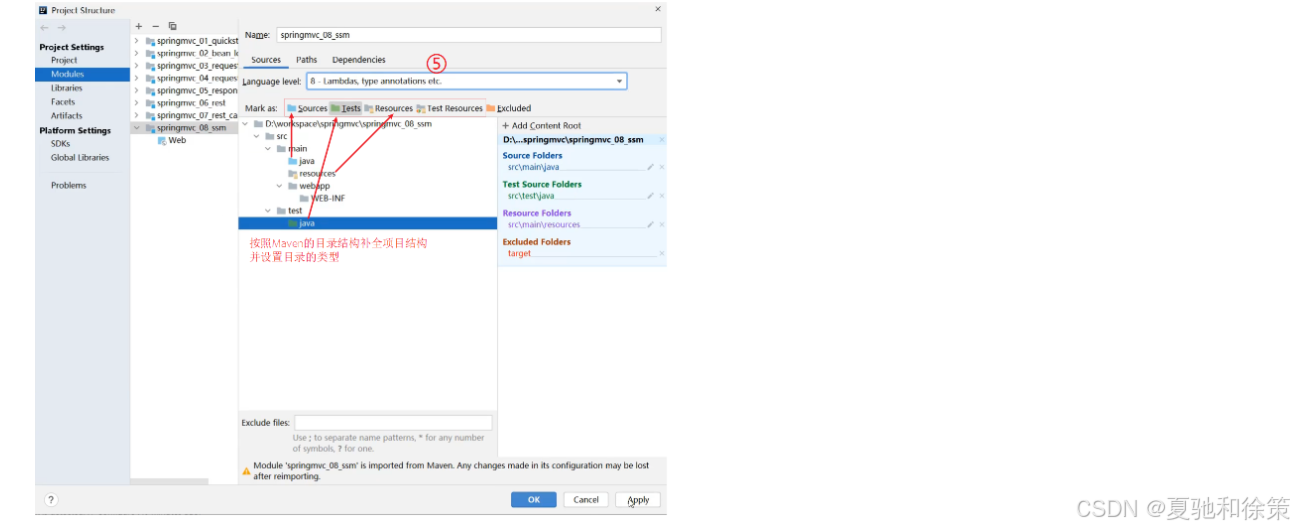
🧠 理论理解
选择 Maven 项目可以轻松管理依赖、插件、生命周期。Maven Web 项目模板提供标准目录结构(src/main/java、src/main/resources、src/main/webapp),方便团队协作和工具链集成。
🏢 大厂实战理解
-
字节跳动:通过内部 Maven 镜像与自研插件(如代码扫描、依赖合规检查)创建项目,提升初始化效率。
-
阿里巴巴:使用 Maven 结合 GitFlow 分支管理模型,保障多人开发时的版本一致性。
-
OpenAI:即使使用 Python 和 Go,项目初始化也强调标准化目录,便于与 Docker/Kubernetes 集成。
步骤2:添加依赖
pom.xml添加SSM所需要的依赖jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itheima</groupId>
<artifactId>springmvc_08_ssm</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.1</version>
<configuration>
<port>80</port>
<path>/</path>
</configuration>
</plugin>
</plugins>
</build>
</project>
步骤3:创建项目包结构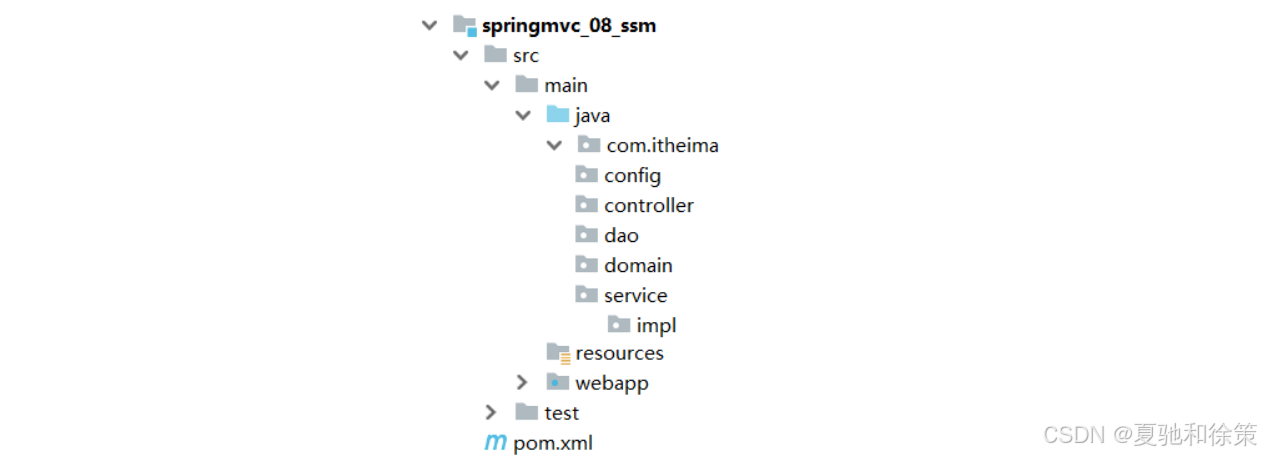
-
config目录存放的是相关的配置类
-
controller编写的是Controller类
-
dao存放的是Dao接口,因为使用的是Mapper接口代理方式,所以没有实现类包
-
service存的是Service接口,impl存放的是Service实现类
-
resources:存入的是配置文件,如Jdbc.properties
-
webapp:目录可以存放静态资源
-
test/java:存放的是测试类
步骤4:创建SpringConfig配置类
@Configuration
@ComponentScan({"com.itheima.service"})
@PropertySource("classpath:jdbc.properties")
@Import({JdbcConfig.class,MyBatisConfig.class})
@EnableTransactionManagement
public class SpringConfig {
}步骤5:创建JdbcConfig配置类
public class JdbcConfig {
@Value("${jdbc.driver}")
private String driver;
@Value("${jdbc.url}")
private String url;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource dataSource(){
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driver);
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
return dataSource;
}
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource){
DataSourceTransactionManager ds = new DataSourceTransactionManager();
ds.setDataSource(dataSource);
return ds;
}
}步骤6:创建MybatisConfig配置类
public class MyBatisConfig {
@Bean
public SqlSessionFactoryBean sqlSessionFactory(DataSource dataSource){
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
factoryBean.setTypeAliasesPackage("com.itheima.domain");
return factoryBean;
}
@Bean
public MapperScannerConfigurer mapperScannerConfigurer(){
MapperScannerConfigurer msc = new MapperScannerConfigurer();
msc.setBasePackage("com.itheima.dao");
return msc;
}
}步骤7:创建jdbc.properties
在resources下提供jdbc.properties,设置数据库连接四要素
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/ssm_db
jdbc.username=root
jdbc.password=root步骤8:创建SpringMVC配置类
@Configuration
@ComponentScan("com.itheima.controller")
@EnableWebMvc
public class SpringMvcConfig {
}步骤9:创建Web项目入口配置类
public class ServletConfig extends AbstractAnnotationConfigDispatcherServletInitializer {
//加载Spring配置类
protected Class<?>[] getRootConfigClasses() {
return new Class[]{SpringConfig.class};
}
//加载SpringMVC配置类
protected Class<?>[] getServletConfigClasses() {
return new Class[]{SpringMvcConfig.class};
}
//设置SpringMVC请求地址拦截规则
protected String[] getServletMappings() {
return new String[]{"/"};
}
//设置post请求中文乱码过滤器
@Override
protected Filter[] getServletFilters() {
CharacterEncodingFilter filter = new CharacterEncodingFilter();
filter.setEncoding("utf-8");
return new Filter[]{filter};
}
}
至此SSM整合的环境就已经搭建好了。在这个环境上,我们如何进行功能模块的开发呢?
面试题2:
字节跳动面试官问:
SSM 整合时,为什么要将 Spring、MyBatis、SpringMVC 配置分离,而不是放到一个配置文件中?
答:
配置分离的原因主要有以下几点:
1️⃣ 关注点分离(Separation of Concerns)
Spring 管理业务、事务和 Bean 容器,MyBatis 负责数据持久化,SpringMVC 负责 Web 层调度。放在一起容易导致配置膨胀,维护困难。分离后,每个配置文件只关注自身职责。
2️⃣ 解耦与模块化
分离配置使得模块之间解耦,便于重用。例如,业务模块可以单独复用 Spring + MyBatis,不依赖 SpringMVC。
3️⃣ 灵活扩展
在大厂场景下,通常会引入多数据源、读写分离、缓存等高级配置。独立配置文件可以按需扩展,而不是修改整体配置,降低出错风险。
4️⃣ 运维和配置管理
在字节等大厂,配置会接入配置中心(如 Apollo、Diamond),按模块下发。分离后的配置更易于动态管理和热更新。
因此,分离配置不仅是项目整洁的需求,更是企业级工程扩展性、运维能力的基石。
2️⃣ 场景题:字节跳动 - 抖音视频推荐后台的 SSM 架构优化
🎬 背景:
字节跳动的抖音推荐后台基于 SSM 架构,主要负责内容入库、视频元数据管理、推荐标签的更新与查询。近期系统承受了极大压力,尤其在热点内容(如网红挑战赛)发布期间,数据库频繁被打爆。
🧩 挑战点:
-
大量视频入库操作导致数据库连接池耗尽。
-
Spring 事务配置粒度太粗,导致热点表锁竞争。
-
MyBatis Mapper XML 动态 SQL 编写混乱,难以维护。
-
Controller 层和前端联调时缺乏统一的接口文档,接口频繁变动导致回归成本高。
🔧 问题:
你作为字节后端负责人,需要回答:
1️⃣ 如何优化 Spring DataSource 配置,确保高并发下数据库连接的稳定性?
2️⃣ 如何调整事务管理策略,将热点写操作分片或拆分?
3️⃣ MyBatis 大量动态 SQL 如何规范化、模板化,降低后续维护成本?
4️⃣ 如何引入 API 网关或接口文档平台,提升前后端协作效率?
2️⃣ 字节跳动 - 抖音视频推荐后台的 SSM 架构优化
💬 开发回答:
1️⃣ 高并发下,数据库连接池(Druid/HikariCP)必须配置合理:
-
最大连接数按 QPS × 处理时间估算;
-
打开连接泄漏检测、慢 SQL 日志。
同时业务代码中,绝不能自己反复开关连接。
2️⃣ 热点写操作要拆分,比如按标签、视频类型分库分表。事务粒度上,能局部提交就局部提交,避免大事务包住大量无关逻辑。
3️⃣ MyBatis 动态 SQL 混乱,最好引入代码模板或封装公共 SQL 片段(用 include、where 标签),每个团队都按统一规范编写。
4️⃣ 接口管理上,字节用的是 Swagger + YApi,前后端自动生成接口文档,有改动直接同步,这大大减少了沟通成本。
1.3 功能模块开发
需求:对表tbl_book进行新增、修改、删除、根据ID查询和查询所有
步骤1:创建数据库及表
create database ssm_db character set utf8;
use ssm_db;
create table tbl_book(
id int primary key auto_increment,
type varchar(20),
name varchar(50),
description varchar(255)
)
insert into `tbl_book`(`id`,`type`,`name`,`description`) values (1,'计算机理论','Spring实战 第五版','Spring入门经典教程,深入理解Spring原理技术内幕'),(2,'计算机理论','Spring 5核心原理与30个类手写实践','十年沉淀之作,手写Spring精华思想'),(3,'计算机理论','Spring 5设计模式','深入Spring源码刨析Spring源码中蕴含的10大设计模式'),(4,'计算机理论','Spring MVC+Mybatis开发从入门到项目实战','全方位解析面向Web应用的轻量级框架,带你成为Spring MVC开发高手'),(5,'计算机理论','轻量级Java Web企业应用实战','源码级刨析Spring框架,适合已掌握Java基础的读者'),(6,'计算机理论','Java核心技术 卷Ⅰ 基础知识(原书第11版)','Core Java第11版,Jolt大奖获奖作品,针对Java SE9、10、11全面更新'),(7,'计算机理论','深入理解Java虚拟机','5个纬度全面刨析JVM,大厂面试知识点全覆盖'),(8,'计算机理论','Java编程思想(第4版)','Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉'),(9,'计算机理论','零基础学Java(全彩版)','零基础自学编程的入门图书,由浅入深,详解Java语言的编程思想和核心技术'),(10,'市场营销','直播就这么做:主播高效沟通实战指南','李子柒、李佳奇、薇娅成长为网红的秘密都在书中'),(11,'市场营销','直播销讲实战一本通','和秋叶一起学系列网络营销书籍'),(12,'市场营销','直播带货:淘宝、天猫直播从新手到高手','一本教你如何玩转直播的书,10堂课轻松实现带货月入3W+');数据库及表
🧠 理论理解
建表时要考虑数据类型、主键、索引、字符集等;插入初始数据可用于开发联调。推荐使用 UTF-8 统一编码,防止多语言乱码问题。
🏢 大厂实战理解
-
阿里:上线前的数据库表设计必须走 DBA 审核和规范化检查,保证高性能和高可扩展性。
-
字节跳动:采用 Flyway/Liquibase 进行数据库版本管理和迁移。
-
NVIDIA:数据库设计时要考虑 GPU 资源调度、高并发下的事务一致性。
步骤2:编写模型类
public class Book {
private Integer id;
private String type;
private String name;
private String description;
//getter...setter...toString省略
}🧠 理论理解
Maven 的核心价值在于依赖管理和传递。添加 Spring、MyBatis、Druid、Jackson 等依赖需要注意版本兼容、冲突排查,并定期更新以修复安全漏洞。
🏢 大厂实战理解
-
腾讯云:统一管理 pom 依赖版本,避免出现多项目依赖版本冲突问题。
-
字节跳动:在 pom 文件中引入内部 BOM(Bill of Materials)进行全局依赖版本控制。
-
Google:尽管内部不用 Maven,但高度重视依赖版本和安全性,确保主干代码无高危漏洞。
步骤3:编写Dao接口
public interface BookDao {
// @Insert("insert into tbl_book values(null,#{type},#{name},#{description})")
@Insert("insert into tbl_book (type,name,description) values(#{type},#{name},#{description})")
public void save(Book book);
@Update("update tbl_book set type = #{type}, name = #{name}, description = #{description} where id = #{id}")
public void update(Book book);
@Delete("delete from tbl_book where id = #{id}")
public void delete(Integer id);
@Select("select * from tbl_book where id = #{id}")
public Book getById(Integer id);
@Select("select * from tbl_book")
public List<Book> getAll();
}🧠 理论理解
合理的包结构是代码可维护性的基础。推荐结构:controller、service、dao、domain、config、utils,各层职责清晰,防止交叉依赖。
🏢 大厂实战理解
-
美团:采用 DDD + 分模块(分包)设计,甚至使用多模块 Maven 工程划分上下游依赖。
-
NVIDIA:大项目中引入微服务,将单体包结构拆分为 API、Impl、Client 三层。
-
OpenAI:在服务层严格遵循 Clean Architecture,将核心逻辑、接口、基础设施层分离。
步骤4:编写Service接口和实现类
@Transactional
public interface BookService {
/**
* 保存
* @param book
* @return
*/
public boolean save(Book book);
/**
* 修改
* @param book
* @return
*/
public boolean update(Book book);
/**
* 按id删除
* @param id
* @return
*/
public boolean delete(Integer id);
/**
* 按id查询
* @param id
* @return
*/
public Book getById(Integer id);
/**
* 查询全部
* @return
*/
public List<Book> getAll();
}
@Service
public class BookServiceImpl implements BookService {
@Autowired
private BookDao bookDao;
public boolean save(Book book) {
bookDao.save(book);
return true;
}
public boolean update(Book book) {
bookDao.update(book);
return true;
}
public boolean delete(Integer id) {
bookDao.delete(id);
return true;
}
public Book getById(Integer id) {
return bookDao.getById(id);
}
public List<Book> getAll() {
return bookDao.getAll();
}
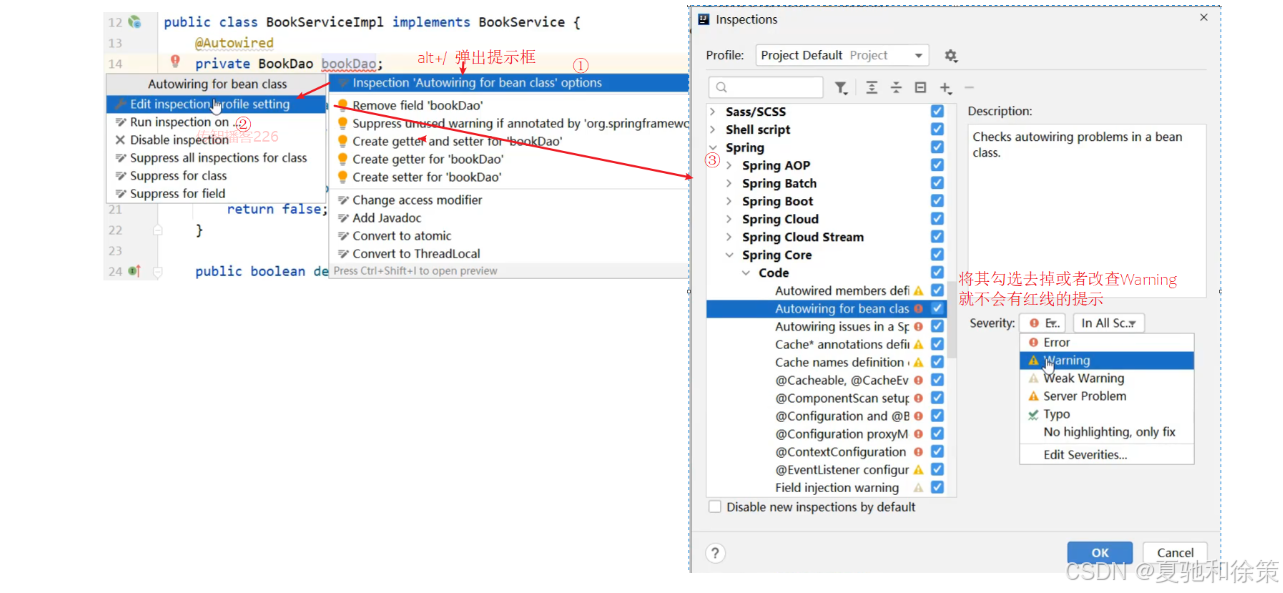
}说明:
-
bookDao在Service中注入的会提示一个红线提示,为什么呢?
-
BookDao是一个接口,没有实现类,接口是不能创建对象的,所以最终注入的应该是代理对象
-
代理对象是由Spring的IOC容器来创建管理的
-
IOC容器又是在Web服务器启动的时候才会创建
-
IDEA在检测依赖关系的时候,没有找到适合的类注入,所以会提示错误提示
-
但是程序运行的时候,代理对象就会被创建,框架会使用DI进行注入,所以程序运行无影响。
-
-
如何解决上述问题?
-
可以不用理会,因为运行是正常的
-
设置错误提示级别
-
🧠 理论理解
每个配置类要遵循单一职责、集中管理。Spring 管理业务与事务,Jdbc 管理数据库连接池,MyBatis 管理 SQLSession 工厂与 Mapper 扫描,SpringMVC 管理 Web 路由,Servlet 管理启动入口。整体要避免配置散落,防止耦合。
🏢 大厂实战理解
-
字节跳动:大规模项目中,配置统一托管到配置中心,动态下发,不写死在本地。
-
阿里巴巴:结合自研 Diamond 配置中心与 Spring Cloud Config,实现实时配置刷新。
-
Google:采用自研 Spinnaker + K8S ConfigMap,实现配置灰度、版本控制、回滚。
步骤5:编写Contorller类
@RestController
@RequestMapping("/books")
public class BookController {
@Autowired
private BookService bookService;
@PostMapping
public boolean save(@RequestBody Book book) {
return bookService.save(book);
}
@PutMapping
public boolean update(@RequestBody Book book) {
return bookService.update(book);
}
@DeleteMapping("/{id}")
public boolean delete(@PathVariable Integer id) {
return bookService.delete(id);
}
@GetMapping("/{id}")
public Book getById(@PathVariable Integer id) {
return bookService.getById(id);
}
@GetMapping
public List<Book> getAll() {
return bookService.getAll();
}
}对于图书模块的增删改查就已经完成了编写,我们可以从后往前写也可以从前往后写,最终只需要能把功能实现即可。
接下来我们就先把业务层的代码使用Spring整合Junit的知识点进行单元测试:
🧠 理论理解
按照 MVC 三层架构:模型类封装数据,DAO 接口封装持久层操作,Service 层封装业务逻辑,Controller 层对接前端请求,确保层次分明、解耦清晰。事务逻辑必须放在 Service 层。
🏢 大厂实战理解
-
字节跳动:Service 层会拆分为读服务和写服务,甚至独立部署,避免读写相互影响。
-
阿里巴巴:大流量场景下,DAO 层会接入缓存(如 Redis),降低 DB 压力。
-
Google:严格定义接口契约,采用接口隔离,防止直接跨层访问破坏架构。
面试题3:
腾讯面试官问:
SSM 项目中,Service 层为什么要加事务?为什么事务不能放在 Controller 或 DAO 层?
答:
Service 层加事务的原因有:
-
业务边界明确:事务的边界就是业务操作的边界。一个业务通常由多个 DAO 操作组成,应该由 Service 层统一控制事务,而不是 Controller(只负责接收请求)或 DAO(只负责单表操作)。
-
保证原子性:Service 层作为业务协调者,可以确保多步数据库操作的原子性。比如,用户下单要更新库存、生成订单、扣减余额,这些需要一起成功或一起回滚。
-
可维护性与解耦:如果把事务写在 Controller,会导致表现层和业务层耦合;如果写在 DAO,只能覆盖单个 SQL,无法保证跨 DAO 的一致性。
在大厂(如腾讯、阿里)中,事务管理不仅用 Spring @Transactional,还会结合分布式事务方案(如 Seata、TCC)处理跨服务事务,尤其是在微服务架构下。
3️⃣ 场景题:腾讯 - 微信支付后台的 SSM 模块化重构
💰 背景:
腾讯微信支付的后台系统最初采用 SSM 架构开发,随着业务发展逐渐膨胀,出现了:
-
Controller 层代码臃肿,缺乏统一规范;
-
Service 层包含大量与支付无关的杂项逻辑;
-
Dao 层 Mapper 写死 SQL,难以支持多数据源扩展。
🧩 挑战点:
-
支付业务必须高可用、强一致,但现有事务机制难以覆盖分布式场景。
-
多个微服务共享 SSM 模块代码,出现了版本依赖冲突。
-
单元测试覆盖率低,核心支付代码难以改造。
🔧 问题:
你作为腾讯高级开发工程师,需要回答:
1️⃣ 如何按模块重构 SSM 架构,让 Controller、Service、Dao 各司其职?
2️⃣ 在微服务架构下,SSM 如何升级支持分布式事务?
3️⃣ 如何引入版本管理和模块拆分,避免多团队协作时的依赖冲突?
4️⃣ 如何提升测试覆盖率,确保重构不引入新 Bug?
💬 工程师回答:
1️⃣ 重构时我会按业务域(支付、退款、账单等)拆分模块:
-
Controller 层抽象公共基类,统一异常、响应封装。
-
Service 层把支付核心逻辑和非支付逻辑解耦,用 SPI 或事件驱动调用外部。
-
Dao 层用 MyBatis 多数据源配置,支持账务、清结算分别走不同库。
2️⃣ 分布式事务场景,我们会用 Seata 或 TCC 模式代替传统 @Transactional。微信支付里很多是异步补偿(比如订单支付失败后自动退款)。
3️⃣ 代码多团队协作时,用 Maven 多模块管理,单个模块独立打包,版本依赖固定。
4️⃣ 提升测试覆盖率,需要引入 Mock 框架(Mockito)、契约测试,尤其在核心支付路径上加回归测试保障。
1.4 单元测试
步骤1:新建测试类
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfig.class)
public class BookServiceTest {
}步骤2:注入Service类
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfig.class)
public class BookServiceTest {
@Autowired
private BookService bookService;
}步骤3:编写测试方法
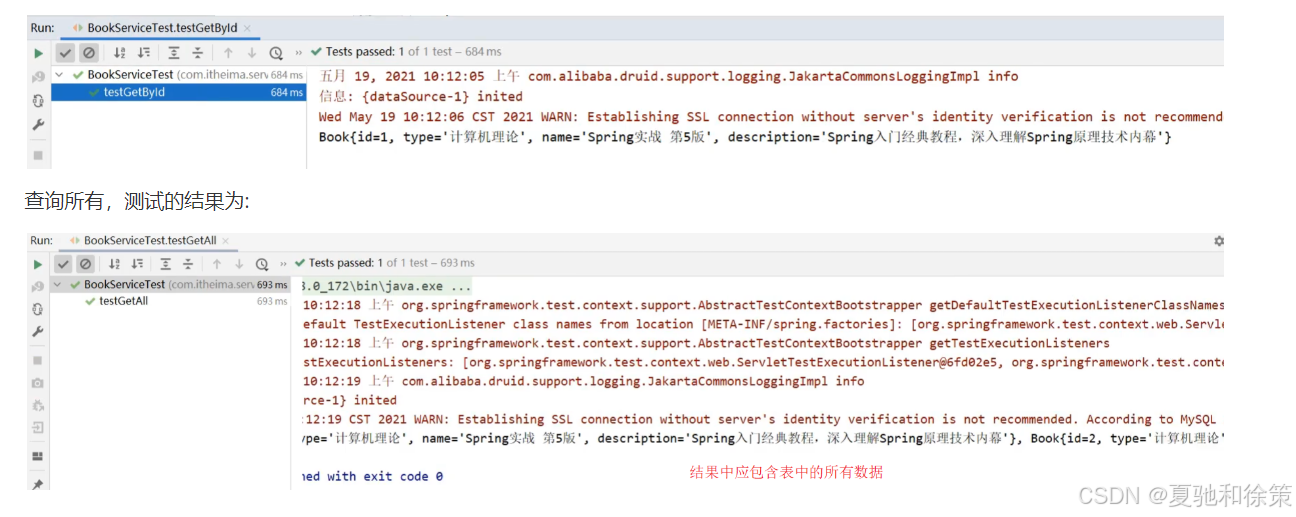
我们先来对查询进行单元测试。
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfig.class)
public class BookServiceTest {
@Autowired
private BookService bookService;
@Test
public void testGetById(){
Book book = bookService.getById(1);
System.out.println(book);
}
@Test
public void testGetAll(){
List<Book> all = bookService.getAll();
System.out.println(all);
}
}根据ID查询,测试的结果为:
查询所有,测试的结果为:
🧠 理论理解
使用 Spring 整合 Junit 编写单元测试,可以在不启动整个项目的情况下,快速验证 Service 层、DAO 层逻辑。测试要覆盖核心业务、异常分支、边界条件。
🏢 大厂实战理解
-
字节跳动:所有核心模块必须写单测,测试覆盖率纳入 CI 检查。
-
阿里巴巴:通过自研单测框架,结合 Mock 数据库、缓存,模拟大流量场景。
-
OpenAI:对外提供 API 时,每个接口都要写接口测试、性能测试,保证高并发下可用。
面试题4:
美团面试官问:
Spring 整合 Junit 做单元测试时,如何保证测试数据的隔离性和幂等性?大厂项目中通常怎么做?
答:
保证测试数据隔离性和幂等性的核心措施包括:
-
使用专门的测试数据库,与生产数据库彻底隔离。
-
在 @Before 或 @BeforeEach 方法中准备数据,保证测试用例运行前环境一致。
-
在 @After 或 @AfterEach 方法中清理数据,避免污染其他测试。
-
使用事务回滚(Spring 的 @Transactional + @Rollback),让测试数据在用例执行完自动撤销。
-
使用 Mock 对象(如 Mockito)或内存数据库(如 H2、Derby)减少对真实数据库的依赖。
在大厂中,测试会被纳入 CI/CD 流水线。比如:
-
字节跳动:每个提交都要跑单测,CI 平台会动态创建测试数据库容器。
-
美团:通过 TestContainer 动态拉起 Docker 化的数据库服务,跑完销毁,确保测试环境纯净。
-
Google:大规模微服务中,采用模拟数据和接口契约测试,保证模块解耦下的测试覆盖。
4️⃣ 场景题:Google - Cloud AI 数据服务的 SSM 架构适配
☁️ 背景:
Google Cloud AI 团队计划将部分 AI 数据服务模块迁移到 SSM 架构(主要用于中国区客户的定制化需求)。团队需要评估:
-
SpringMVC 是否能满足企业级接口管理?
-
Spring 事务在高并发 AI 任务调度场景下的表现如何?
-
MyBatis 与 Google 内部 Spanner 数据库集成的可行性。
🧩 挑战点:
-
全球化部署对多语言、多区域兼容有严格要求。
-
Google 内部很多工具和规范与 SSM 不直接兼容,需要适配层。
-
AI 服务要求高吞吐、低延迟,传统 SSM 架构可能性能不足。
🔧 问题:
你作为 Google Cloud 技术负责人,需要回答:
1️⃣ SpringMVC 在面向企业客户的 API 管理上,如何做权限、限流、监控?
2️⃣ Spring 事务在 AI 任务分布式调度下,如何与 Google 内部的分布式事务框架集成?
3️⃣ 如何让 MyBatis 有效适配 Spanner 或 BigTable 这种非传统关系型数据库?
4️⃣ 在 AI 高性能场景下,如何用异步化、反应式编程替代传统 SSM 同步阻塞模型?
💬 Google Cloud 架构师回答:
1️⃣ 面向企业客户的 API,SpringMVC 要接入统一认证(OAuth2、JWT)、限流(Guava、Envoy)、监控(Prometheus + Grafana)。接口不能裸跑在公网,必须 behind API Gateway。
2️⃣ 分布式事务,我们不会单靠 Spring,通常是集成 Google 自研的分布式事务(比如 Spanner 事务、Cloud Tasks + Pub/Sub 补偿机制)。
3️⃣ MyBatis 对接 Spanner 不够友好,通常我们用专门的 Google SDK 或 Hibernate Adapter,MyBatis 主要用于关系型 DB 场景。
4️⃣ 高性能场景下,我们会用 Spring WebFlux 替换 SpringMVC,走反应式、非阻塞架构,让 AI 推理服务最大化吞吐。
1.5 PostMan测试
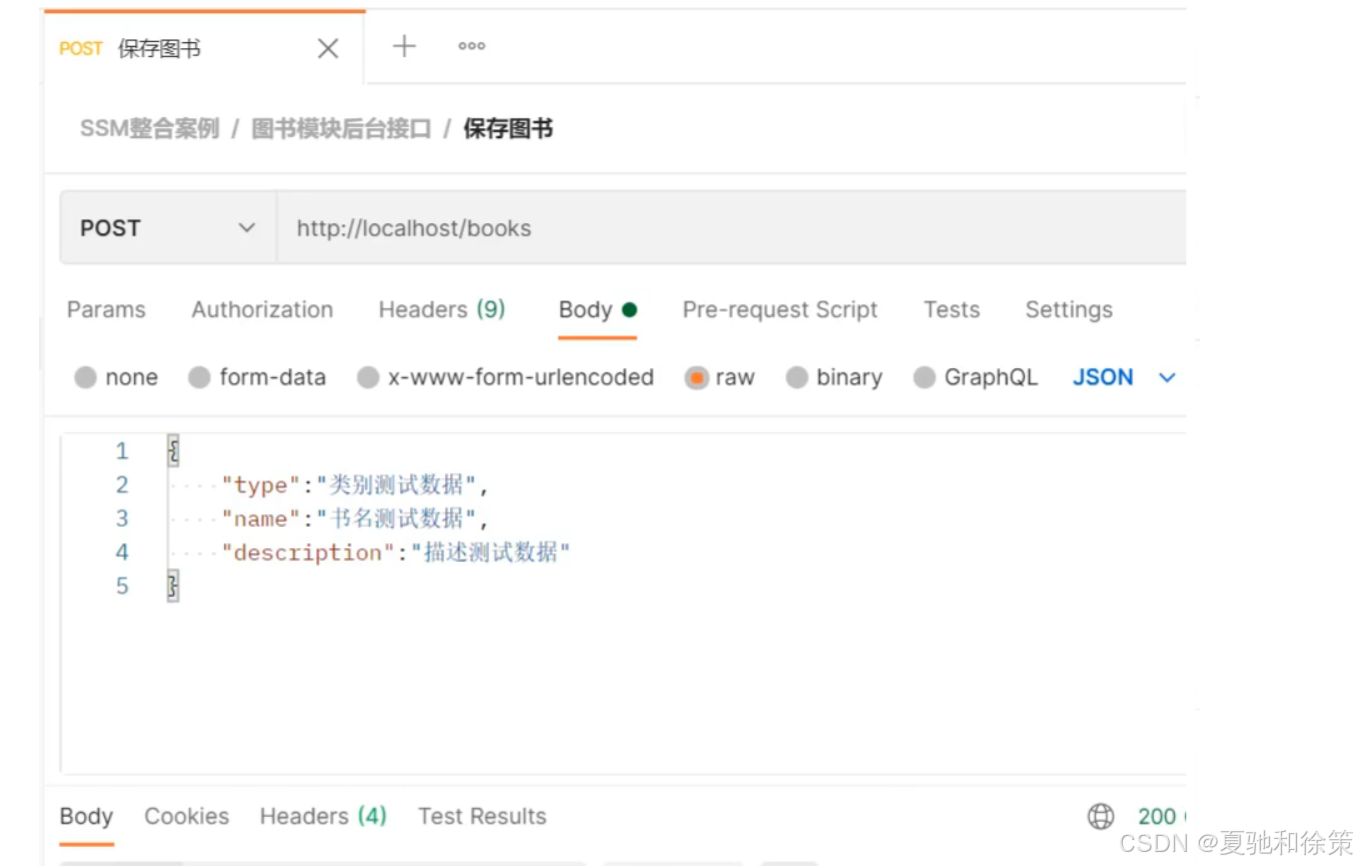
新增
http://localhost/books
{
"type":"类别测试数据",
"name":"书名测试数据",
"description":"描述测试数据"
} 
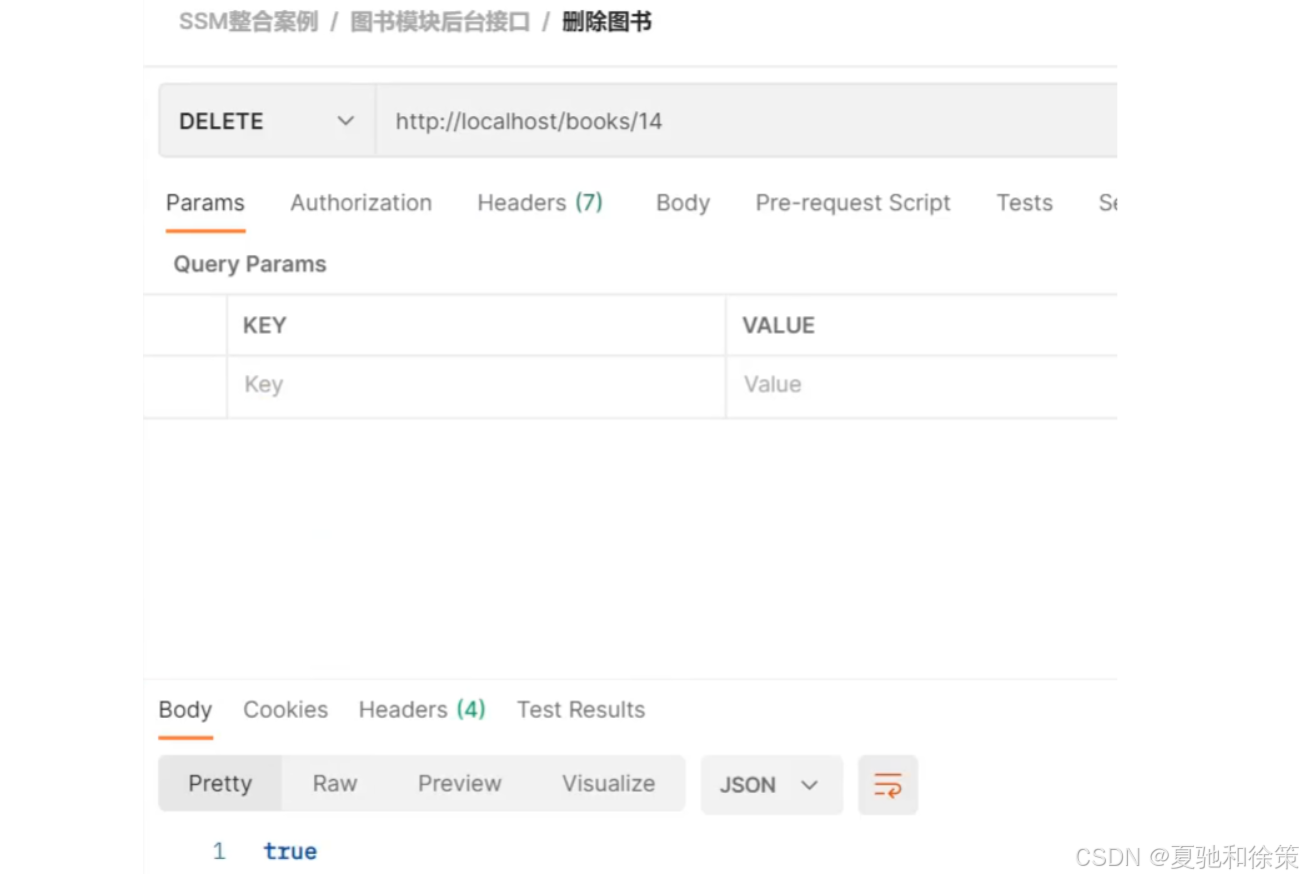
修改
http://localhost/books
{
"id":13,
"type":"类别测试数据",
"name":"书名测试数据",
"description":"描述测试数据"
} 
删除
http://localhost/books/14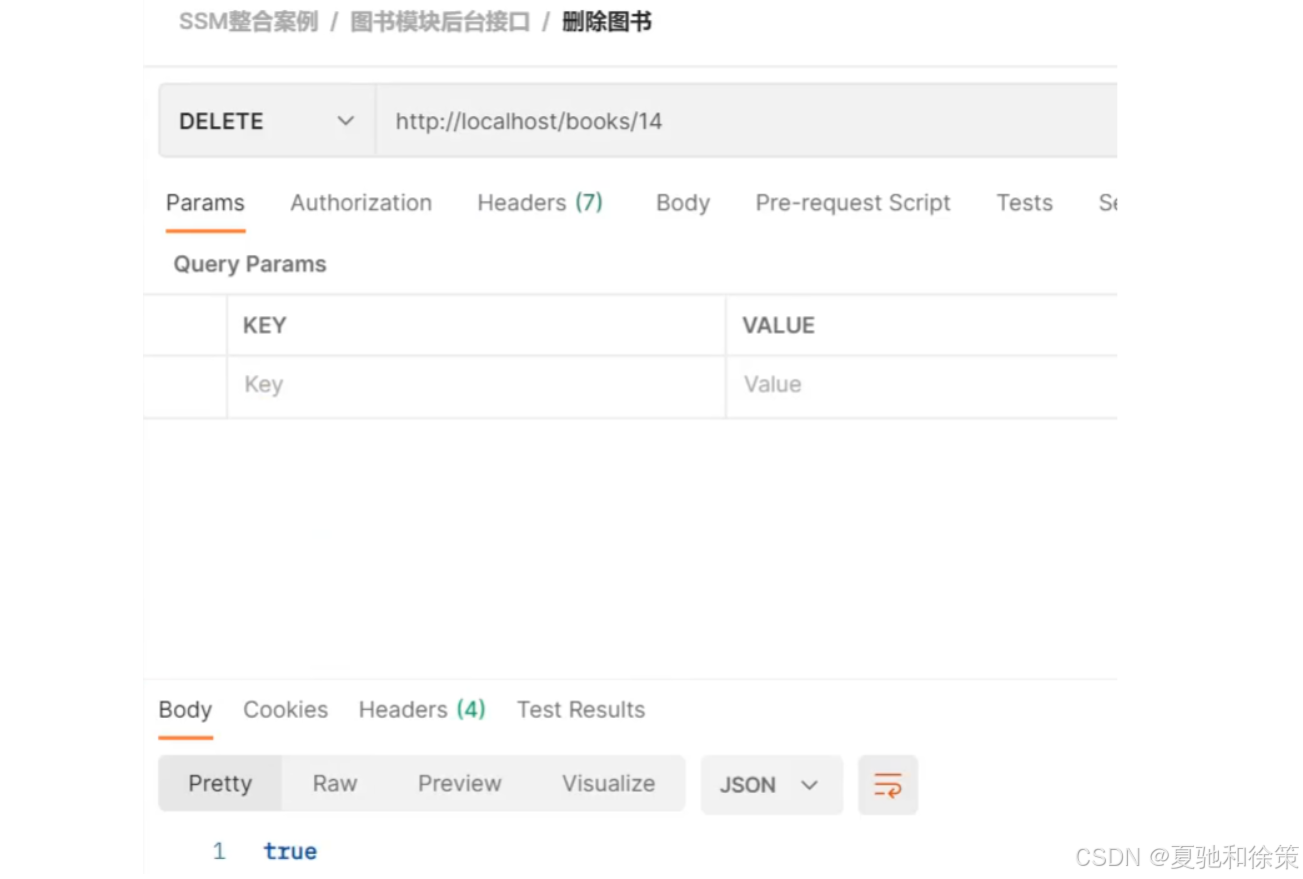
查询单个
http://localhost/books/1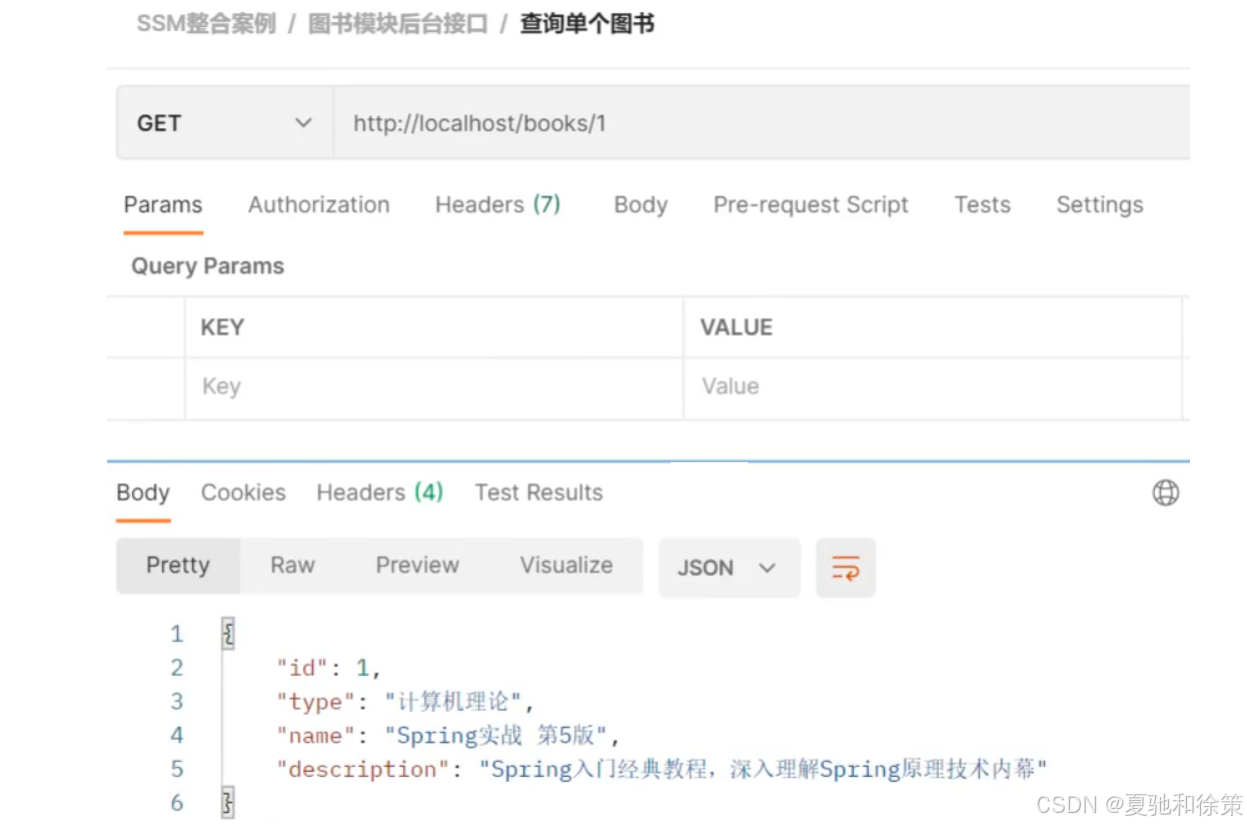
查询所有
http://localhost/books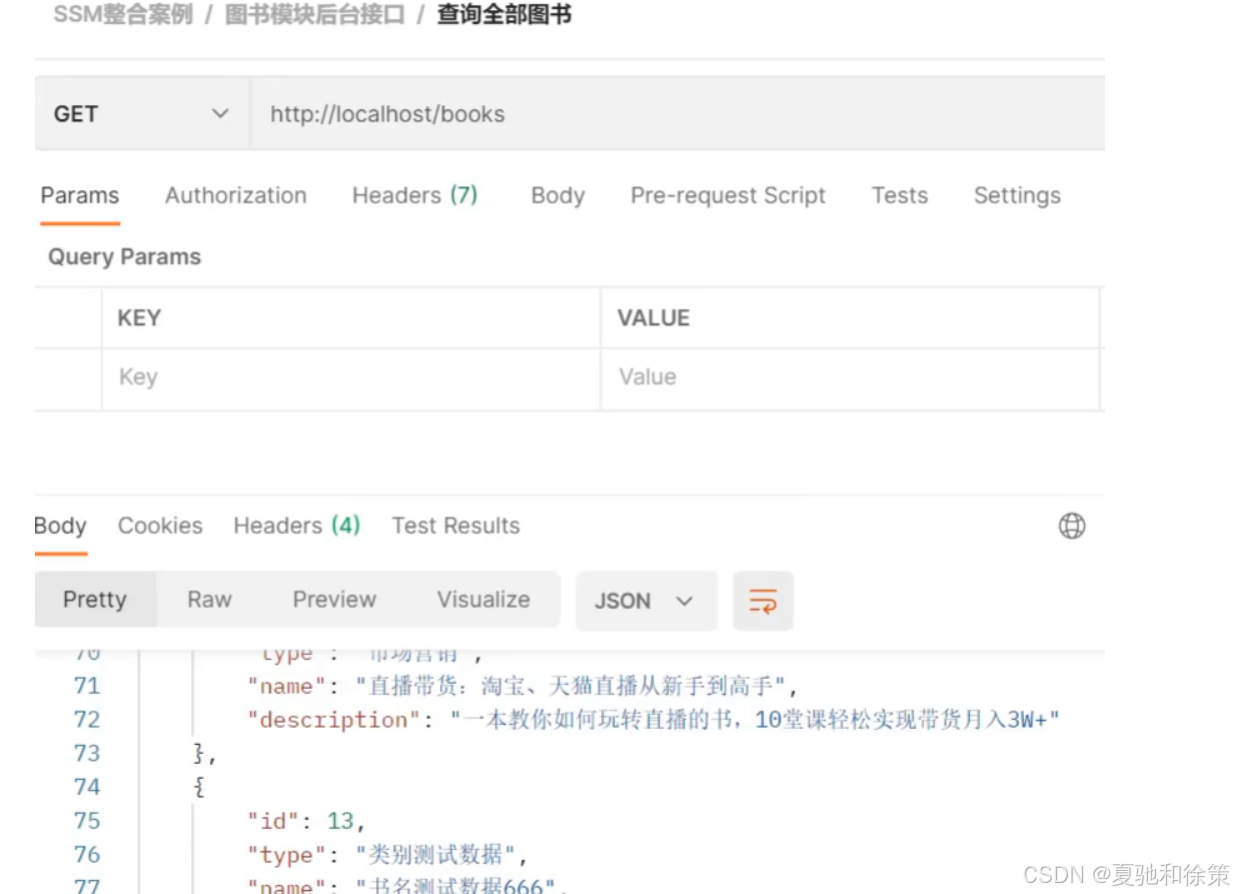
接口测试
🧠 理论理解
使用 Postman 进行增删改查接口测试,可以快速验证 RESTful 接口是否符合预期。测试要关注:请求路径、请求方法、请求体、响应体、状态码。
🏢 大厂实战理解
-
腾讯:上线前接口测试结合自动化脚本(如 Postman + Newman),验证接口稳定性。
-
字节跳动:测试环境与线上隔离,通过内部测试平台统一管理接口验证。
-
Google:自动化集成测试全流程接入 CI/CD,确保每次提交后接口都能回归测试。
面试题5:
阿里云面试官问:
Postman 测试 RESTful 接口可以发现哪些典型问题?在大厂项目中,接口测试一般是怎么自动化进行的?
答:
Postman 测试可以发现的问题包括:
-
接口路径、请求方法错误(如 GET 用成 POST)。
-
请求体参数缺失或类型错误。
-
接口返回值格式、字段不符合约定。
-
响应时间过长、超时。
-
异常处理不一致,状态码不规范(如 500、404、400 混用)。
在大厂项目中,接口测试通常不是手工跑,而是自动化:
-
阿里云:用 Postman + Newman 编写自动化脚本,结合 Jenkins 持续集成,每次提交后跑全量接口测试。
-
字节跳动:接入内部接口测试平台,统一管理 API 接口、用例、Mock 数据,自动跑冒烟和回归测试。
-
OpenAI:在 API 平台,所有对外接口都要跑负载测试、限流测试、恶意请求模拟,保证接口安全和稳定。
5️⃣ 场景题:OpenAI - ChatGPT 接口后台的 SSM 安全防护
🤖 背景:
OpenAI 的 ChatGPT 对外开放 API 接口,采用 SSM 架构开发中国区代理服务,需要防范以下风险:
-
接口被恶意刷流量,导致服务崩溃。
-
大规模请求产生雪崩效应,影响上下游依赖。
-
接口返回敏感数据泄漏(如调试日志、堆栈信息)。
🧩 挑战点:
-
Controller 层缺乏限流与鉴权,容易被攻击。
-
Service 层日志打印过多,未区分生产和测试环境。
-
异常处理机制不健全,错误信息直接返回前端。
🔧 问题:
你作为 OpenAI 中国区后端负责人,需要回答:
1️⃣ 如何在 SpringMVC 层引入统一限流和鉴权,保护核心接口?
2️⃣ 如何在 Service 层做好日志分级、敏感信息屏蔽?
3️⃣ 如何设计异常处理机制,让接口返回安全、规范的错误响应?
4️⃣ 如何用 API 网关或安全中间件,提供全局的防火墙和熔断保护?
5️⃣ OpenAI - ChatGPT 接口后台的 SSM 安全防护
💬 OpenAI 后端负责人回答:
1️⃣ SpringMVC 层,我会加统一的 HandlerInterceptor 实现限流(基于 IP、API Key),还要接入 OAuth2 鉴权中间件。核心接口前再套一层 API Gateway 做全局防刷。
2️⃣ Service 层日志必须分级(DEBUG、INFO、WARN、ERROR),并区分环境(生产禁止打印敏感信息、堆栈详情)。
3️⃣ 异常处理,用 @ControllerAdvice 全局异常捕获,返回标准化响应(code、message),绝不把 Java Exception 直接暴露给前端。
4️⃣ API 网关上,我们会配置熔断(Hystrix、Sentinel)、限流(令牌桶、漏斗算法)、防火墙(IP 黑名单、User-Agent 白名单)等机制,形成多道防护墙。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











